

Session 604 : Metal for OpenGL Developers
关于作者:可以在这里找到一些关于我的信息。
引言
Metal 是 Apple 开发的一款图形引擎。本文将对比 OpenGL,详细介绍 Metal 的对象模型以及开发思想,旨在帮助 OpenGL 开发者更容易地转向 Metal 开发。
由于 Metal 与 OpenGL 同为底层图形引擎,因此阅读本文需要一定的图形基础。本文假定读者已经具备一定图形学知识并对 OpenGL 熟悉。
为何选择 Metal
对于广大图形开发者来说,有着非常多的工具可供选择。
上层框架
对于普通的 2D、3D 图形开发者来说,有 Apple 原生的SpriteKit、SceneKit等框架,而对于游戏开发者来说,有Unity、虚幻等强大的第三方游戏引擎。
在条件允许的情况下,开发者们应该尽可能使用上层框架进行开发,以专注于业务,屏蔽图形学细节。以上上层框架应是开发者们的首选。
OpenGL
但在某些特定场景如要求跨平台、包大小限制等场景下,开发者们可能不得不使用 OpenGL 来开发。因为 OpenGL 跨平台,性能佳,且不占用过大的包大小等优点,使 OpenGL 至今仍然广泛被使用。
但有着超过25年历史的 OpenGL 技术本身,随着现代图形技术的发展,遇到了一些问题:
- 现代 GPU 的渲染管线已经发生变化。
- 不支持多线程操作。
- 不支持异步处理。
随着图形学的发展,OpenGL 本身设计上存在的问题已经影响了 GPU 真正性能的发挥,因此 Apple 设计了 Metal。
Metal
为了解决这些问题,Metal 诞生了。
它为现代 GPU 设计,并面向 OpenGL 开发者。它拥有:
- 更高效的 GPU 交互,更低的 CPU 负荷。
- 支持多线程操作,以及线程间资源共享能力。
- 支持资源和同步的控制。
Metal 简化了 CPU 参与渲染的步骤,尽可能地让 GPU 去控制资源。与此同时,拥有更现代的设计,使操作处于可控,结果可预测的状态。在优化设计的同时,它仍然是一个直接访问硬件的框架。与 OpenGL 相比,它更加接近于 GPU,以获得更好的性能。
小结
古老的 OpenGL 已经无法适应现代图形技术的发展,而 Metal 为现代图形技术而设计,是 OpenGL 的优良替代品。
Apple 早在 2014 年就推出了 Metal,经过四年的铺垫,于今年 WWDC 祭出了大杀器:
- OpenGL 和 OpenCL 将于 macOS 10.14 弃用。
- OpenGL ES 将于 iOS 12 弃用。
虽然目前 API 还能够使用,但是被标记弃用的 API 很可能会在未来的某一刻被永远抹去。
因此,是时候开始使用 Metal 了。
Metal 的对象模型
在 OpenGL 中,所有资源如 Buffer,Texture 等都依附于一个上下文(Context)。

而在 Metal 中,情况则完全不同。Metal 使用一系列更小,职责更加清晰的对象去分别管理各类资源,开发者们从对象名中一眼就能认出他的职责。
Metal Device
Metal Device 可以看做是 GPU 的入口,从此为入口可以去生成,操作更加具体的资源和对象。
由 Metal Device 可以继续构造出 Texture、Buffer 和 Pipeline(Pipeline 中包含了着色器程序)等资源对象。
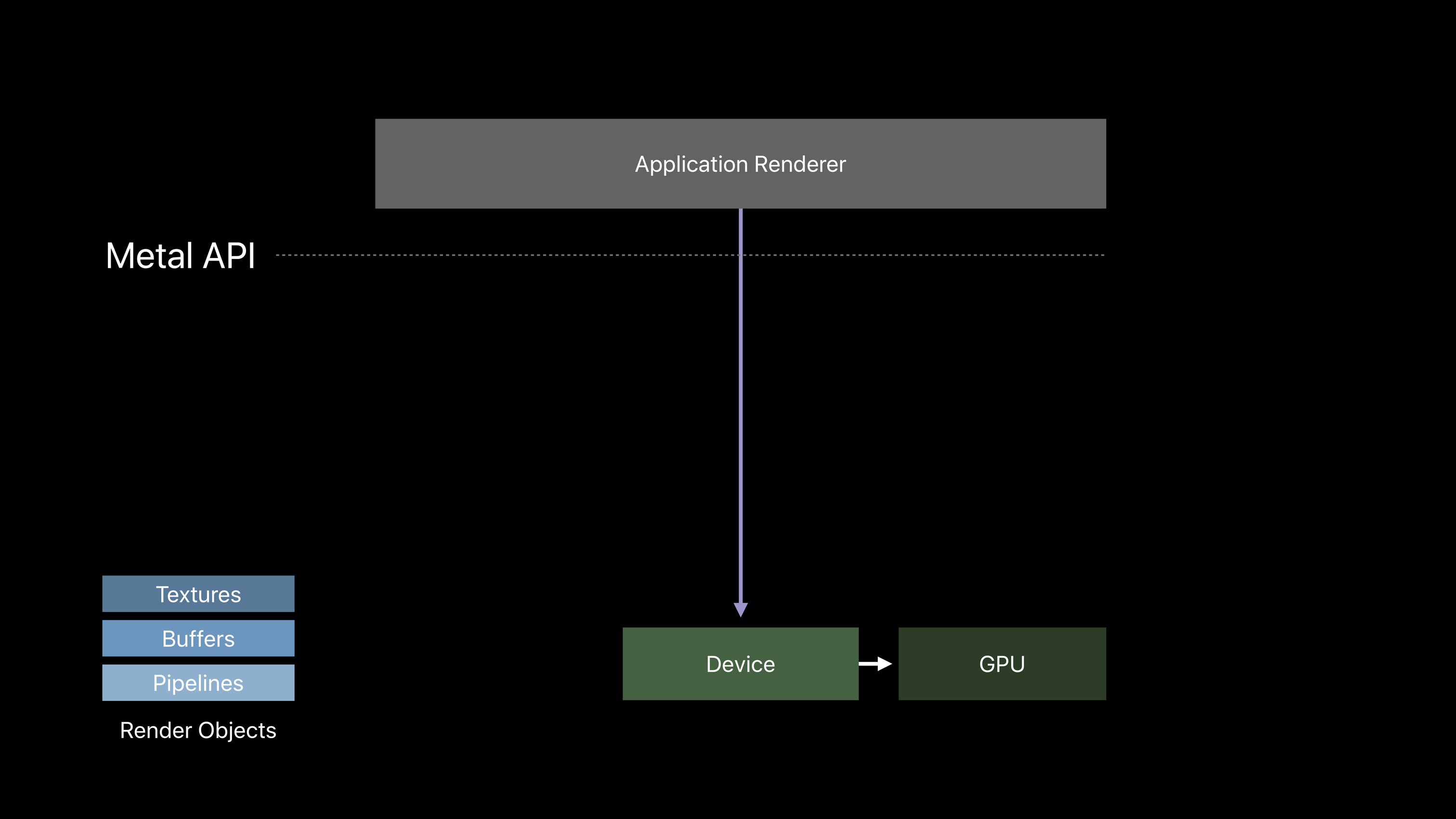
熟悉 OpenGL 的读者会发现在 OpenGL 中也存在这些概念。它们的用途是大同小异的,但在构造和管理等的工程设计上有很大的区别。
Metal 资源对象
纹理(Texture)、缓冲区(Buffer)等资源对象将直接从 Metal Device 对象创建,创建以后,对象是不可变的,但内部的图像数据是可变的。
渲染管线(Render Pipeline)、深度模板(Depth Stencil)等对象通过状态描述(Descriptor)创建,对象以及内部数据都是不可变的。
由于不可变对象的存在,使得 Metal 在只需要在创建对象时检查一次对象即可。而 OpenGL 在每次绘制以前都需要检查对象是否发生变化,在这一点上 Metal 将会获得更好的性能。
除此之外,由于不可变对象的存在,在多线程中,Metal 不需要使用线程锁,因此也会得到更好的性能。
Metal 命令系统
Metal 将渲染进一步抽象成了命令,以命令和命令队列的形式进行管理。
命令队列
上文中提到的 Metal Device,可以生成一个命令队列(Command Queue)。这个命令队列由 Metal 自行维护,而开发者只需要往这个队列里面丢命令就可以了。
命令
