

欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~
本文来自云+社区翻译社,作者HesionBlack
最近我从马克·里德尔 那拿到了很棒的自然语言方面的数据集 :从WIKI下载了112000个故事作品的情节。其中包括了书籍、电影、电视剧集、视频游戏等有“情节”的任何内容。
这为我定量分析故事结构提供了一个很好的契机。在这篇文章中,我将会进行一个简单的分析来检验在故事中的特定情节上,哪些词会频繁出现,比如一些提示了故事开端开始,中间情节或结局的词。
根据我对文本挖掘的习惯,我将使用Julia Silge和我在去年开发的tidytext软件包。如果你想要了解更多相关知识,请参阅我们的这本在线书Text Mining with R: A Tidy Approach,它将很快被O'Reilly出版了。我将为您提供部分代码,以便您可以继续跟上我的思路。为了保持文章简洁,关于可视化部分的代码我基本都没贴出来。但所有的文章和代码都可以在GitHub上找到。
建立
我从GitHub上下载并解压缩了plots.zip文件。然后我们将这些文件读入R,然后将它们与dplyr使用结合。
library(readr)
library(dplyr)
# Plots and titles are in separate files
plots <- read_lines("~/Downloads/plots/plots", progress = FALSE)
titles <- read_lines("~/Downloads/plots/titles", progress = FALSE)
# Each story ends with an <EOS> line
plot_text <- data_frame(text = plots) %>%
mutate(story_number = cumsum(text == "<EOS>") + 1,
