

笔者自语: 当有一个面试官问我NSDictionary底层实现原理,我平时开发的时候只是会用而已,哪里知道它的内部实现原理呀,一脸懵逼的样子,感觉跟那个面试的人相差甚远,现在有空来系统整理一下我自己对NSDictionary内部实现原理的理解,真的理解了对你只有好处没有坏处,永远不要说我会用就完了,那只是初级开发工程师的要求不是吗?废话不多说,希望各位引起重视。
一言以蔽之: 在OC中NSDictionary是使用hash表来实现key和value的映射和存储的。
那么问题来了什么是hash表呢?
哈希表(hash表):又叫做散列表,是根据关键码值(key value)而直接访问的数据结构。也就是说它通过关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射叫做函数,存放记录的数组叫做哈希表。
读到此处我们得到一个关键信息:所谓哈希表就是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。看一个示意图就一目了然了:
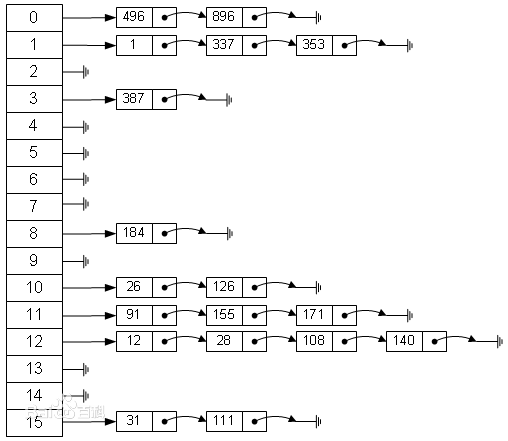
hash表存储过程简单介绍:
- 根据key值计算出它的hash值h;
- 假设箱子的个数是n,那么键值对应该放在第(h%n)个箱子中。
- 如果该箱子中已经有了键值对,就是用开放寻址法或者拉链法解决冲突。使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。
依此我们得出结论: OC中的字典其实是一个数组,数组中每一个元素同样为一个链表实现的数组,也就是数组中套数组。
那么对应在oc中字典是如何进行存储的呢?
在oc中每一个对象创建时,都默认生成一个hashCode,也就是经过hash算法生成的一串数字,当利用key去取字典中的value时,若是使用遍历或者二分查找等方法,效率相对较低,于是出现了根据每一个key生成的hashCode将键值对放到hasCode对应的数组中的指定位置,这样当用key去取值时,便不必遍历去获取,既可以根据hashCode直接取出。因为hashCode的值过大,或许经过取余获取一个较小的数字,假如是对999进行取余运算,那么得到的结果始终处于0-999之间。但是,这样做的弊端在于取余所得到的值,可能是相同的,这样可能导致完全不相干的键值对被新的键值对(取余后值key相等)所覆盖,于是出现了数组中套链表实现的数组。这样,key值取余得到值相等的键值对,都将保存在同一个链表数组中,当查找key对应的值时,首先获取到该链表数组,然后遍历数组,取正确的key所对应的值即可。
至此NSDictionary的底层原理算是基本上讲透彻了,希望对看到者有一定的启示作用,那么笔者就心满意足了。
