

原文地址:blogof33.com/post/8/
前言
最近做项目,Raspberry Pi (ARM Cortex-A53 四核,1GB内存)上面连了两个超声波,需要一直测距。树莓派作为机器人主控控制机器人运动,此外树莓派上面还同时运行了摄像头和web服务器(用来传输视频流),并且后台常驻有Tensorflow图像识别模型,按照要求隔一段时间会进行图像识别。由于树莓派的配置不高,每次运行Tensorflow图像识别四个核都会跑满,所以为了使得超声波不影响Tensorflow的识别并且防止CPU长期占用率过高烧坏拓展板,需要降低超声波CPU占用率。
Python GIL
因为有两个超声波同时测距,因为控制程序用python写的,所以我们最开始想到的是使用 Python thread 库中的 start_new_thread 方法创建子进程:
thread.start_new_thread(checkdist,(GPIO_R1,var1,))
thread.start_new_thread(checkdist,(GPIO_R2,var2,))
checkdist为超声波程序,具体可见之前的文章-》树莓派3B 超声波测距传感器Python GPIO/WPI/BCM三种方式 。
然后程序运行的时候机器人运动起来很卡,发出的命令有延迟。一看CPU占用率,如下图,原来是程序全部挤在一个核上面,导致卡顿。
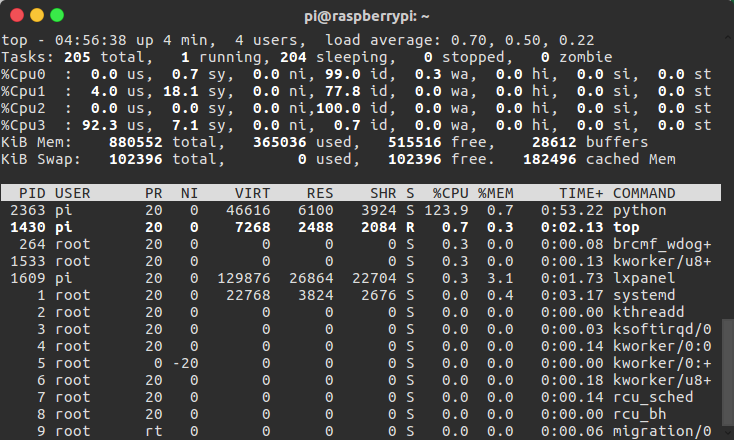
为什么整个程序全部挤在一个核上面运行?一查资料,发现是因为CPython解释器存在GIL。
GIL是什么
首先需要明确的一点是 **GIL(Global Interpreter Lock,全局解释器锁)**并不是Python的特性,它是在实现Python解释器(CPython,使用C语言实现)时所引入的一个概念。解释器有很多种,同样一段代码可以通过CPython,PyPy,JPython等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
CPython解释器中所有C代码在执行Python时必须保持这个锁。Python之父Guido van Rossum当初加这个锁是因为那个年代多核还不常见,并且这个锁使用起来足够简单,保证了同一时刻只有一个线程对共享资源进行存取(这里提一句,线程切换时,CPython可以进行协同式多任务处理或者抢占式多任务处理,具体说明见 这篇文章),但是这样也使得python无法实现多核多线程,随着多核时代的来临,GIL暴露出它先天的不足,不仅仅使程序不能多核多线程并行运行,并且在多核上面运行会对多线程的效率造成影响。
那么,python发展到今天,为什么不能移除GIL,用更好的实现代替呢?
