

机器之心原创,作者:Tony Peng。
美国时间 6 月 18 日,为期五天的计算机视觉(CV)三大顶级会议之一的 CVPR 2018 在美国犹他州首府城市盐湖城(Salt Lake City)拉开序幕。虽然不是大会的第一个正式日,但当日的 26 个研讨会(Workshop)以及 11 个挑战赛也足够让现场的数千名参会者饱足眼福。
机器之心现场记者挑选并总结了几个值得关注的研讨会内容,于第一时间和读者分享。
前伯克利 CS 系主任 Jitendra Malik:研究 SLAM 需要结合几何和语义
在今年的 CVPR 上,首届 SLAM(即时定位与地图构建) 与深度学习的国际研讨会受到了极大的关注,这也得益于 SLAM 技术在自主机器人和自动驾驶领域中日益重要的地位。
第一场演讲的主讲人是计算机视觉(CV)领域的宗师级大牛、加州大学伯克利分校前计算机科学系主任 Jitendra Malik。去年年末,Malik 加入了 Facebook 的人工智能研究院(FAIR)。
Malik 首先简述了过去几十年在目标识别、定位和 3D 重建的研究发展进程——从以 DPM(Deformable Parts Model) 为代表的传统算法开始,随后介绍了 2015 年前后开始流行的图像分割重要算法 Fast R-CNN,以及其进一步衍生出的 Mask R-CNN,最后到目前最新的有关 3D 物体形状的研究。
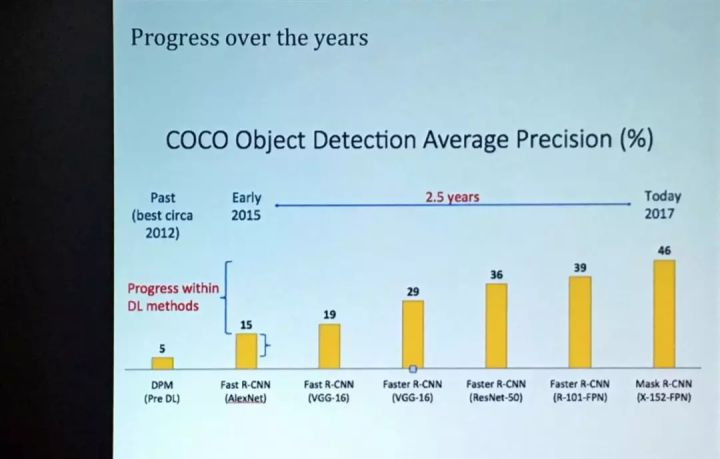
随后,Malik 推荐介绍了三篇他所参与的、分别被 NIPS 2017 以及近两年的 CVPR 所接收的论文,都是有关基于二维图像重建三维结构:
- Factoring Shape, Pose, and Layout from the 2D Image of a 3D Scene,本文的目的是获取场景的单个 2D 图像,并根据一组小的因素恢复 3D 结构:一个表示封闭表面的布局以及一组以形状和姿态表示的对象。论文提出了一种基于卷积神经网络的方法来预测这种表示,并在室内场景的大数据集上对其进行基准测试。
- Learning Category-Specific Mesh Reconstruction from Image Collections:本文提出了一个学习框架,用于从单个图像中重建真实世界物体的三个方面:3D 形状、Camera 和纹理(Texture)。该形状被表示为对象类别的可变形 3D 网格模型。该论文允许利用注释图像集合进行训练,而不依赖于地面真实 3D 或多视图监督。
- Learning a Multi-View Stereo Machine:本文提出了一个多视点立体视觉学习系统。并采用了一种端到端的学习系统,使得比经典方法所需少得多的图像 (甚至单个图像) 重建以及完成不可见表面成为可能。
最后,Malik 提到了在 SLAM 领域一些新进展。在他看来,传统的绘图和规划方法十分低效,因为它需要重建整个区域内的结构,这并不是人类所采用的方法。同时,传统的 SLAM 技术只关注几何结构(geometry)的注释却忽视了语义(semantics),比如人类在看到一个带着「出口」的门时,他自然而然地就会理解为「从这儿走可以出去」,但机器没有这个概念。
「研究 SLAM 需要从语义和几何结构两个角度同时出发,」Malik 说道。随后他介绍了斯坦福大学研究的数据集——Stanford Large-Scale 3D Indoor Spaces Dataset (S3DIS),出自CVPR 2016年的一篇论文。该论文提出了一种分层方法对整个建筑物的三维点云进行语义分析。论文强调,室内空间结构元素的识别本质上是一个检测问题,而不是常用的分割。论文作者们在S3DIS这个数据集上验证了他们的方法,该数据集覆盖面积超过6,000平方米的建筑,并且涵盖了超过2.15亿个点。

