


当开发人员使用文本时,他们通常需要先清理它。有时是替换关键词,就像用“JavaScript”替换“Javascript”一样。其它时候,我们只想知道文档中是否提到了“JavaScript”。
像这样的数据清理是大多数处理文本的数据科学项目的标准任务。
数据科学始于数据清理。
最近我有一项非常类似的工作。我在 Belong.co 担任数据科学家,其中有一半工作是在做自然语言处理。
当我在我们的文档语料库中训练 Word2Vec 模型时,它最初会把同义词当成近似术语给出。 比如“Javascripting”变成了“JavaScript”的近似术语。
为了解决这事,我编写了一个正则表达式(Regex)来用标准化名称替换所有已知的同义词。比如将“JavaScripting”替换成“Javascript”。正则表达式解决了这一个问题,但创造了另一个问题。
有些人在面对一个问题时会想
“知道了,我该使用正则表达式。”现在他们有两个问题了。
以上引用来自 stack-exchange 的问题,说的就是我这种。
事实证明,如果要搜索和替换的关键词数量在 100 个以内,正则表达式会很快。但我的语料库有超过 2 万个关键词和 300 万个文件。
当我对我的正则表达式代码进行基准测试时,我发现它跑一次要花 5 天。

哦,恐怖
自然的解决方案是并行运行。但是,当我们的数量级达到文档千万、关键词十万时,这将无济于事。**必须有更好的方法!**我开始寻找......
我在办公室和 Stack Overflow 上问了问 —— 收获了一些建议。Vinay Pandey,Suresh Lakshmanan 和 Stack Overflow 指出了称为 Aho-Corasick 算法的美妙算法,以及 Trie 数据结构方法。我寻找已有的解决方案,但找不到多少。
所以我编写了自己的实现,FlashText 诞生了。
在我们了解什么是 FlashText 以及它是如何工作的之前,让我们看看它的搜索性能:
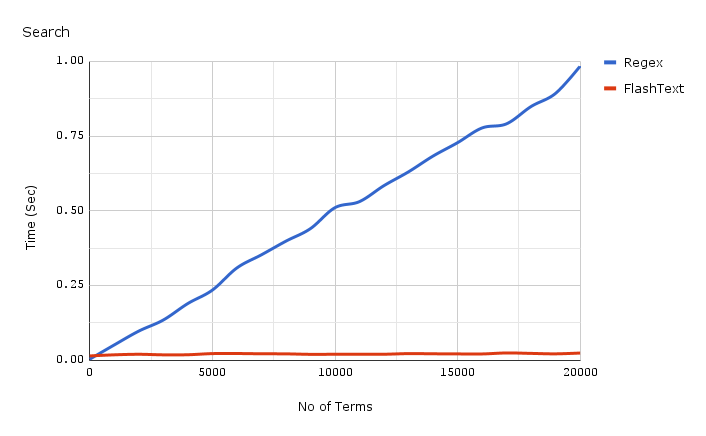
底部的红线是 FlashText 搜索所花费的时间
上面显示的图表是 1 个文档时编译过的正则表达式与 FlashText 的比较。随着关键词数量的增加,正则表达式所用的时间几乎呈线性增长,但 FlashText 对此并不敏感。
**FlashText 将运行时间从 5 天减少到 15 分钟!! **

