

流(stream),看一个人流不流逼,就看你对流的理解了
学习本无底,前进莫徬徨
今天跟大家分享的是node.js中的流(stream)。它的作用大家应该都在平常使用node的时候看到过,比如:
gulp中的pipe就是流的一种方法,通过可写流和可读流的配合,达到不占用多余缓存的一种读写方式。- express和koa中的res和req也是流,res是
可写流,req是可读流,他们都是通过封装node中的net模块的socket(双工流,即可写、可读流)而来的。 - 。。。
可能很多时候大家都知道怎么用,但不了解它的原理,很尴尬,就像这样

何谓流?
- 流是一组有序的,有起点和终点的字节数据传输手段。
- 它不关心文件的整体内容,只关注是否从文件中读到了数据,以及读到数据之后的处理。
- 流是一个抽象接口,被 Node 中的很多对象所实现。比如HTTP 服务器request和response对象都是流。
- 流被分为
Readable(可读流)、Writable(可写流)、Duplex(双工流)、Transform(转换流)
流中的是什么?
二进制模式:每个分块都是buffer、string对象。对象模式:流内部处理的是一系列普通对象。
可读流
可读流分为
flowing和paused两种模式
参数
path:读取的文件的路径option:highWaterMark:水位线,一次可读的字节,一般默认是64kflags:标识,打开文件要做的操作,默认是rencoding:编码,默认为bufferstart:开始读取的索引位置end:结束读取的索引位置(包括结束位置)autoClose:读取完毕是否关闭,默认为true
let ReadStream = require('./ReadStream')
//读取的时候默认读64k
let rs = new ReadStream('./a.txt',{
highWaterMark: 2,//一次读的字节 默认64k
flags: 'r', //标示 r为读 w为写
autoClose: true, //默认读取完毕后自动关闭
start: 0,
end: 5, //流是闭合区间包start,也包end 默认是读完
encoding: 'utf8' //默认编码是buffer
})
方法
data:切换到流动模式,可以流出数据
rs.on('data', function (data) {
console.log(data);
});
open:流打开文件的时候会触发此监听
rs.on('open', function () {
console.log('文件被打开');
});
error:流出错的时候,监听错误信息
rs.on('error', function (err) {
console.log(err);
});
end:流读取完成,触发end
rs.on('end', function (err) {
console.log('读取完成');
});
close:关闭流,触发
rs.on('close', function (err) {
console.log('关闭');
});
pause:暂停流(改变流的flowing,不读取数据了);resume:恢复流(改变流的flowing,继续读取数据)
//流通过一次后,停止流动,过了2s后再动
rs.on('data', function (data) {
rs.pause();
console.log(data);
});
setTimeout(function () {
rs.resume();
},2000);
fs.read():可读流底层调用的就是这个方法,最原生的读方法
//fd文件描述符,一般通过fs.open中获取
//buffer是读取后的数据放入的缓存目标
//0,从buffer的0位置开始放入
//BUFFER_SIZE,每次放BUFFER_SIZE这么长的长度
//index,每次从文件的index的位置开始读
//bytesRead,真实读到的个数
fs.read(fd,buffer,0,BUFFER_SIZE,index,function(err,bytesRead){
})
那让我们自己来实现一个可爱的读流吧!

