

前言
之前一直在忙毕业设计和毕业的事,博客有点久没更新了,现在赶紧重新拾起。
这次本文介绍一种非常有用的算法,叫做决策树(Decision Tree)。其应用非常广泛,而且在kaggle等数据科学比赛中也有大量使用基于其的一些方法比如随机森林,GBDT等。
写完之后感觉自己的理解还是非常浅显,这种东西还是要继续花时间才能理解透彻,后面有机会再继续补全了。
正文
决策树(Decision Tree)是一种自动分类器算法,也就是输入一堆数据,就能够自动学习出一个分类器用于分类,当然决策树是监督学习算法。而且决策树产生的模型具有易于解释的特点,像神经网络这种基本上就像个黑盒一样难以解释分类的理由,而决策树只需要通过观察分支规则就可以理解其推导过程。
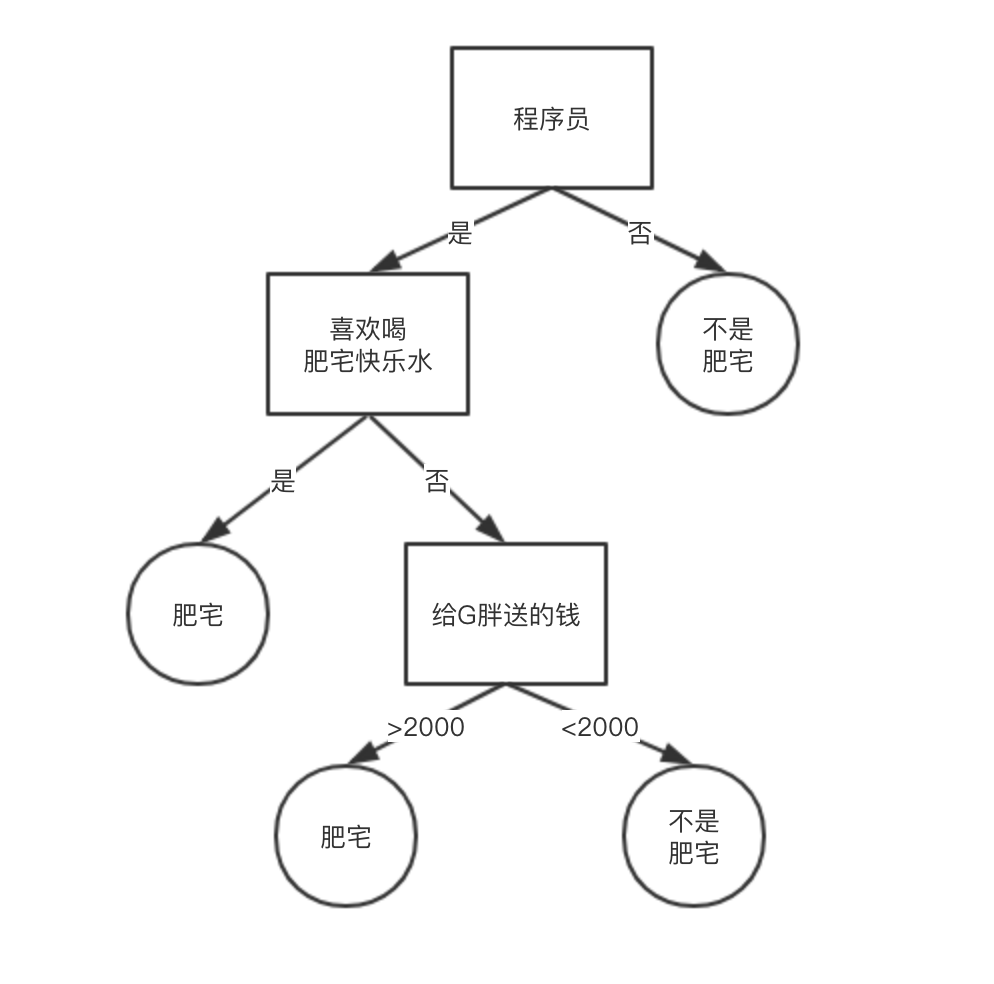
决策树的构造
