

看似无边无际、高深难懂而又时刻更新的数据科学知识,该怎样学才更高效呢?希望读过本文后,你能获得一些帮助。

疑惑
周五下午,我给自己的研究生开组会。主题是工作坊教学,尝试搭建自己的第一个深度神经网络。
参考资料是我的文章《如何用Python和深度神经网络发现即将流失的客户?》。我带着学生们从下载最新版Anaconda安装包开始,直到完成第一个神经网络分类器。
过程涉及编程虚拟环境问题,他们参考了《如何在Jupyter Notebook中使用Python虚拟环境?》一文,比较顺利地掌握了如何在虚拟环境里安装软件包和执行命令。
我要求他们,一旦遇到问题就立即提出。我帮助解决的时候,所有人围过来一起看解决方案,以提升效率。

我给学生们介绍了神经网络的层次结构,并且用Tensorboard可视化展示。他们对神经网络和传统的机器学习算法(师兄师姐答辩的时候,他们听过,有印象)的区别不是很了解,我就带着他们一起玩儿了一把深度学习实验场。
看着原本傻乎乎的直线绕成了曲线,然后从开放到闭合,把平面上的点根据内外区分,他们都很兴奋。还录了视频发到了微信朋友圈。
欣喜之余,一个学生不无担忧地问我:
老师,我现在能够把样例跑出来了,但是里面有很多内容现在还不懂。这么多东西该怎么学呢?
我觉得这是个非常好的问题。
对于非IT类本科毕业生,尤其是“文科生”(定义见这里),读研阶段若要用到数据科学方法,确实有很多知识和技能需要补充。他们中不少人因此很焦虑。
但是焦虑是没有用的,不会给你一丝一毫完善和进步。学会拆解和处理问题,才是你不断进步的保证。
这篇文章,我来跟你谈一谈,看似无边无际、高深难懂而又时刻更新的数据科学知识,该怎样学才更高效。
许多读者曾经给我留言,询问过类似的问题。因此我把给自己学生的一些建议分享给你,希望对你也有一些帮助。
目标
你觉得自己在数据科学的知识海洋里面迷失,是因为套用的学习模式不对。
从上小学开始,你就习惯了把要学习的内容当成学科知识树,然后系统地一步步学完。前面如果学不好,必然会影响后面内容的理解消化。

知识树的学习,也必须全覆盖。否则考试的时候,一旦考察你没有掌握的内容,就会扣分。
学习的进程,有教学大纲、教材和老师来负责一步步喂给你,并且督促你不断预习、学习和复习。
现在,你突然独自面对一个新的学科领域。没了教学大纲和老师的方向与进度指引,教材又如此繁多,根本不知道该看哪一本,茫然无措。
其实如果数据科学的知识是个凝固的、静态的集合,你又有无限长的学习时间,用原先的方法来学习,也挺好。
可现实是,你的时间是有限的,数据科学的知识却是日新月异。今年的热点,兴许到了明年就会退潮。深度学习专家Andrej Karpathy评论不同的机器学习框架时说:
Matlab is so 2012. Caffe is so 2013. Theano is so 2014. Torch is so 2015. TensorFlow is so 2016. :D
怎么办呢?
你需要以目标导向来学习。
例如说,你手头要写的论文里,需要做数据分类。那你就研究分类模型。
分类模型属于监督学习。传统机器学习里,KNN, 逻辑回归,决策树等都是经典的分类模型;如果你的数据量很大,希望用更为复杂而精准的模型,那么可以尝试深度神经网络。
如果你要需要对图片进行识别处理,便需要认真学习卷积神经网络(Convolutional Neural Network),以便高效处理二维图形数据。
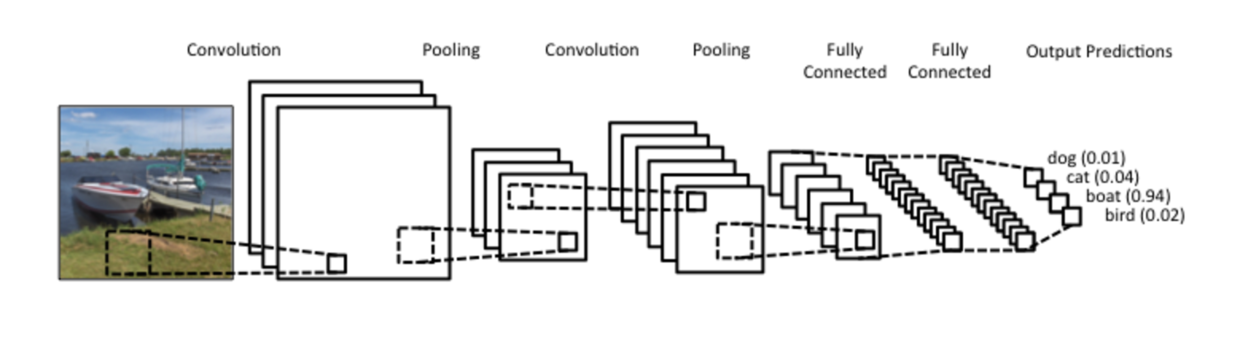
如果你要做的研究,是给时间序列数据(例如金融资产价格变动)找到合适的模型。那么你就得认真了解递归神经网络(recurrent neural network),尤其是长短期记忆(Long short-term memory, LSTM)模型。这样用人工智能玩儿股市水晶球才能游刃有余。

