

学了python也有一段时间了,对于爬虫,后端的框架也有一些了解,但是都是在学习的时候跟着别人写的,感觉都不是自己的知识一样。我去年就给网易云音乐提了一个建议,就是通过播放量或者一个受欢迎程度来排序,然而肯定是没有管我的,随着网易云音乐的版权问题,现在又开始使用QQ音乐了,当然它依然没有这个功能。所以就只有自己动手解决了~
目的
首先抓取这些歌单,一是为了让自己在没有歌听的时候从播放量高的歌单里选一些来听,二是自己动手抓取一下数据,并简单的分析,熟悉技术。所以我需要知道至少需要歌单名,歌单播放次数,之后再分析都是什么类型的时候需要标签,但是这个不一定准确,所以也就加上去仅供参考。最终需要的数据就有:
class QQMusicItem(Item):
# 歌单名
songSheet = Field()
# 作者
authorName = Field()
# 播放次数
playTimes = Field()
# 创建时间
createTime = Field()
# 标签
tags = Field()
# 介绍
introduce = Field()
爬取QQ音乐歌单
首先给出源码,下文中就不再贴代码,因为爬取数据的代码没什么复用行,而且实现方式多种多样,主要是实现思想。下文中就以解决踩到的坑为线索来实现目的。
打开QQ音乐网页版的分类歌单界面,乍一看,一分析网页源码,看到下图:

