

【火炉炼AI】机器学习003-简单线性回归器的创建,测试,模型保存和加载
(本文所使用的Python库和版本号: Python 3.5, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2 )
回归分析是一种基于现有数据集,从现有数据集中寻找数据规律的一种建模技术,主要研究的是因变量(输出y,或标记,或目标,它的别名比较多)和自变量(输入x,或特征,或预测器)之间的关系。通常用于预测分析,从现有数据集中找到数据规律,用该数据规律来预测未来的,或新输入的自变量,从而计算出因变量的过程。
简单线性回归是最基本,最简单的一种回归分析模型,也是最被人熟知,最被人首选的回归模型。简单线性回归模型的因变量y是连续的,自变量X可以是连续的也可以是离散的,其基本假设是因变量与自变量之间成直线的变化关系,可以通过一条简单的拟合直线(y=ax+b)来表示两者之间的关系。所以线性回归模型的训练目标就是获取这两直线的斜率a和截距b。如下图所示为简单的线性回归器的模型得到的线性图。
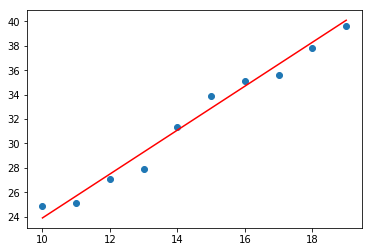 图1. 使用简单线性回归器拟合得到的直线图
图1. 使用简单线性回归器拟合得到的直线图
剩下的问题就是,怎么从数据集中得回归直线y=ax+b中的a和b,答案是最小二乘法。最小二乘法是拟合直线最常用的方法,其本质是通过最小化每个数据点到直线的垂直偏差的平方和来计算最佳拟合直线。最小二乘法的计算公式为:
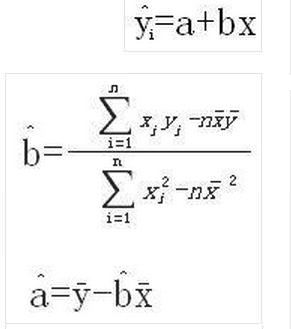 图2. 最小二乘法计算公式
图2. 最小二乘法计算公式
下面使用线性回归来拟合数据集,得到线性方程。
1. 准备数据集
对于机器学习而言,第一部分往往是准备数据集。一般的,数据集是存放在txt,或csv,或excel,或图片文件中,但此处我们没有这些数据集,故而我自己用随机数生成x,y组成数据集。如下代码:
# ***************使用随机数据来构建简单线性回归器**********************************
import numpy as np
import matplotlib.pyplot as plt
# %matplotlib inline
np.random.seed(37) # 使得每次运行得到的随机数都一样
# 第一部分:准备数据集
# 一般的,数据集可以放置在一个专门的txt,或csv文件中,此处我自己创造一些数据
x=np.arange(10,110)
x_shift=np.random.normal(size=x.shape)
x=x+x_shift # 构建的x含有100个数,通过在整数点引入偏差得到
print('x first 5: {},\nx last 5: {}'.format(x[:5],x[-5:]))
error=np.random.normal(size=x.shape)*15 # 构建误差作为噪音,*15是扩大噪音的影响
y=1.8*x+5.9+error
plt.scatter(x,y) # 可以查看生成的数据集的分布情况
# 要从这100个随机选择80个点来train,剩下的20个点来test
# 最简单的方法是调用下面的train_test_split函数
dataset=[(i,j) for i,j in zip(x,y)]
from sklearn.model_selection import train_test_split
train_set,test_set=train_test_split(dataset,test_size=0.2,random_state=37)
print('train set first 3: {}, last 3: {}'.format(train_set[:3],train_set[-3:]))
print('test set first 3: {}, last 3: {}'.format(test_set[:3],test_set[-3:]))
# 第二种方法:也可以自己先shuffle,再随机选取
# np.random.shuffle(dataset) # 乱序排列
# train_set,test_set=dataset[:80],dataset[80:]
# print('train set first 3: {}, last 3: {}'.format(train_set[:3],train_set[-3:]))
# print('test set first 3: {}, last 3: {}'.format(test_set[:3],test_set[-3:]))
X_train=np.array([i for (i,j) in train_set]).reshape(-1,1) # 后面的fit需要先reshape
y_train=np.array([j for (i,j) in train_set]).reshape(-1,1)
X_test= np.array([i for (i,j) in test_set]).reshape(-1,1)
