

之前一直说看HashMap源码一直没有看过,以至于面试时候,没能够说清楚很多问题,现在面试基本都会问到的一道问题,就是HashMap源码,你是否看过HashMap源码,HashMap的具体数据结构是怎么的。
大学学习过数据结构,但当时学习得非常抽象,在将来的工作中,数据结构又是在程序里面如何体现的呢。
我之前去学习HashMap源码都是看前辈们分析的博客,从来没有自己去看过,而且也从来没有分析过,对于HashMap的原理也非常模糊。
首先我们需要了解HashMap是种什么数据结构,才能明白具体实现k-v键值对存放数据的原理。
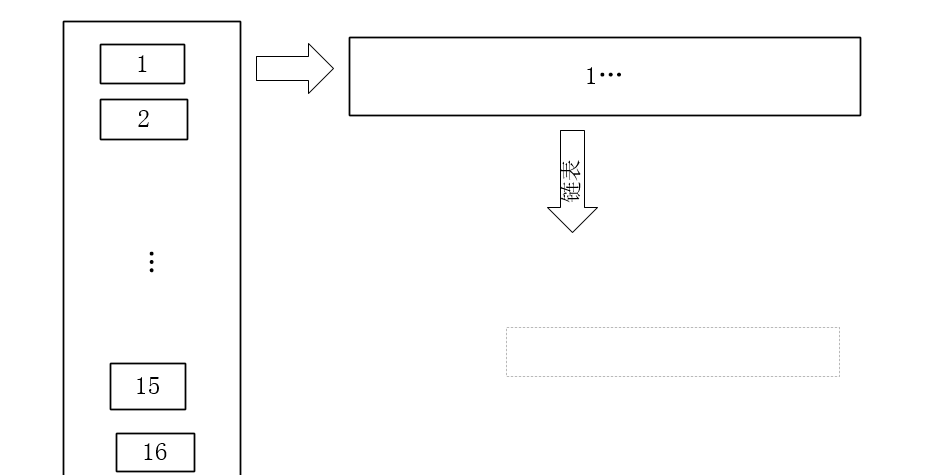
大概数据结构如上,HashMap会是一个数组加链表的数据结构,put的时候,会根据key值计算出数组下标index。可以理解为这个时候,k-v键值对决定存入到哪个具体的链表上,具体我们看源码(本文仅仅先对JDK1.8之前的HashMap源码进行分析):
- 分析源码之前,先明确几个参数:
- static final int DEFAULT_INITIAL_CAPACITY = 1 << 4:默认初始化大小16,该默认大小为数组结构的大小
- static final int MAXIMUM_CAPACITY = 1 << 30:数组结构的最大大小,即便设置数组结构超过该大小,数组大小依然会默认此值
- static final float DEFAULT_LOAD_FACTOR = 0.75f;:默认负载因子大小,数组将以0.75倍扩容
- static final Entry[] EMPTY_TABLE = {}:数组+链表,为空时候的默认值
- transient int size:
- int threshold:发生扩容时候,数组结构的大小
- final float loadFactor:负载因子 我们再来看put和get两个方法:
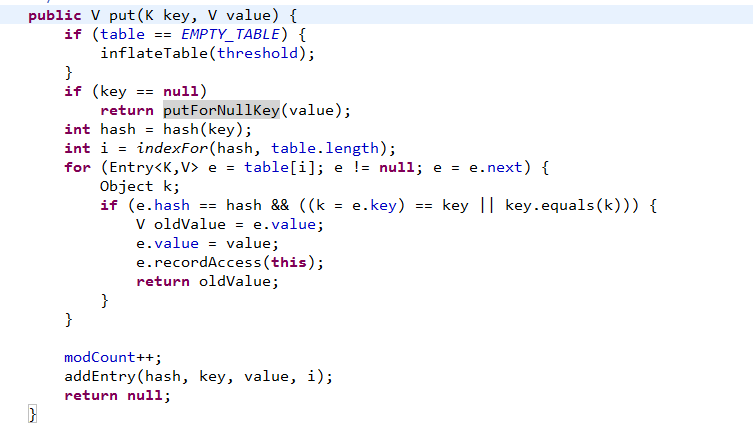
inflateTable(threshold):初始化一个数组+链表结构
putForNullKey(value):key==null时候,会将这个键值对存放至数组的第一位,
indexFor(hash,table.length):先用key计算出hash值,然后再利用hash计算出数组具体的下标,也就是位置
addEntry(hash,key,value,i):将k-v键值对存放到桶中,可理解为存放到具体的数组的某个具体链表的具体位置
这里有两个重点问题:
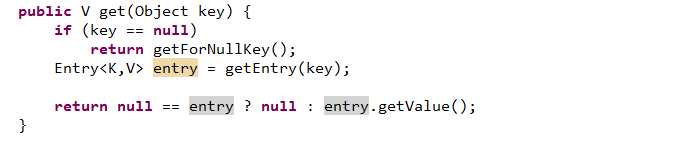
hash碰撞:所谓hash碰撞,简单来说指得就是根据key值计算所得hash值相同,这样一来就会发生hash碰撞,那么hashmap如何解决这种hash碰撞的呢?这样我们就需要具体去看看addEntry(hash,key,value,i)方法。

