

作者:xiaoyu
微信公众号:Python数据科学
知乎:python数据分析师

前情回顾
上一篇是数据挖掘的前戏,主要目的是认识数据特征、判断特征重要性、观察数据异常,掌握数据间联系。本篇将继续上一篇分析进行数据挖掘建模部分。
上篇数据分析的链接: 【Kaggle入门级竞赛top5%排名经验分享】— 分析篇
数据预处理
数据预处理涉及的内容很多,也包括特征工程,是任务量最大的一部分。为了让大家更清晰的阅读,以下先列出处理部分大致要用到的一些方法。
- 数据清洗:缺失值,异常值,一致性;
- 特征编码:
one-hot和label coding; - 特征分箱:等频,等距,聚类等;
- 衍生变量:可解释性强,适合模型输入;
- 特征选择:方差选择,卡方选择,正则化等;
1. 数据清洗
分析部分我们看到,存在缺失值的特征有4个:Age,Cabin,Embarked,Fare。关于缺失值处理部分博主之前介绍过一些方法:【Python数据分析基础】: 数据缺失值处理
下面开始对缺失值分别处理。
Fare缺失值处理
首先查看一下Fare特征缺失:
df[df['Fare'].isnull()]

发现只有一个缺失值,其实可以直接删除,但是好多乘客都是以一个家庭来的,这其中会有很强的联系,并会给我们很好的线索,因此选择不删除。
继续观察一下这个缺失值乘客有什么特点?如何利用我们之前的分析来处理?
- 特点1:Pclass为3,我们在分析部分知道Fare和Pclass社会等级有着紧密的关系,Pclass1的Fare相对较高,Fare最低的是Pclass3;
- 特点2:该乘客的Age大于60,且为男性;
这时我们可以使用相似特征替换方法来填补缺失值,下面来找一下与缺失值具有相似特征的其它样本数据:
df.loc[(df['Pclass']==3)&(df['Age']>60)&(df['Sex']=='male')]

找到了与之相匹配的几位其它乘客,我们就用这几位乘客的Fare平均值来填补。
# 提取出Name中的Surname信息
df['surname'] = df["Name"].apply(lambda x: x.split(',')[0].lower())
fare_mean_estimated = df.loc[(df['Pclass']==3)&(df['Age']>60)&(df['Sex']=='male')].Fare.mean()
df.loc[df['surname']=='storey','Fare'] = fare_mean_estimated
Embarked特征缺失值
同样,观察Embarked的缺失值情况:
# Embarked缺失值处理
df[df['Embarked'].isnull()]

发现两位都是女性。上篇可视化分析过,pclass1且为女性的情况下,Q港口几乎为0,而C港口最多,其次S港口,下图为分析篇的可视化结果。
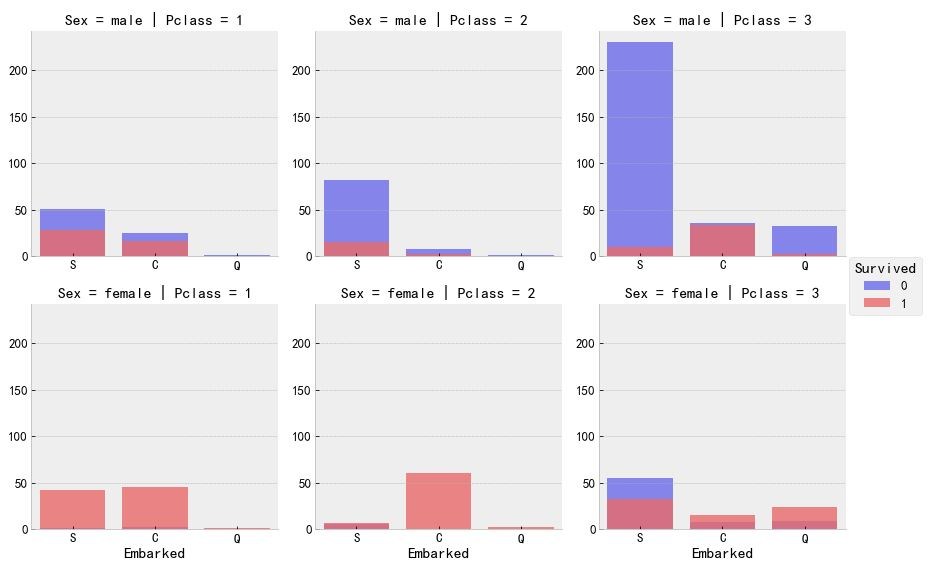
df['Embarked'] = df['Embarked'].fillna('C')
Cabin特征缺失值
Cain特征有70%的缺失值,较为严重,如果进行大量的填补会引入更多噪声。因为缺失值也是一种值,这里将Cabin缺失值视为一种特殊的值来处理,并根据Cabin首个字符衍生一个新的特征CabinCat。
df['CabinCat'] = pd.Categorical.from_array(df.Cabin.fillna('0').apply(lambda x: x[0])).codes
pandas的 Categorical.from_array()用法。代码含义是用“0”替换Cabin缺失值,并将非缺失Cabin特征值提取出第一个值以进行分类,比如A114就是A,C345就是C,如下:
[0, C, 0, C, 0, ..., 0, C, 0, 0, 0]
Length: 1309
Categories (9, object): [0, A, B, C, ..., E, F, G, T]
用Categorical.from_array()将Cabin分成了9组,最后通过codes量化为数字,通过可视化观察一下分组离散化后的结果:
fig, ax = plt.subplots(figsize=(10,5))
sns.countplot(x='CabinCat', hue='Survived',data=df)
plt.show()
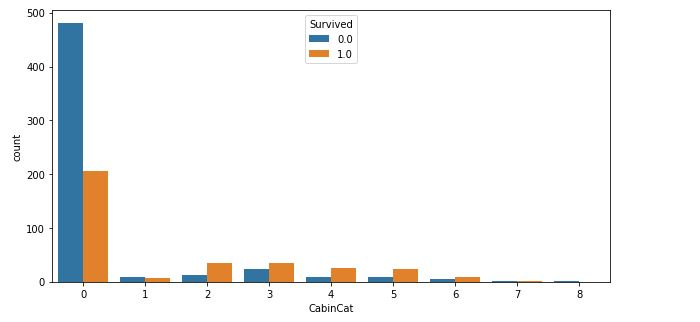
以上可视化看到:Cabin缺失的乘客中,遇难人数是获救人数2倍以上,而其它有Cabin信息的乘客中,获救人数都相对较多。因此说明Cabin缺失与否关系到了生还的概率。
Age特征缺失值
Age有20%缺失值,缺失值较多,大量删除会减少样本信息,由于它与Cabin不同,这里将利用其它特征进行预测填补Age,也就是拟合未知Age特征值,会在后续进行处理。
数据一致性分析
当我们拿到数据后,我们要谨记一个道理:不要完全相信数据。即使不是异常值,也有可能是错误的信息,那就是检查数据的一致性。
本例中,我们通过两个错误的修正来理解一下。
错误1:SibSp和Parch特征存在不一致
df.loc[df['surname']=='abbott',['Name','Sex','Age','SibSp','Parch']]
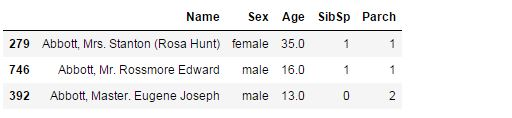
为了方便阅读,下面用序号来代替名字。
首先寻找到了船上姓 abbott 的所有人,即一家人。发现:392 乘客只有13岁,确有两个孩子Parch=2(理论上不太可能),而279乘客35岁,有一个孩子,还有一个兄弟姐妹,746有一个家长和一个兄弟姐妹。很明显,信息是错误的,279与392乘客的信息写反了。正确的信息是一位母亲带着两个孩子,所以改为:279乘客为SibSp=0,Parh=2,392岁的乘客是:SibSp=1, Parh=1。下面是修改代码:
df.loc[(df['surname']=='abbott')&(df['Age']==35),'SibSp'] = 0
df.loc[(df['surname']=='abbott')&(df['Age']==35),'Parch'] = 2
df.loc[(df['surname']=='abbott')&(df['Age']==13),'SibSp'] = 1
df.loc[(df['surname']=='abbott')&(df['Age']==13),'Parch'] = 1
错误2:SibSp和Parch特征存在不一致
df.loc[df['surname']=='ford',['Name','Sex','Age','SibSp','Parch']]
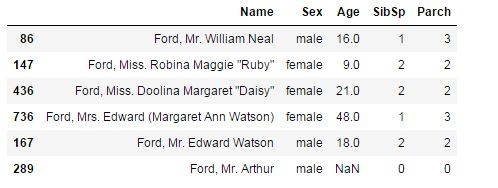
同理,ford一家人也出现了一致性错误的问题,具体大家可自行分析。正确的是:一位母亲带着三个孩子,而最后一位乘客为测试集里的样本,推测很可能是父亲。下面是修改代码:
df.loc[(df['surname']=='ford')&(df['Age']==16),'SibSp'] = 3
df.loc[(df['surname']=='ford')&(df['Age']==16),'Parch'] = 1
df.loc[(df['surname']=='ford')&(df['Age']==9),'SibSp'] = 3
df.loc[(df['surname']=='ford')&(df['Age']==9),'Parch'] = 1
df.loc[(df['surname']=='ford')&(df['Age']==21),'SibSp'] = 3
df.loc[(df['surname']=='ford')&(df['Age']==21),'Parch'] = 1
df.loc[(df['surname']=='ford')&(df['Age']==48),'SibSp'] = 0
df.loc[(df['surname']=='ford')&(df['Age']==48),'Parch'] = 4
df.loc[(df['surname']=='ford')&(df['Age']==18),'SibSp'] = 3
df.loc[(df['surname']=='ford')&(df['Age']==18),'Parch'] = 1