y_test= np.array([j for (i,j) in test_set]).reshape(-1,1)
print('X_train first 3: {}'.format(X_train[:3]))
print('y_train first 3: {}'.format(y_train[:3]))
-------------------------------------输---------出--------------------------------
x first 5: [ 9.94553639 11.67430807 12.34664703 11.69965383 15.51851188], x last 5: [104.96860647 105.5657788 107.39973957 109.13188006 107.11399729] train set first 3: [(87.14423520405674, 167.36573263695115), (55.67781082162659, 99.22823777086437), (66.59394694856373, 132.76688712312875)], last 3: [(101.17645506359409, 192.5625947080063), (84.26081861492051, 140.24466883845), (25.045565547096164, 30.8008361424697)] test set first 3: [(70.59406981304555, 119.31318224915739), (57.91939805734182, 92.13834259220599), (96.47990086803438, 179.5012882066724)], last 3: [(102.0058216600241, 201.04210881463908), (18.172421360793678, 47.04372291312748), (104.96860647152728, 222.13041948920244)] X_train first 3: [[87.1442352 ] [55.67781082] [66.59394695]] y_train first 3: [[167.36573264] [ 99.22823777] [132.76688712]]
--------------------------------------------完-------------------------------------
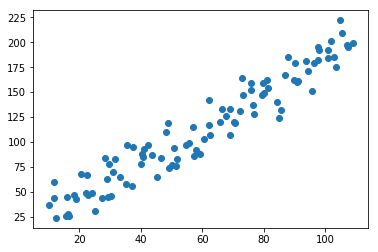 图3. 随机生成的原始数据集,共有100个数据点。
图3. 随机生成的原始数据集,共有100个数据点。
########################小**********结###############################
1,数据集的准备通常需要对数据进行处理,比如,异常点,缺失值的处理等。
2,从数据集中划分一部分作为train set,一部分作为test set是很有必要的,也是机器学习中经常做的一部分工作,可以采用sklearn的train_test_split函数来实现,简单有效。也可以自己写函数先shuffle,再取一部分数据。
3,为了配合后面的线性回归器进行fit,需要对向量数据进行reshape,转变为M行N列的形式(此处只有一个特征向量,即X,故而N=1)。
#################################################################
2. 构建,训练线性回归器模型
使用sklearn可以非常简单的创建和训练回归器模型,只需一两行代码就搞定,如下代码:
# 第二部分:使用train set进行模型训练
from sklearn import linear_model
linear_regressor=linear_model.LinearRegression() # 创建线性回归器对象
linear_regressor.fit(X_train,y_train) # 使用训练数据集训练该回归器对象
# 查看拟合结果
y_predict=linear_regressor.predict(X_train) # 使用训练后的回归器对象来拟合训练数据
plt.figure()
plt.scatter(X_train,y_train)
plt.plot(X_train,y_predict,'-b',linewidth=3)
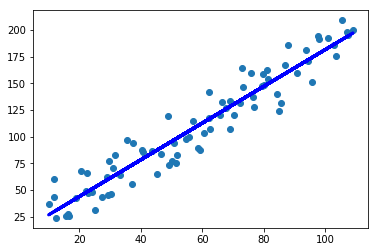 图4. 使用线性回归模型拟合训练集得到的直线
图4. 使用线性回归模型拟合训练集得到的直线
通过上图,可以看出该线性回归模型貌似能够很好地拟合这些数据点,但是这是将模型用于预测训练集得到的结果,如果用该模型预测它从来没见过的测试集,会得到什么结果了?
