

简介机器学习与TensorFlow.js
从人脸识别到自动驾驶,从机器翻译到游戏AI,机器学习已经是如今计算机应用领域当仁不让的明星。其只需改变训练所用的数据集即可适应不同的应用场景的特性,更是让论者如 Pedro Domingos 期待这条路的终点或可找到能够彻底理解世界规律的“终极算法”。一直以来,这个重要的领域由 Python 和 C++ 主导。前者是数据科学家的万能胶水,后者则承担着对接硬件与优化性能的苦工。但是近年来业界不断爆出数据安全和隐私丑闻,使得人们对于服务提供者是否有能力保护其受托代管的数据,以及是否有足够自律不滥用数据,心生疑虑。缓解这种疑虑的一种方法是在客户端处理用户数据,而不将数据上传到别处。但如果想要在客户端利用用户的数据来优化模型,又没有如谷歌或苹果那样对客户端平台的垄断地位,就必须使用 JavaScript 的运行环境。 TensorFlow.js 应运而生。
根据 StackOverflow 的调查数据,JavaScript 已经连续六年蝉联用户最多的编程语言。但是由于 JavaScript 原本设计用于浏览器环境,即使有了可在服务器上运行的 Node.js ,其开发者生态也多偏重网页应用,并未重视机器学习领域。希望 TensorFlow.js 能够将机器学习的威能带给 JavaScript 开发者,也将 JavaScript 社区的多样化融入机器学习社区,交流提高。
本文接下来从机器学习的基本概念开始,简单介绍 TensorFlow.js 的使用方法,并介绍如何用 TensorFlow.js 与一个已经训练好的图像分类模型,利用一种叫做迁移学习的方法,在客户端利用用户数据,实现一个用摄像头控制的《吃豆人》游戏。
简介机器学习基本概念
机器学习是人工智能分支中的一支。与人工智能类似的概念,最早在 Ada Lovelace 的书信中就有提及,可说是从襁褓就伴随着计算机科学的关键领域。在探索如何用计算来模拟智能的征途上,学界提出了三条路径:模拟理性思维;模拟学习能力;模拟智能行为。机器学习即是来自第二条路上的成果。它旨在让计算过程模拟人类获取知识的学习过程,从大量经验数据中总结出规律。某种程度上,它是对统计学回归方法的延伸扩展。
现代机器学习大部分是围绕张量(Tensor)进行的。张量是对标量(即单个数字)和向量(亦可理解为数组)的逻辑延伸;标量是零维张量,向量是一维张量。在此之上则有二维张量(矩阵),三维张量(矩阵组)等。在机器学习的实际应用中,通常使用向量描述模型的输入,如一张黑白图片中的所有像素的灰度值;使用标量或向量描述模型的输出,如输入图片的意义是数字“1”的概率。
目前机器学习使用的主流数据结构是神经网络。名符其实,神经网络是从人脑的神经元连接网络中获取灵感,将统计学回归过程连接成一个网络。如图所示:
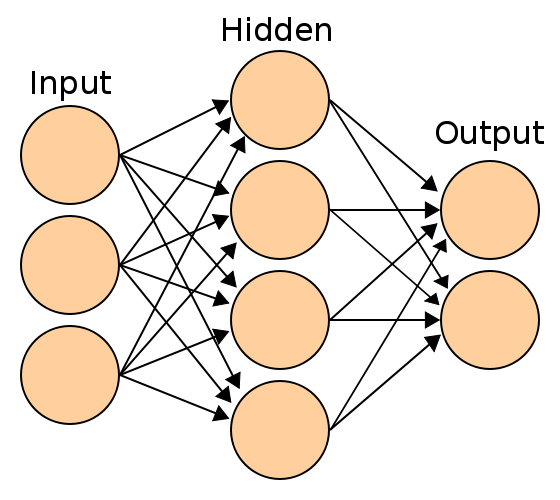
上图中,输入层和输出层各自由一个一维张量表示。输入和输出的每一个节点可以根据需要解决的问题不同,拥有的数据不同,需要的输出不同,而表达不同的意义。在经典手写识别问题 MNIST 中,输入是一张含有手写数字的黑白图片中所有像素的灰度值,而输出是数字“0”到数字“9”的概率。
神经网络的隐藏层是其关键。在隐藏层的节点中,对于每一个连接,会进行线性组合,但是组合的结果会再输入到一个非线性函数中,以模拟神经元的激发。这个非线性函数同线性组合以及神经网络的结构一起,使得整个神经网络得以近似各种各样复杂的函数,以作出识别人脸、下围棋等看上去富含智慧的行动。一般将这个非线性函数称为激活函数。
图中可见每一层的每一个节点都同下一层的每一个节点相连,因此输入层和隐藏层之间有 3 * 4 = 12 个连接,而隐藏层和输出层之间有 4 * 2 = 8 个连接。层与层之间的连接即是以二维张量(矩阵或二维数组)表示,可以方便地通过前一层的节点编号和下一层的节点编号来获取连接的权重。更重要的是,利用张量表示法,可以利用硬件加速的线性代数运算来显著加快训练模型和运行模型的速度。
简介机器学习模型的训练