Metal 中的命令(Command Buffer)是 GPU 任务的抽象封装,近似于OpenGL 中的一次绘制调用(draw call)。如果读者阅读过 cocos2d-x 的源码的话就会发现,cocos2d-x 的渲染系统也进行了类似的封装,以便于进行合并、批量回执等优化操作。
Metal 中的命令分为四种类型:
- 渲染命令(Render Command):渲染图像的命令。
- 块传输命令(Blit Command):纹理和缓冲区进行复制的命令。
- 计算命令(Compute Command):GPU 并行计算的命令。
- 并行渲染命令(Parallel Render Command):并发的渲染命令。
这些命令被添加到命令队列以后,Metal 会自行按顺序执行命令。
命令编码器
命令如何被创建呢,可以通过命令编码器(Command Buffer Encoder)创建。上文提到命令有四种类型,所以命令编码器也有四种类型,分别编码四个类型的命令。命令编码阶段完全由 CPU 负责。
在命令编码器中,开发者可以具体设置命令的各项参数,并最终生成命令对象交于命令队列。
小结
Metal 的对象模型在设计上有许多优于 OpenGL 的地方。例如不可变对象的存在可以简化多线程操作以及节约对象检查的时间,命令系统的存在使渲染系统能更好地进行优化。
除了这些,Metal 还拥有优秀的面向对象封装。相比于 API 晦涩,到处使用数字句柄的 OpenGL,在开发和维护的效率上都有质的飞跃。
在了解了 Metal 的对象模型以后,就可以开始实战了。
以 OpenGL 程序移植为例,来具体体验一下 Metal 的实战。
Metal 实战
本节将会分构建时、初始化时和渲染时这三个阶段来讲。

构建时
在程序编译构建之时,Metal 的着色器程序将会被提前编译。
Metal 着色器语言
Metal 所使用的着色器语言 Metal SL 是一套基于 C++ 扩展的语言。class、namespace、enum 等 C++ 中的特性都可以应用在 Metal 的着色器中,甚至还可以使用 template。相比基于C语言扩展的 OpenGL SL,可谓是质的改变。
当然,毫无疑问的,向量矩阵运算,图形相关的类必然也是内建好的,下面来具体看看 Metal 的着色器程序该怎么写。
渲染时所需的顶点着色器:
vertex VertexOutput myVertexShader(uint vid [[ vertex_id ]],
device Vertex * vertices [[ buffer(0) ]],
constant Uniforms & uniforms [[ buffer(1) ]])
{
VertexOutput out;
out.clipPos = vertices[vid].modelPos * uniforms.mvp;
out.texCoord = vertices[vid].texCoord;
return out;
}
vertex前缀代表这是一个顶点着色器,VertexOutput是函数的返回值,这是一个自定义的结构体,具体结构暂且先不管。myVertexShader为函数名,后面跟的是参数。
这个函数有两个参数,一个是uint类型的参数名为vid,而后面跟的[[ vertex_id ]]是参数的句柄。
这是一个新的概念,Metal 给每个参数扩展了一个句柄,这和 OpenGL 类似。每个参数会有个句柄,在 CPU 往 GPU 传递参数时需要这个对应的句柄才可以传过来。那么这里vid参数的句柄为vertex_id,这是一个内建的句柄,表示绘制时顶点的索引数。
第二个参数为类型为Vertex指针,Vertex也是个自定义结构体,具体内容暂且不管。它是一个结构体指针,句柄为[[ buffer(0) ]]。在 Metal 中,不同类型的参数的句柄是分开计算的。vertices参数的句柄为buffer的0。
同理,下面是个片元着色器函数:
fragment float4 myFragmentShader(VertexOutput in [[ stage_in ]],
constant Uniforms & uniforms [[ buffer(3) ]],
texture2d<float> colorTex [[ texture(0) ]],
sampler texSampler [[ sampler(1) ]])
{
return colorTex.sample(texSampler, in.texCoord * uniforms.coordScale);
}
它的输入时顶点着色器的输出,且拥有纹理、采样器等参数。返回值是四维浮点数组,即该片元的颜色值。
下面来看看这两个自定义的结构:
struct Vertex
{
float4 modelPos;
float2 texCoord;
};
struct VertexOutput
