

本文首发自集智专栏
不管是大公司也好,小公司也罢,为用户创建感性的参与体验都是一个重要目标,而这个过程往往通过原型设计、程序设计和用户测试这几个部分之间快速循环来完成。对于大型公司,比如 Facebook,它们有足够的专用带宽,可供整个团队设计前面所说的所有流程,通常要花费几周的时间;而小型公司由于没有此类资源支持,往往得到很不理想的用户界面。
本文我将分享如何用深度学习算法大幅简化设计工作流,从而让任何体量的公司都能快速创建测试网页。
项目代码地址见文末
当前的设计工作流
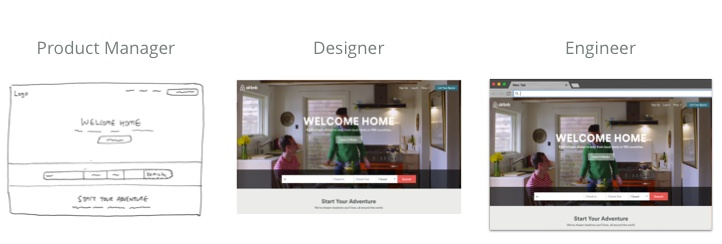
当前一个典型的设计工作流可能如下所示:
-
产品经理进行用户调查后,列出一系列的要求。
-
设计师根据需求,探索低保真原型,最终创建高保真产品模型。
-
工程师用代码实现设计,最终将产品传达给用户。
这种冗长的开发流程很多时候会成为制约企业的瓶颈问题,因此一些公司比如 Airbnb,已经开始用机器学习让开发流程更加高效。
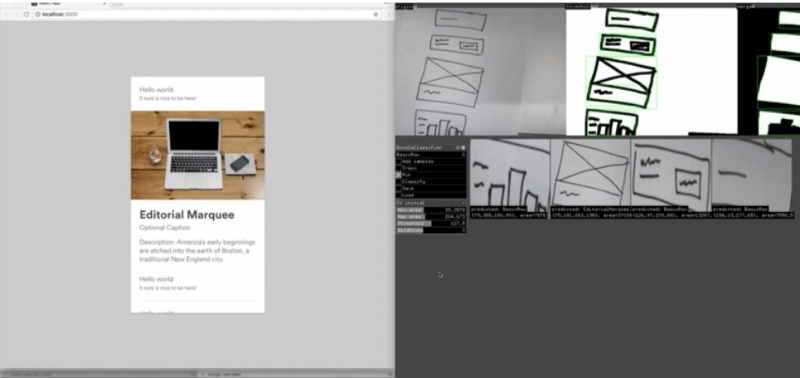
但是这些公司应用的方法到底如何,外界不得而知。因此我决定研究一种开源版的网页自动开发技术,让广大开发者和设计师都能从中受益。
理想状况下,我的模型能够根据网站设计的简单手绘图,立刻生成可以运行的 HTML 网站:
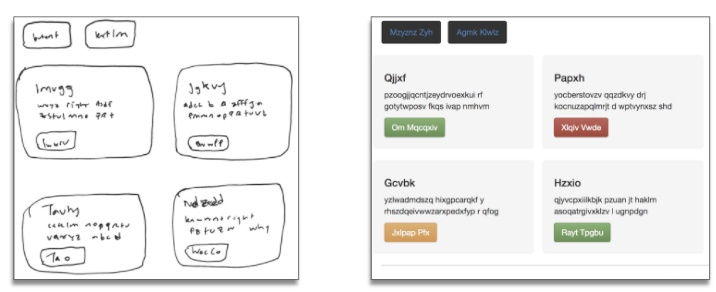
实际上,上面的例子就是我的模型根据测试照片实际生成的一个网站。可以在我的 GitHub 上查看生成该网站的代码。
从图片描述中汲取灵感
我要解决的问题,从大的方向上可以归类为一种叫做“程序综合”的任务,也就是自动生成能够运行的源代码。虽然大部分程序综合处理的是自然语言指令或执行追踪中生成的代码,但我的模型还能在开始时利用源图像(手绘的示意图)。
机器学习领域有个充分研究的方向叫做图像描述,这种方法会学习将图像和文本相匹配的模型,专为源图像中的内容生成文本描述。