请回想一下自己记忆一个书本上新知识点的过程。这个过程可能是这样:在阅读几遍后,尝试默背知识点的内容,然后对照书本上原来的内容,发现不同之处,再加以修正。机器学习即是模仿这个过程。书本上的内容即输入,记忆后再回想起的内容即输出,在这个特殊的例子中,书本上的内容也同时是标准的输出。训练一个机器学习模型的过程像是这样:将输入放入神经网络,得到其输出,测量网络输出和标准输出之间的偏差,再根据偏差修正网络中的权重。一般将这一过程中所用到的输入和标准输出统称为训练用数据,将用来测量偏差的工具称为损失函数,将根据偏差修正权重的过程称为反向传播。
损失函数和反向传播的过程是紧密相连的。如同记忆知识点时希望将知识点完整正确地记住,反向传播的目的是通过调整网络权重,来将损失函数的值降到最低。因此反向传播问题可以认为是一个求函数最小值的问题。这一问题在这里采用的解法是随机梯度下降。请想象一片地貌,有平原、山脉、丘陵和盆地。如果将这一片地貌近似地看作以经度和纬度为参数,以海拔高度为输出的函数,那么梯度就是读者坐在地貌的任一点上,受重力作用滑动的方向。随机梯度下降,就是随着重力滑到地貌的最低点的过程。读者可能已经想到一些这个过程中可能发生的问题,但限于笔者智识及本文篇幅,无法详述,惭愧。
进行随机梯度下降的过程中,有一个不得不考虑的细节。神经网络的运算是由一个个节点的运算组成,因此梯度下降需要修正每个节点之间连接的权重,但是损失函数只描述神经网络整体的输出偏差。如何让损失函数参与到每个节点的修正中呢?其实,损失函数包含神经网络的输出函数,而网络整体的输出函数包含每个节点的激活函数。因此,求损失函数相对于输入数据的梯度时,由于链式法则,其实已经需要对每个节点的激活函数也求导数。这样,在输出层计算的损失函数的梯度,就通过链式法则一层一层向输入层,即反向,传播回去,在途径每一层时修正那一层与前一层的连接权重。这也就是反向传播之名的由来。
利用节点的激活函数导数修正权重是训练机器学习模型中运算量最大的操作,因此学界一直致力于找到更有效率的激活函数。传统上学界使用的是与统计学中的指数回归相同的 Sigmoid 函数,其导数正好是 sigmoid * (1 - sigmoid) ,易于计算。近期的新成果则普遍采用一个分段函数,f(x) = x 如 x ≥ 0; 否则 f(x) = 0,名之线性修正单元(ReLU)。它放弃不太重要的在 0 处的连续性,在 ≥0 时导数就是 1 ,无需计算,在不影响训练结果的前提下,显著加快了训练速度。
回到记忆知识点的类比,当知识点已经记住,修正就不再必要,学习的过程也就告一段落。对于机器学习而言,如果损失函数降到一个谷底无法再降,也标志着训练的告一段落。训练是否真的成功,还要看训练得到损失函数值是否达标。就如同考试不及格需要继续学习补考,机器学习的结果如果不及格,也要回头反省,调整再来。
简介 TensorFlow.js 与迁移学习
TensorFlow.js 是 TensorFlow 库在 JavaScript 中的实现。目前其后端支持 CPU 加速和 GPU 加速,前者对接的是 V8 及 Node.js 运行环境,而后者对接的是 WebGL 接口,性能约是原本 C++ 后端的一半。对于原本 C++ 后端的支持会稍后推出。不过考虑到在客户端浏览器中应用的场景,不说 C++ 后端难以部署到客户端,就是能够使用,以客户端的硬件性能,也无法用来训练大规模的模型。 TensorFlow.js 的主要用法应当是以利用已经训练好的模型为主。 TensorFlow.js 对利用已有模型的支持十分到位,可以转译任意的 Keras 的模型为一个 JSON 文件导入,感兴趣的读者可以参照官方网站的示例尝试。
已经训练好的模型用处虽有,但不能适应用户的使用习惯来提供更好的服务。在不重新训练整个模型的前提下,要在客户端将数据整合到模型当中,就需要迁移学习。简而言之,迁移学习是取来已经训练好的模型,砍掉最后的几层,暴露出原本的一个隐藏层,在其上嫁接一个简单得多的模型,在客户端中只训练嫁接上去的部分,而得到的一个新模型的过程。新的模型可以有与原来的模型完全不同的输出层。比如在《吃豆人》的示例中,利用了为移动终端优化的小型图像分类模型 MobileNet ,其原本的输出层是上万个图像类别的概率,在示例中则被嫁接上了一个仅仅输出四个方向操作的概率的输出层。