{
float4 clipPos [[position]];
float2 texCoord;
};
Vertex由 CPU 输入,获得模型的三维坐标以及贴图的映射坐标,经过顶点着色器处理之后输出VertexOutput,这个结构作为片元着色器的输入,进入片元着色器计算片元颜色。这个流程与传统的 OpenGL 相同。
结构中包含内简句柄position的参数,片元着色器的输入结构中必须包含有此句柄的参数,否则会无法通过编译。
使用着色器程序
有了上文中的着色器程序,使用时如何传递参数给着色器程序呢?
在 OpenGL 中,开发者需要首先要根据参数名获得参数句柄,然后利用句柄进行参数传递(高版本的 OpenGL 也支持通过 layout 写死句柄),而使用 Metal 时,是在编码器编码阶段通过编码器和句柄直接进行参数传递。
[renderEncoder setFragmentBuffer:myUniformBuffer offset:0 atIndex:0];
[renderEncoder setFragmentTexture:myColorTexture atIndex:0];
[renderEncoder setFragmentSampler:mySampler atIndex:1];
函数中使用的 index 即是该参数的句柄。通过编码器的这一系列操作,已经能够将参数正确传递到着色器程序中了。
SIMD
SIMD 是 Apple 提供的一款方便原生程序与着色器程序共享数据结构的库。
开发者可以在头文件中定义一系列结构,在原生代码和着色器程序中通过#include包含这个头文件,两者就都有了这个结构的定义。
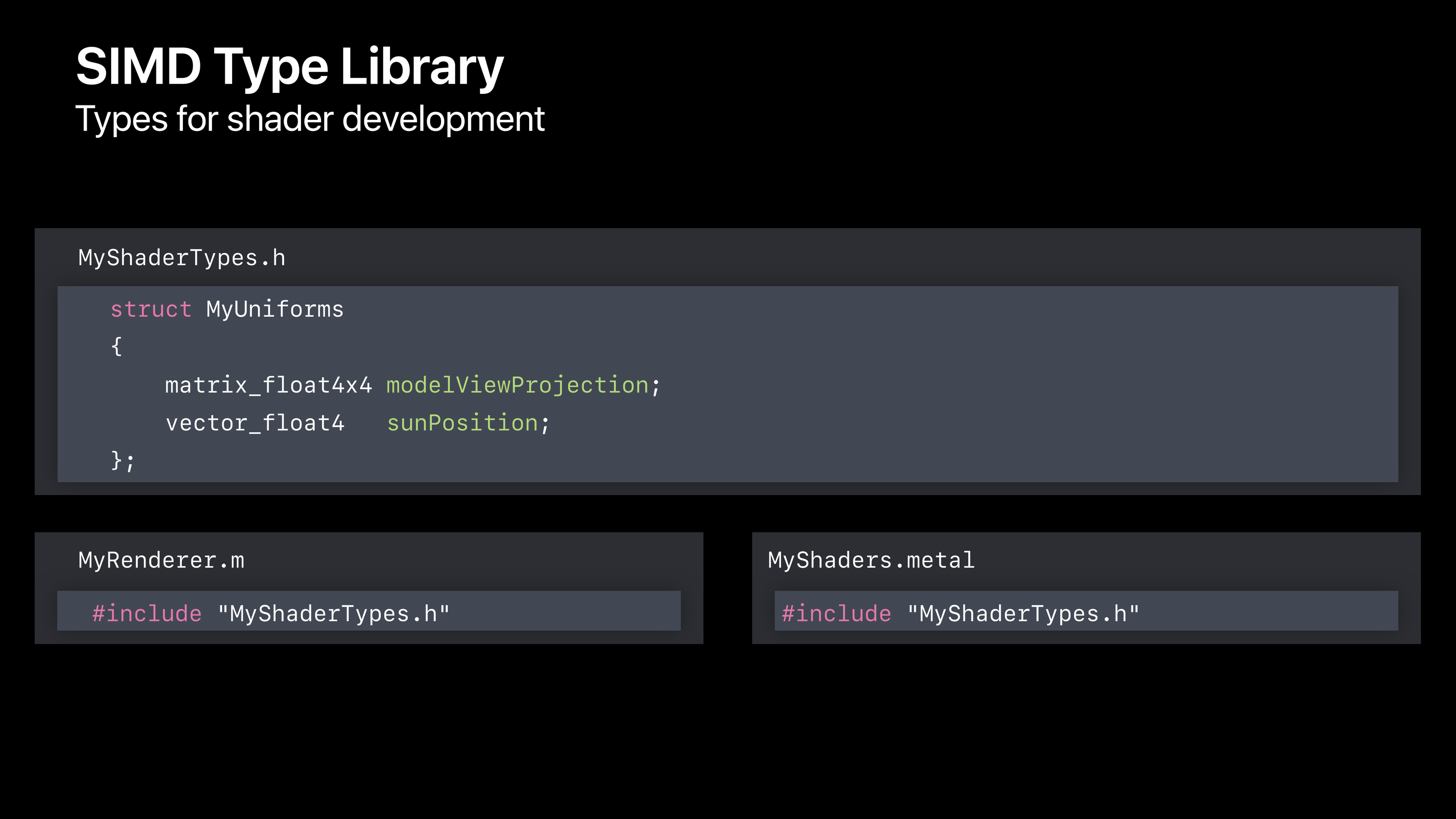
使用 SIMD 能最大程度减少由于结构 layout 上的不同引发的问题。
其他
Metal 的着色器程序在编译时会被编译成类型为metallib的文件,在这个文件中,着色器程序并没有真正被编译成二进制,而是只经过了编译器前端的中间态。在运行时会被真正编译成二进制,这一步仅需要完全编译的时间的一半。
当然,Metal 也支持在运行时编译着色器源码,但 Apple 并不支持这么做。这样许多问题无法在编译时定位,不方便开发与维护。
小结
Metal 使用了比 OpenGL 更为高级的着色器语言,并在编译时编译着色器代码以快速暴露错误,以及 SIMD 等工具库可以帮助开发者们更快速地开发与维护图形代码。
初始化时
在 Metal 初始化时,需要根据上文提到的对象模型,构造一系列对象。
Device
Device 象征着一个 GPU,所有纹理、缓冲区等都基于这个对象产生。
id<MTLDevice> device = MTLCreateSystemDefaultDevice();
在 iOS 中,只有一个 GPU,因此只会有一个MTLDevice对象,在 macOS 中,多块显卡就会带来多 GPU,即多个MTLDevice对象。
Command Queue
id<MTLCommandQueue> commandQueue = [device newComandQueue];
Texture
创建 Texture 时,将使用一个 TextureDescriptor 对象。它包含了一系列 Texture 所需要的属性,并使用这个 Descriptor,从 Device 创建一个 Texture Object 对象。Texture Object 会管理一块内存,真正存放纹理的数据。

对于真正存放纹理数据的内存,开发者选择存储模式以控制 CPU 和 GPU 如何管理这片内存:
- Shared Storage:CPU 和 GPU 均可读写这块内存。
- Private Storage: 仅 GPU 可读写这块内存,可以通过 Blit 命令等进行拷贝。
- Managed Storage: 仅在 macOS 中允许。仅 GPU 可读写这块内存,但 Metal 会创建一块镜像内存供 CPU 使用。
Apple 推荐在 iOS 中使用 shared mode,而在 macOS 中使用 managed mode。
在了解了内存管理方法后,创建一个 Texture 实现如下:
MTLTextureDescriptor *textureDescriptor = [MTLTextureDescriptor new];
textureDescriptor.pixelFormat = MTLPixelFormatBGRA8Unorm;
textureDescriptor.width = 512;
textureDescriptor.height = 512;
textureDescriptor.storageMode = MTLStorageModeShared;
