

YOLO,即You Only Look Once(你只能看一次)的缩写,是一个基于卷积神经网络(CNN)的物体检测算法。而YOLO v3是YOLO的第3个版本,即YOLO、YOLO 9000、YOLO v3,检测效果,更准更强。
YOLO v3的更多细节,可以参考YOLO的官网。

YOLO是一句美国的俗语,You Only Live Once,你只能活一次,即人生苦短,及时行乐。
本文主要分享,如何实现YOLO v3的算法细节,Keras框架。这是第2篇,模型。当然还有第3篇,至第n篇,毕竟,这是一个完整版 :)
本文的GitHub源码:github.com/SpikeKing/k…
已更新:
- 第1篇 训练:mp.weixin.qq.com/s/T9LshbXoe…
- 第2篇 模型:mp.weixin.qq.com/s/N79S9Qf1O…
- 第3篇 网络:mp.weixin.qq.com/s/hC4P7iRGv…
- 第4篇 真值:mp.weixin.qq.com/s/5Sj7QadfV…
- 第5篇 Loss:mp.weixin.qq.com/s/4L9E4WGSh…
欢迎关注,微信公众号 深度算法 (ID: DeepAlgorithm) ,了解更多深度技术!
入口
在训练中,调用create_model方法创建算法模型。因此,本节重点分析create_model的实现逻辑。
在create_model方法中,创建YOLO v3的算法模型,其中方法参数是:
input_shape:输入图片的尺寸,默认是(416, 416);anchors:默认的9种anchor box,结构是(9, 2);num_classes:类别个数,在创建网络时,只需类别数即可。在网络中,类别值按0~n排列,同时,输入数据的类别也是用索引表示;load_pretrained:是否使用预训练权重。预训练权重,既可以产生更好的效果,也可以加快模型的训练速度;freeze_body:冻结模式,1或2。其中,1是冻结DarkNet53网络中的层,2是只保留最后3个1x1的卷积层,其余层全部冻结;weights_path:预训练权重的读取路径;
如下:
def create_model(input_shape, anchors, num_classes, load_pretrained=True, freeze_body=2,
weights_path='model_data/yolo_weights.h5'):
逻辑
在create_model方法中,先将输入参数,进行处理:
- 拆分图片尺寸的宽h和高w;
- 创建图片的输入层
image_input。在输入层中,既可显式指定图片尺寸,如(416, 416, 3),也可隐式指定,用“?”代替,如(?, ?, 3); - 计算anchor的数量
num_anchors; - 根据anchor的数量,创建真值
y_true的输入格式。
具体的实现,如下:
h, w = input_shape # 尺寸
image_input = Input(shape=(w, h, 3)) # 图片输入格式
num_anchors = len(anchors) # anchor数量
# YOLO的三种尺度,每个尺度的anchor数,类别数+边框4个+置信度1
y_true = [Input(shape=(h // {0: 32, 1: 16, 2: 8}[l], w // {0: 32, 1: 16, 2: 8}[l],
num_anchors // 3, num_classes + 5)) for l in range(3)]
其中,真值y_true,真值即Ground Truth。“//”是Python语法中的整除符号。通过循环,创建3个Input层的列表,作为y_true。y_true的张量(Tensor)结构,如下:
Tensor("input_2:0", shape=(?, 13, 13, 3, 6), dtype=float32)
Tensor("input_3:0", shape=(?, 26, 26, 3, 6), dtype=float32)
Tensor("input_4:0", shape=(?, 52, 52, 3, 6), dtype=float32)
其中,在真值y_true中,第1位是输入的样本数,第2~3位是特征图的尺寸,如13x13,第4位是每个图中的anchor数,第5位是:类别(n)+4个框值(xywh)+框的置信度(是否含有物体)。
接着,通过传入,输入Input层image_input、每个尺度的anchor数num_anchors//3和类别数num_classes,构建YOLO v3的网络yolo_body,这个yolo_body方法是核心逻辑。
即:
model_body = yolo_body(image_input, num_anchors // 3, num_classes)
下一步,是加载预训练权重的逻辑块:
- 根据预训练权重的地址
weights_path,加载权重文件,设置参数为,按名称对应by_name,略过不匹配skip_mismatch; - 选择冻结模式:
- 模式1是冻结185层,模式2是保留最底部3层,其余全部冻结。整个模型共有252层;
- 将所冻结的层,设置为不可训练,
model_body.layers[i].trainable=False;
实现:
if load_pretrained: # 加载预训练模型
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
if freeze_body in [1, 2]:
# Freeze darknet53 body or freeze all but 3 output layers.
num = (185, len(model_body.layers) - 3)[freeze_body - 1]
for i in range(num):
model_body.layers[i].trainable = False # 将其他层的训练关闭
其中,185层是DarkNet53网络的层数,而最底部3层是3个1x1的卷积层,用于预测最终结果。185层是DarkNet53网络的最后一个残差(Residual)单元,其输入和输出如下:
input: [(None, 13, 13, 1024), (None, 13, 13, 1024)]
output: (None, 13, 13, 1024)
最底部3个1x1的卷积层,将3个特征矩阵转换为3个预测矩阵,其格式如下:
1: (None, 13, 13, 1024) -> (None, 13, 13, 18)
2: (None, 26, 26, 512) -> (None, 26, 26, 18)
3: (None, 52, 52, 256) -> (None, 52, 52, 18)
下一步,构建模型的损失层model_loss,其内容如下:
- Lambda是Keras的自定义层,输入为
model_body.output和y_true,输出output_shape是(1,),即一个损失值; - 自定义Lambda层的名字name为
yolo_loss; - 层的参数是锚框列表anchors、类别数
num_classes和IoU阈值ignore_thresh。其中,ignore_thresh用于在物体置信度损失(object confidence loss)中过滤IoU(Intersection over Union,重叠度)较小的框; yolo_loss是损失函数的核心逻辑。
实现如下:
model_loss = Lambda(yolo_loss,
output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors,
'num_classes': num_classes,
'ignore_thresh': 0.5}
)(model_body.output + y_true)
下一步,构建完整的算法模型,步骤如下:
- 模型的输入层:
model_body的输入(即image_input)和真值y_true; - 模型的输出层:自定义的
model_loss层,其输出是一个损失值(None,1); - 保存模型的网络图
plot_model和打印网络结构model.summary();
即:
model = Model(inputs=[model_body.input] + y_true, outputs=model_loss) # 模型
plot_model(model, to_file=os.path.join('model_data', 'model.png'), show_shapes=True, show_layer_names=True) # 存储网络结构
model.summary() # 打印网络
其中,model_body.input是任意(?)个(416,416,3)的图片;y_true是已标注数据所转换的真值结构,即:
[Tensor("input_2:0", shape=(?, 13, 13, 3, 6), dtype=float32),
Tensor("input_3:0", shape=(?, 26, 26, 3, 6), dtype=float32),
Tensor("input_4:0", shape=(?, 52, 52, 3, 6), dtype=float32)]
最终,这些逻辑,完成算法模型model的构建。
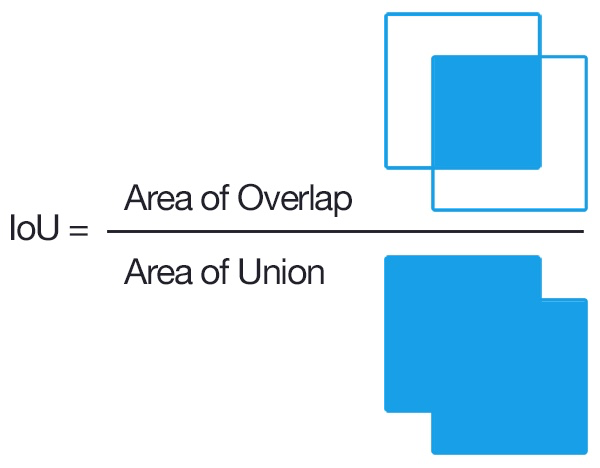
补充1. IoU
IoU,即Intersection over Union,用于计算两个图的重叠度,用于计算两个标注框(bounding box)之间的相关度,值越高,相关度越高。在NMS(Non-Maximum Suppression,非极大值抑制)或计算mAP(mean Average Precision)中,都会使用IoU判断两个框的相关性。
如图:
实现:
def bb_intersection_over_union(boxA, boxB):
boxA = [int(x) for x in boxA]
boxB = [int(x) for x in boxB]
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
boxAArea = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
boxBArea = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
iou = interArea / float(boxAArea + boxBArea - interArea)
return iou
补充2. 冻结网络层
在微调(fine-tuning)中,需要确定冻结的层数和可训练的层数,主要取决于,数据集相似度和新数据集的大小。原则上,相似度越高,则固定(fix)的层数越多;新数据集越大,不考虑训练时间的成本,则可训练更多的层数。然后可能也要考虑数据集本身的类别间差异度,但上面说的规则基本上还是成立的。
例如,在图片分类的网络中,底层一般是颜色、轮廓、纹理等基础结构,显然大部分问题都由这些相同的基础结构组成,所以可以冻结这些层。层数越高,所具有泛化性越高,例如这些层会包含对鞋子、裙子和眼睛等,具体语义信息,比较敏感的神经元。所以,对于新的数据集,就需要训练这些较高的层。同时,比如一个高层神经元对车的轮胎较为敏感,不等于输入其它图像,就无法激活,因而,普通问题甚至可以只训练最后全连接层。
在Keras中,通过设置每层的trainable参数,即可控制是否冻结该层,如:
model_body.layers[i].trainable = False
OK, that's all! Enjoy it!
欢迎关注,微信公众号 深度算法 (ID: DeepAlgorithm) ,了解更多深度技术!