这样的做法可以奏效,是由于 MobileNet 的隐藏层包含了输入图像中的规律。 MobileNet 是一个卷积神经网络。卷积神经网络是为了图像处理而设计的。上文所描述的前馈神经网络在应用到图像上时,由于其隐藏层每一节点与前一层所有节点全部连接,在处理常常是上万、十万甚至百万图像像素的输入层时,连接的数量呈指数级增长,计算需求太大。卷积神经网络吸取了对动物大脑视觉处理区域的研究成果带来的灵感,其隐藏层并非每个节点全部连接到前一层的所有节点,而是仅连接到前一层对应的一部分节点,这种对应连接表现为一个隐藏层中的每个像素与前一层位置对应的一个边长几像素的正方形窗口相连接。这个窗口被称为卷积核。比如,某一隐藏层的 (1,1) 像素与前一层从 (0,0) 到 (2,2) 的边长为 3 个像素的正方形窗口相连接; (1,2) 与 (0,1) 到 (2,3) 相连接;以此类推。这样,上一层对应的窗口中出现的图形规律,比如是否出现物体的边缘,就可以被隐藏层捕捉到。由于捕捉的结果经常像是在原图上加了滤镜,所以卷积核也称为卷积滤镜。在 MobileNet 的隐藏层上嫁接一个小模型,小模型就可以通过很少的训练,化隐藏层所提取出的图像的规律为己用。
接下来笔者按顺序摘取几段重要的示例代码,展示 TensorFlow.js 的实际应用。示例代码来自 TensorFlow.js 官方 Github 仓库。以下代码来自其中的 index.js 文件。为了简洁,笔者省略了一些代码中原本的英文注释。
- 示例代码最新链接:github.com/tensorflow/…
- 本文基于的
index.js文件版本链接:github.com/tensorflow/…
// [第18行]
import * as tf from '@tensorflow/tfjs';
新的 JavaScript 标准已经支持在浏览器环境中使用模块系统和 import 语句。此处将 TensorFlow.js 的接口导入到 tf 名下。
// [第39行]
async function loadMobilenet() {
const mobilenet = await tf.loadModel(
'https://storage.googleapis.com/tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json');
// Return a model that outputs an internal activation.
const layer = mobilenet.getLayer('conv_pw_13_relu');
return tf.model({inputs: mobilenet.inputs, outputs: layer.output});
}
此处使用 loadModel 函数从 URL 中读取 JSON 文件形式的模型数据,并从中加载模型。然后,使用 getLayer 函数获得指向中间隐藏层的变量,再用 tf.model 截取从输入层到隐藏层的模型,并返回截取的结果。另外值得注意的是,示例代码使用 async / await 语法来书写异步指令。 async 用以标记返回异步结果的函数,而 await 用来等待 async 函数完成,获取其结果。
// [第26行]
const NUM_CLASSES = 4;
// [第35行]
let model;
// [第64行]
async function train() {
// [第72行]
model = tf.sequential({
layers: [
tf.layers.flatten({inputShape: [7, 7, 256]}),
tf.layers.dense({
units: ui.getDenseUnits(),
activation: 'relu',
kernelInitializer: 'varianceScaling',
useBias: true
}),
tf.layers.dense({
units: NUM_CLASSES,
kernelInitializer: 'varianceScaling',
useBias: false,
activation: 'softmax'
})
]
});
// [...]