但如果你目前还没有明确的研究题目,怎么办?
不要紧。可以在学习中,以案例为单位,不断积累能力。
实践领域需求旺盛,数据科学的内容又过于庞杂,近年来MOOC上数据科学类课程的发展,越来越有案例化趋势。
一向以技术培训类见长的平台,如Udacity, Udemy等自不必说。就连从高校生长出来的Coursera,也大量在习题中加入实际案例场景。Andrew Ng最新的Deep Neural Network课程就是很好的例证。
我之前推荐过的华盛顿大学机器学习课程,更是非常激进地在第一门课中,通过案例完整展示后面若干门课的主要内容。
注意,学第一门课时,学员们对于相关的技术(甚至是术语)还一无所知呢!
然而你把代码跑完,出现了结果的时候,真的会因为不了解和掌握细节就一无所获吗?
当然不是。
退一万步说,至少你见识了可以用这样的方法成功解决该场景的问题。这就叫认知。
告诉你一个小窍门:在生活、工作和学习中,你跟别人比拼的,基本上都是认知。
你获得了认知后,可以快速了解整个领域的概况。知道哪些知识对自己目前的需求更加重要,学习的优先级更高。
比案例学习更高效的“找目标”方式,是参加项目,动手实践。
动手实践,不断迭代的原理,在《如何高效学Python?》和《创新怎么教?》文中我都有详细分析,欢迎查阅。
这里我给你讲一个真实的例子。
我的一个三年级研究生,本科学的是工商管理。刚入学的时候按照我的要求,学习了密歇根大学的Python课程,并且拿到了系列证书。但是很长的一段时间里,他根本就不知道该怎么实际应用这些知识,论文自然也写不出来。
一个偶然的机会,我带着他参加了另一个老师的研究项目,负责技术环节,做文本挖掘。因为有了实际的应用背景和严格的时间限定,他学得很用心,干得非常起劲儿。之前学习的技能在此时真正被激活了。
等到项目圆满结束,他主动跑来找我,跟我探讨能否把这些技术方法应用于本学科的研究,写篇小论文出来。
