

LOF离群因子检测算法及python3实现
转载声明
本文首发于 知乎专栏-数据科学与python小记
原文链接 LOF离群因子检测算法及python3实现 - Suranyi的文章 - 知乎
一、相关背景
1.1 异常检测算法
随着数据挖掘技术的快速发展,人们在关注数据整体趋势的同时,开始越来越关注那些明显偏离数据整体趋势的离群数据点,因为这些数据点往往蕴含着更加重要的信息,而处理这些离群数据要依赖于相应的数据挖掘技术。 离群点挖掘的目的是有效的识别出数据集中的异常数据,并且挖掘出数据集中有意义的潜在信息。出现离群点的原因各有不同,其中主要有以下几种情况:
- 数据来源于异类:如欺诈、入侵、疾病爆发、不同寻常的实验结果等。这类离群点的产生机制偏离正常轨道,往往是被关注的重点
- 数据变量固有的变化:自然、周期发生等反映数据集的分布特征,如气候的突然变化、顾客新型购买模式、基因突变等
- 数据测最或收集误差:主要是系统误差、人为的数据读取偏差、测量设备出现故障或“噪音”干扰
- 随机或人为误差:主要原因是实验平台存在随机机制,同时人为在数据录入等过程中可能出现的误差
离群点检测具有非常强的实际意义,在相应的应用领域有着广泛前景。其中工程应用领域主要有以下几个方面:
- 欺诈检测:信用卡的不正当行为,如信用卡、社会保障的欺诈行为或者是银行卡、电话卡的欺诈使用等
- 工业检测:如计算机网络的非法访问等
- 活动监控:通过实时检测手机活跃度或者是股权市场的可疑交易,从而实现检测移动手机诈骗行为等
- 网络性能:计算机网络性能检测(稳健性分析),检测网络堵塞情况等
- 自然生态应用领域:生态系统失调、异常自然气候的发现等
- 公共服务领域:公共卫生中的异常疾病的爆发、公共安全中的突发事件的发生等
目前,随着离群点检测技术的日渐成熟,在未来的发展中将会应用在更多的行业当中,并且能更好地为人类的决策提供指导作用。
离群点检测的一个目标是从看似杂乱无章的大量数据中挖掘有价值的信息,使这些数据更好地为我们的日常生活所服务。但是现实生活中的数据往往具有成百上千的维度,并且数据量极大,这无疑给目前现有的离群点检测方法带来大难题。传统的离群点检测方法虽然在各自特定的应用领域里表现出很好效果,但在高维大数据集中却不再适用。因此如何把离群点检测方法有效地应用于大数据、高维度数据,是目前离群点检测方法的首要目标之一。
1.2 为什么是异常点检测
分类学习算法在训练时有一个共同的基本假设:不同类别的训练样例数目相当。如果不同类别的训练样例数目稍有差别,通常影响不大,但若差别很大,则会对学习过程造成困扰。 ——周志华《机器学习》
2018 年 Mathorcup 数学建模竞赛 B 题——“品牌手机目标用户的精准营销”中就出现这样的问题。原题中,检测用户数 1万+,购买手机用户500+。若使用分类算法,那么分类器很可能会返回这样的一个算法:“所有用户都不会购买这款手机”,分类的正确率高达96%,但显然没有实际意义,因为它并不能预测出任何的正例。
这类问题称为“类别不平衡”,指不同类别的训练样例数目差别很大的情况(上例中,购买的与没有购买用户数量差别大)。处理这类问题往往采用“欠采样”、“过采样”进行数据处理,但通过这样的方法,可能会损失原始数据中的信息。因此,从离群点的角度出发,将购买行为视为“异常”,进行离群点挖掘。
1.3 离群点挖掘方法

1.4 LOF 算法背景
基于密度的离群点检测方法的关键步骤在于给每个数据点都分配一个离散度,其主要思想是:针对给定的数据集,对其中的任意一个数据点,如果在其局部邻域内的点都很密集,那么认为此数据点为正常数据点,而离群点则是距离正常数据点最近邻的点都比较远的数据点。通常有阈值进行界定距离的远近。在基于密度的离群点检测方法中,最具有代表性的方法是局部离群因子检测方法 (Local Outlier Factor, LOF)。
二、算法简介
在众多的离群点检测方法中,LOF 方法是一种典型的基于密度的高精度离群点检测方法。在 LOF 方法中,通过给每个数据点都分配一个依赖于邻域密度的离群因子 LOF,进而判断该数据点是否为离群点。若 LOF 1, 则该数据点为离群点;若 LOF 接近于 1,则该数据点为正常数据点。
2.1 距离度量尺度
设对于没有相同点的样本集合 ,假设共有
个检测样本,数据维数为
,对于
针对数据集 中的任意两个数据点
,定义如下几种常用距离度量方式
2.1.1 Eucild(欧几里得)距离:
2.1.2 Hamming(汉明)距离:
注 汉明距离使用在数据传输差错控制编码里面,用于度量信息不相同的位数。
取 ,易见
与
中有
位数字不相同,因此
与
的汉明距离为
。
对于数据处理,一种技巧是先对连续数据进行分组,化为分类变量(分组变量),对分类变量可以引入汉明距离进行度量。——沃兹基 · 硕德

2.1.3 Mahalanobis(马氏)距离:
设样本集 的协方差矩阵为
,记其逆矩阵为
若
可逆,对
做
分解(奇异值分解),得到:
若 不可逆,则使用广义逆矩阵
代替
,对其求彭罗斯广义逆,有:
则两个数据点 的马氏距离为:
注 马氏距离表示数据的协方差距离,利用 Cholesky 变换处理不同维度之间的相关性和度量尺度变换的问题,是一种有效计算样本集之间的相似度的方法。
2.1.4 球面距离
球面距离其实是在欧式距离基础上进行转换得到的,并不是一种独特的距离度量方式,在地理信息转换中经常使用,本文对此进行详细介绍。
| 符号 | 说明 | 符号 | 说明 | 符号 | 说明 |
|---|---|---|---|---|---|
| 球体球心 | |||||
| 球体球径 | |||||
| 待测距离点 | |||||
| 交点 |
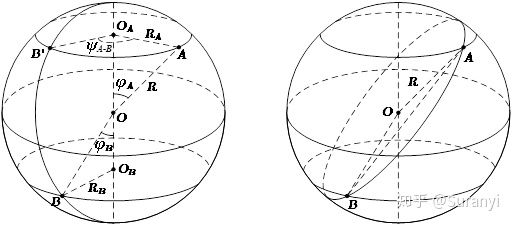
设 A,B 两点的球面坐标为 。若该球体为地球,则 x,y 分别代表纬度和经度。(注:下文的
为 x 的余角,便于推导所使用的记号)
如图所示,连接,在
和
中计算:
由于 与
是异面直线,
是它们的公垂线,所成角度经度差为
,利用异面直线上两点距离公式:
在 中,由余弦定理:
由于此处的 代表纬度的补角,对其进行转换:
因此,点 A,B 的球面距离为:
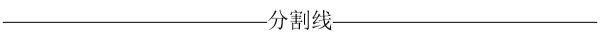
此外还有 Chebyshev(切比雪夫)距离、Minkowski(闵科夫斯基)距离、绝对值距离、Lance & Williams 距离,具体问题具体分析,选择合适的度量方式。
统一使用 表示点
和点
之间的距离。根据定义,易知交换律成立:
2.2 第  距离
距离
定义 为点
的第
距离,
,满足如下条件
- (1) 在集合中至少存在
,使得
- (2) 在集合中至多存在
个点
简言之:点 P 是距离 O 最近的第 k 个点
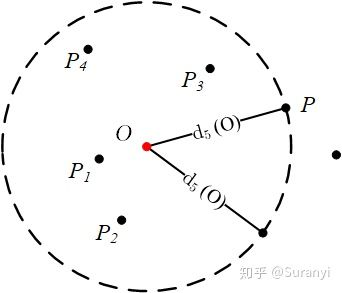
2.3 距离邻域
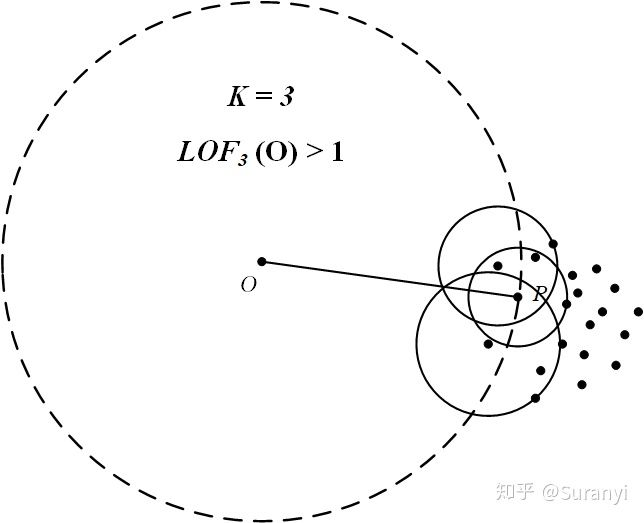
定义 设 N_{k}(O) 为点 O 的第 k 距离邻域,满足:
注 此处的邻域概念与国内高数教材略有不同(具体的点,而非区间)。该集合中包含所有到点 O 距离小于点 O 第 k 邻域距离的点。易知有,如上图,点 O 的第 5 距离邻域为:
2.4 可达距离
定义 点 P 到点 O 的第 k 可达距离定义为:
注 即点 到点
的第
可达距离至少是点
的第
距离。距离
点最近的
个点,它们到
的可达距离被认为是相当的,且都等于
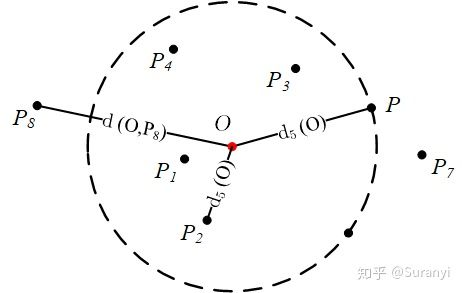
2.5 局部可达密度
定义 局部可达密度定义为:
注 表示点 的第
邻域内所有点到
的平均可达距离,位于第
邻域边界上的点即使个数大于