# 用训练好的模型计算测试集的数据,看是否能得到准确值
y_predict_test=linear_regressor.predict(X_test)
plt.figure()
plt.scatter(X_test,y_test)
plt.plot(X_test,y_predict_test,'-b',linewidth=3)
plt.scatter(X_test,y_predict_test,color='black',marker='x')
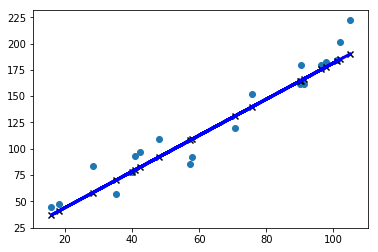 图5. 使用线性回归模型拟合测试集得到的直线
图5. 使用线性回归模型拟合测试集得到的直线
########################小**********结###############################
1,sklearn模块种类的linear_model包中有很多线性模型,其中的LinearRegression 专门用于线性回归模型。
2,这个线性回归模型的训练很简单,fit()函数一下子搞定。
3,一旦模型训练好,可以用predict()函数来预测新的没有见过的X数据。
#################################################################
3. 评价模型的准确性
虽然上面我们把模型拟合后的直线绘制出来,从肉眼看上去,貌似这个线性回归模型可以得到比较好的拟合结果,但是怎么样通过定量的数值来评价这个模型的好坏了?评价指标。
有很多评价指标可以用来衡量回归器的拟合效果,最常用的是:均方误差(Mean Squared Error, MSE)。
均方误差MSE是应用的最广泛的一个评价指标,其定义为:给定数据集的所有点的误差的平方的平均值,是衡量模型的预测值和真实值之间误差的常用指标。这个值越小,表明模型越好。计算公式为:
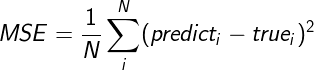 图6. 均方误差MSE计算公式
图6. 均方误差MSE计算公式
还有一些其他的评价指标,比如中位数绝对误差,解释方差分,R方得分等。如下是本模型的评价指标结果。
# 使用评价指标来评估模型的好坏
import sklearn.metrics as metrics
print('平均绝对误差:{}'.format(
round(metrics.mean_absolute_error(y_predict_test,y_test),2)))
print('均方误差MSE:{}'.format(
round(metrics.mean_squared_error(y_predict_test,y_test),2)))
print('中位数绝对误差:{}'.format(
round(metrics.median_absolute_error(y_predict_test,y_test),2)))
print('解释方差分:{}'.format(
round(metrics.explained_variance_score(y_predict_test,y_test),2)))
print('R方得分:{}'.format(
round(metrics.r2_score(y_predict_test,y_test),2)))
-------------------------------------输---------出--------------------------------
平均绝对误差:11.98 均方误差MSE:211.52 中位数绝对误差:12.35 解释方差分:0.93 R方得分:0.92
--------------------------------------------完-------------------------------------
########################小**********结###############################
1,对一个模型的评价指标非常多,而对线性回归模型,可以只看均方误差和解释方差分,均方误差越小越好,而解释方差分越大越好。
2,本模型的均方误差比较大的原因,可能在于准备数据集时引入的误差太大,导致了数据太过分散,得到的模型拟合的直线与随机点的误差较大。
#################################################################
4. 模型的保存和加载
模型一般得来不易,有时候需要耗费几个小时,乃至几个月的训练才能得到,故而在训练过程中,或者训练结束后保存模型是非常有必要的,这样的预测新数据时只需简单加载模型就可以直接使用。
关于sklearn模型的保存和加载,sklearn官网给出了两种建议的方式,第一种是使用pickle,第二种使用joblib,但我建议使用joblib,因为简单好用。
# 回归模型的保存和加载
# 在保存之前先看一下模型的内部参数,主要为两项,截距和系数
print('直线的截距: {}'.format(linear_regressor.intercept_)) #这是截距
print('直线的系数(斜率): {}'.format(linear_regressor.coef_)) #这系数,对应于本项目的直线斜率
y_value=linear_regressor.predict([[120]])
print('用线性模型计算的值:{}'
.format(y_value)) # 这两个print的结果应该是一样的
print('直线方程计算的值:{}'
.format(linear_regressor.coef_*120+linear_regressor.intercept_))
save_path='d:/Models/LinearRegressor_v1.txt'
# 第一种方法,pickle
import pickle
s=pickle.dumps(linear_regressor) # 模型保存
loaded_classifier=pickle.loads(s) # 模型加载
y_value=loaded_classifier.predict([[120]])
print('pickle加载后的模型计算结果:{}'.format(y_value))
# 第二种方法:joblib
from sklearn.externals import joblib
joblib.dump(linear_regressor,save_path) # 模型保存到文件中
loaded_classifier2=joblib.load(save_path)
y_value=loaded_classifier2.predict([[120]])
print('joblib加载后的模型计算结果:{}'.format(y_value))
-------------------------------------输---------出--------------------------------
直线的截距: [9.50824666] 直线的系数(斜率): [[1.71905515]] 用线性模型计算的值:[[215.79486427]] 直线方程计算的值:[[215.79486427]] pickle加载后的模型计算结果:[[215.79486427]] joblib加载后的模型计算结果:[[215.79486427]]
--------------------------------------------完-------------------------------------
########################小**********结###############################
1,对sklearn模型的保存和加载有两种方式,通过pickle和joblib两种方式,但joblib是sklearn自带的模型保存函数,而且可以很明确的指定保存到哪一个文件中,故而推荐用这种方式。
2,虽然保存的方式不一样,但是都可以正常的保存和加载,得到的计算结果也一样。
3,模型得到的直线方程是y=1.719x+9.508,和最开始的y数据产生时所用的直线方程y=1.8x+5.9+error有很大偏差,这是因为error噪音数据太大所导致的,故而模型得到的均方误差也比较大一些。
#################################################################
注:本部分代码已经全部上传到(我的github)上,欢迎下载。
参考资料:
1, Python机器学习经典实例,Prateek Joshi著,陶俊杰,陈小莉译