title = titles[story_number]) %>%
filter(text != "<EOS>")
然后,我们可以使用tidytext将情节整理为一个简洁的结构,一个词一行。
library(tidytext)
plot_words <- plot_text %>%
unnest_tokens(word, text)
plot_words
## # A tibble: 40,330,086 × 3
## story_number title word
## <dbl> <chr> <chr>
## 1 1 Animal Farm old
## 2 1 Animal Farm major
## 3 1 Animal Farm the
## 4 1 Animal Farm old
## 5 1 Animal Farm boar
## 6 1 Animal Farm on
## 7 1 Animal Farm the
## 8 1 Animal Farm manor
## 9 1 Animal Farm farm
## 10 1 Animal Farm summons
## # ... with 40,330,076 more rows
该数据集包含了超过4000万个单词,112000个故事。
故事开头和结尾部分的单词
约瑟夫坎贝尔提出了名为“hero‘s journey”的分析方法,他认为每个故事都有一致的结构。无论你是否对他的理论买账,假如一个故事在一开头就是高潮开始的或者到了结束却引入了新角色,你可能也会觉得这是很令人诧异的。
这种结构可以用单词的量化结构来表现-- 有些词汇应该被期望在开始时出现,而一些词词则在应该在结尾出现。
一个简单的测量方法,我们将记录每个单词的位置的中值,同时也记录它出现的次数。
word_averages <- plot_words %>%