曾经有人做过实验,移除了GIL用更小粒度的锁,发现在单线程上面性能降低非常严重,多线程程序也只有在线程数达到一定数量时才会有性能上的改进。所以移除GIL换更小粒度的锁目前看来还是不值得的,Python社区目前最为重点的研究之一就是GIL,移除GIL任重道远。
那么,我们如何绕开GIL的限制呢?我进行了几种尝试。
绕开GIL
multiprocessing
要实现程序同时运行在多核上面,如果仅仅使用python,一般来说都是使用 multiprocessing 编写多进程程序:
from multiprocessing import Process
p1=Process(target=checkdist,args=(GPIO_R1,var1,))
P2=Process(target=checkdist,args=(GPIO_R2,var2,))
P1.start()
P2.start()
P1.join()
P2.join()
CPU占用情况:
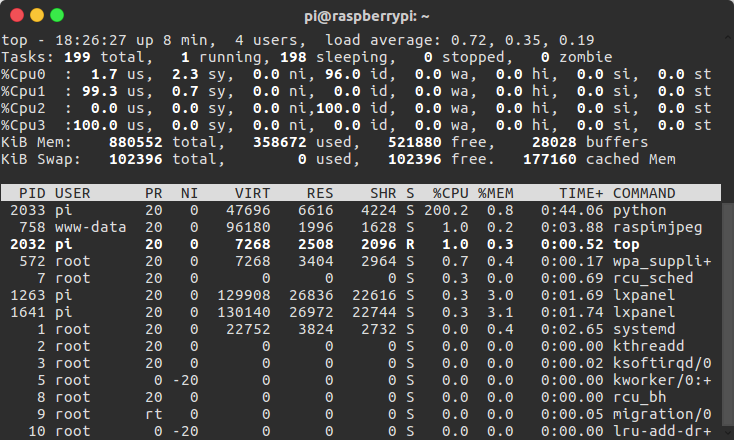
发现程序超声波部分运行在两个核上面了,父进程运行在另外一个核上面,所以机器人运动起来不卡了!但是,两个核都跑满了,虽然解决了延迟问题,但是占用率更糟糕了。出现这样的问题,是不是进程太重了?网上找了一圈,很多人都说超声波死循环确实会把核占满。
那么,没有解决方法了吗?这时候我想到C语言,能不能用C语言绕过GIL的限制呢?
与C语言共舞
“Python 有时候是一把瑞士军刀”。官方的解释器CPython是用C语言实现的,所以Python具有与C/C++整合的能力。如果用C语言来执行超声波距离检测,用python来调用,能否实现多核多线程?
python有一个 ctypes 库,能够实现python调用C语言函数的要求。阅读了官方文档以后,我们首先编写C语言的函数,如下所示,关于超声波函数的具体说明请见上一篇文章 树莓派3B 超声波测距传感器Python GPIO/WPI/BCM三种方式。
//checkdist.c文件
//这里我的树莓派拓展板只能使用bcm编码方式
#include<stdio.h>
#include <bcm2835.h>
#include<termio.h>
#include<sys/time.h>
#include<stdlib.h>
void checkdist(int GPIO_R,int *var,int *signal,int GPIO_S,void(*t_stop)(int)){
struct timeval tv1;
struct timeval tv2;
long start, stop;
double dis;
if(!bcm2835_init()){
printf("setup bcm2835 failed !");
return;
}
bcm2835_gpio_fsel(GPIO_S, BCM2835_GPIO_FSEL_OUTP);
bcm2835_gpio_fsel(GPIO_R, BCM2835_GPIO_FSEL_INPT);
while(1){
if(*signal==1)
continue;
else
*signal=1;
printf("GPIO:%d\n",GPIO_R);