let fs = require('fs')
let EventEmitter = require('events')
class ReadStream extends EventEmitter{
constructor(path,options = {}){
super()
this.path = path
this.highWaterMark = options.highWaterMark || 64*1024
this.flags = options.flags || 'r'
this.start = options.start || 0
this.pos = this.start //会随着读取的位置改变
this.autoClose = options.autoClose || true
this.end = options.end || null
//默认null就是buffer
this.encoding = options.encoding || null
//参数的问题
this.flowing = null //非流动模式
//创建个buffer用来存储每次读出来的数据
this.buffer = Buffer.alloc(this.highWaterMark)
//打开这个文件
this.open()
//此方法默认同步调用 每次设置on监听事件时都会调用之前所有的newListener事件
this.on('newListener',(type)=>{// 等待着他监听data事件
if(type === 'data'){
this.flowing = true
//开始读取 客户已经监听的data事件
this.read()
}
})
}
//默认第一次调用read方法时fd还没获取 所以不能直接读
read(){
if(typeof this.fd != 'number'){
//等待着触发open事件后fd肯定拿到了 再去执行read方法
return this.once('open',()=>{this.read()})
}
//每次读的时候都要判断一下下次读几个 如果没有end就根据highWaterMark来(读所有的) 如果有且大于highWaterMark就根据highWaterMark来 如果小于highWaterMark就根据end来
let howMuchToRead = this.end?Math.min(this.end - this.pos + 1,this.highWaterMark):this.highWaterMark
fs.read(this.fd,this.buffer,0,howMuchToRead,this.pos,(err,byteRead)=>{
this.pos += byteRead
let b = this.encoding?this.buffer.slice(0,byteRead).toString(this.encoding):this.buffer.slice(0,byteRead)
this.emit('data',b)
//如果读取到的数量和highWaterMark一样 说明还得继续读
if((byteRead === this.highWaterMark)&&this.flowing){
this.read()
}
if(byteRead < this.highWaterMark){
this.emit('end')
this.destory()
}
})
}
destory(){
if(typeof this.fd != 'number'){
return this.emit('close')
}
//如果文件被打开过 就关闭文件并且触发close事件
fs.close(this.fd,()=>{
this.emit('close')
})
}
pause(){
this.flowing = false
}
resume(){
this.flowing = true
this.read()
}
open(){
//fd表示的就是当前this.path的这个文件,从3开始(number类型)
fs.open(this.path,this.flags,(err,fd)=>{
//有可能fd这个文件不存在 需要做处理
if(err){
//如果有自动关闭 则帮他销毁
if(this.autoClose){
//销毁(关闭文件,触发关闭文件事件)
this.destory()
}
//如果有错误 就会触发error事件
this.emit('error',err)
return
}
//保存文件描述符
this.fd = fd
//当文件打开成功时触发open事件
this.emit('open',this.fd)
})
}
}
Readable
这个方法是可读流的一种
暂停模式,他的模式可以参考为读流是往水杯倒水的人,Readable是喝水的人,他们之间存在着一种联系,只要Readable喝掉一点水,读流就会继续往里倒。
Readable是什么?
- 他会在刚开始监听Readable的时候就触发流的,此时流就会读取一次数据,之后
流会监听,如果有人读过流(喝过水),并且减少,就会再去读一次(倒点水) - 主要可以用来做
行读取器(LineReader)
let fs = require('fs')
let read = require('./ReadableStream')
let rs = fs.createReadStream('./a.txt', {
//每次读7个
highWaterMark: 7
})
//如果读流第一次全部读下来并且小于highWaterMark,就会再读一次(再触发一次readable事件)