当两个不同的键却有相同的hashCode时,他们会存储在同一个bucket位置的链表中,Entry就是HashMap中链表最后的面纱。

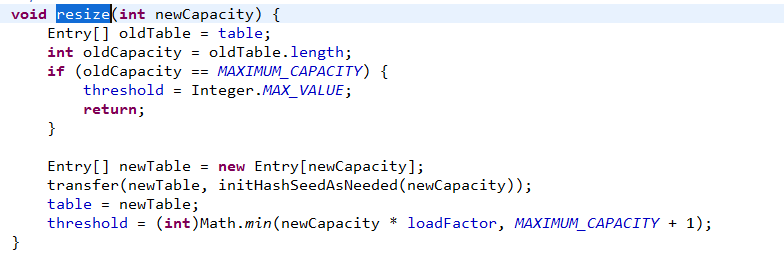
扩容机制:
扩容机制就很简单,主要是对数组结构进行扩容,主要是两倍的数组大小*loadFactor(负载因子),不会超过最大容量。
这里需要注意的是:HashMap很有可能存放了16个k-v键值对,也不会发生扩容,因为其中如果16个k-v键值对中发生hash碰撞,那么这几个k-v键值对就会发生在同一个桶的位置,也就是只会占用16个位置中的一个,并不会发生扩容现象。
简单来说,就是两个key的hash值相同的时候且key值
其他Map成员
其实很多时候,HashMap无法满足线上需要,我们希望HashMap能线程安全,又或者我们希望Map可以通过value找到key,又或者我们希望Map可以排序,等等之类,如果动手去实现这些功能也不无可以,当时确实很多时候我们考虑的需求,有很多先辈们已经实现了。
- 这是最基本的map,其实jdk还实现了其他的map,下面有常用的两个:
CurrentHashMap:线程安全的HashMap,使用了分段锁,在保证了线程安全的同时,也提升了效率
TreeMap:会对Map中的key进行排序,内部数据结构是红黑树
- 我们常用到的一个开源架包Apache的common架包下是实现了很多集合结构的,那我们看看有哪些map结构: BidiMap:即双向Map,可以通过key找到value,也可以通过value找到key。需要注意的是BidiMap中key和value都不可以重复; LinkedMap,可以维护条目顺序的map MultiMap,一个key指向的是一组对象,add()和remove()的时候跟普通的Map无异,只是在get()时返回一个Collection,实现了一对多; LazyMap,即Map中的键/值对一开始并不存在,当被调用到时才创建。
这些Map在实现某些特定的需求,都可以直接拿来使用。
思想借鉴:JDK1.8版本以后,几乎重写了HashMap,下次分析一篇1.8后的HashMap和现在的对比,这种变化又是为何?Map使用了红黑树结构,从而优化HashMap的存储;大量使用三元运算符。