}
此处用 tf.sequential 来创建一个新的仅有三层的模型。
- 第一层是用
tf.layers.flatten创建的对接 MobileNet 隐藏层的输入层; - 第二层是用
tf.layers.dense创建的隐藏层,使用的激活函数是 ReLU ; - 第三层是用
tf.layers.dense创建的对应上下左右四个方向控制的输出层,使用的激活函数是 Softmax 。
async function train() {
// [第97行]
const optimizer = tf.train.adam(ui.getLearningRate());
model.compile({optimizer: optimizer, loss: 'categoricalCrossentropy'});
// [...]
}
此处指定模型的反向传播算法和损失函数。此处使用的反向传播算法, tf.train.adam ,是随机梯度下降的一个优化版本。此处使用的损失函数是 Categorical Cross Entropy ,是分类问题的经典损失函数,用在将图像分成上下左右四类的示例中十分合适。
async function train() {
// [第115行]
model.fit(controllerDataset.xs, controllerDataset.ys, {
// [...]
});
}
此处用 model.fit 启动模型训练,传入训练用数据和一些本文没有涉及的工程上的参数,因此省略。
// [第129行]
async function predict() {
ui.isPredicting();
while (isPredicting) {
const predictedClass = tf.tidy(() => {
const img = webcam.capture();
const activation = mobilenet.predict(img);
const predictions = model.predict(activation);
return predictions.as1D().argMax();
});
const classId = (await predictedClass.data())[0];
predictedClass.dispose();
ui.predictClass(classId);
await tf.nextFrame();
}
ui.donePredicting();
}
此处开始利用上文训练好的模型来将摄像头拍到的画面分类到上下左右其中一类。
- 用
webcam.capture来获取摄像头的画面。这个函数是由示例中webcam.js模块定义的; - 将画面传入
mobilenet.predict,来获取 MobileNet 的隐藏层结果; - 将 MobileNet 的隐藏层结果传入上文训练好的
model.predict,得到最终的分类结果,上下左右四类的概率; - 用
predictions.as1D().argMax()得到概率最大的分类,作为最终的分类结果;
另外值得注意的是, tf.tidy 和 predictedClass.dispose 这两个函数是用于指导 TensorFlow.js 进行 GPU 内存管理的。传给 tf.tidy 的闭包中的 const 常量如果是 Tensor ,那么就会由 tf.tidy 负责在闭包执行完毕后回收其所占内存。但是 tf.tidy 不能清理掉返回值,因此在用 predictedClass.data 取得模型分类的结果后,需要用 predictedClass.dispose 回收其所占用的内存。 tf.tidy 还要求所接受的闭包不能是异步函数,并且不会清理闭包中的 let 变量。合理使用这两个函数管理内存是优化 TensorFlow.js 实现性能的一个要点。
tf.nextFrame 是 TensorFlow.js 对于 window.requestAnimationFrame 的异步封装,用来与浏览器的重绘时间同步。
结语
本文从机器学习的基础概念开始,简要介绍了张量、前馈神经网络、卷积神经网络、神经网络模型训练、和迁移学习,并以 TensorFlow.js 的《吃豆人》示例项目为例子,简短介绍了实际使用 TensorFlow.js 的代码结构和最佳实践。抛砖引玉,希望本文对大家入门 TensorFlow 与机器学习有所帮助。
注记
- 本文结构及迁移学习的例子来自 Ashi Krishnan 在 JSConf EU 2018 上所作的演讲 Deep Learning in JS 。 如果对于机器学习有兴趣,且英语过关,笔者十分推荐接下来完整观看 Ashi 的演讲,在她鲜明易懂的图例和优美的书法中获得对 JavaScript 中的深度学习更详细的理解。 演讲介绍及 Ashi 的个人简介:2018.jsconf.eu/speakers/as…; 演讲录像:www.youtube.com/watch?v=SV-…。
- 本文涉及的众多知识点及拓展阅读,可参考《最全的 DNN 概述论文:详解前馈、卷积和循环神经网络技术》:zhuanlan.zhihu.com/p/29141828。
- TensorFlow.js 的官方网站:js.tensorflow.org/。
- 本文涉及卷积神经网络的内容可拓展阅读《CS231n Convolutional Neural Networks for Visual Recognition》:cs231n.github.io/convolution…。