//如果rs.read()不加参数,一次性读完,会从缓存区再读一次,为null
//如果readable每次都刚好读完(即rs.read()的参数刚好和highWaterMark相等),就会一直触发readable事件,如果最后不足他想喝的数,他就会先触发一次null,最后把剩下的喝完
//一开始缓存区为0的时候也会默认调一次readable事件
rs.on('readable', () => {
let result = rs.read(2)
console.log(result)
})
实战:行读取器(平常我们的文件可能有回车、换行,此时如果要每次想读一行的数据,就得用到readable)
let EventEmitter = require('events')
//如果要将内容全部读出就用on('data'),精确读取就用on('readable')
class LineReader extends EventEmitter {
constructor(path) {
super()
this.rs = fs.createReadStream(path)
//回车符的十六进制
let RETURN = 0x0d
//换行符的十六进制
let LINE = 0x0a
let arr = []
this.on('newListener', (type) => {
if (type === 'newLine') {
this.rs.on('readable', () => {
let char
//每次读一个,当读完的时候会返回null,终止循环
while (char = this.rs.read(1)) {
switch (char[0]) {
case RETURN:
break;
//Mac下只有换行符,windows下是回车符和换行符,需要根据不同的转换。因为我这里是Mac
case LINE:
//如果是换行符就把数组转换为字符串
let r = Buffer.from(arr).toString('utf8')
//把数组清空
arr.length = 0
//触发newLine事件,把得到的一行数据输出
this.emit('newLine', r)
break;
default:
//如果不是换行符,就放入数组中
arr.push(char[0])
}
}
})
}
})
//以上只能取出之前的换行符前的代码,最后一行的后面没有换行符,所以需要特殊处理。当读流读完需要触发end事件时
this.rs.on('end', () => {
//取出最后一行数据,转成字符串
let r = Buffer.from(arr).toString('utf8')
arr.length = 0
this.emit('newLine', r)
})
}
}
let lineReader = new LineReader('./a.txt')
lineReader.on('newLine', function (data) {
console.log(data)
})
那么Readable到底是怎样的存在呢?我们接下来实现他的源码,看看内部到底怎么回事
let fs = require('fs')
let EventEmitter = require('events')
class ReadStream extends EventEmitter{
constructor(path,options = {}){
super()
this.path = path
this.highWaterMark = options.highWaterMark || 64*1024
this.flags = options.flags || 'r'
this.start = options.start || 0
this.pos = this.start //会随着读取的位置改变
this.autoClose = options.autoClose || true
this.end = options.end || null
//默认null就是buffer
this.encoding = options.encoding || null
//参数的问题
this.reading = false //非流动模式
//创建个buffer用来存储每次读出来的数据
this.buffers = []
//缓存区长度
this.len = 0
//是否要触发readable事件
this.emittedReadable = false
//触发open获取文件的fd标识符
this.open()
//此方法默认同步调用 每次设置on监听事件时都会调用之前所有的newListener事件
this.on('newListener',(type)=>{// 等待着他监听data事件
if(type === 'readable'){
//开始读取 客户已经监听的data事件
this.read()
}
})
}
//readable真正的源码中的方法,计算出和n最接近的2的幂次数
computeNewHighWaterMark(n) {
n--;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
n++;
return n;
}
read(n){
//当读的数量大于水平线,会通过取2的幂次取比他大和最接近的数
if(this.len < n){
this.highWaterMark = this.computeNewHighWaterMark(n)
//重新触发readbale的callback,所以第一次会触发null
this.emittedReadable = true
//重新读新的水位线
this._read()
}
//真正读取到的