id<MTLTexture> texture = [device newTextureWithDescriptor:textureDescriptor];
填充图像数据:
NSUInteger bytesPerRow = 4 * image.width;
MTLRegion region =
{
{0,0,0}, //Origin
{ 512, 512, 1 } // Size
};
[texture replaceRegion:region
mipmapLevel:0
withBytes:imageData
bytesPerRow:bytesPerRow];
与 OpenGL 不同的是,Metal 中的 Texture:
- Metal 中采样器不属于纹理的一部分。
- Metal 不会翻转纹理,原点在左上角,OpenGL 的原点是左下角。
- Metal 不转换数据格式。
Metal 还提供了 MetalKit 来快速创建 Texture。
Buffer
Metal 中,所有无结构的数据都使用 Buffer 来管理。与 OpenGL 类似的,顶点、索引等数据都通过 Buffer 管理。
由于数据是无结构的,因此如何管理由开发者自己制定。如以下方法可以利用编译器来计算数据偏移来管理数据:
id<MTLBuffer> buffer = [device newBufferWithLength:bufferDataByteSize
options:MTLResourceStorageModeShared];
struct MyUniforms *uniforms = (struct MyUniforms*) buffer.contents;
uniforms->modelViewProjection = modelViewProjection;
uniforms->sunPosition = sunPosition;
这种方式下,开发者需要考虑内存对其因素。float3、int3、uint3等结构占用的内存空间并非12字节,而是16字节。如果确实需要这样打包数据,需要使用packed_float3等这类数据结构。
Pipeline
Pipeline 同样需要通过一个 Descriptor 来创建。以下是创建一个渲染管线需要的参数:
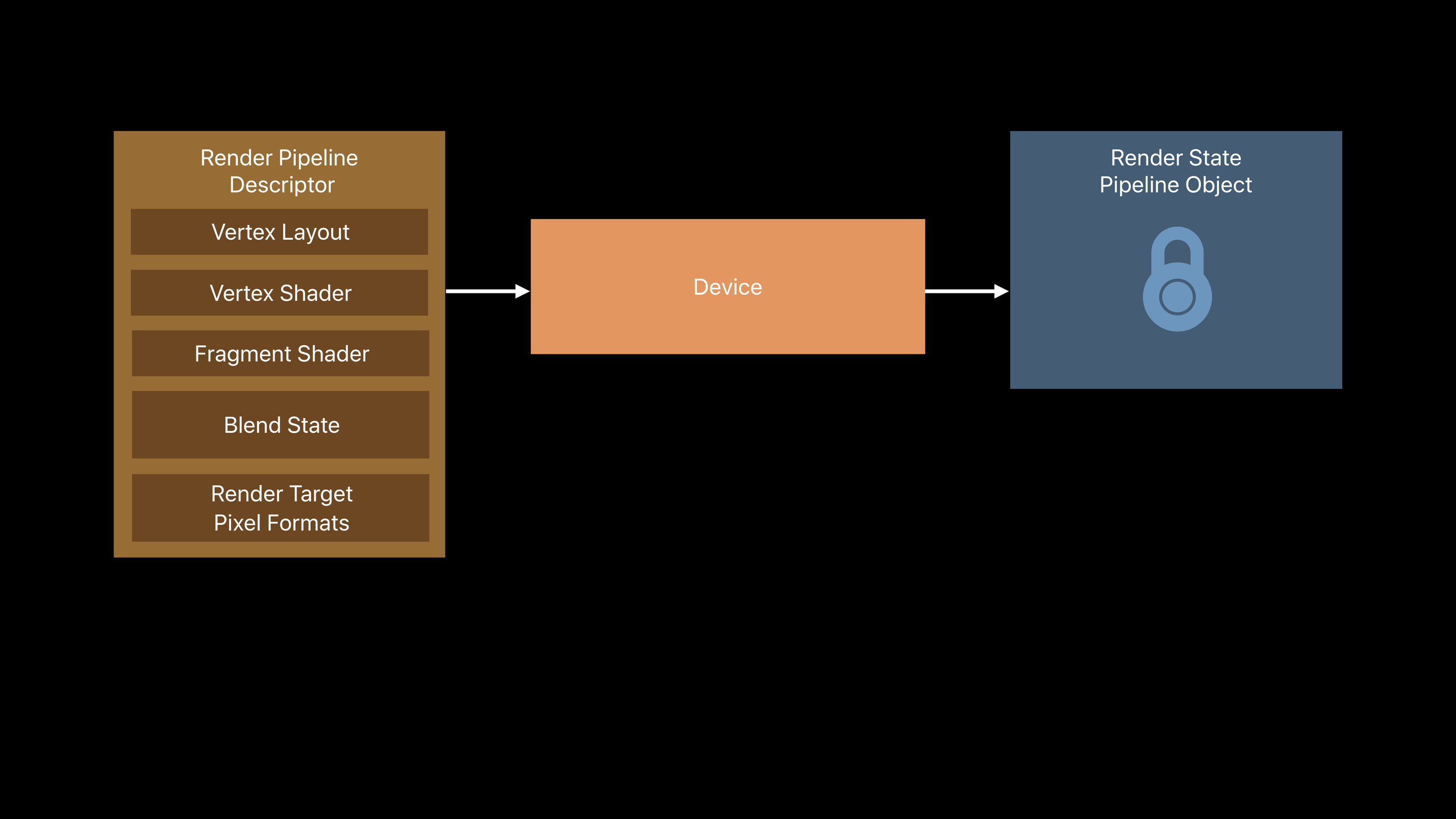
在制定了着色器函数,各类渲染状态以后,就可以使用这个 Descriptor,通过 Device 创建一个 Pipeline 对象。以下是创建渲染管线的实现:
id<MTLLibrary> defaultLibrary = [device newDefaultLibrary];
id<MTLFunction> vertexFunction = [defaultLibrary newFunctionWithName:@"vertexShader"];
id<MTLFunction> fragmentFunction = [defaultLibrary newFunctionWithName:@"fragmentShader"];
MTLRenderPipelineDescriptor *pipelineStateDescriptor = [MTLRenderPipelineDescriptor new];
pipelineStateDescriptor.vertexFunction = vertexFunction;
pipelineStateDescriptor.fragmentFunction = fragmentFunction;
pipelineStateDescriptor.colorAttachments[0].pixelFormat = MTLPixelFormatRGBA8Unorm;
id<MTLRenderPipelineState> pipelineState;
pipelineState = [device newRenderPipelineStateWithDescriptor:pipelineStateDescriptor
error:nil];
在 OpenGL 中,一个 Shader Program 对象只包含顶点着色器和片元着色器,而在 Metal 中,包含了以上描述提到的所有属性。因此在构造一个渲染管线以前,必须确定全部这些参数以后才能够创建。
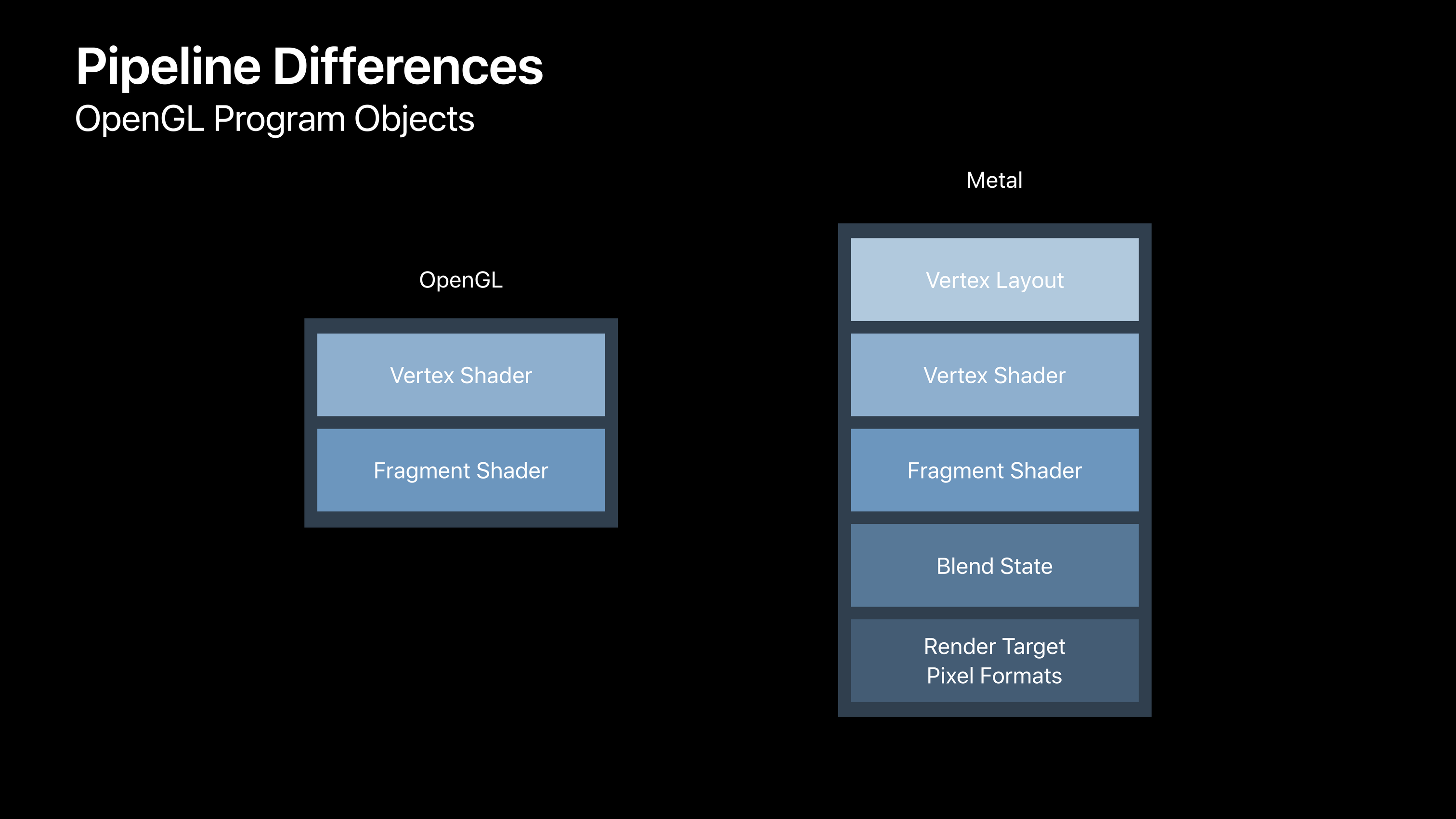
小结
以上资源对象都需要付出昂贵的开销。
Pipeline 创建需要后台编译,Texture 和 Buffer 需要分配内存。因此这些操作应尽可能在初始化时一次性操作。
渲染时
初始化结束以后,程序将会进入主题 —— 渲染循环。
在 Metal 中,命令系统对渲染循环进行了封装。开发者们只要在一个渲染循环内将要做的事编码成命令后丢入命令队列即可。