找到这里我以为和普通的爬取数据一样,直接看其标签的内容就能抓去完成了,是的不踩一下坑都不知道有多深。是的显然失败了,一条数据都没有。打印一下访问的网页,查找一下这个class的名字,发现居然没有,是的我就这样掉坑里了。
那么看来它就是使用动态填充的,那么它肯定就调用了接口,请求数据,那么就去找,在检查里的network中找啊找,最终找到了它:
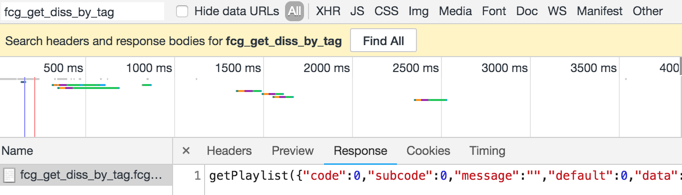
这个接口的寻找不知道技巧,请知道的不吝赐教
到这里得到了大部分数据,歌单名,作者名,播放次数,创建时间都有了。也就是说,只有标签和介绍没有,这个数据通过每一项点进详情里边就能发现,这次我聪明了,没有再直接写,先去找获取详情的接口,毕竟qq音乐这种大厂的产品肯定是技术统一的,这里的数据肯定也是填充的,功夫不负有心人,让我找到了~
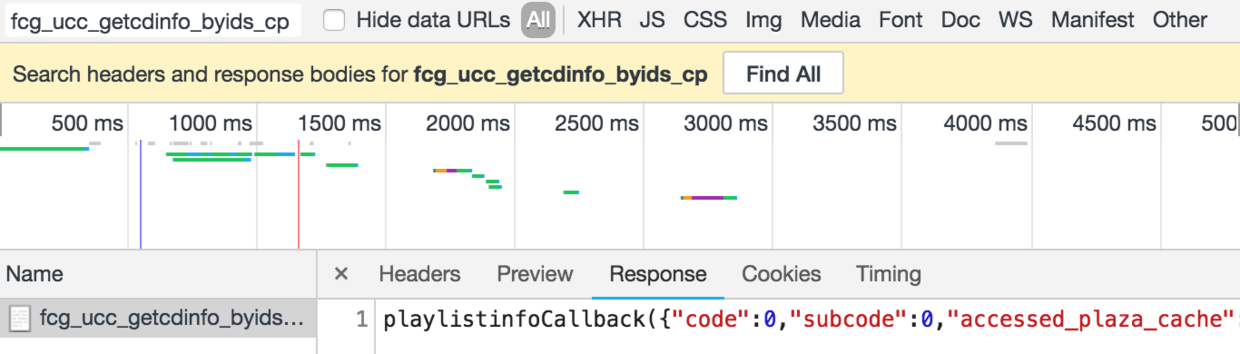
是的从这个数据里边就找到了标签和介绍。
看着短短的几句话,就找到了,其实这个过程我不知道技巧,所以还是耗费了不少时间,也是因为不熟悉吧。
然后就是分页获取全部歌单数据,既然每一页它是调的接口就更容易了,我在第二页去查看第二页请求数据的接口,和第一页的比较,发现其实就是最后两个参数(sin(开始)和ein(结束))引起的变化。在观察这个接口的参数的过程中发现他的rnd这个参数是在变化的,所以在请求每页的数据的时候这三个参数是需要动态改变的。
然后我就重新编码,获取数据,处理数据编程json字符串格式,再转为字典,然后遍历获取到需要的数据。写完执行发现接口访问不了,这时候想起来可能是header需要加参数,再去看那个数据,避免错误就把几乎所有的参数都加上了,其中我觉得referer比较重要。对于referer每一页的接口都是可以来自歌单首页,但是对于详情来源就是详情页,参数带有歌单的id,这个id正好可以从每页的每一项的数据中拿到,所以动态改变就行了,最后删掉一些不是很重要的参数,例如这里我只删除了loginUin。
然后写上代码,经过调试,终于成功了。
最后我把它保存成一个csv文件,通过播放量排序,截取前20,得到了下图
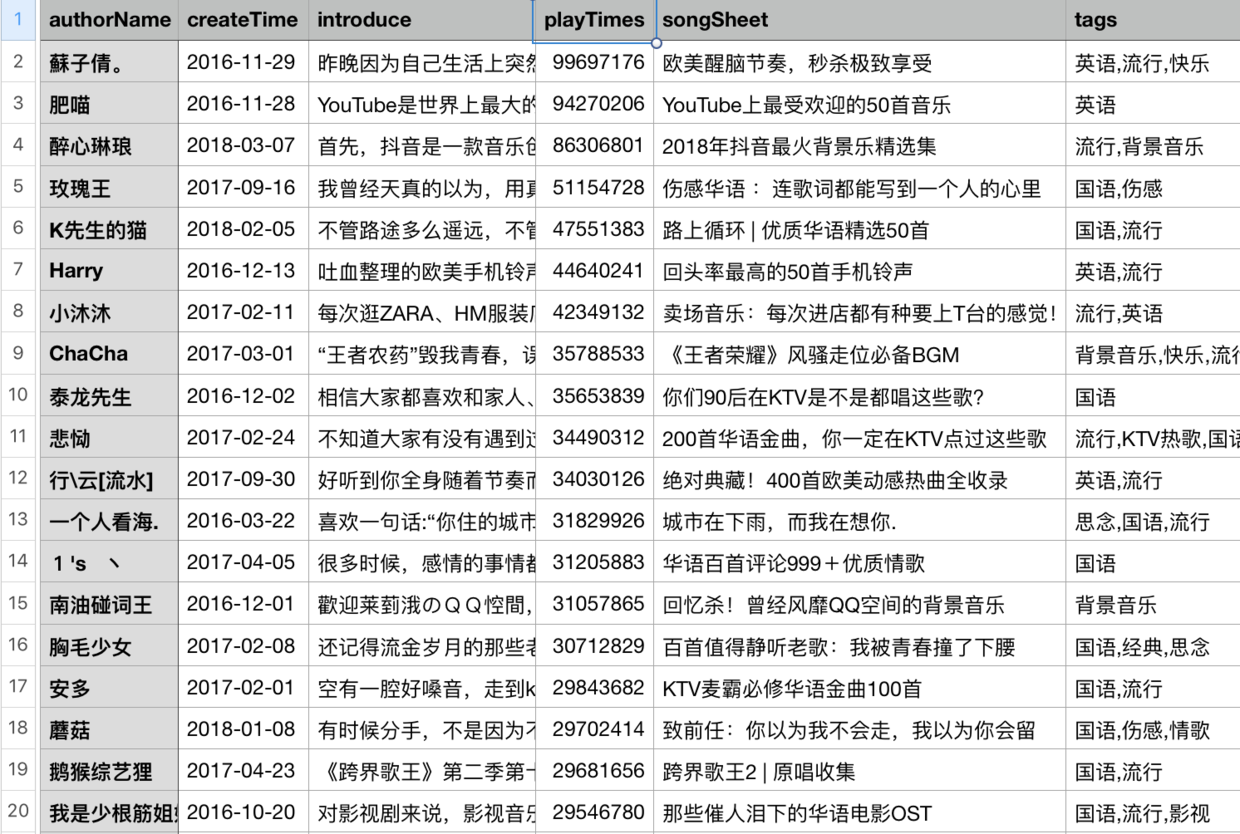
到这里数据的爬取工作已经完成。
分析数据
数据拿到后,在上边已经简单的处理了以下数据,就是看看播放次数前20的歌单。
接着我想看看播放次数的大致分布情况,例如播放5000万次以上有多少,1000万,500万,100万,50万,10万以上以及10万以下,都有多少。然后绘制成柱状图,看看是什么情况。
是的,对于这个数据的处理,就用到了numpy和pandas以及matplotlib。经过分析得出下图结果:
播放次数分析
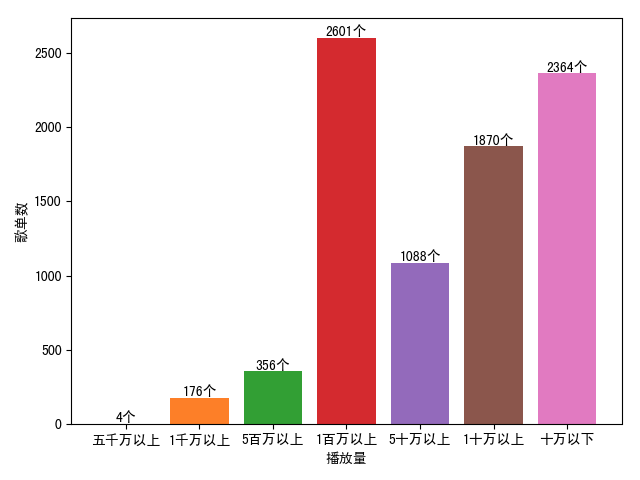
很直观的看到高于500万播放次数的歌单是少数的。按比例来看的话,能明显看到10万以下的歌单有2300多个,还是比较多的,之后再进一步分析这2300多个歌单的创建时间的分布,这里就不继续分析了。
标签分析
对于标签什么的,以下我就想到了使用词云,就能直观的看到哪些词出现的次数多。歌单都主要是什么类型的比较受欢迎。编码后得到如下结果:

可能直接这样看能大概知道哪些多,但是还是不是很能分得很细,我又排了个序,下边列出降序排列前十的标签~
[('流行', 1834), ('英语', 1669), ('国语', 1386), ('电子', 723),
('日语', 552), ('民谣', 369), ('ACG', 347), ('影视', 337),
('治愈', 337), ('韩语', 330)]
先就分析这么多,等有空再分析一下创建时间的分布情况。
不当之处请不吝赐教~
最后再推广一下我的博客,才写不久,之前的文章大多都是从之前我的简书上迁移过去的。之后也会不定期更新Android、Java、Python相关技术。