let buffer = null
//说明缓存里有这么多,取出来
if(n>0 && n<=this.len){
//定义一个buffer
buffer = Buffer.alloc(n)
let buf
let flag = true
let index = 0
//[buffer<1,2,3,4>,buffer<1,2,3,4>,buffer<1,2,3,4>]
//每次取出缓存前的第一个buffer
while(flag && (buf = this.buffers.shift())){
for(let i=0;i<buf.length;i++){
//把取出的一个buffer中的数据放入新定义的buffer中
buffer[index++] = buf[i]
//当buffer的长度和n(参数)长度一样时,停止循环
if(index === n){
flag = false
//维护缓存,因为可能缓存中的buffer长度大于n,当取出n的长度时,还会剩下其余的buffer,我们需要切割buf并且放到缓存数组之前
this.len -= n
let r = buf.slice(i+1)
if(r.length){
this.buffers.unshift(r)
}
break
}
}
}
}
//如果缓存区没有东西,等会读完需要触发readable事件
//这里会有一种状况,就是如果每次Readable读取的数量正好等于highWaterMark(流读取到缓存的长度),就会每次都等于0,每次都触发Readable事件,就会每次读,读到没有为止,最后还会触发一下null
if(this.len === 0){
this.emittedReadable = true
}
if(this.len < this.highWaterMark){
//默认,一开始的时候开始读取
if(!this.reading){
this.reading = true
//真正多读取操作
this._read()
}
}
return buffer&&buffer.toString()
}
_read(){
if(typeof this.fd != 'number'){
//等待着触发open事件后fd肯定拿到了 再去执行read方法
return this.once('open',()=>{this._read()})
}
//先读这么多buffer
let buffer = Buffer.alloc(this.highWaterMark)
fs.read(this.fd,buffer,0,buffer.length,this.pos,(err,byteRead)=>{
if(byteRead > 0){
//当第一次读到数据后,改变reading的状态,如果触发read事件,可能还会在触发第二次_read
this.reading = false
//每次读到数据增加缓存取得长度
this.len += byteRead
//每次读取之后,会增加读取的文件的读取开始位置
this.pos += byteRead
//将读到的buffer放入缓存区buffers中
this.buffers.push(buffer.slice(0,byteRead))
//触发readable
if(this.emittedReadable){
this.emittedReadable = false
//可以读取了,默认开始的时候杯子填满了
this.emit('readable')
}
}else{
//没读到就出发end事件
this.emit('end')
}
})
}
destory(){
if(typeof this.fd != 'number'){
return this.emit('close')
}
//如果文件被打开过 就关闭文件并且触发close事件
fs.close(this.fd,()=>{
this.emit('close')
})
}
open(){
//fd表示的就是当前this.path的这个文件,从3开始(number类型)
fs.open(this.path,this.flags,(err,fd)=>{
//有可能fd这个文件不存在 需要做处理
if(err){
//如果有自动关闭 则帮他销毁
if(this.autoClose){
//销毁(关闭文件,触发关闭文件事件)
this.destory()
}
//如果有错误 就会触发error事件
this.emit('error',err)
return
}
//保存文件描述符
this.fd = fd
//当文件打开成功时触发open事件
this.emit('open',this.fd)
})
}
}
- Readable和读流的data的区别就是,Readable可以控制自己从缓存区读多少和控制读的次数,而data是每次读取都清空缓存,读多少输出多少
- 我们可以看一下下面这个例子
let rs = fs.createReadStream('./a.txt')
rs.on('data',(data)=>{
console.log(data)
})
//因为上面的data事件把数据读了,清空缓存区。所以导致下面的readable读出为null
rs.on('readable',()=>{
let result = r.read(1)
console.log(result)
})
自定义可读流
因为createReadStream内部调用了ReadStream类,ReadStream又实现了Readable接口,ReadStream实现了_read()方法,所以我们通过自定义一个类继承stream模块的Readable,并在原型上自定义一个_read()就可以自定义自己的可读流