bcm2835_gpio_write(GPIO_S,HIGH);
bcm2835_delayMicroseconds(15);//延时15us
bcm2835_gpio_write(GPIO_S,LOW);
while(!bcm2835_gpio_lev(GPIO_R));
gettimeofday(&tv1, NULL);
while(bcm2835_gpio_lev(GPIO_R));
gettimeofday(&tv2, NULL);
start = tv1.tv_sec * 1000000 + tv1.tv_usec; //微秒级的时间
stop = tv2.tv_sec * 1000000 + tv2.tv_usec;
dis = ((double)(stop - start) * 34000 / 2)/1000000; //求出距离
if(dis<5){
*var=1;
t_stop(1);
}
else
*var=0;
printf("dist:%lfcm\n",dis);
*signal=0;
bcm2835_delay(100);//延时15ms
}
}
然后使用以下命令生成目标文件:
gcc checkdist.c -shared -fPIC -o libcheck.so
这里说明一下,选项 -shared -fPIC 意思是生成与位置无关的代码,则产生的代码中,没有绝对地址,全部使用相对地址,故而代码可以被加载器加载到内存的任意位置,都可以正确的执行。这正是共享库所要求的,共享库被加载时,在内存的位置不是固定的。防止变量之类地址错误。
然后使用以下的python代码实现C语言线程函数:
#checkdist函数原型为:
#void checkdist(int GPIO_R,int *var,int *signal,int GPIO_S,void(*t_stop)(int));
#t_stop为python函数,函数原型为:def t_stop(t_time)
lib=cdll.LoadLibrary("/home/pi/Raspbarry_Tensorflow_Car/Servo/MotorHAT/libcheck.so")#加载DLL
stop_func=CFUNCTYPE(None,c_int)
#CFUNCTYPE的第一个参数是函数的返回值,void则为NULL,函数的其他参数紧随其后
func=stop_func(t_stop)#回调函数,func为函数指针类型,指向python中的t_stop函数
signal=c_int(0)#c语言中的int类型
var1=c_int(0)
var2=c_int(0)
#创建两个子线程,线程函数为C语言函数checkdist
thread.start_new_thread(lib.checkdist,(GPIO_R1,byref(var1),byref(signal),GPIO_S,func,))
thread.start_new_thread(lib.checkdist,(GPIO_R2,byref(var2),byref(signal),GPIO_S,func,))
下面来说明一下上面代码的一些细节。