,也仍将该范围内点的个数计为
。如果
和周围邻域点是同一簇,那么可达距离越可能为较小的
,导致可达距离之和越小,局部可达密度越大。如果
和周围邻域点较远,那么可达距离可能会取较大值
,导致可达距离之和越大,局部可达密度越小。
部分资料这里使用
而不是
会因为过多点在内部同一圆环上(如式13中的
位于同一圆环上)而导致
此外,本文 2.1 开头指出“没有样本点重合”在这里也能得到解释:如果考虑重合样本点,可能会造成此处的可达密度为或下文的
为
形式,计算上带来困扰。
2.6 局部离群因子
注 表示点 的邻域
内其他点的局部可达密度与点
的局部可达密度之比的平均数。如果这个比值越接近
,说明
的邻域点密度差不多,
可能和邻域同属一簇;如果这个比值小于
,说明
的密度高于其邻域点密度,
为密集点;如果这个比值大于
,说明
的密度小于其邻域点密度,
可能是异常点。
三、LOF离群因子检测算法python3 实现(第 4 部分进行改进)
此部分先介绍 sklearn 提供的函数,再介绍逐步编程实现方法。
3.1 导入 sklearn 模块实现
在 python3 中,sklearn 模块提供了 LOF 离群检测算法
3.1.1 导入模块
import pandas as pd
import matplotlib.pyplot as plt
3.1.2 核心函数
clf = LocalOutlierFactor(n_neighbors=20, algorithm='auto', contamination=0.1, n_jobs=-1)
n_neighbors = 20:即上文提及的algorithm = 'auto':使用的求解算法,使用默认值即可contamination = 0.1:范围为 (0, 0.5),表示样本中的异常点比例,默认为 0.1n_jobs = -1:并行任务数,设置为-1表示使用所有CPU进行工作p = 2:距离度量函数,默认使用欧式距离。(其他距离模型使用较少,这里不作介绍。具体参考官方文档)
clf.fit(data)
无监督学习,只需要传入训练数据data,传入的数据维度至少是 2 维
clf.kneighbors(data)
-
作用:获取第 k 距离邻域内的每一个点到中心点的距离,并按从小到大排序
-
返回
数组,[距离,样本索引]
-clf._decision_function(data)
- 作用:获取每一个样本点的 LOF 值,该函数范围 LOF 值的相反数,需要取反号
clf._decision_function的输出方式更为灵活:若使用 clf._predict(data) 函数,则按照原先设置的 contamination 输出判断结果(按比例给出判断结果,异常点返回-1,非异常点返回1)
3.1.3 封装函数
localoutlierfactor(data, predict, k)
- 输入:训练样本,测试样本,
- 输出:每一个测试样本 LOF 值及对应的第
plot_lof(result,method)
- 输入:LOF 值、阈值
- 输出:以索引为横坐标的 LOF 值分布图
lof(data, predict=None, k=5, method=1, plot = False)
- 输入:训练样本,测试样本,
- 输出:离群点、正常点分类情况 没有输入测试样本时,默认测试样本=训练样本
def localoutlierfactor(data, predict, k):
from sklearn.neighbors import LocalOutlierFactor
clf = LocalOutlierFactor(n_neighbors=k + 1, algorithm='auto', contamination=0.1, n_jobs=-1)
clf.fit(data)
# 记录 k 邻域距离
predict['k distances'] = clf.kneighbors(predict)[0].max(axis=1)
# 记录 LOF 离群因子,做相反数处理
predict['local outlier factor'] = -clf._decision_function(predict.iloc[:, :-1])
return predict
def plot_lof(result, method):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(8, 4)).add_subplot(111)
plt.scatter(result[result['local outlier factor'] > method].index,
result[result['local outlier factor'] > method]['local outlier factor'], c='red', s=50,
marker='.', alpha=None,
label='离群点')
plt.scatter(result[result['local outlier factor'] <= method].index,
result[result['local outlier factor'] <= method]['local outlier factor'], c='black', s=50,
marker='.', alpha=None, label='正常点')
plt.hlines(method, -2, 2 + max(result.index), linestyles='--')
plt.xlim(-2, 2 + max(result.index))
plt.title('LOF局部离群点检测', fontsize=13)
plt.ylabel('局部离群因子', fontsize=15)
plt.legend()
plt.show()
def lof(data, predict=None, k=5, method=1, plot=False):
import pandas as pd
# 判断是否传入测试数据,若没有传入则测试数据赋值为训练数据
try:
if predict == None:
predict = data.copy()
except Exception:
pass
predict = pd.DataFrame(predict)
# 计算 LOF 离群因子
predict = localoutlierfactor(data, predict, k)
if plot == True:
plot_lof(predict, method)
# 根据阈值划分离群点与正常点
outliers = predict[predict['local outlier factor'] > method].sort_values(by='local outlier factor')
inliers = predict[predict['local outlier factor'] <= method].sort_values(by='local outlier factor')
return outliers, inliers
3.1.4 实例测试
测试数据:2017年全国大学生数学建模竞赛B题数据
测试数据有俩份文件,进行三次测试:没有输入测试样本、输入测试样本、测试样本与训练样本互换
测试 1 没有输入测试样本情况:任务密度
数据背景:众包任务价格制定中,地区任务的密度反映任务的密集程度,从而影响任务的定价,此处不考虑球面距离偏差(即认为是同一个平面上的点),现在需要使用一个合理的指标刻画任务的密集程度。
import numpy as np
import pandas as pd