let { Readable } = require('stream')
class MyRead extends Readable{
//流需要一个_read方法,方法中push什么,外面就接收什么
_read(){
//push方法就是上面_read方法中的push一样,把数据放入缓存区中
this.push('100')
//如果push了null就表示没有东西可读了,停止(如果不写,就会一直push上面的值,死循环)
this.push(null)
}
}
可写流
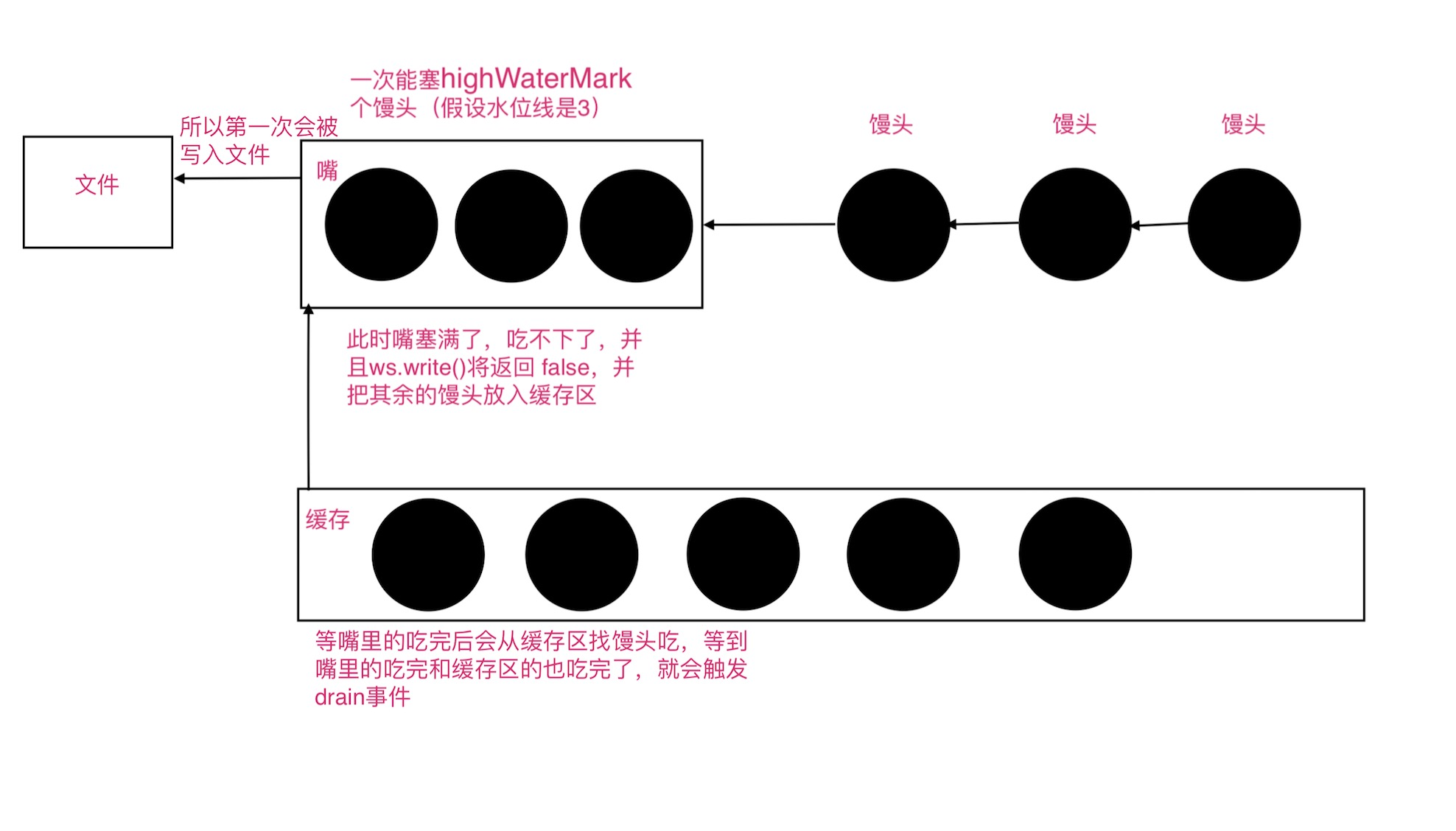
- 如果文件不存在会创建,如果有内容会被清空
- 读取到highWaterMark的时候就会输出
- 第一次是真的写到文件 后面就是写入缓存区 再从缓存区里面去取
参数(和可读流的类似)
path:写入的文件的路径option:highWaterMark:水位线,一次可写入缓存中的字节,一般默认是64kflags:标识,写入文件要做的操作,默认是wencoding:编码,默认为bufferstart:开始写入的索引位置end:结束写入的索引位置(包括结束位置)autoClose:写入完毕是否关闭,默认为true
let ReadStream = require('./ReadStream')
//读取的时候默认读64k
let rs = new ReadStream('./a.txt',{
highWaterMark: 2,//一次读的字节 默认64k
flags: 'r', //标示 r为读 w为写
autoClose: true, //默认读取完毕后自动关闭
start: 0,
end: 5, //流是闭合区间包start,也包end 默认是读完
encoding: 'utf8' //默认编码是buffer
})
方法
write
let fs = require('fs')
let ws = fs.createWriteStream('./d.txt',{
flags: 'w',
encoding: 'utf8',
start: 0,
//write的highWaterMark只是用来触发是不是干了
highWaterMark: 3 //写是默认16k
})
//返回boolean 每当write一次都会在ws中吃下一个馒头 当吃下的馒头数量达到highWaterMark时 就会返回false 吃不下了会把其余放入缓存 其余状态返回true
//write只能放string或者buffer
flag = ws.write('1','utf8',()=>{
console.log(i)
})
drain
//drain只有嘴塞满了 吃完(包括内存中的,就是地下的)才会触发 这里是两个条件 一个是必须是吃下highWaterMark个馒头 并且在吃完的时候才会callback
ws.on('drain',()=>{
console.log('干了')
})
fs.write():可读流底层调用的就是这个方法,最原生的读方法
//wfd文件描述符,一般通过fs.open中获取
//buffer,要取数据的缓存源
//0,从buffer的0位置开始取
//BUFFER_SIZE,每次取BUFFER_SIZE这么长的长度
//index,每次写入文件的index的位置
//bytesRead,真实写入的个数
fs.write(wfd,buffer,0,bytesRead,index,function(err,bytesWrite){
})
通过代码实现
let fs = require('fs')
let EventEmitter = require('events')
//只有第一次write的时候直接用_write写入文件 其余都是放到cache中 但是len超过了highWaterMark就会返回false告知需要drain 很占缓存
//从第一次的_write开始 回去一直通过clearBuffer递归_write写入文件 如果cache中没有了要写入的东西 会根据needDrain来判断是否触发干点
class WriteStream extends EventEmitter{
constructor(path,options = {}){
super()
this.path = path
this.highWaterMark = options.highWaterMark || 64*1024
this.flags = options.flags || 'r'
this.start = options.start || 0
this.pos = this.start
this.autoClose = options.autoClose || true
this.mode = options.mode || 0o666
//默认null就是buffer
this.encoding = options.encoding || null
//打开这个文件
this.open()
//写文件的时候需要哪些参数
//第一次写入的时候 是给highWaterMark个馒头 他会硬着头皮写到文件中 之后才会把多余吃不下的放到缓存中
this.writing = false
//缓存数组
this.cache = []
this.callbackList = []
//数组长度
this.len = 0
//是否触发drain事件
this.needDrain = false
}
clearBuffer(){
//取缓存中最上面的一个
let buffer = this.cache.shift()
if(buffer){
//有buffer的情况下