于是我俩一起确定了题目,设计了实验。然后我把数据采集和分析环节交给了他,他也很完满地做出了结果。
有了这些经验,他意识到了自己毕业论文数据分析环节的缺失,于是又顺手改进了毕业论文的分析深度。
恰好是周五工作坊当天,我们收到了期刊的正式录用通知。
看得出来,他很激动,也很开心。
深度
确定目标后,你就明白了该学什么,不该学什么。
但是下一个问题就来了,该学的内容,要学到多深、多细呢?
在《贷还是不贷:如何用Python和机器学习帮你决策?》一文里,我们尝试了决策树模型。
所谓应用决策树模型,实际上就是调用了一个包。
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X_train_trans, y_train)
只用了三行语句,我们就完成了决策树的训练功能。
这里我们用的是默认参数。如果你需要了解可以进行哪些参数调整设置,在函数的括号里使用shift+tab按键组合,就能看到详细的参数列表,并且知道了默认的参数取值是多少。
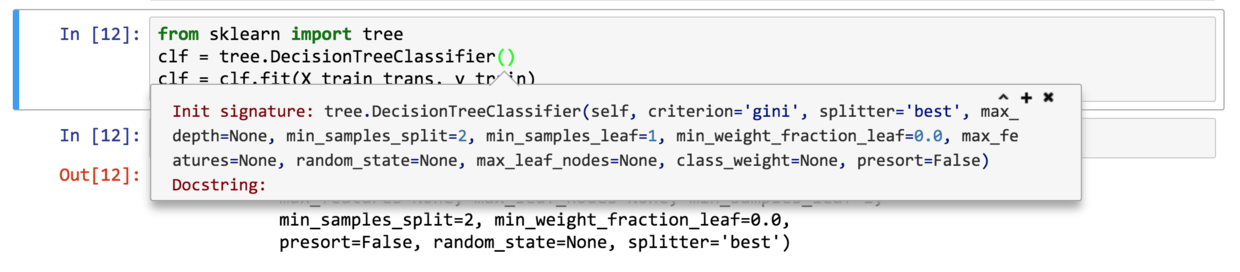
如果你需要更详细的说明,可以直接查文档。在搜索引擎里搜索sklearn tree DecisionTreeClassifier这几个关键词,你会看到以下的结果。
点击其中的第一项,就可以看到最新版本scikit-learn相关功能的官方文档。
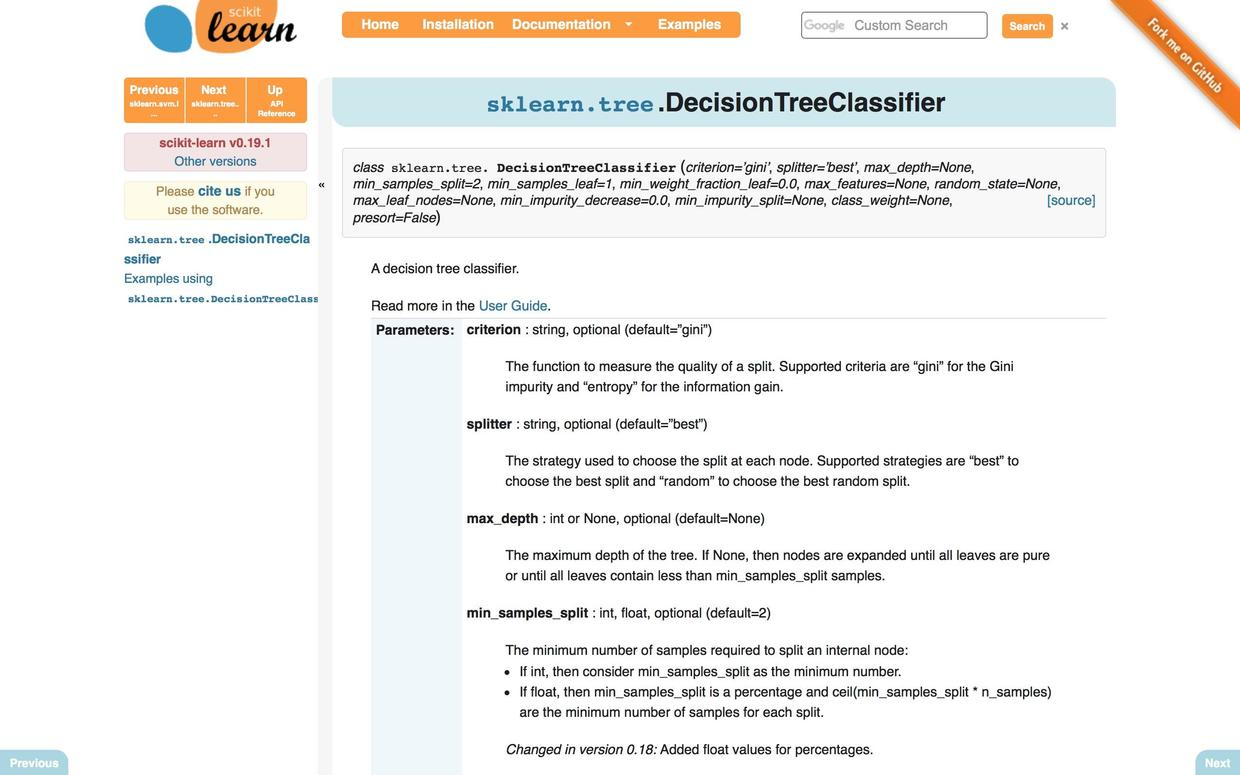
当你明白了每个函数工作的方法、参数可以调整的类型和取值范围时,你是否可以宣称自己了解这个功能了?
你好像不太有信心。
因为你觉得这只是“知其然”,而没有做到“知其所以然”。
但是,你真的需要进一步了解这个函数/功能是如何实现的吗?
注意图中函数定义部分,有一个指向source的链接。