# 根据文件位置自行修改
posi = pd.read_excel(r'已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
# 获取任务密度,取第5邻域,阈值为2(LOF大于2认为是离群值)
outliers1, inliers1 = lof(A, k=5, method = 2)
给定数据中共有835条数据,设置 LOF 阈值为 2,输出17个离群点信息:
绘制数据点检测情况分布如下图所示,其中蓝色表示任务分布情况,红色范围表示 LOF 值大小:
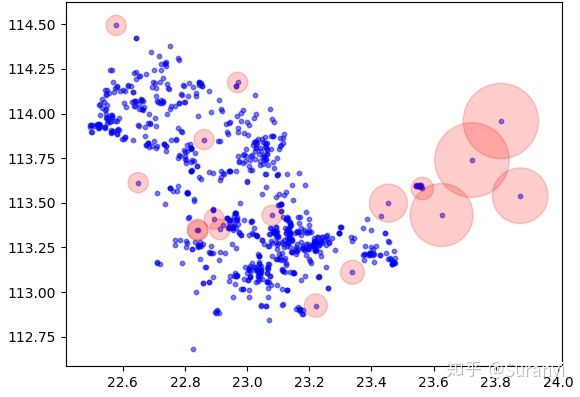
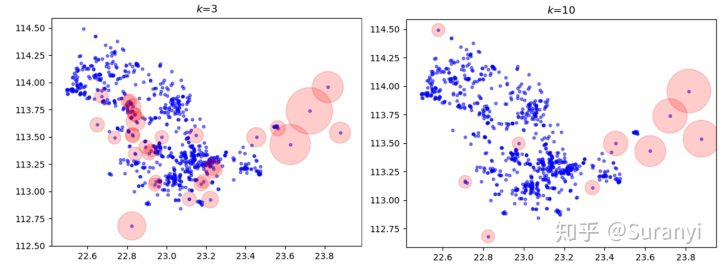
# 绘图程序
import matplotlib.pyplot as plt
for k in [3,5,10]:
plt.figure('k=%d'%k)
outliers1, inliers1 = lof(A, k=k, method = 2)
plt.scatter(np.array(A)[:,0],np.array(A)[:,1],s = 10,c='b',alpha = 0.5)
plt.scatter(outliers1[0],outliers1[1],s = 10+outliers1['local outlier factor']*100,c='r',alpha = 0.2)
plt.title('k=%d' % k)
测试 2 有输入测试样本情况:任务对会员的密度
数据背景:众包任务价格制定中,地区任务的密度反映任务的密集程度、会员密度反映会员的密集程度。而任务对会员的密度则可以用于刻画任务点周围会员的密集程度,从而体现任务被完成的相对概率。此时训练样本为会员密度,测试样本为任务密度。
import numpy as np
import pandas as pd
posi = pd.read_excel(r'已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
posi = pd.read_excel(r'会员信息数据.xlsx')
lon = np.array(posi["会员位置(GPS)经度"][:]) # 经度
lat = np.array(posi["会员位置(GPS)纬度"][:]) # 纬度
B = list(zip(lat, lon)) # 按照纬度-经度匹配
# 获取任务对会员密度,取第5邻域,阈值为2(LOF大于2认为是离群值)
outliers2, inliers2 = lof(B, A, k=5, method=2)
给定训练样本中共有1877条数据,测试样本中共有835条数据,设置 LOF 阈值为 2,输出34个离群点信息:
绘制数据点检测情况分布如下图所示,其中蓝色表示任务分布情况,绿色表示会员分布情况,红色范围表示 LOF 值大小。
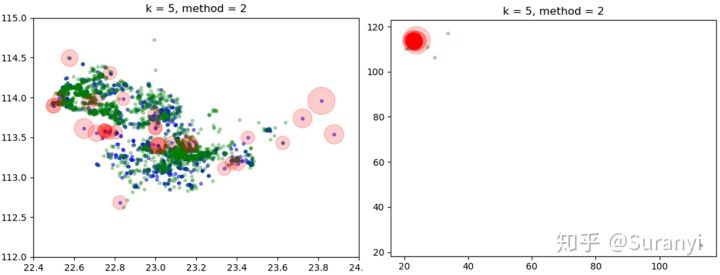
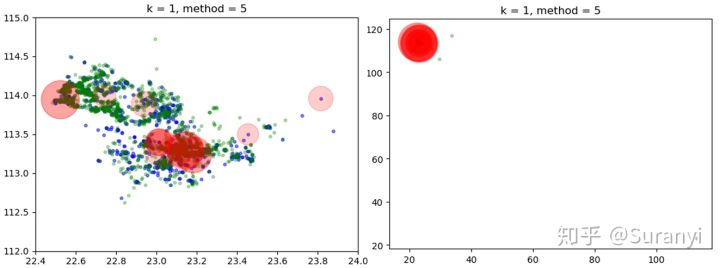
# 绘图程序
import matplotlib.pyplot as plt
for k,v in ([1,5],[5,2]):
plt.figure('k=%d'%k)
outliers2, inliers2 = lof(B, A, k=k, method=v)
plt.scatter(np.array(A)[:,0],np.array(A)[:,1],s = 10,c='b',alpha = 0.5)
plt.scatter(np.array(B)[:,0],np.array(B)[:,1],s = 10,c='green',alpha = 0.3)
plt.scatter(outliers2[0],outliers2[1],s = 10+outliers2['local outlier factor']*100,c='r',alpha = 0.2)
plt.title('k = %d, method = %g' % (k,v))
测试 3 测试样本与训练样本互换:会员对任务的密度
数据背景:众包任务价格制定中,地区任务的密度反映任务的密集程度、会员密度反映会员的密集程度。而任务对会员的密度则可以用于刻画会员周围任务的密集程度,从而体现会员能接到任务的相对概率。此时训练样本为任务密度,测试样本为会员密度。
import numpy as np
import pandas as pd
posi = pd.read_excel(r'已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
posi = pd.read_excel(r'会员信息数据.xlsx')
lon = np.array(posi["会员位置(GPS)经度"][:]) # 经度
lat = np.array(posi["会员位置(GPS)纬度"][:]) # 纬度
B = list(zip(lat, lon)) # 按照纬度-经度匹配
# 获取会员对任务密度,取第5邻域,阈值为5(LOF大于5认为是离群值)
outliers3, inliers3 = lof(A, B, k=5, method=5)
给定训练样本中共有835条数据,测试样本中共有1877条数据,设置 LOF 阈值为 5,输出20个离群点信息:
绘制数据点检测情况分布如下图所示,其中蓝色表示会员分布情况,绿色表示任务分布情况,红色范围表示 LOF 值大小。
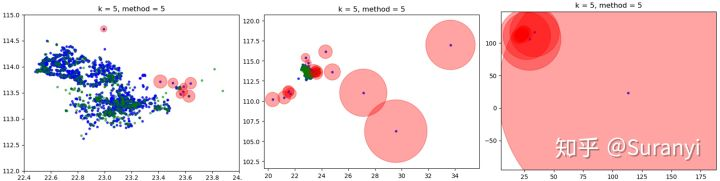
# 绘图程序
plt.figure('k=5')
outliers3, inliers3 = lof(A, B, k=5, method=5)
plt.scatter(np.array(B)[:, 0], np.array(B)[:, 1], s=10, c='b', alpha=0.5)
plt.scatter(np.array(A)[:, 0], np.array(A)[:, 1], s=10, c='green', alpha=0.3)
plt.scatter(outliers3[0], outliers3[1], s=10 + outliers3['local outlier factor'] * 20, c='r', alpha=0.2)
plt.title('k = 5, method = 5')
将 method 设置为 0 就能输出每一个点的 LOF 值,作为密度指标。
3.2 逐步编程实现方法
3.2.1 距离度量尺度
distances(A, B,model = 'euclidean')
- 调用 geopy 模块中的函数进行球面距离计算
- 输入:A,B两点坐标,距离模式('euclidean', 'geo' 分别为欧式距离和球面距离)
- 输出:若A,B为两个坐标点,则返回坐标点距离;若A,B为矩阵,计算规则如下:
def distances(A, B,model = 'euclidean'):
'''LOF中定义的距离,默认为欧式距离,也提供球面距离'''
import numpy as np
A = np.array(A); B = np.array(B)
if model == 'euclidean':
from scipy.spatial.distance import pdist, squareform
distance = squareform(pdist(np.vstack([A, B])))[:A.shape[0],A.shape[0]:]
if model == 'geo':