this._write(buffer.chunk,buffer.encoding,()=>this.clearBuffer(),buffer.callback)
}else{
//没有的话 先看看需不需要drain
if(this.needDrain){
//触发drain 并初始化所有状态
this.writing = false
this.needDrain = false
this.callbackList.shift()()
this.emit('drain')
}
this.callbackList.map(v=>{
v()
})
this.callbackList.length = 0
}
}
_write(chunk,encoding,clearBuffer,callback){
//因为write方法是同步调用的 所以可能还没获取到fd
if(typeof this.fd != 'number'){
//直接在open的时间对象上注册一个一次性事件 当open被emit的时候会被调用
return this.once('open',()=>this._write(chunk,encoding,clearBuffer,callback))
}
fs.write(this.fd,chunk,0,chunk.length,this.pos,(err,byteWrite)=>{
this.pos += byteWrite
//每次写完 相应减少内存中的数量
this.len -= byteWrite
if(callback) this.callbackList.push(callback)
//第一次写完
clearBuffer()
})
}
//写入方法
write(chunk,encoding=this.encoding,callback){
//判断chunk必须是字符串或者buffer 为了统一都变成buffer
chunk = Buffer.isBuffer(chunk)?chunk:Buffer.from(chunk,encoding)
//维护缓存的长度 3
this.len += chunk.length
let ret = this.len < this.highWaterMark
if(!ret){
//表示要触发drain事件
this.needDrain = true
}
//正在写入的应该放到内存中
if(this.writing){
this.cache.push({
chunk,
encoding,
callback
})
}else{
//这里是第一次写的时候
this.writing = true
//专门实现写的方法
this._write(chunk,encoding,()=>this.clearBuffer(),callback)
}
// console.log(ret)
//能不能继续写了 false代表下次写的时候更占内存
return ret
}
destory(){
if(typeof this.fd != 'number'){
return this.emit('close')
}
//如果文件被打开过 就关闭文件并且触发close事件
fs.close(this.fd,()=>{
this.emit('close')
})
}
open(){
//fd表示的就是当前this.path的这个文件,从3开始(number类型)
fs.open(this.path,this.flags,(err,fd)=>{
//有可能fd这个文件不存在 需要做处理
if(err){
//如果有自动关闭 则帮他销毁
if(this.autoClose){
//销毁(关闭文件,出发关闭文件事件)
this.destory()
}
//如果有错误 就会触发error事件
this.emit('error',err)
return
}
//保存文件描述符
this.fd = fd
//当文件打开成功时触发open事件
this.emit('open',this.fd)
})
}
}
自定义可写流
因为createWriteStream内部调用了WriteStream类,WriteStream又实现了Writable接口,WriteStream实现了_write()方法,所以我们通过自定义一个类继承stream模块的Writable,并在原型上自定义一个_write()就可以自定义自己的可写流
let { Writable } = require('stream')
class MyWrite extends Writable{
_write(chunk,encoding,callback){
//write()的第一个参数,写入的数据
console.log(chunk)
//这个callback,就相当于我们上面的clearBuffer方法,如果不执行callback就不会继续从缓存中取出写
callback()
}
}
let write = new MyWrite()
write.write('1','utf8',()=>{
console.log('ok')
})
pipe
管道流,是可读流上的方法,至于为什么放到这里,主要是因为需要2个流的基础知识,是可读流配合可写流的一种
传输方式。如果用原来的读写,因为写比较耗时,所以会多读少写,耗内存,但用了pipe就不会了,始终用规定的内存。
用法
let fs = require('fs')
//pipe方法叫管道 可以控制速率
let rs = fs.createReadStream('./d.txt',{
highWaterMark: 4
})
let ws = fs.createWriteStream('./e,txt',{
highWaterMark: 1
})
//会监听rs的on('data')将读取到的数据,通过ws.write的方法写入文件