命令
上文中已经介绍了 Metal 中的四种命令,它们都派生自同一个父类,它们的使用方法是一样的。一个完整的命令执行闭环是这样的:
- 使用 CPU 进行命令编码,放入编码队列等待执行。
- 等待过程中,开发者可以选择阻塞 CPU,或让 CPU 去做别的事情。
- GPU 按次序执行命令,执行完毕释放阻塞或通过闭包回调 CPU。
阻塞式的完整的闭环实现如下:
id<MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer];
// 编码命令...
[commandBuffer commit];
[commandBuffer waitUntilCompleted];
非阻塞式的闭环实现如下:
id<MTLCommandBuffer> commandBuffer = [commandQueue commandBuffer];
// 编码命令...
commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> commandBuffer) {
// 回调 CPU...
}
[commandBuffer commit];
当然,非阻塞的使用方法更值得推荐。以下是一种推荐使用的资源三重缓冲的模式,利用回调来使 CPU 和 GPU 更高效地配合。
资源更新
创建三帧的资源缓冲区来形成一个缓冲池。CPU 将每一帧的数据按顺序写入缓冲区供 GPU 使用。
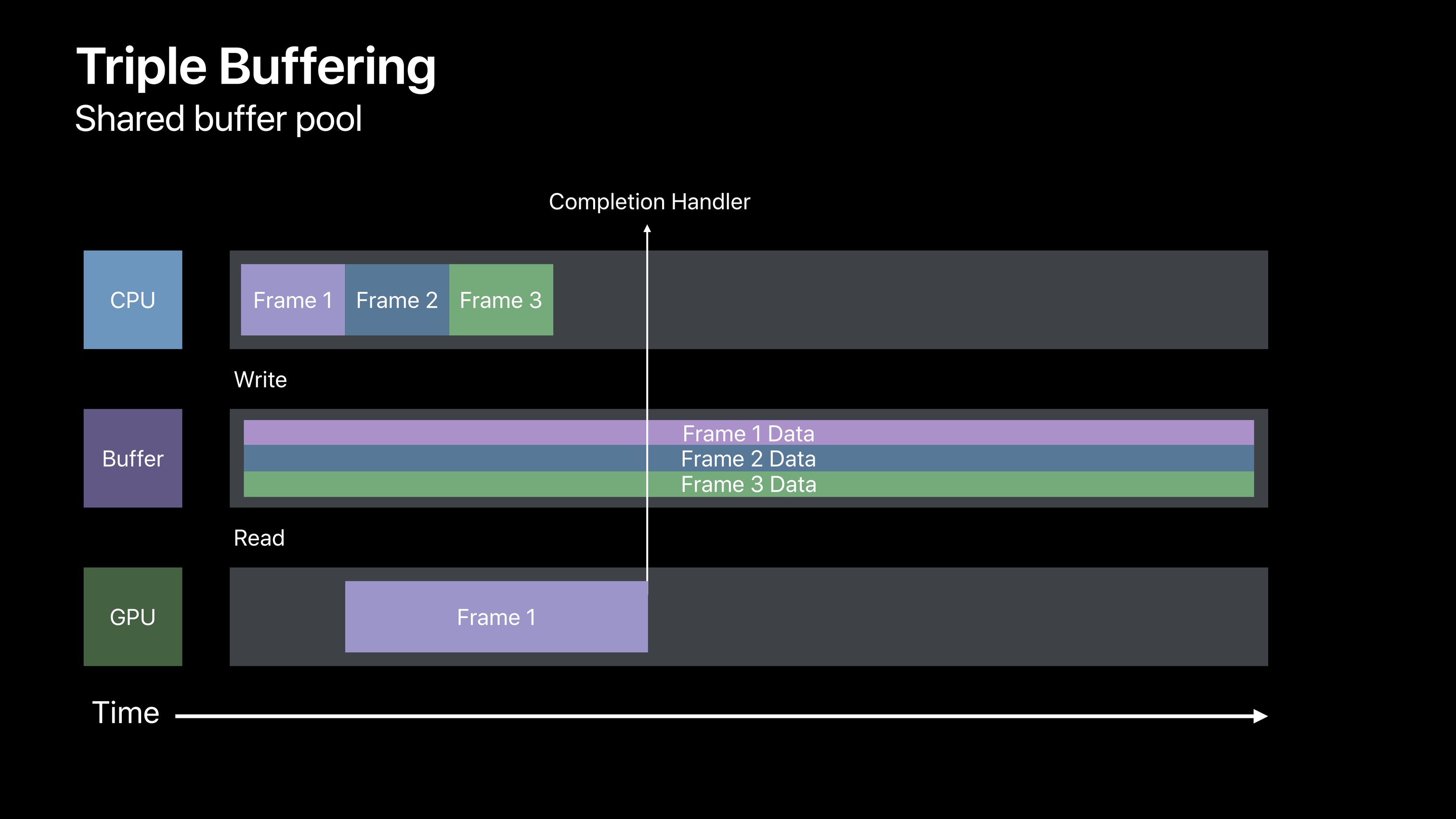
当 GPU 触发回调时,CPU 将释放该帧的缓冲区,并于下一帧使用。
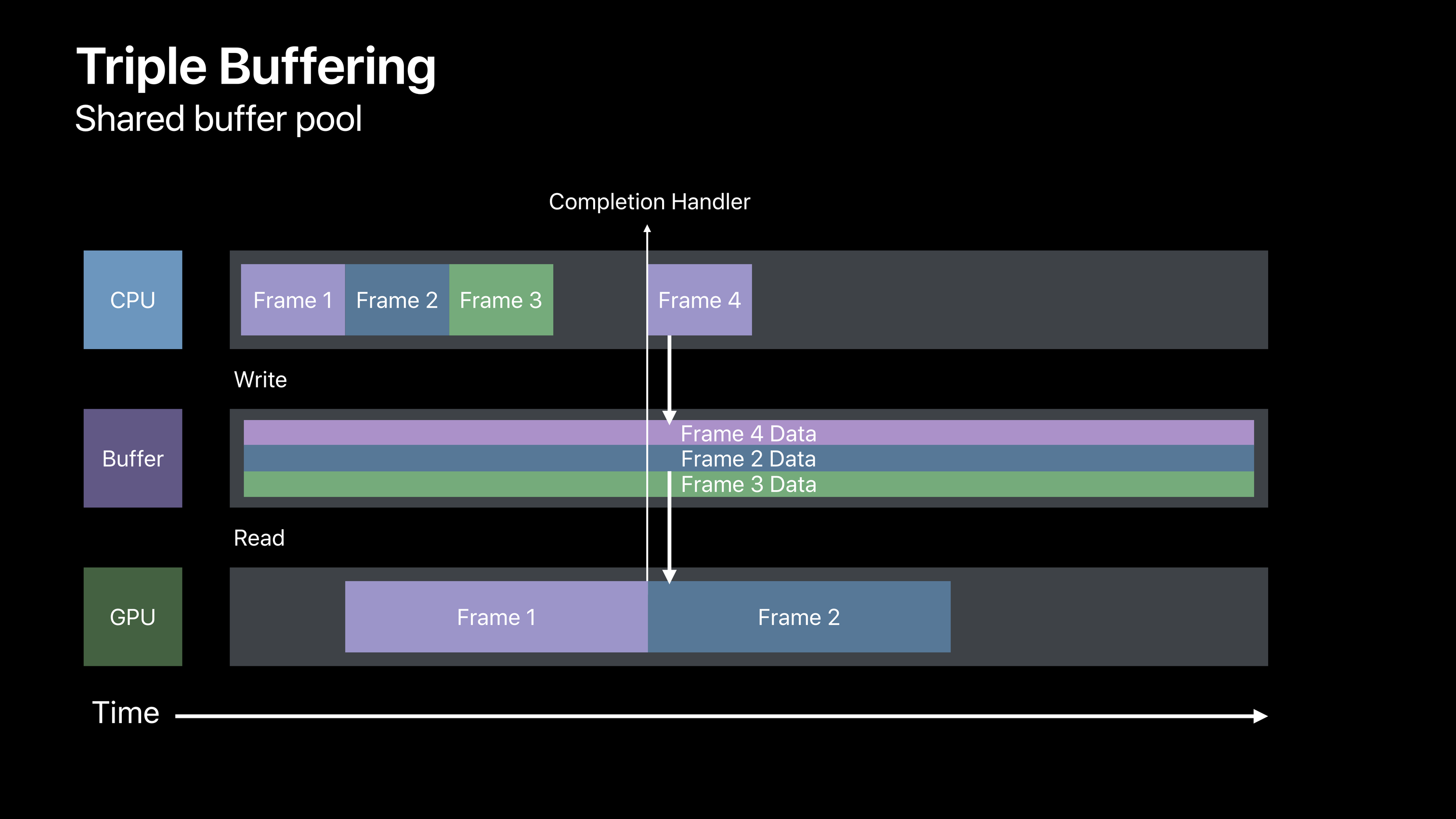
以此来减少 GPU 和 CPU 互相等待的环节,提高性能。三重缓冲的实现如下:
首先构造缓冲区以及信号量:
id <MTLBuffer> myUniformBuffers[3];
dispatch_semaphore_t frameBoundarySemaphore = dispatch_semaphore_create(3);
NSUInteger currentUniformIndex = 0;
在渲染循环中通过信号量来实现三重缓冲的循环。
dispatch_semaphore_wait(frameBoundarySemaphore, DISPATCH_TIME_FOREVER);
currentUniformIndex = (currentUniformIndex + 1) % 3;
[self updateUniformResource: myUniformBuffers[currentUniformIndex]];
[commandBuffer addCompletedHandler:^(id<MTLCommandBuffer> commandBuffer) {
dispatch_semaphore_signal(frameBoundarySemaphore);
}];
[commandBuffer commit];
以上就是 Apple 推荐的资源更新方式。
渲染
在有了资源的更新方式以后,就要进行渲染了。
渲染命令和渲染管线的状态息息相关,因此在创建渲染命令以前需要知道渲染管线的状态。开发者们可以通过一个状态描述对象来描述渲染管线的状态。

由渲染管线状态获得渲染命令编码器的实现如下:
MTLRenderPassDescriptor * desc = [MTLRenderPassDescriptor new];
desc.colorAttachment[0].texture = myColorTexture;
desc.depthAttachment.texture = myDepthTexture;
id <MTLRenderCommandEncoder> encoder = [commandBuffer renderCommandEncoderWithDescriptor: desc];
GPU 渲染图像的步骤大致可以分为:加载、渲染、存储。开发者可以指定这三个步骤具体做什么事。
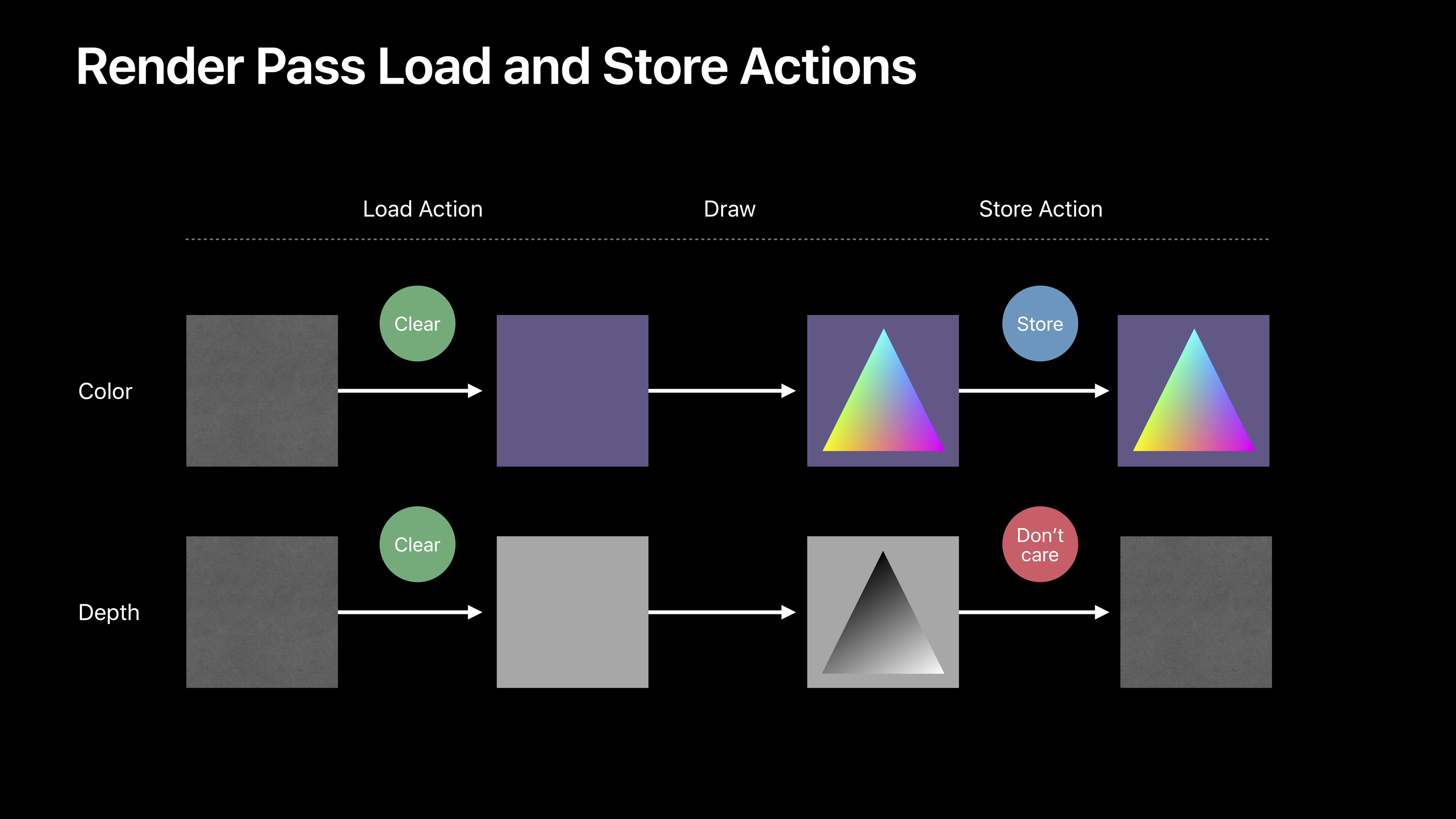
经过这个步骤会得到最终的图像。注意途中的深度缓冲区在存储步骤时候被标记为了 Don't care,结果会被抛弃(discard),不会被存储。
是否需要抛弃随图像渲染的用途而定,如果是用于显示的图像,那么深度信息已经没有用了,没有必要被存储。而如果是用于其他表面贴图或是用于后处理,深度信息可能仍然有用,需要存储下来。
存储的步骤是相对昂贵的,因为显存带宽是非常宝贵的资源,因此应该尽可能抛弃不必要的数据。
如何指定这三个步骤的行为呢?