from geopy.distance import great_circle
distance = np.zeros(A.shape[0]*B.shape[0]).reshape(A.shape[0],B.shape[0])
for i in range(len(A)):
for j in range(len(B)):
distance[i,j] = great_circle(A[i], B[j]).kilometers
if distance.shape == (1,1):
return distance[0][0]
return distance
3.2.2 k 邻域半径及邻域点
k_distance(k, instance_A, instance_B, result, model)
- 调用 3.2.1 的 distances 函数
- 输入: k 值,A,B两点坐标,pandas.DataFrame 表用于存储中间信息量,距离模式
- 输出:pandas.DataFrame 表(距离、邻域点坐标)
def k_distance(k, instance_A, instance_B, result, model):
'''计算k距离邻域半径及邻域点'''
distance_all = distances(instance_B, instance_A, model)
# 对 instance_A 中的每一个点进行遍历
for i,a in enumerate(instance_A):
distances = {}
distance = distance_all[:,i]
# 记录 instance_B 到 instance_A 每一个点的距离,不重复记录
for j in range(distance.shape[0]):
if distance[j] in distances.keys():
if instance_B[j].tolist() in distances[distance[j]]:
pass
else:
distances[distance[j]].append(instance_B[j].tolist())
else:
distances[distance[j]] = [instance_B[j].tolist()]
# 距离排序
distances = sorted(distances.items())
if distances[0][0] == 0:
distances.remove(distances[0])
neighbours = [];k_sero = 0;k_dist = None
# 截取前 k 个点
for dist in distances:
k_sero += len(dist[1])
neighbours.extend(dist[1])
k_dist = dist[0]
if k_sero >= k:
break
# 输出信息
result.loc[str(a.tolist()),'k_dist'] = k_dist
result.loc[str(a.tolist()),'neighbours'] = str(neighbours)
return result
3.2.3 局部可达密度
local_reachability_density(k,instance_A,instance_B,result, model)
- 调用 3.2.2 的 k_distance 函数
- 输入: k 值,A,B两点坐标,pandas.DataFrame 表用于存储中间信息量,距离模式
- 输出:pandas.DataFrame 表(距离、邻域点坐标、局部可达密度)
def local_reachability_density(k,instance_A,instance_B,result, model):
'''局部可达密度'''
result = k_distance(k, instance_A, instance_B, result, model)
# 对 instance_A 中的每一个点进行遍历
for a in instance_A:
# 获取k_distance中得到的邻域点坐标,解析为点坐标(字符串 -> 数组 -> 点)
try:
(k_distance_value, neighbours) = result.loc[str(a.tolist())]['k_dist'].mean(),eval(result.loc[str(a.tolist())]['neighbours'])
except Exception:
(k_distance_value, neighbours) = result.loc[str(a.tolist())]['k_dist'].mean(), eval(result.loc[str(a.tolist())]['neighbours'].values[0])
# 计算局部可达距离
reachability_distances_array = [0]*len(neighbours)
for j, neighbour in enumerate(neighbours):
reachability_distances_array[j] = max([k_distance_value, distances([a], [neighbour],model)])
sum_reach_dist = sum(reachability_distances_array)
# 计算局部可达密度,并储存结果
result.loc[str(a.tolist()),'local_reachability_density'] = k / sum_reach_dist
return result
3.2.4 局部离群因子
k_distance(k, instance_A, instance_B, result, model)
- 调用 3.2.3 的 local_reachability_density 函数
- 输入: k 值,A,B两点坐标,pandas.DataFrame 表用于存储中间信息量,距离模式
- 输出:pandas.DataFrame 表(距离、邻域点坐标、局部可达密度、离群因子)
def local_outlier_factor(k,instance_A,instance_B,model):
'''局部离群因子'''
result = local_reachability_density(k,instance_A,instance_B,pd.DataFrame(index=[str(i.tolist()) for i in instance_A]), model)
# 判断:若测试数据=样本数据
if np.all(instance_A == instance_B):
result_B = result
else:
result_B = local_reachability_density(k, instance_B, instance_B, k_distance(k, instance_B, instance_B, pd.DataFrame(index=[str(i.tolist()) for i in instance_B]), model), model)
for a in instance_A:
try:
(k_distance_value, neighbours, instance_lrd) = result.loc[str(a.tolist())]['k_dist'].mean(),np.array(eval(result.loc[str(a.tolist())]['neighbours'])),result.loc[str(a.tolist())]['local_reachability_density'].mean()