//调用写的一个方法 返回boolean类型
//如果返回false就调用rs的pause方法 暂停读取
//等待可写流 写入完毕在监听drain resume rs
rs.pipe(ws) //会控制速率 防止淹没可用内存
自己实现一下
let fs = require('fs')
//这两个是上面自己写的ReadStream和WriteStream
let ReadStream = require('./ReadStream')
let WriteStream = require('./WriteStream')
//如果用原来的读写,因为写比较耗时,所以会多读少写,耗内存
ReadStream.prototype.pipe = function(dest){
this.on('data',(data)=>{
let flag = dest.write(data)
//如果写入的时候嘴巴吃满了就不继续读了,暂停
if(!flag){
this.pause()
}
})
//如果写的时候嘴巴里的吃完了,就会继续读
dest.on('drain',()=>{
this.resume()
})
this.on('end',()=>{
this.destory()
//清空缓存中的数据
fs.fsync(dest.fd,()=>{
dest.destory()
})
})
}
双工流
有了双工流,我们可以在同一个对象上
同时实现可读和可写,就好像同时继承这两个接口。 重要的是双工流的可读性和可写性操作完全独立于彼此。这仅仅是将两个特性组合成一个对象。
let { Duplex } = require('stream')
//双工流,可读可写
class MyDuplex extends Duplex{
_read(){
this.push('hello')
this.push(null)
}
_write(chunk,encoding,clearBuffer){
console.log(chunk)
clearBuffer()
}
}
let myDuplex = new MyDuplex()
//process.stdin是node自带的process进程中的可读流,会监听命令行的输入
//process.stdout是node自带的process进程中的可写流,会监听并输出在命令行中
//所以这里的意思就是在命令行先输出hello,然后我们输入什么他就出来对应的buffer(先作为可读流出来)
process.stdin.pipe(myDuplex).pipe(process.stdout)
转换流
转换流的输出是从输入中
计算出来的。对于转换流,我们不必实现read或write的方法,我们只需要实现一个transform方法,将两者结合起来。它有write方法的意思,我们也可以用它来push数据。
let { Transform } = require('stream')
class MyTransform extends Transform{
_transform(chunk,encoding,callback){
console.log(chunk.toString().toUpperCase())
callback()
}
}
let myTransform = new MyTransform()
class MyTransform2 extends Transform{
_transform(chunk,encoding,callback){
console.log(chunk.toString().toUpperCase())
this.push('1')
// this.push(null)
callback()
}
}
let myTransform2 = new MyTransform2()
//此时myTransform2被作为可写流触发_transform,输出输入的大写字符后,会通过可读流push字符到下一个转换流中
//当写入的时候才会触发transform的值,此时才会push,所以后面的pipe拿到的chunk是前面的push的值
process.stdin.pipe(myTransform2).pipe(myTransform)
总结
可读流
- 在 flowing 模式下, 可读流自动从系统底层读取数据,并通过 EventEmitter 接口的事件尽快将数据提供给应用。
- 在 paused 模式下,必须显式调用 stream.read() 方法来从流中读取数据片段。
- 所有初始工作模式为 paused 的 Readable 流,可以通过下面三种途径切换到 flowing 模式:
- 监听 'data' 事件
- 调用 stream.resume() 方法
- 调用 stream.pipe() 方法将数据发送到 Writable
- 可读流可以通过下面途径切换到 paused 模式:
- 如果不存在管道目标(pipe destination),可以通过调用 stream.pause() 方法实现。
- 如果存在管道目标,可以通过取消 'data' 事件监听,并调用 stream.unpipe() 方法移除所有管道目标来实现。
可写流
- 需要知道只有在
嘴真正的吃满了,并且等到把嘴里的和地上的馒头(缓存中的)都吃下了才会触发drain事件 - 第一次写入会直接写入文件中,后面会从缓存中一个个取
双工流
- 只是对可写可读流的一种应用,既可作为可读流,也能作为可写流,并且作为可读或者可写时时
隔离的
转换流
- 一般转换流是边输入边输出的,而且一般只有触发了写入操作时才会进入
_transform方法中。跟双工流的区别就是,他的可读可写是在一起的。
OK,讲完收工,从此你就是流魔王