2. 数据变换
衍生变量
分析部分没提及到Name特征,因为每个人的名字都不一样。但是一些人可能是群体行动,比如一家人一起,而一家人的surname是一样的,因此这时候就可以通过surname找到一个家庭群体。家庭群体有什么用?我们后面会提到。
实际上,如果我们深入分析,Name特征是非常重要的。试想一下乘客有没有可能是和其他人一起上船的?是一家人?情侣?还是独自一人?而这一群人生还的概率应该是存在共性的,比如:有一个5人之家,有4人死亡,可以推测第5个人极有可能死亡。
下面是对所有特征进行衍生的新特征变量。
# 从Name中提取Title信息,因为同为男性,Mr.和 Master.的生还率是不一样的
df["Title"] = df["Name"].apply(lambda x: re.search(' ([A-Za-z]+)\.',x).group(1))
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Dr": 5, "Rev": 6, "Major": 7, "Col": 7, "Mlle": 2, "Mme": 3,"Don": 9,"Dona": 9, "Lady": 10, "Countess": 10, "Jonkheer": 10, "Sir": 9, "Capt": 7, "Ms": 2}
# 量化Title信息
df["TitleCat"] = df.loc[:,'Title'].map(title_mapping)
# SibSp和Parch特征进行组合
df["FamilySize"] = df["SibSp"] + df["Parch"] + 1
# 根据FamilySize分布进行分箱
df["FamilySize"] = pd.cut(df["FamilySize"], bins=[0,1,4,20], labels=[0,1,2])
# 从Name特征衍生出Name的长度
df["NameLength"] = df["Name"].apply(lambda x: len(x))
# 量化Embarked特征
df["Embarked"] = pd.Categorical.from_array(df.Embarked).codes
# 对Sex特征进行独热编码分组
df = pd.concat([df,pd.get_dummies(df['Sex'])],axis=1)
下面衍生特征变量的说明:
- Title:从Name中提取Title信息,因为同为男性,Mr.和 Master.的生还率是不一样的;
- TitleCat:映射并量化Title信息,虽然这个特征可能会与Sex有共线性,但是我们先衍生出来,后进行筛选;
- FamilySize:可视化分析部分看到SibSp和Parch分布相似,固将SibSp和Parch特征进行组合;
- NameLength:从Name特征衍生出Name的长度,因为有的国家名字越短代表越显贵;
- CabinCat:Cabin的分组信息; 高级衍生变量
【1】人物衍生特征
由于儿童的生还率较高,因此将所有乘客儿童单独提取出来(这里设置为18岁)。而对于成年人女性生还概率比较高,所以又非为成年女性和成年男性。代码如下:
# 妇女/儿童 男士标签
child_age = 18
def get_person(passenger):
age, sex = passenger
if (age < child_age):
return 'child'
elif (sex == 'female'):
return 'female_adult'
else:
return 'male_adult'
df = pd.concat([df, pd.DataFrame(df[['Age', 'Sex']].apply(get_person, axis=1), columns=['person'])],axis=1)
df = pd.concat([df,pd.get_dummies(df['person'])],axis=1)
【2】Ticket衍生特征