MTLRenderPassDescriptor * desc = [MTLRenderPassDescriptor new];
desc.colorAttachment[0].texture = myColorTexture;
// 指定三个步骤的行为
desc.colorAttachment[0].loadAction = MTLLoadActionClear;
desc.colorAttachment[0].clearColor = MTLClearColorMake(0.39f, 0.34f, 0.53f, 1.0f);
desc.colorAttachment[0].storeAction = MTLStoreActionStore;
id <MTLRenderCommandEncoder> encoder = [commandBuffer renderCommandEncoderWithDescriptor: desc];
显示
在经过一系列绘制命令以后,图像已经被离屏绘制到了一个 Texture 上。那么如何把图像最终显示在屏幕上呢?
关于显示的容器,Apple 为开发者提供了MTKView,这是一个来自MetalKit的视图。这个视图包含了一个 drawable 对象。对于CoreAnimation的开发者来说 drawable 这个概念应该不会陌生。
有了这个视图,就可以用于显示 Texture 上的图像了。
MTLRenderPassDescriptor* renderPassDescriptor = view.currentRenderPassDescriptor;
id <MTLRenderCommandEncoder> renderCommandEncoder =
[commandBuffer renderCommandEncoderWithDescriptor:renderPassDescriptor];
// 编码渲染命令...
[renderCommandEncoder endEncoding];
[commandBuffer presentDrawable:view.currentDrawable];
[commandBuffer commit];
最终使用 Command Buffer 的presentDrawable方法即可。
当这个命令被 GPU 执行完成以后,就能看到图像被显示在屏幕上了。
小结
本节从 Metal 渲染图像的构建时、初始化时以及渲染时三个步骤详细描述了 Metal 渲染图像的流程。经过本节,相信大多数读者已经清楚 Metal 渲染图像的流程了。
为了更清晰地与 OpenGL 的渲染流程作对比,以下是 OpenGL 和 Metal 渲染图像的流程对比:
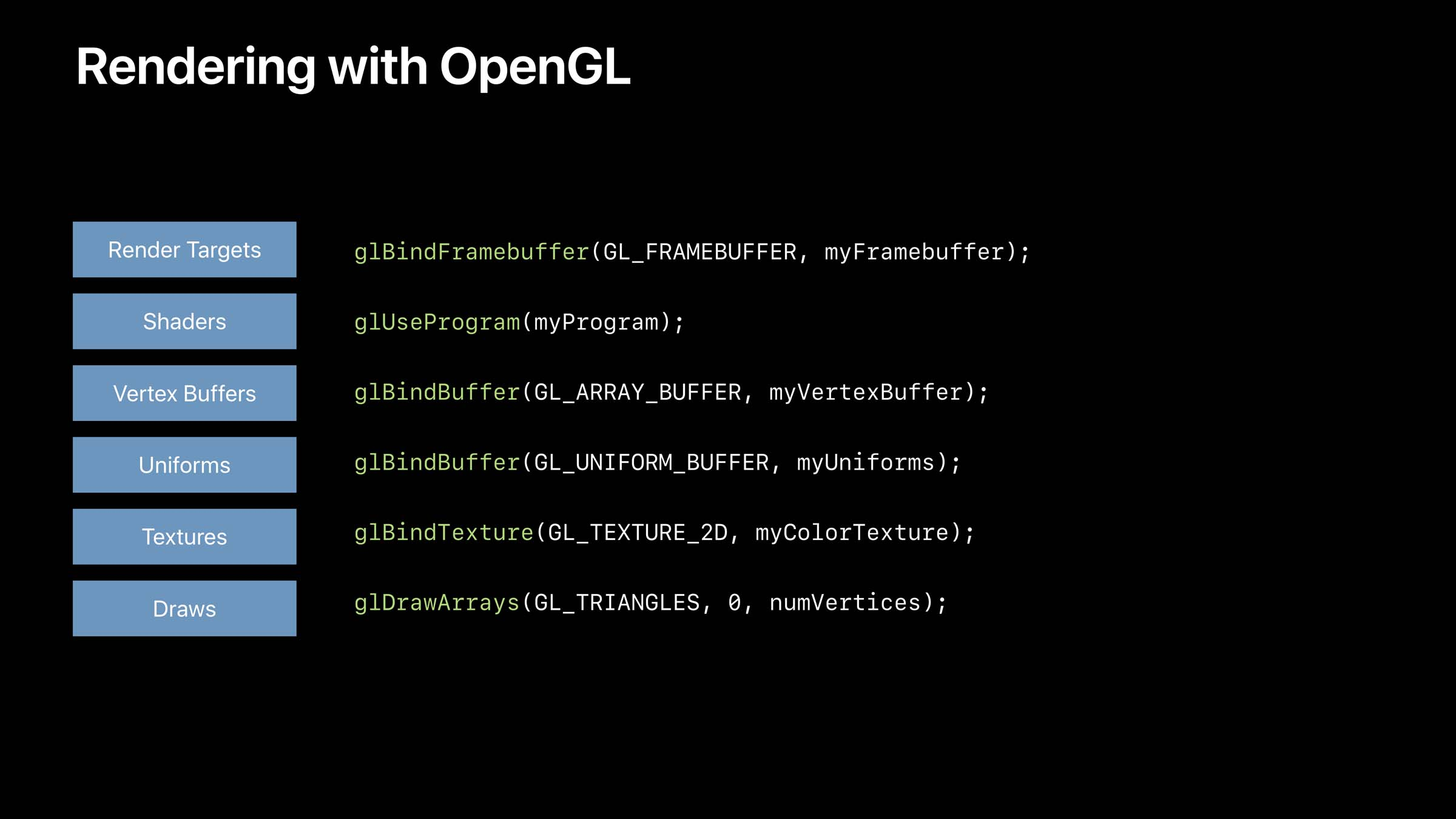

Tips
Metal & OpenGL 混编
虽然 Metal 和 OpenGL 的职能是一样的,但并不意味着程序中只能有 Metal 或 OpenGL 一方。
Metal 和 OpenGL 在程序中可以被混合使用。IOSurface和CVPixelBuffer等数据结构可以提供数据交换支撑。
这意味着开发者们如果想要移植 OpenGL 程序到 Metal,并不需要一口气全部移植过去,因为它们支持混编。
关于混编,开发者们可以参考这里的代码。
多线程编码
由于 Metal 针对 CPU 多线程进行了设计,因此可以尽可能发挥多线程的作用,利用多线程进行命令编码。