Malik & R-CNN 奠基人 Ross Girshick:视频问答系统需要更好的数据集
依旧是 Malik,他在主题为「视觉问答 (Visual Question Anwersing,简称 VQA) 和对话系统」的研讨会上强调了视觉问答系统对目前人工智能研究的重要性,以及它目前存在的挑战。
VQA 是目前视觉和语言的一个重要的交叉学科领域。系统根据图片上的信息,回答来自提问者的任何问题。在此基础上,视觉对话系统(在去年的 CVPR 上被提出)则要求机器可以回答后续问题,比如「轮椅中有多少人?」「他们的性别是什么?」
为什么语言对于视觉理解(visual understanding)这么重要?一篇题为「语言有助于分类」的研究论文表明,对婴儿来说,语言在获取对象类概念的过程中发挥着非常重要的作用,文字可以作为一种本质占位符,它能帮助婴儿更快地建立对不同物件的认识和表示。

但是,Malik 认为解决 VQA 很难,远比物体识别困难的多。系统可以通过物体识别或者获取图片上的一些基本信息,也有不少此类的标注数据集,但是没有数据集是能够标注图片中的人类行为、目标、动作和事件等元素,而这些元素恰恰是视觉理解的关键。
另一位值得一提的演讲嘉宾是 FAIR 的高级研究员、同样也是提出 R-CNN 和 Fast R-CNN 的学术大牛 Ross Girshick。他在演讲中提出了目前在 VQA 存在的问题:答案矛盾。
举一个例子:CloudCV: Visual Question Answering (VQA) 是一个云端的视觉问答系统,给出一张图,用户可以随意提出问题,系统会给出不同答案的准确率。当一些精明的用户提出不同的问题来「调戏」这个系统时,他们发现这个系统有时会对截然不同的问题作出相同的答案。
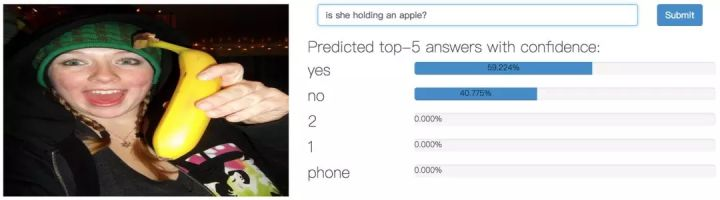
一般的视觉问答数据集里都含有这么三个元素——一张图片,对应的问题和对应的答案,即为(I, Q, A)。Girshick 认为,测量一个 VQA 的准确性不应该是检查孤立的(I, Q, A),而是应该考量结构化的数据集合,即在同一张图片下,每一个问题 Q 都意味着另一个答案 A 的值。
「建立这样的数据集毫无疑问是相当的困难的,但我们需要数据集对算法和模型的要求更高一些,」Girshick 说。
一个小插曲:Malik 今天讲了一个段子:「一位警察驾着警车沿街巡逻。他发现路灯下有黑影晃动,看起来像是个醉鬼,于是警察上前盘问:『请问你在这儿干嘛?』『我在找钥匙,刚刚开门时不小心掉了。』『你把钥匙掉在路灯下了?』『不是,钥匙掉在门口旁的树丛里!』『那你为什么在路灯下面找呢?』『因为这里光线比较亮啊!』」
虽是老梗,Malik 却认为这个故事和如今的科学研究颇为相似。近年来大量标注数据、强大的算力以及大规模模拟环境给当前的监督学习提供了很好的研究环境,这就如同那个路灯下,快速地提升研究成果,但这或许不是通往强人工智能的正确道路。
吴恩达高徒 Honglak Lee: 视频预测和无监督学习
在 CV 领域,深度学习在视频分析领域,包括动作识别和检测、运动分析和跟踪、浅层架构等问题上,还存在许多挑战。在今年的 CVPR 上,主题为「视频理解的大胆新理念」的研讨会将来自视频分析领域的研究人员聚集在一起,讨论各种挑战、评估指标、以及基准。
研讨会邀请到了密歇根教授、谷歌大脑研究员 Honglak Lee,他也是吴恩达在斯坦福大学的高徒。
Lee 带来的是有关视频(动作)预测和无监督学习方面的研究。
Lee 介绍说,目前研究视频分析的一个关键挑战是将产生图像的许多变异因素分开,场景方面包括姿势、形状、照明,视频方面则是后景和前景对象的区分,以及画面中不同物体的交互。他的研究方向是在视频上进行复杂的推理,比如预测未来并对其采取行动。
Lee 主要介绍了他最新的一篇被 ICML 18 接收的论文:Hierarchical Long-term Video Prediction without Supervision。该论文旨在提供一种用于解决长期视频预测的训练方法,无需高级监督就可以训练编码器、预测器和解码器。通过在特征空间中使用对抗性损失来训练预测变量来做进一步改进。Lee 研究的方法可以预测视频未来约 20 秒,并在 Human 3.6M 数据集上提供更好的结果。