lib=cdll.LoadLibrary("/home/pi/Raspbarry_Tensorflow_Car/Servo/MotorHAT/libcheck.so")
这一行代码加载C语言目标文件 libcheck.so 。
ctypes 库提供了三个容易加载动态连接库的对象:cdll、windll和oledll。通过访问这三个对象的属性,就可以调用动态连接库的函数了。其中cdll主要用来加载C语言调用方式(cdecl),windll主要用来加载WIN32调用方式(stdcall),而oledll使用WIN32调用方式(stdcall)且返回值是Windows里返回的HRESULT值。在C语言里面,参数是采用入栈的方式来传递,顺序是从右往左,cdll和后面两种的区别在于清除栈时,cdll是使用调用者清除栈的方式,所以实现可变参数的函数只能使用该调用约定;而windll和oledll是使用被调用者清除,被调用的函数在返回前清理传送参数的栈,函数参数个数固定。下图可以很好的体现出来:
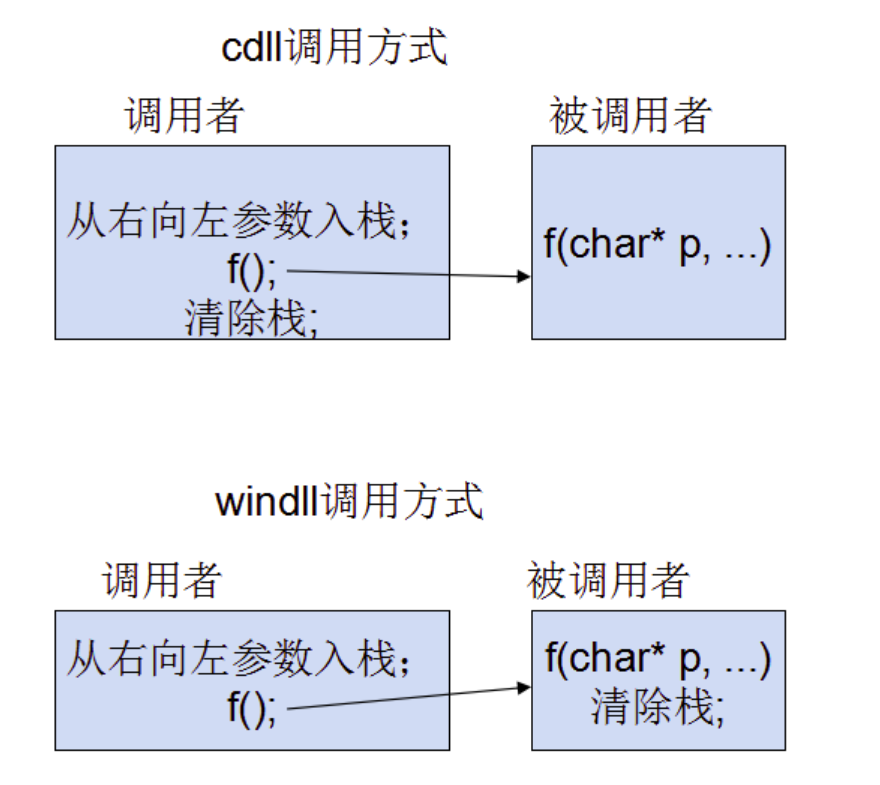
这里采用cdll的方式,防止不必要的错误。
然后是调用回调函数:
stop_func=CFUNCTYPE(None,c_int)
#CFUNCTYPE的第一个参数是函数的返回值,void则为NULL,函数的其他参数紧随其后
func=stop_func(t_stop)#回调函数,func为函数指针类型,指向python中的t_stop函数
这两行的目的就是将python中的 t_stop 函数传进后面的C函数,使得C语言函数里面能够调用 t_stop 函数。
然后后面一行的 signal=c_int(0) 相当于C语言中的 int singel=0; 后面几行同理。
最后便是:
#创建两个子线程,线程函数为C语言函数checkdist
thread.start_new_thread(lib.checkdist,(GPIO_R1,byref(var1),byref(signal),GPIO_S,func,))
thread.start_new_thread(lib.checkdist,(GPIO_R2,byref(var2),byref(signal),GPIO_S,func,))
创建线程,参数的函数是C语言函数 checkdist,byref(var1) 相当于 &var1 ,传 var1 的地址进去,其他的类似。
然后我们运行一下看看结果怎么样:
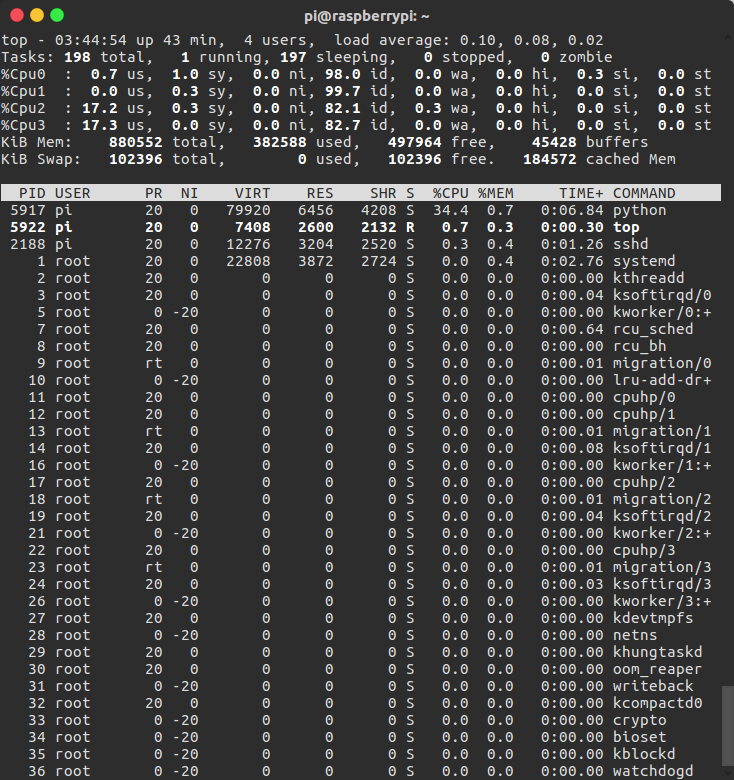
Nice!我们可以看出来,结果超出了预料,效果比想象中的要好很多!不仅实现了多核多线程,而且CPU占用率降低了很多。双核占用率基本上在2%~30%之间波动,比之前的好太多。
结语
这次的经历收获颇丰,想不到简单的一个超声波避障,会遇到这么多问题。其实文章写到这里意犹未尽,还有很多方面没有探讨过,比如GIL对多线程的效率造成影响的实验,为什么会出现 multiprocessing 和C语言作为线程函数之间这么大的占用率差距,等等。另外还有一个 Tensorflow 在树莓派这种性能低下的机器上面的优化问题,我也一直想写,迟迟未能动笔。先就这样吧,文章还有很多不足,如果发现有疏漏的地方,请各位读者不吝赐教。
与君共勉。