Apple 已经为开发者做好了多线程编码的准备工作,开发者可以使用MTLParallelRenderCommandEncoder编码器来进行多线程并行编码。
GPU 计算
Metal 原生支持 GPU 计算。
这意味着许多可以高并发的任务可以通过 Metal 的计算命令交给 GPU 执行了。
在粒子系统,物理模拟等规模比较大的计算任务上,GPU 可以自己计算,自己渲染,在一定程度上解放了 CPU。
调试工具
关于调试工具,Apple 也已经为开发者们准备好了。
GPU 调试器,可用于单步调试:
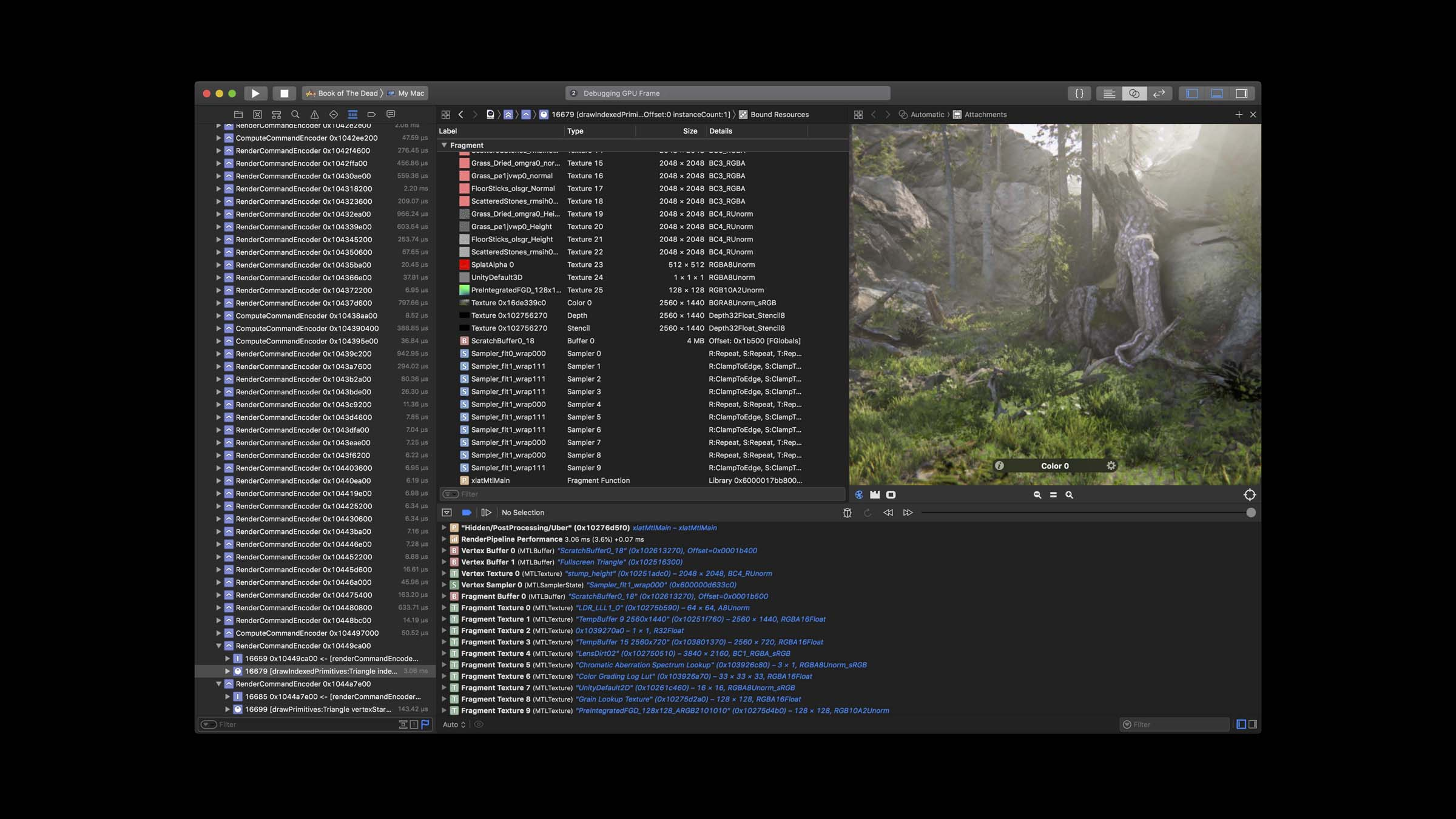
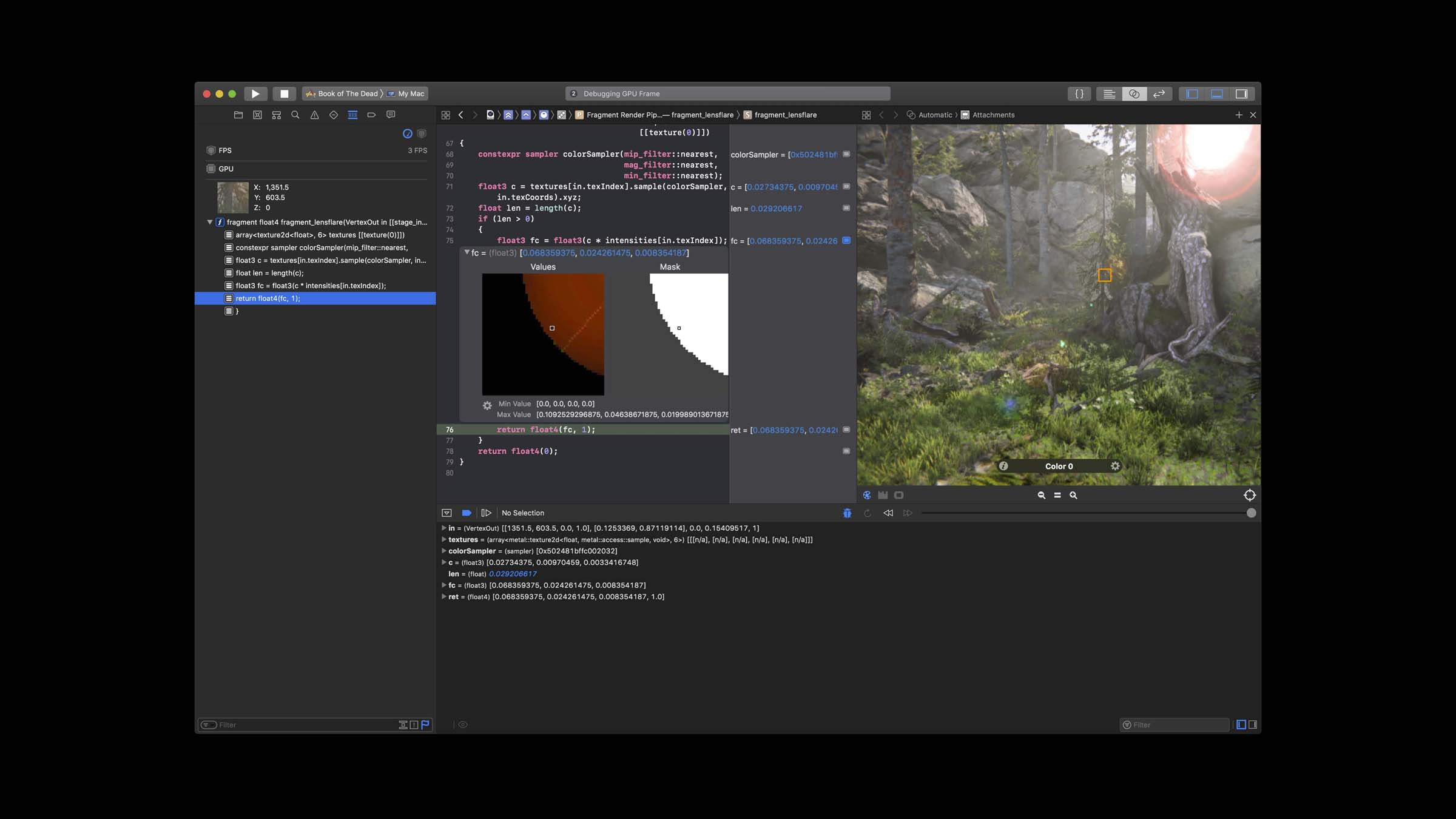
着色器调试器,可像调试普通函数一样调试着色器函数:
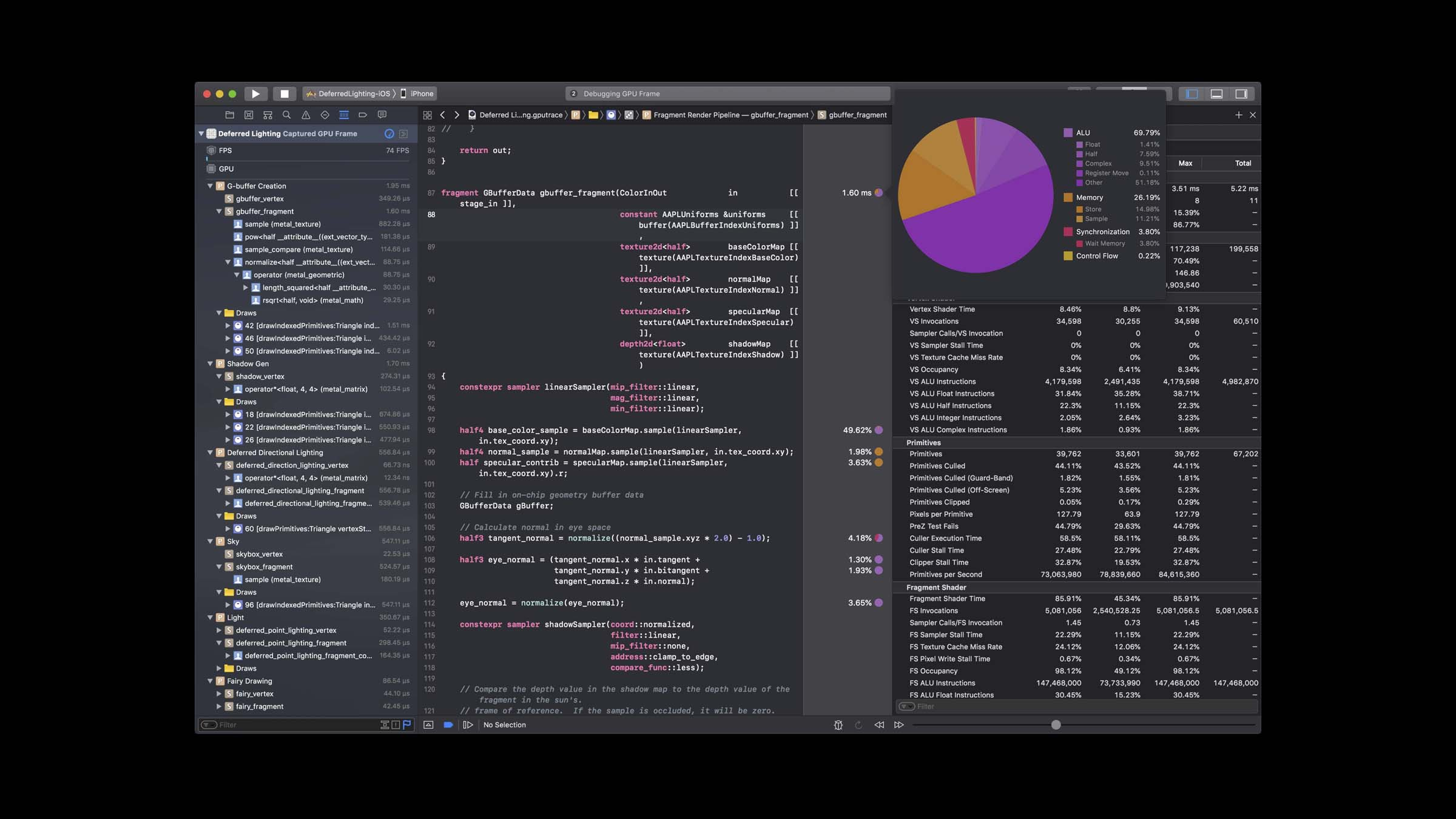
着色器性能调试器:
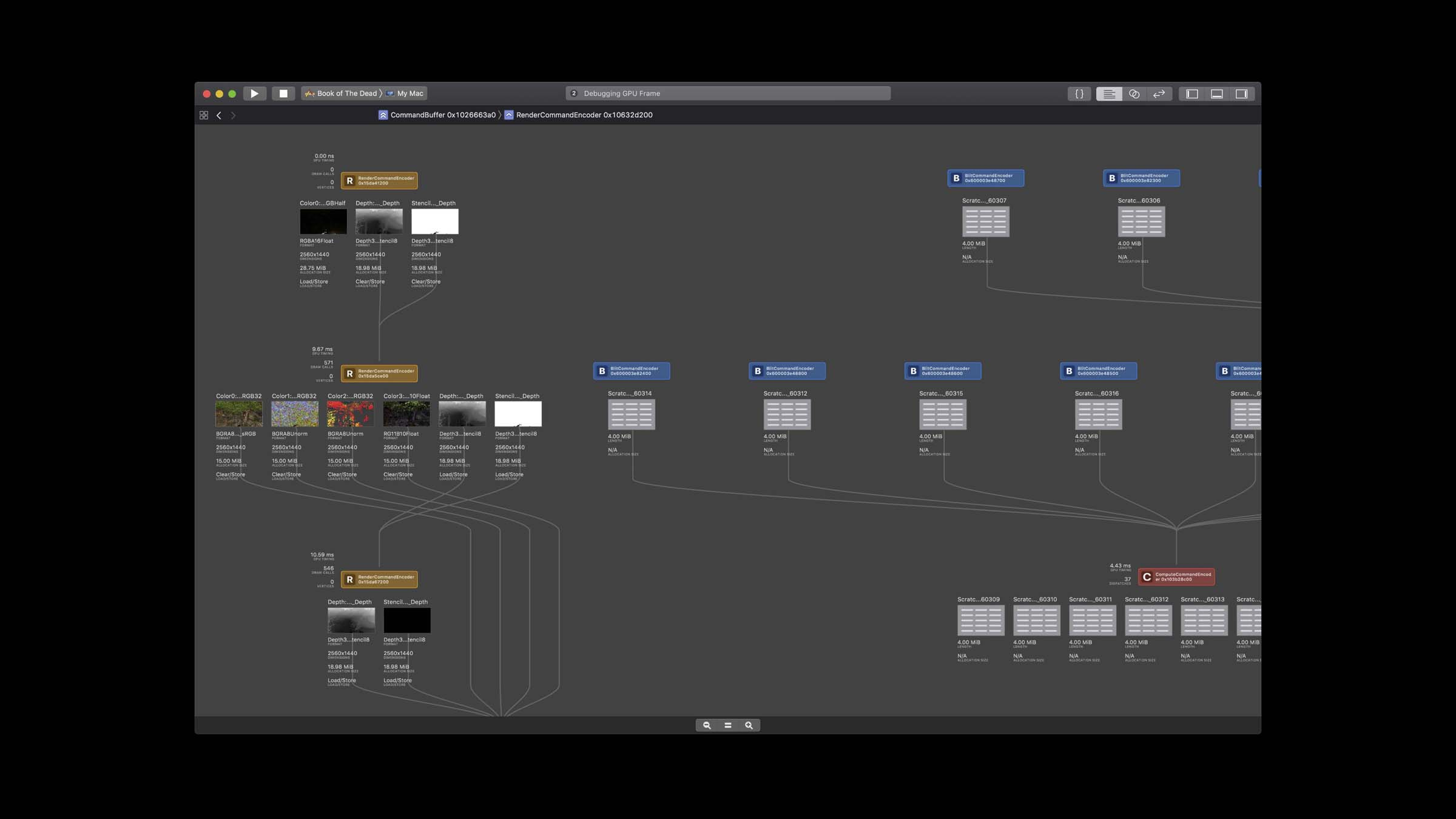
渲染管线调试器:
Metal 追踪调试器,可用于调试 Metal 完整行为:
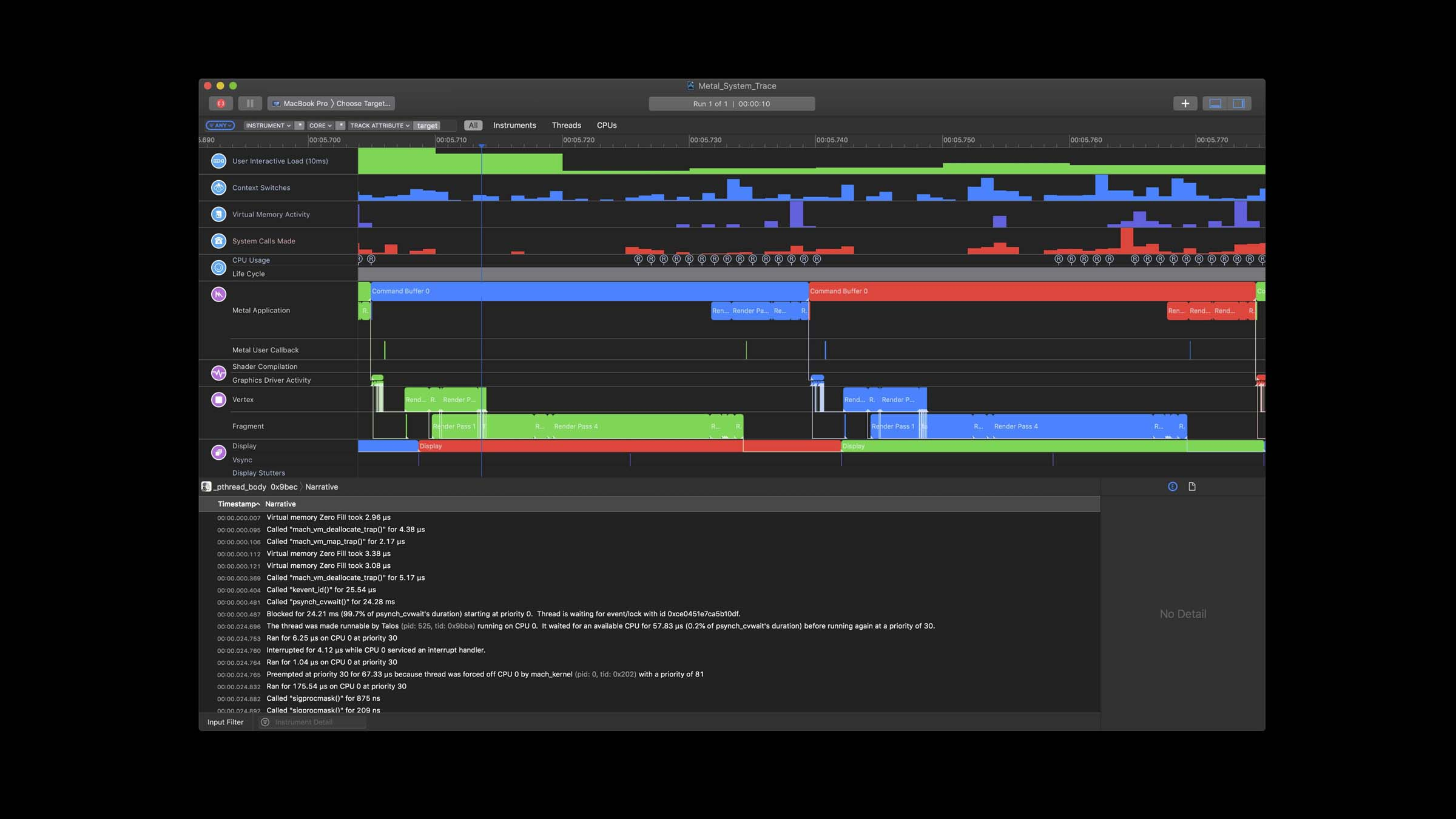
结语
Metal 解决了很多 OpenGL 设计本身存在的问题。它是一款真正为现代设备而设计的图形引擎。它的对象模型,多线程支持经过了精心设计以满足现代开发的需要。经过四年的发展和沉淀,Metal 本身以及配套工具已经日趋成熟。
随着今年 WWDC 苹果宣布 OpenGL 和 OpenCL 被弃用,宣布着 Metal 的时代即将到来。那么,是时候开始使用 Metal 了。
查看更多 WWDC 18 相关文章请前往 老司机x知识小集xSwiftGG WWDC 18 专题目录