except Exception:
(k_distance_value, neighbours, instance_lrd) = result.loc[str(a.tolist())]['k_dist'].mean(), np.array(eval(result.loc[str(a.tolist())]['neighbours'].values[0])), result.loc[str(a.tolist())]['local_reachability_density'].mean()
finally:
lrd_ratios_array = [0]* len(neighbours)
for j,neighbour in enumerate(neighbours):
neighbour_lrd = result_B.loc[str(neighbour.tolist())]['local_reachability_density'].mean()
lrd_ratios_array[j] = neighbour_lrd / instance_lrd
result.loc[str(a.tolist()), 'local_outlier_factor'] = sum(lrd_ratios_array) / k
return result
3.2.5 封装函数
lof(k,instance_A,instance_B,k_means=False,$n_clusters$=False,k_means_pass=3,method=1,model = 'euclidean'
- 调用 3.2.4 的 k_distance 函数
- 输入: k 值,A,B两点坐标,是否使用聚类算法,聚类簇数,跳过聚类样本数低于3的簇,阈值,距离模式
- 输出:离群点信息、正常点信息、LOF 分布图
# 函数中的 k_means将在第4部分介绍
def lof(k, instance_A, instance_B, k_means=False, $n_clusters$=False, k_means_pass=3, method=1, model='euclidean'):
'''A作为定点,B作为动点'''
import numpy as np
instance_A = np.array(instance_A);
instance_B = np.array(instance_B)
if np.all(instance_A == instance_B):
if k_means == True:
if $n_clusters$ == True:
$n_clusters$ = elbow_method(instance_A, maxtest=10)
instance_A = kmeans(instance_A, $n_clusters$, k_means_pass)
instance_B = instance_A.copy()
result = local_outlier_factor(k, instance_A, instance_B, model)
outliers = result[result['local_outlier_factor'] > method].sort_values(by='local_outlier_factor', ascending=False)
inliers = result[result['local_outlier_factor'] <= method].sort_values(by='local_outlier_factor', ascending=True)
plot_lof(result, method) # 该函数见3.1.3
return outliers, inliers
四、LOF 算法相关思考及改进
4.1 一维数据可以使用 LOF 吗?
本文 3.1 中 sklearn 模块提供的 LOF 方法进行训练时会进行数据类型判断,若数据类型为list、tuple、numpy.array 则要求传入数据的维度至少是 2 维。实际上要筛选 1 维数据中的离群点,直接在坐标系中绘制出图像进行阈值选取判断也很方便。但此情形下若要使用 LOF 算法,可以为数据添加虚拟维度,并赋相同的值:
# data 是原先的1维数据,通过下面的方法转换为2维数据
data = list(zip(data, np.zeros_like(data)))
此外,也可以通过将数据转化为 pandas.DataFrame 形式避免上述问题:
data = pd.DataFrame(data)
4.2 多大的 LOF 才是离群值?
LOF 计算结果对于多大的值定义为离群值没有明确的规定。在一个平稳数据集中,可能 1.1 已经是一个异常值,而在另一个具有强烈数据波动的数据集中,即使 LOF 值为 2 可能仍是一个正常值。由于方法的局限性,数据集中的异常值界定可能存在差异,笔者认为可以使用统计分布方法作为参考,再结合数据情况最终确定阈值。
基于统计分布的阈值划分
将 LOF 异常值分数归一化到 [0, 1] 区间,运用统计方法进行划分下面提供使用箱型图进行界定的方法,根据异常输出情况参考选取。
box(data, legend=True)
- 输入:LOF 异常分数值,在箱型图中绘制异常数据(设置为False不绘制)
- 输出:异常识别情况
def box(data, legend=True):
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.style.use("ggplot")
plt.figure()
# 如果不是DataFrame格式,先进行转化
if type(data) != pd.core.frame.DataFrame:
data = pd.DataFrame(data)
p = data.boxplot(return_type='dict')
warming = pd.DataFrame()
y = p['fliers'][0].get_ydata()
y.sort()
for i in range(len(y)):
if legend == True:
plt.text(1, y[i] - 1, y[i], fontsize=10, color='black', ha='right')
if y[i] < data.mean()[0]:
form = '低'
else:
form = '高'
warming = warming.append(pd.Series([y[i], '偏' + form]).T, ignore_index=True)
print(warming)
plt.show()
box 函数可以插入封装函数 lof 中,传入 data = predict['local outlier factor'] 实现;也可以先随机指定一个初始阈值,(输出的离群点、正常点分别命名为outliers, inliers)再输入:
box(outliers['local outlier factor'].tolist()+inliers['local outlier factor'].tolist(), legend=True)
此时,交互控制台中输出情况如下左图所示,箱型图如下右图所示。输出情况提示我们从数据分布的角度上,可以将 1.4 作为离群识别阈值,但实际上取 7 更为合适(从 2 到 7 间有明显的断层,而上文中设定为 5 是经过多次试验后选取的数值)。
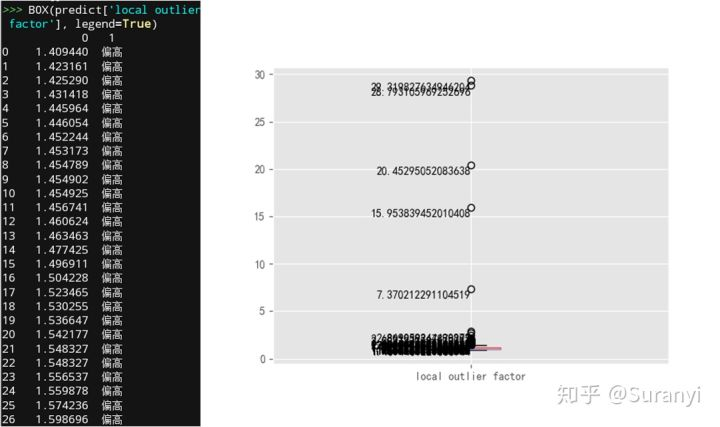
4.3 数据维度过大,还能使用 LOF 算法吗?