自动驾驶座谈会:挑战,机遇,安全
本届 CVPR 的自动驾驶研讨会算得上是阵容强大:Tesla 的人工智能主管 Andrej Karpathy、Uber 自动驾驶主管、也是多伦多大学 CV 领域的权威 Raquel Urtasun、伯克利自动驾驶产业联盟的联合创始人 Kurt Keutzer 等。
尽管他们各自的演讲并不甚出彩,主要就是给自家公司「打广告」,但在当天最后的座谈会上,受邀的八位嘉宾(Karpathy 除外)之间却迸发出了难得一见的精彩辩论。

这也难怪,自动驾驶领域和 CVPR 绝大多数的研讨会主题都不同。视觉理解也好,SLAM 也罢,它们并不太牵涉到生与死的问题。但在自动驾驶领域,研究者们的一举一动和数以亿计的人们的身家性命息息相关,这让话题内容的高度和意义往往被拔高。同时,各家对自动驾驶的理解也都不太一样,各执己见下所引发的争辩反倒是给底下的观众提供了更多的思考。
长达一个小时的座谈会上,机器之心记者总结了其中三个比较重要的议题:
什么是自动驾驶最大的挑战?
Lyft 的工程副总裁 Luc Vincent 认为计算(compute)还没有准备好,同时社会对自动驾驶的接纳程度还不够高。
伯克利的 Keutzer 教授认为是感知(perception), 这个观点得到了 Urtasun 的支持,不过两人在随后的问题上产生了意见分歧:Urtasun 认为解决了感知,规划(planning)也就不成问题了。Keutzer 却认为,这两者是两回事儿,即使感知的问题解决了,还是无法解决在特定场景上出现的规划上的困境。
同样是伯克利的博士后研究员 Bo Li 认为自动驾驶领域依然存在许多未收集到的角落场景(corner case),这会引发一些安全隐患。
如果你是一名 CV 的博士生想要做自动驾驶的研究,你应该做什么?
「做地图!」Urtasun 抢先说道,她认为目前在高精度地图上,业内没有衡量的标准以及可靠的解决方案,技术上难度也比较大。
结果,Urtasun 的回答马上遭到了几位同行的驳斥。「千万不要做(地图)!」密歇根大学副教授、May Mobility 的 CEO Edwin Olson 赶紧抢过话来。「我们正在处于一个在自动驾驶领域中非常愚蠢的时间点——对地图有着过分的依赖。我认为地图的短板也非常明显,而且最终我们会慢慢地减少对地图的依赖。」
其他人也都表达了类似的观点:「算法上去了,你自然不那么需要地图。」「未来制作高精地图的技术也会越来越可靠,需要标记地图数据的人力也会逐步降低。」
未来将如何衡量不同自动驾驶车辆安全性?
这是一个让不少现场嘉宾卡壳的问题,业界似乎也没有一个统一的衡量标准。Olson 倒是提出了很有新意的观点:「车险」,从车险的高低或许能看出公司对安全性的信心到底有多少。
随后,Bo Li 提出,未来或许可以通过建模,将自动驾驶后台系统的代码输进去做基准评估。不过,加州自动驾驶公司 Nuro.ai 的高级工程师 Will Maddern 告诉机器之心记者,这个想法短期内还很难实现,他认为比较可行的方法是让不同的车辆在同一环境里跑来做一些比较。
挑战赛结果出炉:中国军团的进击
除了研讨会上的嘉宾演讲外,大会首日的另一大亮点则是挑战赛。据机器之心记者了解到,中国学者们在挑战赛上有着很出色的发挥,以下是目前获悉的比赛结果(不完全):