点开它,你就会导航到这个函数的源代码,托管在github上。

如果你是个专业人士,希望研究、评估或者修改该函数,认真阅读源代码就不仅必要,而且必须。
但是作为文科生的你,如果仅是为了应用,那完全可以不必深入到这样的细节。将别人写好的,广受好评的软件包当成黑箱,正确地使用就好了。
这就如同你不需要了解电路原理,就可以看电视;不需要了解川菜的技艺和传承,就可以吃麻婆豆腐。只要你会用遥控器,会使筷子,就能享受这些好处。
越来越多的优秀软件包被创造出来,数据科学的门槛也因此变得越来越低。甚至低到被声讨的地步。例如这篇帖子,就大声疾呼“进入门槛太低正在毁掉深度学习的名声!”
但是,不要高兴得太早。觉得自己终于遇到一门可以投机取巧的学问了。
你的基础必须打牢。
数据科学应用的基础,主要是编程、数学和英语。
数学(包括基础的微积分和线性代数)和英语许多本科专业都会开设。文科生主要需要补充的,是编程知识。
只有明白基础的语法,你才能和计算机之间无障碍交流。
一门简单到令人发指的编程语言,可以节省你大量的学习时间,直接上手做应用。
程序员圈子里,流行一句话,叫做:
人生苦短,我用Python。
Python有多简单?我的课上,一个会计学本科生,为了拿下证书去学Python基础语法,一门课在24小时内,便搞定了。这还包括做习题、项目和系统判分时间。
怎么高效入门和掌握Python呢?欢迎读读《如何高效学Python?》,希望对你快速上手能有帮助。
协作
了解了该学什么,学多深入之后,我们来讲讲提升学习效率的终极秘密武器。
这个武器,就是协作的力量。
协作的好处,似乎本来就是人人都知道的。
但是,在实践中,太多的人根本就没有这样做。
因为,我们都过于长期地被训练“独立”完成问题了。
例如考试的时候跟别人交流,那叫作弊。
但是,你即便再习惯一个人完成某些“创举”,也不得不逐渐面对一个真实而残酷的世界——一个人的单打独斗很难带来大成就,你必须学会协作。
这就像《权力的游戏》里史塔克家族的名言:
When the cold winds blow the lone wolf dies and the pack survives. (凛冬将至,独狼死,群狼活。)