数据维度过大一方面会增大量纲的影响,另一方面增大计算难度。此时直接使用距离度量的表达形式不合理,并有人为放大较为分散数据影响的风险。一种处理方式是采用马氏距离作为距离度量的方式(去量纲化)。另一种处理方式,参考随机森林的决策思想,可以考虑在多个维度投影上使用 LOF 并将结果结合起来,以提高高维数据的检测质量。
集成学习
集成学习:通过构建并结合多个学习器来完成学习任务,通常可以获得比单一学习器更显著优越的泛化性能。 ——周志华《机器学习》
数据检测中进行使用的数据应该是有意义的数据,这就需要进行简单的特征筛选,否则无论多么“离群”的样本,可能也没有多大的实际意义。根据集成学习的思想,需要将数据按维度拆分,对于同类型的数据,这里假设你已经做好了规约处理(如位置坐标可以放在一起作为一个特征“距离”进行考虑),并且数据的维度大于 1,否则使用 4.1 中的数据变换及一般形式 LOF 即可处理。
4.3.1 投票表决模式
投票表决模式认为每一个维度的数据都是同等重要,单独为每个维度数据设置 LOF 阈值并进行比对,样本的 LOF 值超过阈值则异常票数积 1 分,最终超过票数阈值的样本认为是离群样本。
localoutlierfactor(data, predict, k)
- 输入:训练样本,测试样本, k 值
- 输出:每一个测试样本 LOF 值及对应的第 k 距离
plot_lof(result,method)
- 输入:LOF 值、阈值
- 输出:以索引为横坐标的 LOF 值分布图
ensemble_lof(data, predict=None, k=5, groups=[], method=1, vote_method = 'auto')
- 输入:训练样本,测试样本, k 值,组合特征索引,离群阈值,票数阈值
组合特征索引(列位置 - 1):如第一列数据与第二列数据作为同类型数据,则传入groups = [[0, 1]]
- 离群阈值:每一个特征的离群阈值,缺少位数则以 1 替代
- 票数阈值:正常点离群因子得票数上限
- 输出:离群点、正常点分类情况 没有输入测试样本时,默认测试样本=训练样本
def localoutlierfactor(data, predict, k, group_str):
from sklearn.neighbors import LocalOutlierFactor
clf = LocalOutlierFactor(n_neighbors=k + 1, algorithm='auto', contamination=0.1, n_jobs=-1)
clf.fit(data)
# 记录 LOF 离群因子,做相反数处理
predict['local outlier factor %s' % group_str] = -clf._decision_function(predict.iloc[:, eval(group_str)])
return predict
def plot_lof(result, method, group_str):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure('local outlier factor %s' % group_str)
try:
plt.scatter(result[result > method].index,
result[result > method], c='red', s=50,
marker='.', alpha=None,
label='离群点')
except Exception:
pass
try:
plt.scatter(result[result <= method].index,
result[result <= method], c='black', s=50,
marker='.', alpha=None, label='正常点')
except Exception:
pass
plt.hlines(method, -2, 2 + max(result.index), linestyles='--')
plt.xlim(-2, 2 + max(result.index))
plt.title('LOF局部离群点检测', fontsize=13)
plt.ylabel('局部离群因子', fontsize=15)
plt.legend()
plt.show()
def ensemble_lof(data, predict=None, k=5, groups=[], method=1, vote_method = 'auto'):
import pandas as pd
import numpy as np
# 判断是否传入测试数据,若没有传入则测试数据赋值为训练数据
try:
if predict == None:
predict = data.copy()
except Exception:
pass
data = pd.DataFrame(data); predict = pd.DataFrame(predict)
# 数据标签分组,默认独立自成一组
for i in range(data.shape[1]):
if i not in pd.DataFrame(groups).values:
groups += [[i]]
# 扩充阈值列表
if type(method) != list:
method = [method]
method += [1] * (len(groups) - 1)
else:
method += [1] * (len(groups) - len(method))
vote = np.zeros(len(predict))
# 计算LOF离群因子并根据阈值进行票数统计
for i in range(len(groups)):
predict = localoutlierfactor(pd.DataFrame(data).iloc[:, groups[i]], predict, k, str(groups[i]))
plot_lof(predict.iloc[:, -1], method[i], str(groups[i]))
vote += predict.iloc[:, -1] > method[i]
# 根据票数阈值划分离群点与正常点
predict['vote'] = vote
if vote_method == 'auto':
vote_method = len(groups)/2
outliers = predict[vote > vote_method].sort_values(by='vote')
inliers = predict[vote <= vote_method].sort_values(by='vote')
return outliers, inliers
测试 4 仍然使用测试3的情况进行分析,此时将经度、纬度设置为独立的特征,分别对两个维度数据进行识别(尽管单独的纬度、经度数据没有太大的实际意义)
import numpy as np
import pandas as pd
posi = pd.read_excel(r'已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
posi = pd.read_excel(r'会员信息数据.xlsx')
lon = np.array(posi["会员位置(GPS)经度"][:]) # 经度
lat = np.array(posi["会员位置(GPS)纬度"][:]) # 纬度
B = list(zip(lat, lon)) # 按照纬度-经度匹配
# 获取会员对任务密度,取第5邻域,阈值分别为 1.5,2,得票数超过 1 的认为是异常点
outliers4, inliers4 = ensemble_lof(A, B, k=5, method=[1.5,2], vote_method = 1)
# 绘图程序
plt.figure('投票集成 LOF 模式')
plt.scatter(np.array(B)[:, 0], np.array(B)[:, 1], s=10, c='b', alpha=0.5)
plt.scatter(np.array(A)[:, 0], np.array(A)[:, 1], s=10, c='green', alpha=0.3)