DeepGlobe 卫星图像理解挑战赛
DeepGlobe 卫星图像理解挑战由 Facebook、Uber、IEEE 下的 GRSS 机构等联合赞助。卫星图像是一个强大的信息来源,因为它包含更多结构化和统一的数据。虽然计算机视觉社区已经开发出许多日常图像数据集,但卫星图像最近才引起人们对地图和人口分析的关注。
因此,组织者提出了该项挑战赛,围绕三种不同的卫星图像理解任务进行构建,分别是道路提取、建筑检测,和土地覆盖分类。本次比赛创建和发布的数据集可作为未来卫星图像分析研究的参考基准。
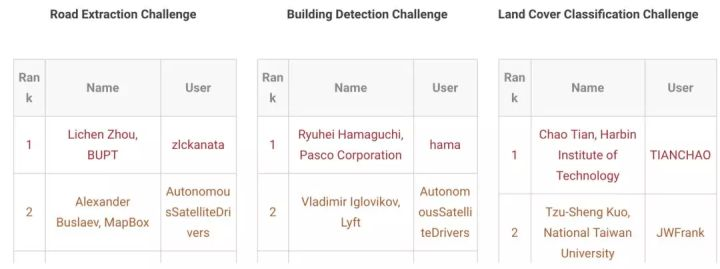
最终,来自北京邮电大学的 Lichen Zhou 团队在道路提取任务上获得第一,而来自哈尔滨工业大学和 Chao Tian 团队则赢得了土地覆盖分类任务的第一名。
Look Into Person (LIP) 挑战赛
Look Into Person(LIP)挑战赛由中山大学和卡内基梅隆大学联合举办。该挑战赛旨在提高计算机视觉在野外场景中的应用,比如人类解析和姿态估计问题。该挑战赛一共有 5 个 track,来自京东人工智能研究院的 Wu Liu 团队获得了其中单人和多人姿态估计任务的第一名。
图像压缩挑战赛(CLIC)
CHALLENGE ON LEARNED IMAGE COMPRESSION 挑战赛由 Google、Twitter、Amazon 等公司联合赞助,是第一个由计算机视觉领域的会议发起的图像压缩挑战赛,旨在将神经网络、深度学习等一些新的方式引入到图像压缩领域。
据大会官方介绍,此次挑战赛分别从 PSNR 和主观评价两个方面去评估参赛团队的表现。不久之前,比赛结果公布:在不同基准下,来自国内创业公司图鸭科技的团队 TucodecTNGcnn4p 在 MOS 和 MS-SSIMM 得分上获得第一名,腾讯音视频实验室和武汉大学陈震中教授联合团队 iipTiramisu 在 PSNR(Peak Signal-to-Noise Ratio,峰值信噪比)指标上占据领先优势,位列第一。

比赛结果:www.compression.cc/results/
Moments in Time 视频行为理解挑战赛
Moment 是由 MIT-IBM Watson AI Lab 开发的研究项目。该项目致力于构建超大规模数据集来帮助 AI 系统识别和理解视频中的动作和事件。如今,该数据集已包含了一百万部标记的 3 秒视频,涉及人物、动物、物体或自然现象,捕捉了动态场景的要点。
此挑战赛分为 Full Track 和 Mini Track,比赛的前三名均为中国团队所得:

比赛结果:moments.csail.mit.edu/results2018…
在 Full Track 类别中,来自海康威视的 DEEP-HRI 获得了第一名,旷视科技第二,七牛云团队第三名。在 Mini Track 中,来自中山大学的 SYSU_isee 团队获得第一名,北航与台湾大学的团队分别是二三名。
在大会第一天,机器之心观察、记录到了以上内容,但这些并不能代表全部精彩内容。接下来几天,我们将会继续为大家报道 CVPR 2018 大会,读者中有参与大会的同学也可以为我们投稿,从而把更多精彩内容分享给大家。

