

疑问?
一直以来个人都对数据表的垂直分表有个误区,因为我觉得一个表如果要垂直分表的话,本来是一个千万级表,现在两个或者多个,这样不是增加了大表的数量吗?
用select具体行可以解决吗?
还有就是想着select不需要的行可以解决这样的问题吗?这个先解答一下,因为mysql本身是行记录格式,也就是说就算select * 或者select 具体字段的话,是不会区分具体列的,当然这个也不是没有意义,更多的是规范,而且减少不必要的网络传输数据。具体的行记录格式之前一篇博客说过表空间结构。
原因是啥?
在这里我可能在个人的知识范畴内说几点,如果有不同的看法,或者发现错误,希望大家提出。
行溢出
这个主要是大字段的拆分,因为字段本身可能非常大,超出行的可变长度,这个是在使用varchar可变类型情况下,因为数据库的行格式会存储变长字段的长度,而这个存储的字段最多就2字节,这样的话可变长度最多就可以达到65535,达到这个长度的话,计算了一下,一行数据的可变长度的列总和不超过64k左右(没精准算),超过的话会溢出行到blob页,这里还衍生了个问题,因为页存储就16k,而一行数据就远远超出,这样就失去了b+树的意义了,所以一般mysql会拆分前缀存储额外数据到额外页,一页保持至少两行数据。
查询缓存
mysql的查询缓存具体是根据查询语句来的,这里具体可以去看《高性能MYSQL》一书,大概表达的意思是查询语句不能有变量或者函数,例如current_timestamp之类的,这样不会有缓存,有点跑偏了。这里的意思是,垂直拆分表后,有些字段是常修改的,例如用户的个性签名之类的,而更新操作会让查询缓存无效,所以垂直拆分会优化查询效率。
数据页的影响
页是什么呢?页应该算作数据库的存储最小单位,在mysql中例如,insert_buffer_pool,AIO,索引查找都是以页为单位,首先垂直拆分表的话,随着字段的减少,每页里面的数据行也会增多,理论上页里面的数据行越多性能越好。

例如图中所示假如未分表之前页分布是这样的,如果要查询id=1和id=9的话可能是需要两次索引查询,两次磁盘IO,这里为啥说页1和页3呢,因为异步IO的可能性,innodb不会去等待第一个扫描结果,而是先扫描,然后去取数据,例如如果是id=1和id=6,根据page判断数据是相邻页,因为页是顺序存储的,所以会合并也就一次磁盘IO取出两页数据。
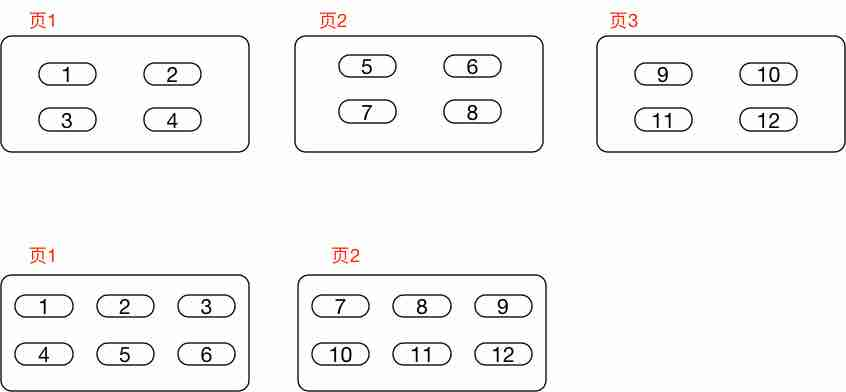
像上面这样,页里的行数增多,就可以减少一部分磁盘的IO,这样也就增加了查询效率。
对写入更新的影响
写入和更新其实还是页的问题,同样的问题,页的减少,就会影响脏页的刷新,insert_buffer的mergy,这样都会影响iops,如果页的减少,数据也会存储更有顺序性,对于写入与读取的话,顺序读比离散读要快,性能也能得到提升。
最后说点
本文只是个人对mysql的一些理解与整理结合,但是对很多原理还不是很熟悉,还是希望带着疑问去看待问题,与大家一起成长。