plt.scatter(outliers4[0], outliers4[1], s=10 + 1000, c='r', alpha=0.2)
plt.title('k = 5, method = [1.5, 2]')
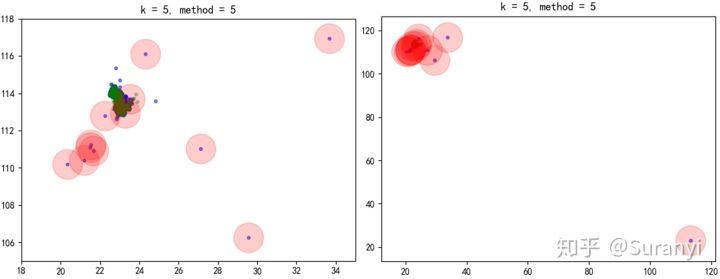
4.3.2 LOF 异常分数加权模式
异常分数加权模式则是对各维度数据的 LOF 值进行加权,获取最终的 LOF 得分作为整体数据的 LOF 得分。权重可以认为是特征的重要程度,也可以认为是数据分布的相对离散程度,若视为后面一种情形,可以根据熵权法进行设定,关于熵权法的介绍详见笔者另一篇博文。
式中 表示第
个数据的第
维度 LOF 异常分数值。
localoutlierfactor(data, predict, k)
- 输入:训练样本,测试样本, k 值
- 输出:每一个测试样本 LOF 值及对应的第 k 距离
plot_lof(result,method)
- 输入:LOF 值、阈值
- 输出:以索引为横坐标的 LOF 值分布图
ensemble_lof(data, predict=None, k=5, groups=[], method=2, weight=1)
- 输入:训练样本,测试样本, k 值,组合特征索引,离群阈值,特征权重
组合特征索引(列位置 - 1):如第一列数据与第二列数据作为同类型数据,则传入groups = [[0, 1]]
- 离群阈值:加权 LOF 离群阈值,默认为 2
- 特征权重:为每个维度的 LOF 设置权重,缺少位数则以 1 代替
- 输出:离群点、正常点分类情况
- 没有输入测试样本时,默认测试样本=训练样本
def localoutlierfactor(data, predict, k, group_str):
from sklearn.neighbors import LocalOutlierFactor
clf = LocalOutlierFactor(n_neighbors=k + 1, algorithm='auto', contamination=0.1, n_jobs=-1)
clf.fit(data)
# 记录 LOF 离群因子,做相反数处理
predict['local outlier factor %s' % group_str] = -clf._decision_function(predict.iloc[:, eval(group_str)])
return predict
def plot_lof(result, method):
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.scatter(result[result > method].index,
result[result > method], c='red', s=50,
marker='.', alpha=None,
label='离群点')
plt.scatter(result[result <= method].index,
result[result <= method], c='black', s=50,
marker='.', alpha=None, label='正常点')
plt.hlines(method, -2, 2 + max(result.index), linestyles='--')
plt.xlim(-2, 2 + max(result.index))
plt.title('LOF局部离群点检测', fontsize=13)
plt.ylabel('局部离群因子', fontsize=15)
plt.legend()
plt.show()
def ensemble_lof(data, predict=None, k=5, groups=[], method='auto', weight=1):
import pandas as pd
# 判断是否传入测试数据,若没有传入则测试数据赋值为训练数据
try:
if predict == None:
predict = data
except Exception:
pass
data = pd.DataFrame(data);
predict = pd.DataFrame(predict)
# 数据标签分组,默认独立自成一组
for i in range(data.shape[1]):
if i not in pd.DataFrame(groups).values:
groups += [[i]]
# 扩充权值列表
if type(weight) != list:
weight = [weight]
weight += [1] * (len(groups) - 1)
else:
weight += [1] * (len(groups) - len(weight))
predict['local outlier factor'] = 0
# 计算LOF离群因子并根据特征权重计算加权LOF得分
for i in range(len(groups)):
predict = localoutlierfactor(pd.DataFrame(data).iloc[:, groups[i]], predict, k, str(groups[i]))
predict['local outlier factor'] += predict.iloc[:, -1] * weight[i]
if method == 'auto':
method = sum(weight)
plot_lof(predict['local outlier factor'], method)
# 根据离群阈值划分离群点与正常点
outliers = predict[predict['local outlier factor'] > method].sort_values(by='local outlier factor')
inliers = predict[predict['local outlier factor'] <= method].sort_values(by='local outlier factor')
return outliers, inliers
测试 5 仍然使用测试3的情况进行分析,此时将经度、纬度设置为独立的特征,分别对两个维度数据进行识别(尽管单独的纬度、经度数据似乎没有太大的实际意义)
import numpy as np
import pandas as pd
posi = pd.read_excel(r'已结束项目任务数据.xls')
lon = np.array(posi["任务gps经度"][:]) # 经度
lat = np.array(posi["任务gps 纬度"][:]) # 纬度
A = list(zip(lat, lon)) # 按照纬度-经度匹配
posi = pd.read_excel(r'会员信息数据.xlsx')
lon = np.array(posi["会员位置(GPS)经度"][:]) # 经度
lat = np.array(posi["会员位置(GPS)纬度"][:]) # 纬度
B = list(zip(lat, lon)) # 按照纬度-经度匹配
# 获取会员对任务密度,取第5邻域,阈值为 100,权重分别为5,1
outliers5, inliers5 = ensemble_lof(A, B, k=5, method=100,weight = [5,1])
# 绘图程序
plt.figure('LOF 异常分数加权模式')
plt.scatter(np.array(B)[:, 0], np.array(B)[:, 1], s=10, c='b', alpha=0.5)
plt.scatter(np.array(A)[:, 0], np.array(A)[:, 1], s=10, c='green', alpha=0.3)
plt.scatter(outliers5[0], outliers5[1], s=10 + outliers5['local outlier factor'], c='r', alpha=0.2)
plt.title('k = 5, method = 100')
4.3.3 混合模式