下面基于Ticket衍生出了几个高级特征变量,其含义:如果几个人拥有相同的Ticket号码,那么意味着他门是一个小群体(一家人或情侣等),而又因为男性女性还概率本省存在差异,因此将分别衍生出几个人物标签特征,即分群体情况下的男女生还特征。以下是代码实现:
table_ticket = pd.DataFrame(df["Ticket"].value_counts())
table_ticket.rename(columns={'Ticket':'Ticket_Numbers'}, inplace=True)
table_ticket['Ticket_dead_women'] = df.Ticket[(df.female_adult == 1.0)
& (df.Survived == 0.0)
& ((df.Parch > 0) | (df.SibSp > 0))].value_counts()
table_ticket['Ticket_dead_women'] = table_ticket['Ticket_dead_women'].fillna(0)
table_ticket['Ticket_dead_women'][table_ticket['Ticket_dead_women'] > 0] = 1.0
table_ticket['Ticket_surviving_men'] = df.Ticket[(df.male_adult == 1.0)
& (df.Survived == 1.0)
& ((df.Parch > 0) | (df.SibSp > 0))].value_counts()
table_ticket['Ticket_surviving_men'] = table_ticket['Ticket_surviving_men'].fillna(0)
table_ticket['Ticket_surviving_men'][table_ticket['Ticket_surviving_men'] > 0] = 1.0
# Ticket特征量化
table_ticket["Ticket_Id"] = pd.Categorical.from_array(table_ticket.index).codes
table_ticket["Ticket_Id"][table_ticket["Ticket_Numbers"] < 3 ] = -1
# Ticket数量分箱
table_ticket["Ticket_Numbers"] = pd.cut(table_ticket["Ticket_Numbers"], bins=[0,1,4,20], labels=[0,1,2])
df = pd.merge(df, table_ticket, left_on="Ticket",right_index=True, how='left', sort=False)
同理,基于衍生变量Surname也可以衍生出高级特征变量,以及Cabin的奇偶性衍生特征。
Age缺失值处理
前面说了将采用拟合的方法来填补Age缺失值,那为什么一定要在后面处理呢?
原因如下:
- 其它特征还存在缺失值,放入拟合模型影响预测效果;
- 特征保持原生符号,还没有进行量化,无法输入模型;
因为上面已经将所提问题解决,因此可以开始拟合Age缺失值。这部分使用了随机森林的ExtraTreesRegressor模型进行拟合,代码如下:
from sklearn.ensemble import RandomForestClassifier, ExtraTreesRegressor
classers = ['Fare','Parch','Pclass','SibSp','TitleCat',
'CabinCat','female','male', 'Embarked', 'FamilySize', 'NameLength','Ticket_Numbers','Ticket_Id']
etr = ExtraTreesRegressor(n_estimators=200,random_state=0)
X_train = df[classers][df['Age'].notnull()]
Y_train = df['Age'][df['Age'].notnull()]
X_test = df[classers][df['Age'].isnull()]