那么决策树算法是如何根据数据自动学习出一个决策树结构的呢?为了回答这个问题我们首先需要了解一些信息论相关的知识点,并了解一些决策树的算法(ID3、C4.5)。
信息熵(Entropy)
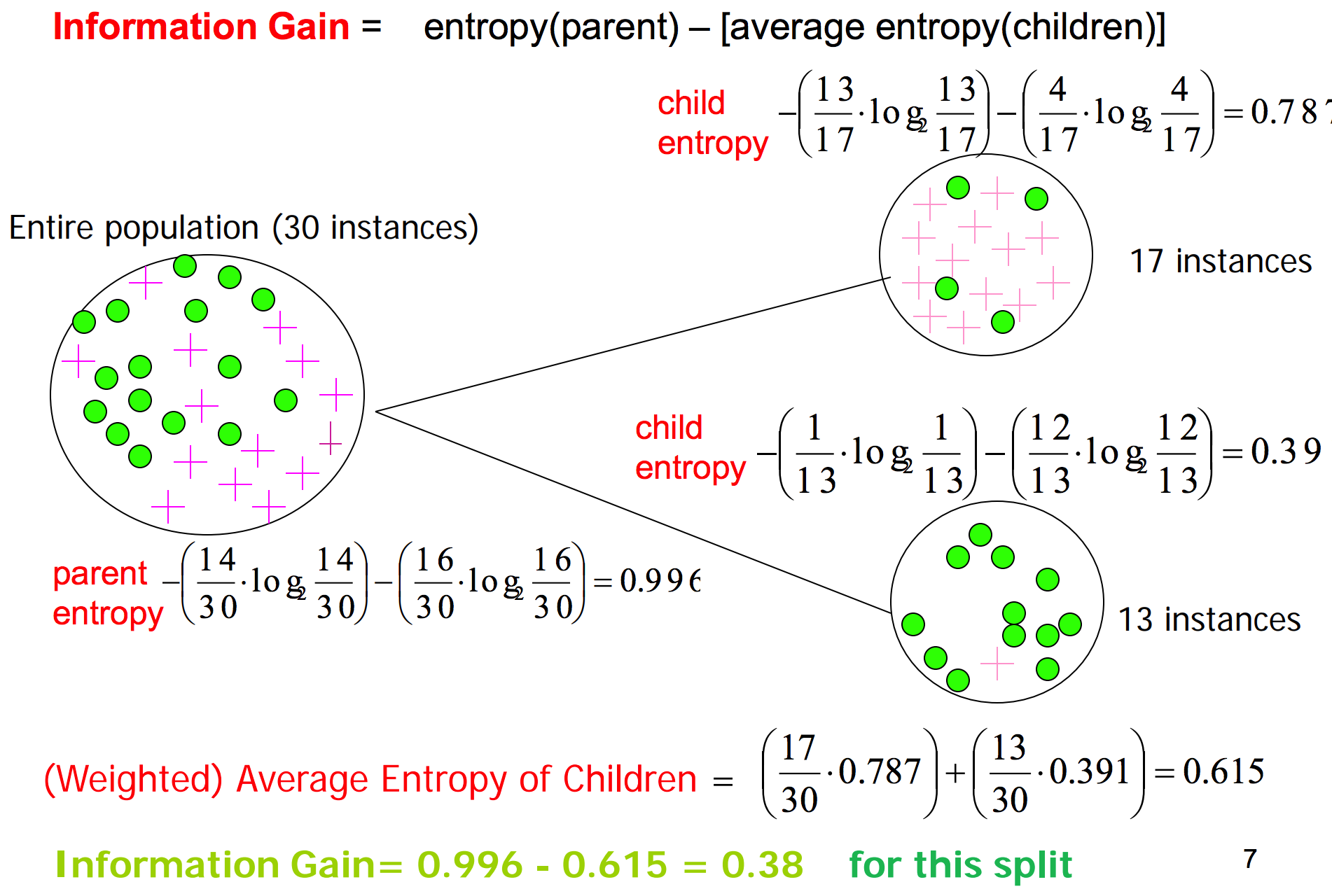
在信息理论中,熵被用来衡量一个随机变量出现的期望值。变量的不确定性越大,熵也就越大,把它搞清楚所需要的信息量也就越大,熵是整个系统的平均消息量。
公式中X表示随机变量,比如,而
表示概率质量函数。
反正熵越大则表示整个集合里越混乱。这里不对信息熵的概念和理解做太多详细的说明,只需要理解信息熵的大小表示什么就行,如果对此有兴趣可以参看信息熵是什么? - D.Han的回答 - 知乎。

选择哪个属性进行划分
决策树中我们需要根据属性自动划分集合,最终目标是将所有数据进行分类,那么我们怎么去选择现在该用哪个属性去划分呢?