group_by(title) %>%
mutate(word_position = row_number() / n()) %>%
group_by(word) %>%
summarize(median_position = median(word_position),
number = n())
我们对在少数情节出现并且出现频率比较小的词语不感兴趣,所以我们将筛选出至少出现了2500次的单词,并只对他们进行分析。
word_averages %>%
filter(number >= 2500) %>%
arrange(median_position)
## # A tibble: 1,640 × 3
## word median_position number
## <chr> <dbl> <int>
## 1 fictional 0.1193618 2688
## 2 year 0.2013554 18692
## 3 protagonist 0.2029450 3222
## 4 century 0.2096774 3583
## 5 wealthy 0.2356817 5686
## 6 opens 0.2408638 7319
## 7 california 0.2423856 2656
## 8 angeles 0.2580645 2889
## 9 los 0.2661747 3110
## 10 student 0.2692308 6961
## # ... with 1,630 more rows
例如,我们可以看到,“fictional”这个词大约用了2700次,其中半数出现在故事的前12% - 这表明这个词与开端有很大的关系。
下图展示了与故事开头和结尾关联最大的一些词。
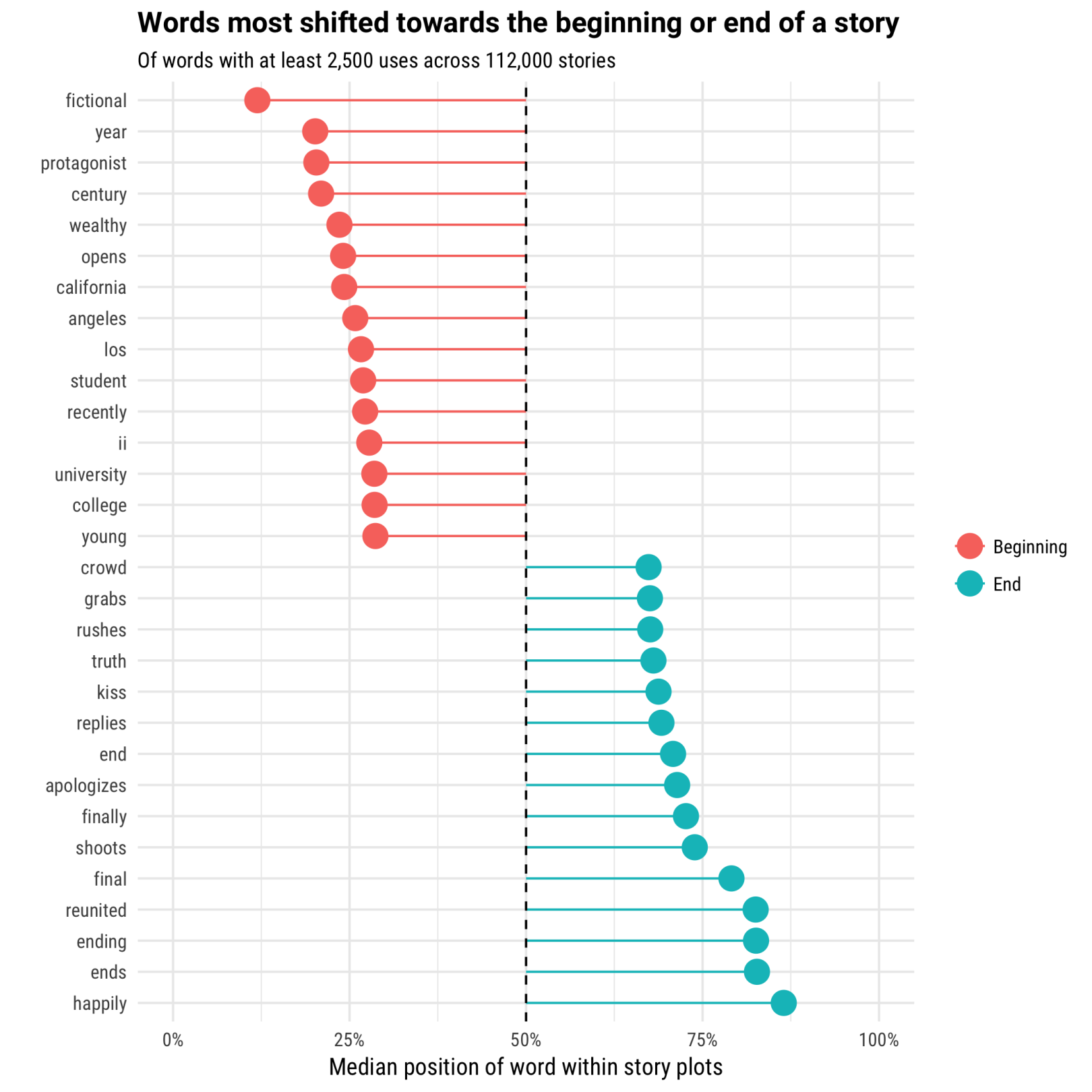