etr.fit(X_train.as_matrix(),np.ravel(Y_train))
age_preds = etr.predict(X_test.as_matrix())
df['Age'][df['Age'].isnull()] = age_preds
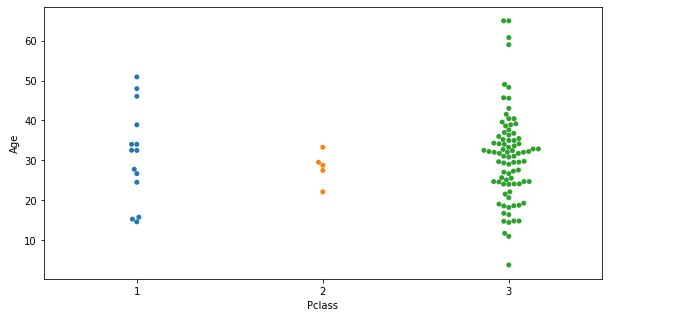
想继续看一下拟合的结果是怎么样,可以通过可视化来观察:
# Age缺失值填补后的情况
X_test['Age'] = pd.Series(age_preds)
f,ax=plt.subplots(figsize=(10,5))
sns.swarmplot(x='Pclass',y='Age',data=X_test)
plt.show()
3. 特征选择
过滤法—方差分析
这里特征采用 ANOVA方差分析的 F值 来对各个特征变量打分,打分的意义是:各个特征变量对目标变量的影响权重。代码如下,使用了sklearn的feature_selection:
from sklearn.feature_selection import SelectKBest, f_classif,chi2
target = data_train["Survived"].values
features= ['female','male','Age','male_adult','female_adult', 'child','TitleCat',
'Pclass','Ticket_Id','NameLength','CabinType','CabinCat', 'SibSp', 'Parch',
'Fare','Embarked','Surname_Numbers','Ticket_Numbers','FamilySize',
'Ticket_dead_women','Ticket_surviving_men',
'Surname_dead_women','Surname_surviving_men']
train = df[0:891].copy()
test = df[891:].copy()
selector = SelectKBest(f_classif, k=len(features))
selector.fit(train[features], target)
scores = -np.log10(selector.pvalues_)
indices = np.argsort(scores)[::-1]
print("Features importance :")
for f in range(len(scores)):
print("%0.2f %s" % (scores[indices[f]],features[indices[f]]))
此部分将之前训练和测试合并的数据集分开,因为最后我们要对测试集进行预测。特征选择权重结果如下(可以通过可视化的方法展示出来):

这里分数越高代表特征权重越大,当然我们可以规定相应的阈值来选择权重大的特征。
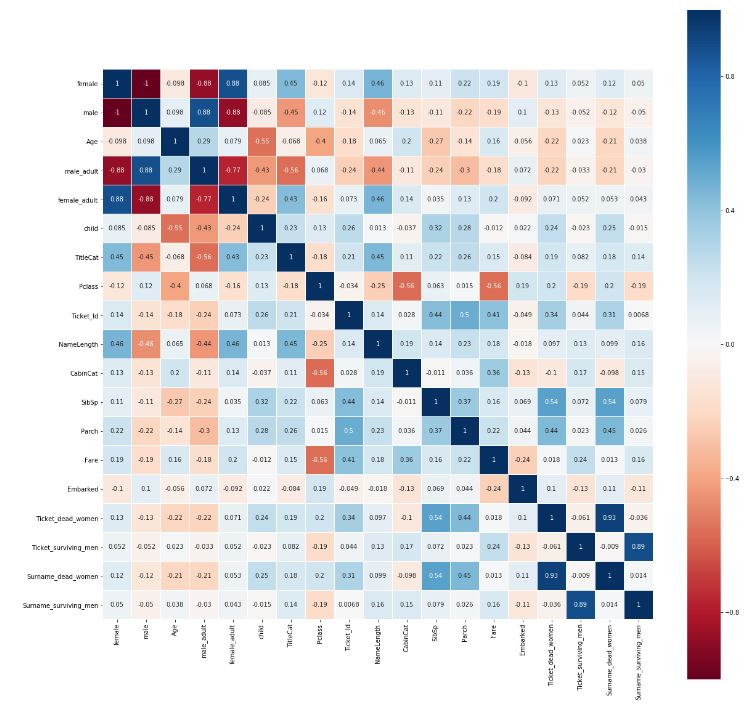
特征相关性分析
除了对特征权重选择外,我们也要分析特征相关性来筛选特征。相关性大的特征容易造成过拟合现象,因此需要进行剔除。最好的情况就是:所有特征相关性很低,各自的方差或者说信息量很高。 使用了seaborn的heatmap展示相关性,代码如下:
features_selected = features
# data_corr
df_corr = df[features_selected].copy()
colormap = plt.cm.RdBu
plt.figure(figsize=(20,20))
sns.heatmap(df_corr.corr(),linewidths=0.1,vmax=1.0, square=True, cmap=colormap, linecolor='white', annot=True)
plt.show()
3 建模预测
创建模型
这是个明显的监督分类问题,因此可选择的模型算法很多,或者模型融合等来提高准确度。这里采用了集成学习的随机森林RandomForest模型。代码如下:
from sklearn import cross_validation
rfc = RandomForestClassifier(n_estimators=3000, min_samples_split=4, class_weight={0:0.745,1:0.255})
# rfc = AdaBoostClassifier(n_estimators=3000, learning_rate=0.1, random_state=1)
# 交叉验证,建模随机森林
kf = cross_validation.KFold(train.shape[0], n_folds=3, random_state=1)
scores = cross_validation.cross_val_score(rfc, train[features_selected], target, cv=kf)
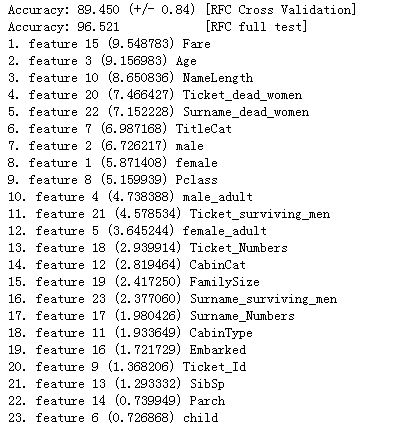
print("Accuracy: %0.3f (+/- %0.2f) [%s]" % (scores.mean()*100, scores.std()*100, 'RFC Cross Validation'))
rfc.fit(train[features_selected], target)
score = rfc.score(train[features_selected], target)
print("Accuracy: %0.3f [%s]" % (score*100, 'RFC full test'))
importances = rfc.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(len(features_selected)):
print("%d. feature %d (%f) %s" % (f + 1, indices[f]+1, importances[indices[f]]*100, features_selected[indices[f]]))
为防止过拟合,采用了K折交叉验证进行采样。集成学习等高级模型有自带的特征打分方法,训练数据后,我们可以通过feature_importances得到特征权重分数(当特征特别多时,也可以作为初始的特征筛选方法)。当然这也可以通过可视化的方法展示出来。
输入结果如下:
模型预测
# 预测目标值
rfc.fit(train[features_selected], target)
predictions = rfc.predict(test[features_selected])
输出文件
# 输出文件
PassengerId =np.array(test["PassengerId"]).astype(int)
my_prediction = pd.DataFrame(predictions, PassengerId, columns = ["Survived"])
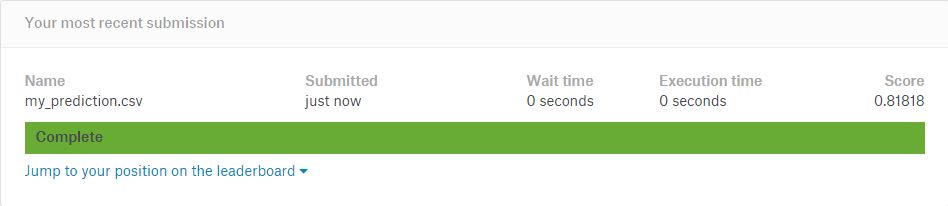
my_prediction.to_csv("my_prediction.csv", index_label = ["PassengerId"])
最后,将预测结果输出到excel表中。如果你到Kaggle将输出的数据提交,你应该得到的分数是:0.8188,也就是说你的准确率是0.8188。这个分数可以达到500/11000的排名(top5%)。
4 总结
本篇分析了数据预处理以及建模的部分,完成了最后的生还者预测,有几下几点还需要提高的地方:
- 寻找更多衍生特征,提高模型输入质量;
- 尝试多种模型,对比预测结果,或者可以使用高级模型融合,以及stacking二次融合优化来提高准确率;
- 尝试多种方法在众多特征中筛选重要特征;
- 对于一些模糊异常值进一步检测和处理;
- 提高填补缺失值的准确度,减少数据中的噪音;
以上就是本次项目的全部内容,后续会继续分享新数据分析挖掘项目,敬请期待。
参考:https://www.kaggle.com/francksylla/titanic-machine-learning-from-disaster/