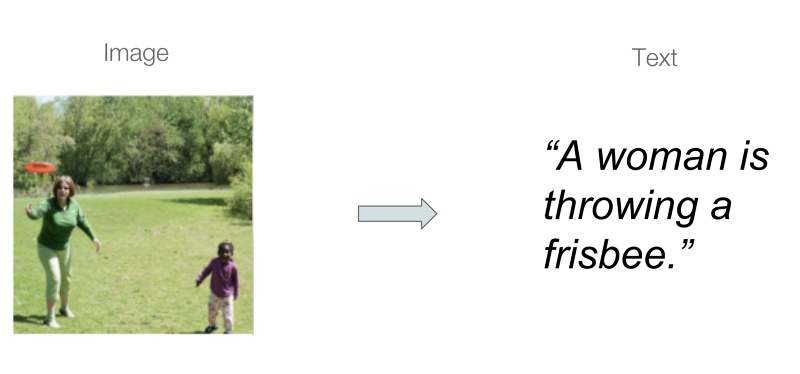
在观摩学习了最近发表的称为pix2code的论文和Emil Wallner的相关项目后,我获得了一些启发,决定将我的任务归类为图像描述,也就是将手绘的网站示意图看作输入图像,而对应的HTML代码就相当于图像的输出文本。
获取正确的数据集
如果是用图像描述这种方法,我理想中的训练数据集应当是几千张手绘的网站设计图及其对应的 HTML 代码。意料之中,这种正好符合要求的数据集根本找不到,因此我只能自己创建任务需要的数据集。
我首先使用来自pix2code论文的开源数据集,包含了1750张综合生成的网站及其相关源代码的截图。
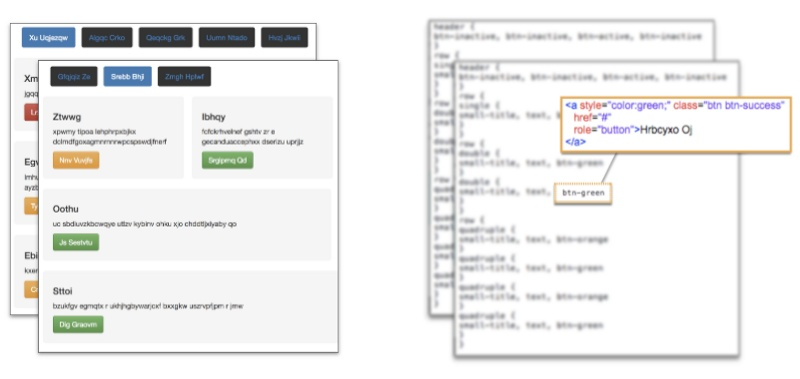
就我的项目的开始阶段而言,这是个很好的数据集,有几个很有趣的亮点:
- 数据集中每个生成的网站都包含几个简单的引导元素的组合,比如按钮、文本框、div 等。虽然这意味着我的模型会局限于生成这几个元素,但这种方法也能很容易的泛化,生成更大规模的元素。
- 每个样本的源代码包含了来自论文作者为相应任务创建的 DSL(特定域语言)中的 token。每个 token 对应一段 HTML 和 CSS 脚本,然后会用一个编译器将 DSL 转换为运行的 HTML 代码。
让图像具有设计草图的效果
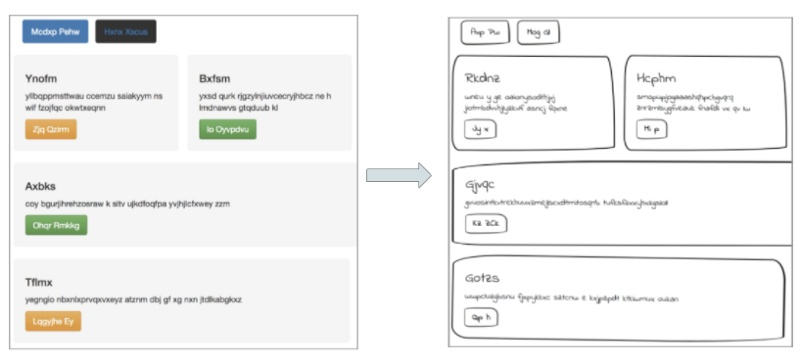
为了修正数据集,更好的适应我的任务,我需要让网站图像看起来是用手画出来的一样。我用了一些工具,比如 OpenCV 和 Python 库 PIL,修改了每张图像的信息,比如灰度转换、轮廓检测等。
最终,我决定直接修改初始网站的 CSS 样式表,进行了一系列的操作:
- 改变网页上各元素的边界值,将按钮和 div 的四角变为曲线。
- 调整边界的厚度以模仿手绘示意图,并添加阴影。
- 将字体改为看上去像手绘的字体。