与开头相关的词时常是描述一些设定:“这个故事主角(protagonist),是一个年轻(young),富有(weathy)的 19**世纪(century)的学生(student),最近(rencently)从在美国加利福尼亚州洛杉矶编造的大学(university College)**毕业。它们大部分都是名词和形容词,可以用来描述并限定一个人,一个地点或者一个时期。
相比之下,在故事结尾处的单词就充满情感!有些词本身就有结尾的意思。比如“ending”和“final”,但也有一些动词反映了激烈刺激的情节,比如“英雄向恶棍射击(shoots)并冲向(rushes)女主角,并道歉(apologizes)。两人团聚(reunited),他们吻了(kiss)。“
可视化词汇趋势
中值的方法为我们提供了一个有用的汇总统计信息,让我们仔细研究下统计信息的内容。首先,我们将每个故事分成几个十分位数(前10%,后10%等),并计算每个单词在每个十分位数内的次数。
decile_counts <- plot_words %>%
group_by(title) %>%
mutate(word_position = row_number() / n()) %>%
ungroup() %>%
mutate(decile = ceiling(word_position * 10) / 10) %>%
count(decile, word)
上述工作使我们可以通过绘制不同单词在不同情节的位置中的频率分布。我们想看看哪些单词集中在开始/结束的:
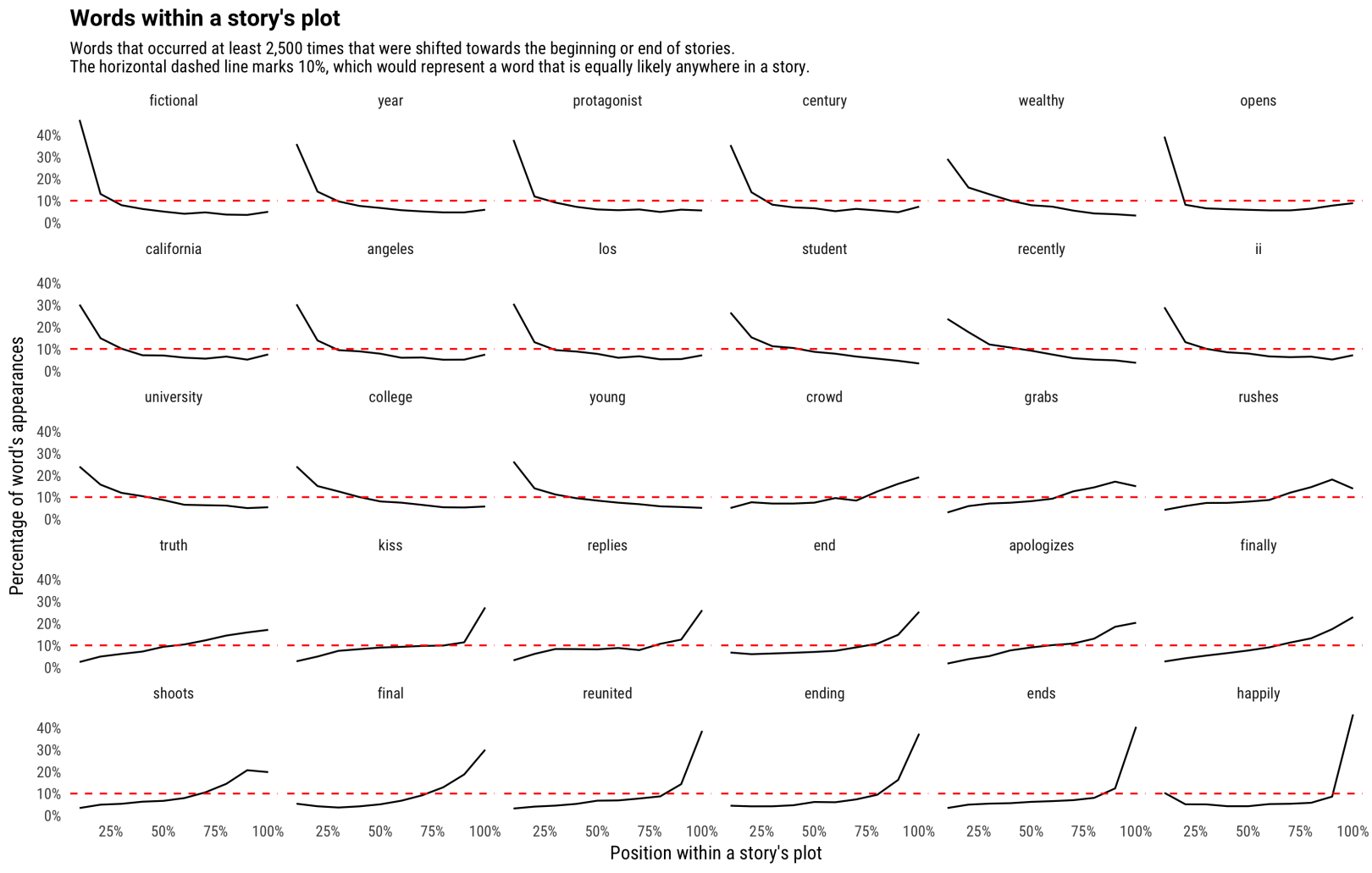
没有任何单词会中只在故事的开始或结束。像“高兴地(happily)”,在全文都稳定出现,但在最后结尾频率飙升(“从此他们过上幸福快乐(happily)的生活”)。其他的词,如“真相(truth)”或“道歉(apologize)”,在故事情节发展的过程中频率不断上升,这很合理。一个角色通常不会在故事开始时就“道歉(apologize)”或“意识到真相(realize the truth)”。类似的,“wealthy”这类描述设定的词出现频率会逐渐下降,就像剧情发展到后面就越不可能引入新的角色一样。