文科生面对屏幕编程,总会有一种孤独无助的感觉,似乎自己被这个世界抛弃了。
这种错误的心态会让你变得焦虑、恐慌,而且很容易放弃。
正确的概念却能够拯救你——你正在协作。而且你需要主动地、更好地协作。
你面前这台电脑或者移动终端,就是无数人的协作成果。
你用的操作系统,也是无数人的协作成果。
你用的编程语言,还是无数人的协作成果。
你调用的每一个软件包,依然是无数人的协作成果。
并非只有你所在的小团队沟通和共事,才叫做协作。协作其实早已发生在地球级别的尺度上。
当你从Github上下载使用了某个开源软件包的时候,你就与软件包的作者建立了协作关系。想想看,这些人可能受雇于大型IT企业,月薪6位数(美元),能跟他们协作不是很难得的机会吗?
当你在论坛上抛出技术问题、并且获得解答的时候,你就与其他的使用者建立了协作关系。这些人有可能是资深的IT技术专家,做咨询的收费是按照秒来算的。
这个社会,就是因为分工协作,才变得更加高效的。
数据科学也是一样。Google, 微软等巨头为什么开源自己的深度学习框架,给全世界免费使用?正是因为他们明白协作的终极含义,知道这种看似吃亏的傻事儿,带来的回报无法估量。

这种全世界范围内的协作,使得知识产生的速度加快,用户的需求被刻画得更清晰透彻,也使得技术应用的范围和深度空前提高。
如果你在这个协作系统里,就会跟系统一起日新月异地发展。如果你不幸自外于这个系统,就只能落寞地看着别人一飞冲天了。
这样的时代,你该怎么更好地跟别人协作呢?
首先,你要学会寻找协作的伙伴。这就需要你掌握搜索引擎、问答平台和社交媒体。不断更新自己的认知,找到更适合解决问题的工具,向更可能回答你问题的人来提问。经常到Github和Stackoverflow上逛一逛,收获可能大到令你吃惊。
其次,你要掌握清晰的逻辑和表达方式。不管是搜寻答案,还是提出问题,逻辑能力可以帮助你少走弯路,表达水平决定了你跟他人协作的有效性和深度。具体的阐释,请参考《Python编程遇问题,文科生怎么办?》。
第三,不要只做个接受帮助者。要尝试主动帮助别人解决问题,把自己的代码开源在Github上,写文章分享自己的知识和见解。这不仅可以帮你在社交资本账户中储蓄(当你需要帮助的时候,相当于在提现),也可以通过反馈增长自己的认知。群体的力量可以通过“赞同”、评论等方式矫正你的错误概念,推动你不断进步。
可以带来协作的链接,就在那里。
你不知道它们的存在,它们对你来说就是虚幻。
你了解它们、掌握它们、使用它们,它们给你带来的巨大益处,就是实打实的。
小结
我们谈了目标,可以帮助你分清楚哪些需要学,哪些不需要学。你现在知道了找到目标的有效方法——项目实践或者案例学习。
我们聊了深度,你了解到大部分的功能实现只需要了解黑箱接口就可以,不需要深入到内部的细节。然而对于基础知识和技能,务必夯实,才能走得更远。
我们强调了协作。充分使用别人优质的工作成果,主动分享自己的认知,跟更多优秀的人建立链接。摆脱单兵作战的窘境,把自己变成优质协作系统中的关键节点。
愿你在学习数据科学过程中,获得认知的增长,享受知识和技能更新带来的愉悦。放下焦虑感,体验心流的美好感受。
讨论
到今天为止,你掌握了哪些数据科学知识和技能?你为此花了多少时间?这个过程痛苦吗?有没有什么经验教训可以供大家借鉴?欢迎留言,把你的感悟分享给大家,我们一起交流讨论。
喜欢请点赞。还可以微信关注和置顶我的公众号“玉树芝兰”(nkwangshuyi)。
如果你对数据科学感兴趣,不妨阅读我的系列教程索引贴《如何高效入门数据科学?》,里面还有更多的有趣问题及解法。