混合模式适用于数据中有些特征同等重要,有些特征有重要性区别的情况,即对 4.3.1、4.3.2 情形综合进行考虑。同等重要的数据将使用投票表决模式,重要程度不同的数据使用加权模式并根据阈值转换为投票表决模式。程序上只需将两部分混合使用即可,本文在此不做展示。
4.4 数据量太大,算法执行效率过低,有什么改进方法吗?
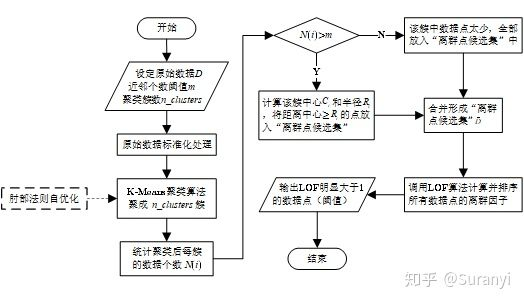
LOF 算法在检测离群点的过程中,遍历整个数据集以计算每个点的 LOF 值,使得算法运算速度慢。同时,由于数据正常点的数量一般远远多于离群点的数量,而 LOF 方法通过比较所有数据点的 LOF 值判断离群程度,产生了大量没必要的计算。因此,通过对原始数据进行修剪可以有效提高 LOF 方法的计算效率。此外,实践过程中也发现通过数据集修剪后,可以大幅度减少数据误判为离群点的几率。这种基于聚类修剪得离群点检测方法称为 CLOF (Cluster-Based Local Outlier Factor) 算法。
基于 K-Means 的 CLOF 算法
在应用 LOF 算法前,先用 K-Means 聚类算法,将原始数据聚成 簇。对其中的每一簇,计算簇的中心
,求出该簇中所有点到该中心的平均距离并记为该簇的半径
。对该类中所有点,若该点到簇中心的距离大于等于
则将其放入“离群点候选集”
,最后对
中的数据使用 LOF 算法计算离群因子。
设第 个簇中的点的个数为
,点集为
中心和半径的计算公式如下:
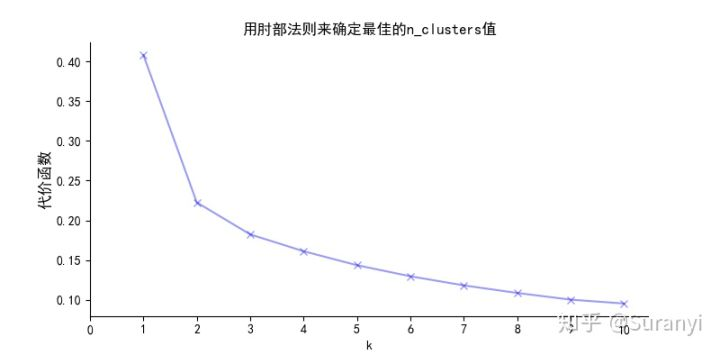
如何确定最佳的 —— 肘部法则
K-Means算法通过指定聚类簇数及随机生成聚类中心,对最靠近他们的对象进行迭代归类,逐次更新各聚类中心的值,直到最好的聚类效果(代价函数值最小)。
对于的选取将直接影响算法的聚类效果。肘部法则将不同的
值的成本函数值刻画出来,随着
增大,每个簇包含的样本数会减少,样本离其中心更接近,代价函数会减小。但随着
继续增大,代价函数的改善程度不断下降(在图像中,代价函数曲线趋于平稳)。
值增大过程中,代价函数改善程度最大的位置对应的
就是肘部,使用此
一般可以取得不错的效果。但肘部法则的使用仅仅是从代价水平进行考虑,有时候还需结合实际考虑。
由于离群值样本数量一般较少,如果聚类出来的簇中样本量太少(如 1-4 个,但其他簇有成百上千个样本),则这种聚类簇不应进行修剪。
定义代价函数:
elbow_method(data,maxtest = 11)
- 输入:需要修剪的数据集,最大测试范围(默认为11)
- 输出:代价曲线图
def elbow_method(data,maxtest = 11):
'''使用肘部法则确定$n_clusters$值'''
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
ax = plt.figure(figsize=(8,4)).add_subplot(111)
N_test = range(1, maxtest)
# 代价函数值列表
meandistortions = []
for $n_clusters$ in N_test:
model = KMeans($n_clusters$=$n_clusters$).fit(data)
# 计算代价函数值
meandistortions.append(sum(np.min(cdist(data, model.cluster_centers_, 'euclidean'), axis=1)) / len(data))
plt.plot(N_test, meandistortions, 'bx-',alpha = 0.4)
plt.xlabel('k')
plt.ylabel('代价函数',fontsize= 12)
plt.title('用肘部法则来确定最佳的$n_clusters$值',fontsize= 12)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.set_xticks(np.arange(0, maxtest, 1))
plt.show()
kmeans(data, $n_clusters$, m):
- 输入:需要修剪的数据集,聚类簇数,最小修剪簇应包含的样本点数
- 输出:修剪后的数据集
def kmeans(data, $n_clusters$, m):
'''使用K-Means算法修剪数据集'''
from sklearn.cluster import KMeans
import numpy as np
data_select = []
model = KMeans($n_clusters$=$n_clusters$).fit(data)
centeroids = model.cluster_centers_
label_pred = model.labels_
import collections
for k, v in collections.Counter(label_pred).items():
if v < m:
data_select += np.array(data)[label_pred == k].tolist()
else:
distance = np.sqrt(((np.array(data)[label_pred == k] - centeroids[k]) ** 2).sum(axis=1))
R = distance.mean()
data_select += np.array(data)[label_pred == k][distance >= R].reshape(-1, np.array(data).shape[-1]).tolist()
return np.array(data_select)
测试6 对B数据集进行修剪分析,B数据集共有 1877 条数据
# 肘部法则确定最佳修剪集
elbow_method(B,maxtest = 11)
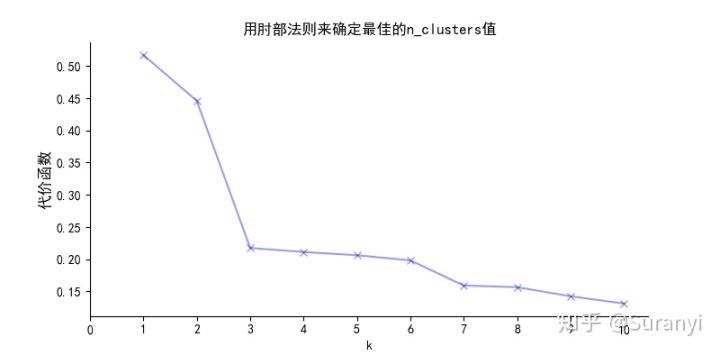
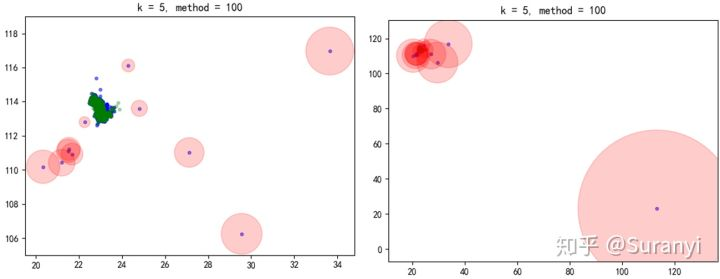
# 根据上面设定的 $n_clusters$ 为3,最小样本量设置为3
B_cut = kmeans(B, $n_clusters$ = 3, m = 3)
执行上述程序,原先包含 1877 条数据的 B 数据集修剪为含有 719 条数据的较小的数据集。使用 LOF 算法进行离群检测,检测结果如下:
# 获取会员分布密度,取第10邻域,阈值为3(LOF大于3认为是离群值)
outliers6, inliers6 = lof(B_cut, k=10, method=3)
# 绘图程序
plt.figure('CLOF 离群因子检测')
plt.scatter(np.array(B)[:, 0], np.array(B)[:, 1], s=10, c='b', alpha=0.5)
plt.scatter(outliers6[0], outliers6[1], s=10 + outliers6['local outlier factor']*10, c='r', alpha=0.2)
plt.title('k = 10, method = 3')
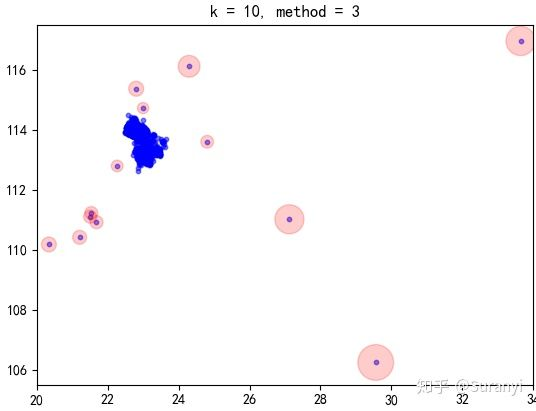
修剪后的数据集 LOF 意义不再那么明显,但离群点的 LOF 仍然会是较大的值,并且 k 选取越大的值,判别效果越明显。
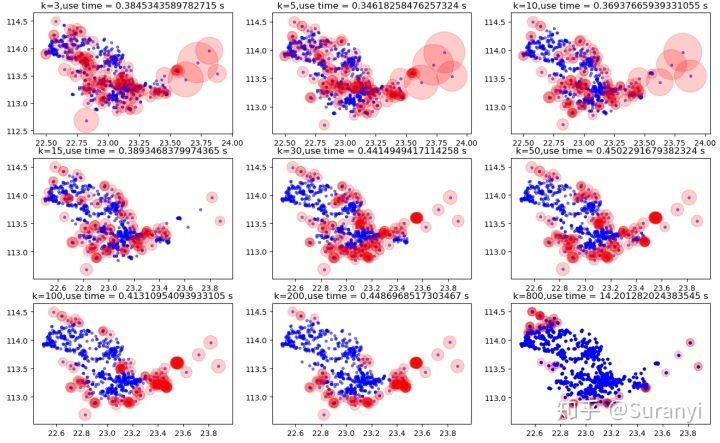
4.5 如何提高识别精度
合理增大 值能显著提高识别精度。但
值的增加会带来不必要的计算、影响算法执行效率,也正因此本文所用的
值都取较小。合理选取
与阈值将是
成功与否的关键。
五、后记
本文内容主要参考算法原文及笔者学习经验进行总结。在异常识别领域,LOF 算法和 Isolation Forest 算法已经被指出是性能最优、识别效果最好的算法。对于常用的人群密度(或其他)的刻画,LOF异常分数值不失为一种“高端”方法(参考文献[3]),相比传统方法,更具有成熟的理论支撑。
后续有时间的话,笔者会根据此文方法,结合实际数据详细进一步说明如何在数据处理中应用 LOF 算法。
六、参考文献
作者:张柳彬
如有疑问,请联系QQ:965579168
转载请声明出处