上图种有一个有趣特征,大多数单词出现频率最高的时候是在开始或结束时,但在90%的点上,像“grabs”, “rushes”, 和 “shoots”这样的词在故事的90%部分最常出现,说明故事的高潮一般在这里。
在故事中出现的词语
受到对出现在故事高潮时出现的单词的分析的启发,我们可以观察哪些单词出现在故事情节的中间部分,而不是一直盯着开头和结尾不放。
peak_decile <- decile_counts %>%
inner_join(word_averages, by = "word") %>%
filter(number >= 2500) %>%
transmute(peak_decile = decile,
word,
number,
fraction_peak = n / number) %>%
arrange(desc(fraction_peak)) %>%
distinct(word, .keep_all = TRUE)
peak_decile
## # A tibble: 1,640 × 4
## peak_decile word number fraction_peak
## <dbl> <chr> <int> <dbl>
## 1 0.1 fictional 2688 0.4676339
## 2 1.0 happily 2895 0.4601036
## 3 1.0 ends 18523 0.4036603
## 4 0.1 opens 7319 0.3913103
## 5 1.0 reunited 2660 0.3853383
## 6 0.1 protagonist 3222 0.3764742
## 7 1.0 ending 4181 0.3721598
## 8 0.1 year 18692 0.3578536
## 9 0.1 century 3583 0.3530561
## 10 0.1 story 37248 0.3257356
## # ... with 1,630 more rows
故事的每个十分位数(起点,终点,30%点等)都有一次单词出现的频率很高。哪些词更能代表这些十分位呢?
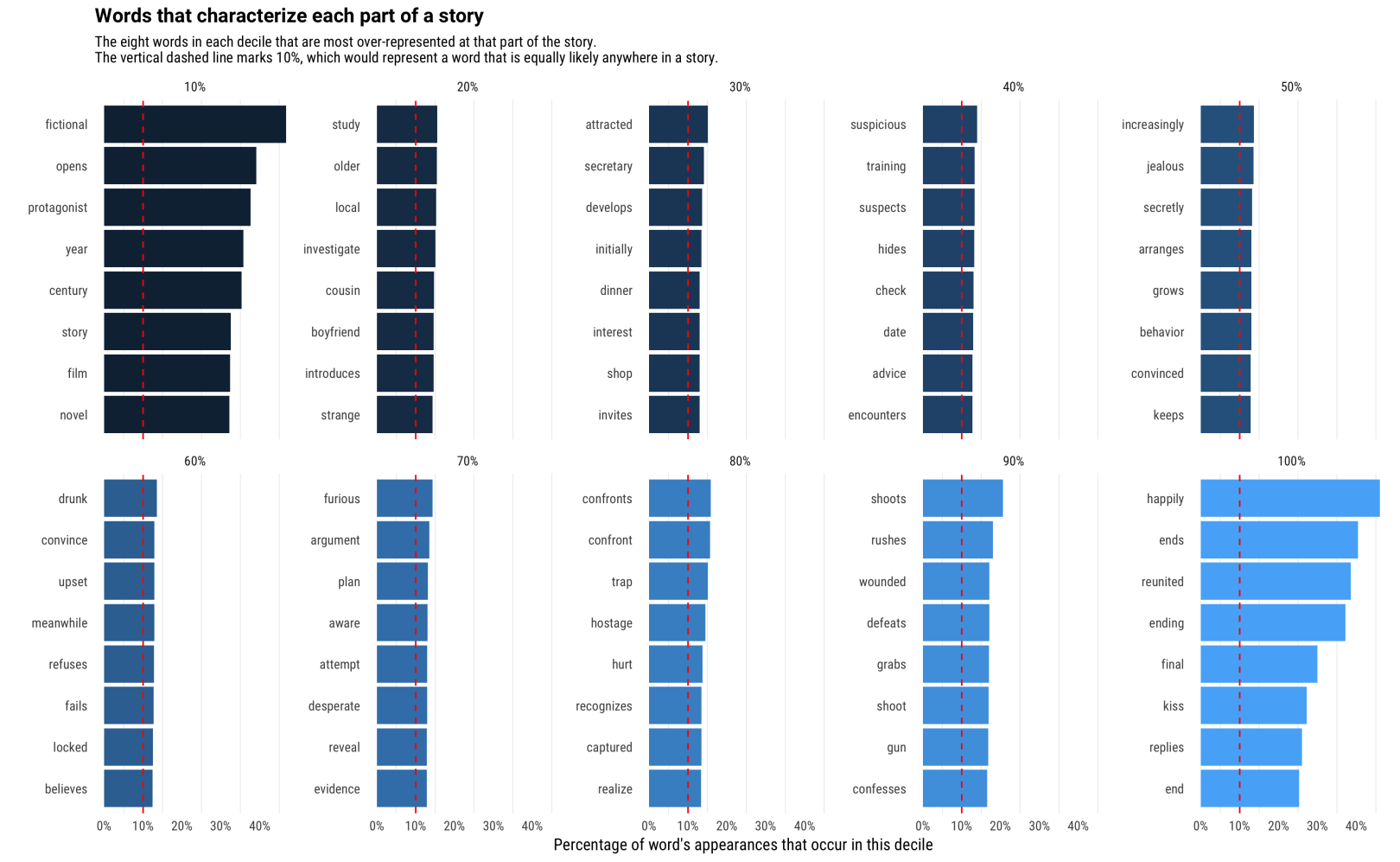
我们观察到,开头和结尾的高频词相对固定。例如,“fictionnal”一词出现在故事的前10%。中间部分的词汇分布的相对分散(比如,在该部分中出现的比例为14%,而不是预期的10%),但它们仍然是故事结构中很有意义的词汇。
我们可以把其中代表性强的单词的完整趋势绘制出来看看。
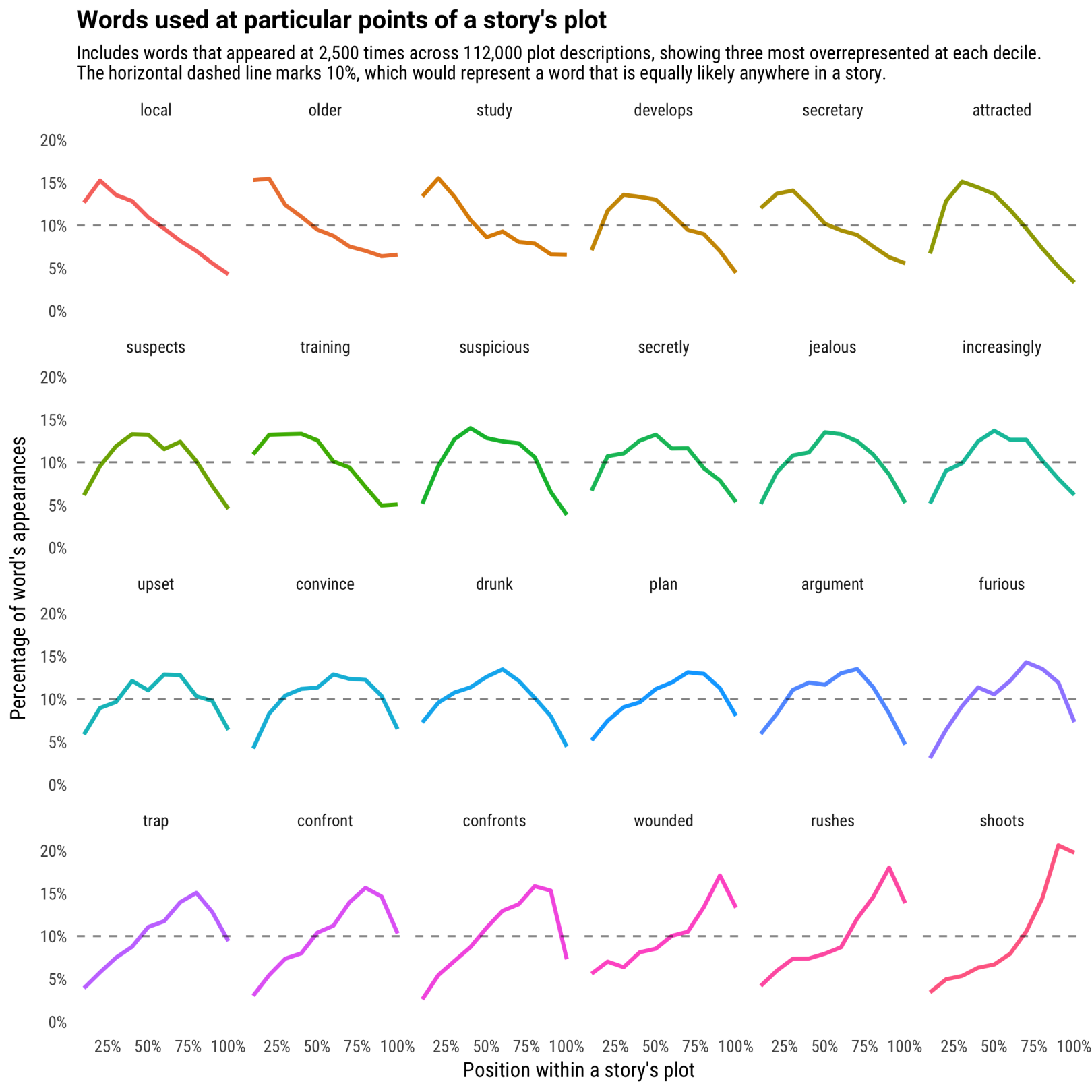
试着分析上图的24个词,我们的主人公被“attracted”, then “suspicious”, followed by “jealous”, “drunk”, and ultimately “furious”. A shame that once they “confront” the problem, they run into a “trap” and are “wounded”.如果你忽略掉哪些重复的词和语法的确实,你可以发现整个故事的趋势可以用这些关键词复述出来。
情感分析
我们关于故事情节中不断上升的紧张局势和冲突的这一假设,得到了证实。可以用情感分析来发现每个故事不同10分位的平均情感得分。
decile_counts %>%
inner_join(get_sentiments("afinn"), by = "word") %>%
group_by(decile) %>%