- 最后一步,增强图像的效果,比如为图像添加斜线、移位和旋转等效果,模仿真实手绘中变化多端的风格。
使用图像描述模型架构
现在,需要的数据已经备好,终于可以将数据输入到模型中了!
我采用了应用于图像描述部分的模型架构,主要包含 3 个主要部分:
- 一个使用了卷积神经网络的计算机视觉模型,用以从源图像中提取图像特征。
- 一个包含 GRU 的语言模型,能够编码源代码 token 的序列。
- 一个编码器模型(也是个 GRU),它会将前面两个部分的输出用作输入,预测序列中的下一个 token。
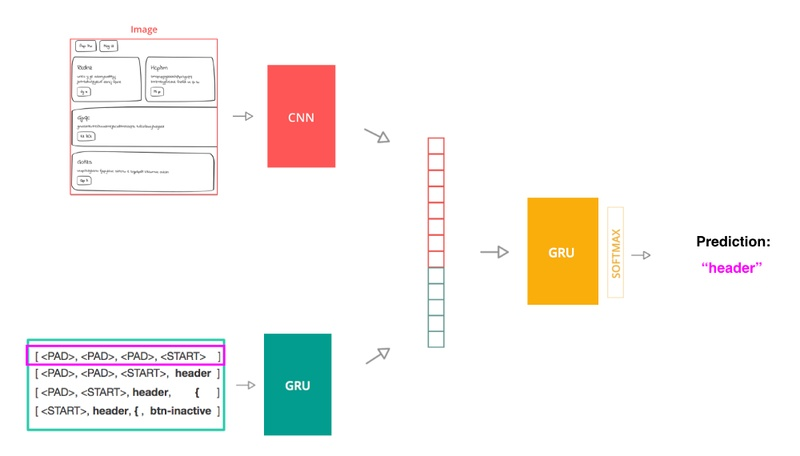
为了能训练模型,我将源代码拆分为 token 的序列。模型的每个输入就是一个 token 序列,并配有和序列对应的源图像,其标签为文件中的下一个 token。模型使用交叉熵代价函数作为其损失函数,它会将模型预测的下一个 token 和实际的下一个 token 进行比较。
在推理阶段,当模型从零开始生成代码时,过程会有所不同。图像仍然是通过 CNN 神经网络处理,但只用起始序列进行文本处理。模型对序列中下一个 token 的预测,在每一步都会添加至当前输入序列,并作为一个新的输入序列输入到模型中。这个过程会反复进行,直到模型预测出一个 token 或者用尽了每个文件中的 token 数量。
用 BLEU 得分评估模型
我决定用 BLEU 得分评估模型。BLEU 得分是应用在机器翻译任务中的常见指标,用来衡量输入相同的情况下,机器生成文本和人类生成文本的接近程度。
基本上,BLEU 会比较生成文本和引用文本这两者的 N-Gram 序列,以改进的形式表示模型的精确度。这对本项目来说非常合适,因为它会将生成的 HTML 中的实际元素以及它们之间的关系考虑进来。
更棒的是,我能通过检查生成的网站查看 BLEU 得分。
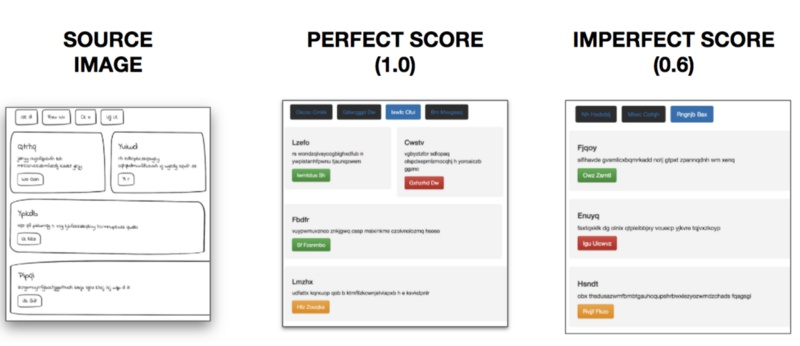