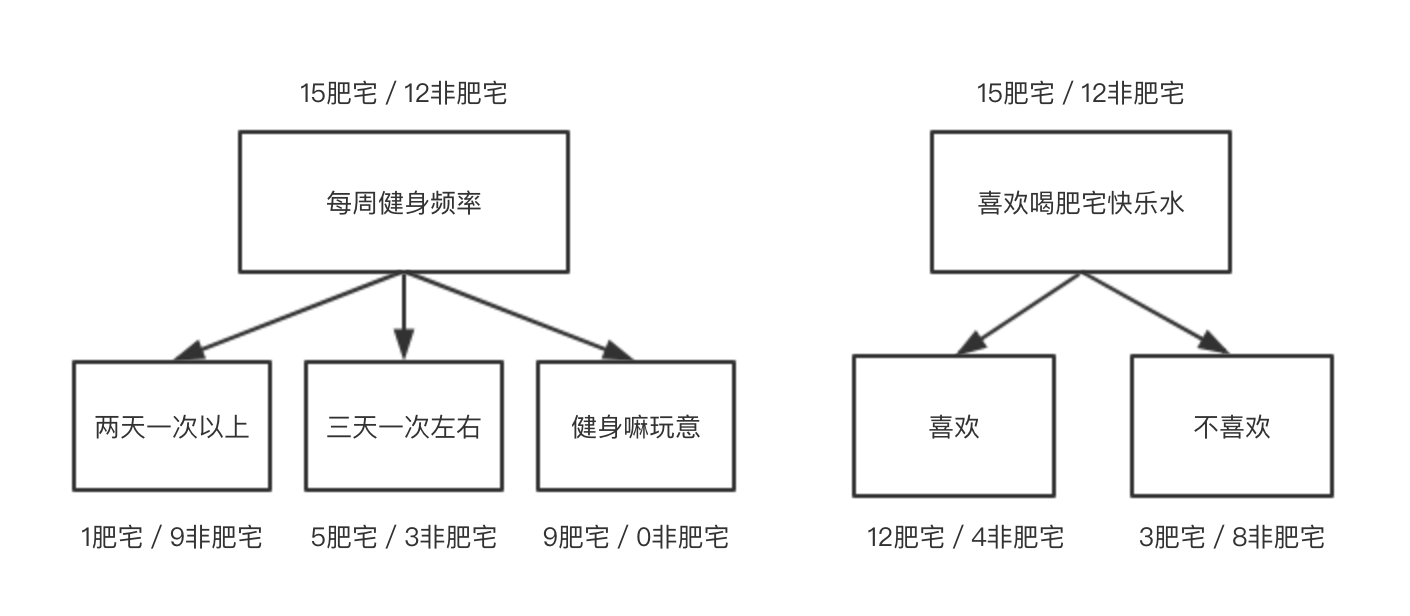
信息增益(Information gain)
我们希望确定使用哪个属性来划分或者如何划分能够更好的区分各个类型。而信息增益就告诉了我们某一属性有多重要。
我们会使用信息增益来确定属性划分的顺序。
以“每周健身频率”做为划分的话,信息增益为:
以“喜欢喝肥仔快乐水”做为划分的话,信息增益为:
由于信息增益0.535 > 0.166 所以选择健身频率的划分比选择喜欢肥仔快乐水更有效。
在这个例子我们以信息熵为例子来计算信息增益最大的属性做为划分。
决策树的剪枝(Pruning)
一般我们都会使用递归的方式构造决策树,然而这样可能会带来一个过拟合的问题,也就是说它可能会变得过于针对训练数据。专门针对训练集所创造出来的分支其熵指与真实情况相比可能会有所降低,但决策树上的判断条件实际上是完全随意的,因此一颗过度拟合的决策树所给出的答案也许会比实际情况更具特殊性。
但递归生成决策树的算法中直到无法进一步降低熵的时候才会停止分支的创建。所以其中一种解决方案是只要当熵减少的数量小雨某个最小值时就停止创建分支。但这种策略有一个小小的缺陷--我们有可能会遇到这种数据集:某一次分支的创建并不会令熵降低多少,但是随后创建的分支却会使熵大幅度降低,所以一个替代的策略是,先构造好整棵树,然后尝试消除多余的节点。这个过程就是剪枝。
在一些搜索算法里,比如DFS中也经常会为了提高算法性能而剪取不可能有解的分支,这个也叫剪枝。
什么时候使用决策树
或许决策树最大的优势就是它可以轻易的对一个受训练的模型进行解释(肥宅喜欢喝肥宅快乐水)。而且决策树可以接手分类数据(国籍)和数值数据(给G胖送的钱)做为输入数据。同时决策树还允许数值的缺失。
不过决策树算法还是有些缺陷的,如果可能的结果只包含少数几种可能(肥宅或非肥宅)的话,算法会非常有效,但是如果可能的结果非常多的时候,算法就没那么有效了,决策树会变得异常复杂,预测效果也不会很好。