summarize(score = sum(score * n) / sum(n)) %>%
ggplot(aes(decile, score)) +
geom_line() +
scale_x_continuous(labels = percent_format()) +
expand_limits(y = 0) +
labs(x = "Position within a story",
y = "Average AFINN sentiment score")
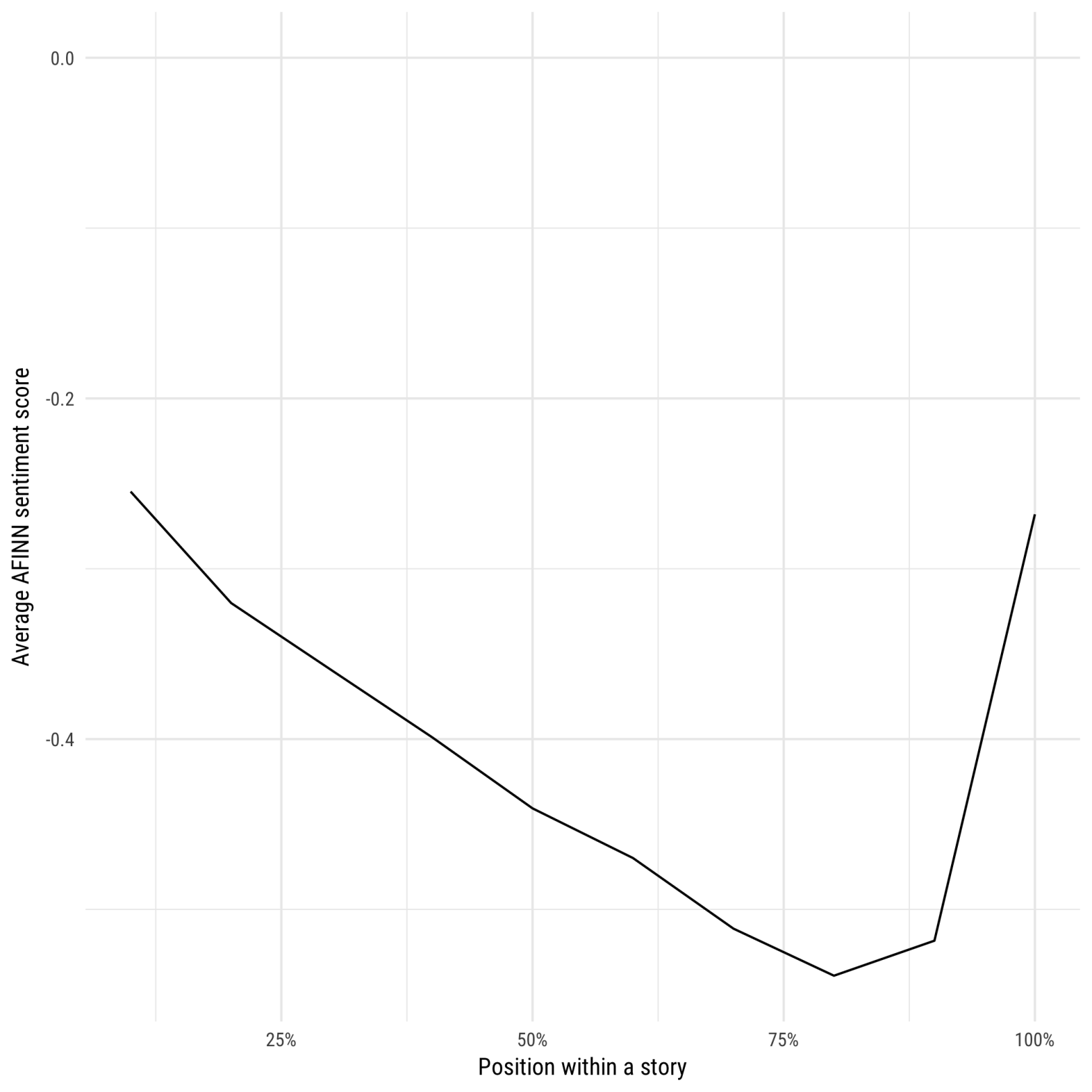
情节描述在故事中的每个部分都计算出了负AFINN分值(这是很有意义的,因为故事是聚焦于矛盾的)。但开头相对平缓一点,然后矛盾开始逐步凸显出来,在80-90%的高潮时。然后通常会有一半的结束,一半包含“快乐(happily)”,“救助(rescues)”和“团聚(reunited)”等词汇,导致得分又变高了。
总而言之,如果我们必须总结出人类撰写的平均的故事结构,那么大致都是“事情会变得越来越糟,直到最后一分钟才出现转机,变得越来越好”这样的情况。
后续
这是对故事情节的简单的分析(需要深入挖掘的例子,参见这些研究),并没有得到齐全的信息,(除了角色可能在故事中期被灌醉。我们如何深入洞悉这些情节)
通过本文我希望你能掌握这些在大型文本据数集上快速量化分析(计数,采用中位数)故事结构的能力。接下来的文章中我会深入挖掘这些情节,来看看我们还能得到哪些信息。
问答
如何使用样本数据或Web服务对NLTK python进行情感分析?
相关阅读
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1142199?fromSource=waitui
欢迎大家前往腾讯云+社区或关注云加社区微信公众号(QcloudCommunity),第一时间获取更多海量技术实践干货哦~