最高 BLEU 得分 1.0 表示模型能根据源图像生成正确的网页元素,且各元素均在正确的位置。 BLEU 得分很低则表示模型没有正确生成元素,或将元素放在了错误的位置。最终用评估数据集对模型进行评估时,显示模型得到了 0.76 的 BLEU 得分。也就是说我搭建的模型,能正确的将 76% 的设计草图短短几秒钟内转换为 HTML 代码。
额外福利——自定义网站风格
我后来意识到还有一个额外的福利。由于模型只生成了网页的框架(文件的 token),那么我可以在编译过程中添加一个自定义 CSS 层,这样模型就能即刻让生成的网站拥有多种不同的风格。
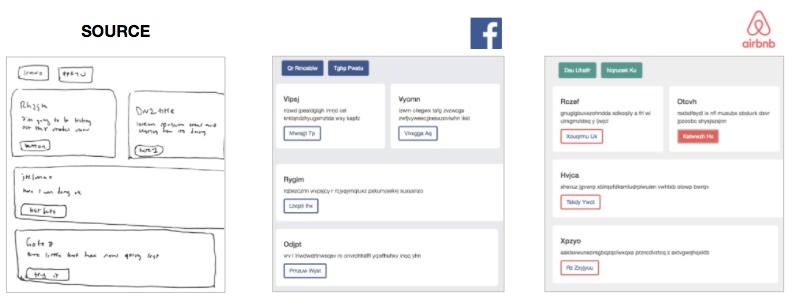
让网站风格和模型生成过程相分离,能让使用模型时具备几个很大的优势:
- 想将我的模型整合到自家公司产品的前端工程师,在使用模型时只需改变单个 CSS 文件以符合公司的设计风格即可。
- 内置可伸缩性能。根据一张源图像,模型输出就能编译为 5 个、10 个甚至 50 个不同的预定义风格,因此用户可以在浏览器上预览网站多个风格版本的效果。
结语及未来展望
通过使用图像描述领域的研究方法,我搭建了一个深度学习模型,能够将手绘的网站设计图在几秒钟内转换为可以运行的 HTML 网站。
当然模型也存在一些局限,未来我可能从以下几个方面优化:
- 由于只用了 16 个元素训练模型,因此模型尚不能预测它没有见过的 token。未来我会用更多元素,比如图像、下拉菜单和表格等训练模型生成更多的网站样本,先从引导元素开始。
- 现实中的网站都有很多变化。未来我会创建更能灵活应对这些变化的训练数据集,彻底弄懂实际中真实的网站,捕捉它们的 HTML/CSS 代码以及网站内容的截图。
- 手绘图同样变化多端,CSS 修改技巧也无法完全捕捉到。用生成式对抗网络创建看起来真实感很强的网站图像,可以让手绘草图数据具有更多的变化。
本项目全部代码见我的GitHub库
限时折扣中:0806期《人工智能-从零开始到精通》(前25位同学可领取¥200优惠券)