这个好 :)
这是 FlashText 做替换时的计时:
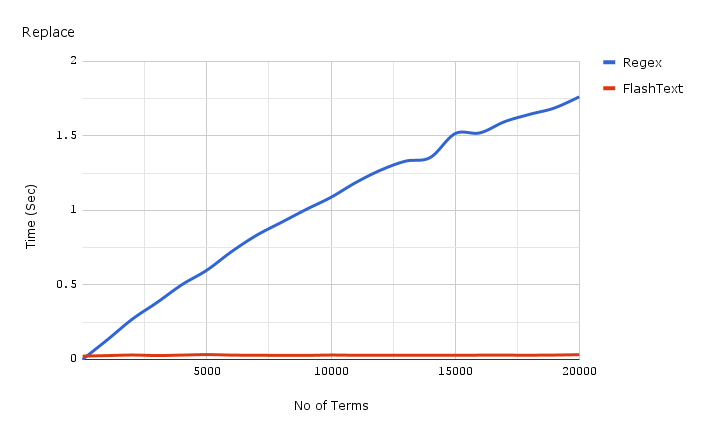
底部的红线是 FlashText 用于替换的时间
那么什么是 FlashText?
FlashText 是我在 GitHub 上开源的一个 Python 库。它在提取关键词和替换上都很高效。
要使用 FlashText,首先必须传入一个关键词列表。此列表将在内部用于构建 Trie 字典。然后传入一个字符串,并说明是要替换还是搜索。
**替换**会创建一个替换了关键词的新字符串。**搜索**会返回字符串中找到的关键词列表。在运行过程中,输入的字符串只会被扫描一遍。
以下是一位满意的用户对这库的看法:
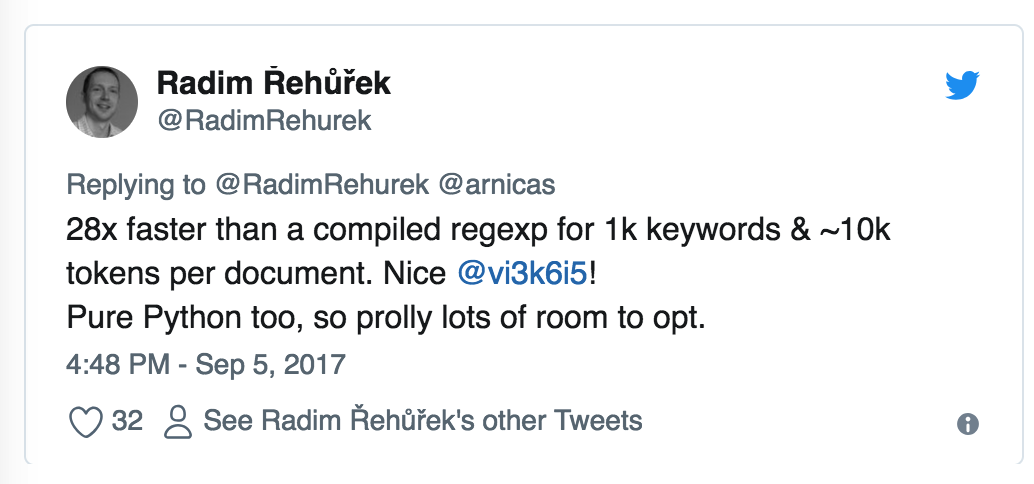
@RadimRehurek 是 @gensim_py 的创建者。
为什么 FlashText 这么快?
我们试着用一个例子来理解这部分。假设我们有一个句子,其中包含 3 个单词 I like Python,以及一个包含 4 个单词 {Python,Java,J2ee,Ruby} 的语料库。
如果我们从语料库中取出每个单词,并检查它是否存在于句子中,则需要 4 次尝试。
'Python' 在句子中吗?
'Java' 在句子中吗?
...
如果语料库有 n 个词,它就会重复 n 次。每个搜索步骤 <word> 在句子中吗? 都要独自花费时间。这就是正则表达式匹配中发生的事情。
还有另一种方法与第一种方法相反:对于句子中的每个单词,检查它是否存在于语料库中。
'I' 在语料库中吗?
'like' 在语料库中吗?
'Python' 在语料库中吗?
如果句子中有 m 个词,它就会重复 m 次。在这种情况下,它所花费的时间仅取决于句子中的单词数量。而 <word> 在语料库中吗? 这一步可以使用字典查找快速完成。
FlashText 算法基于第二种方法。其灵感来自 Aho-Corasick 算法和 Trie 数据结构。
它的工作方式是:
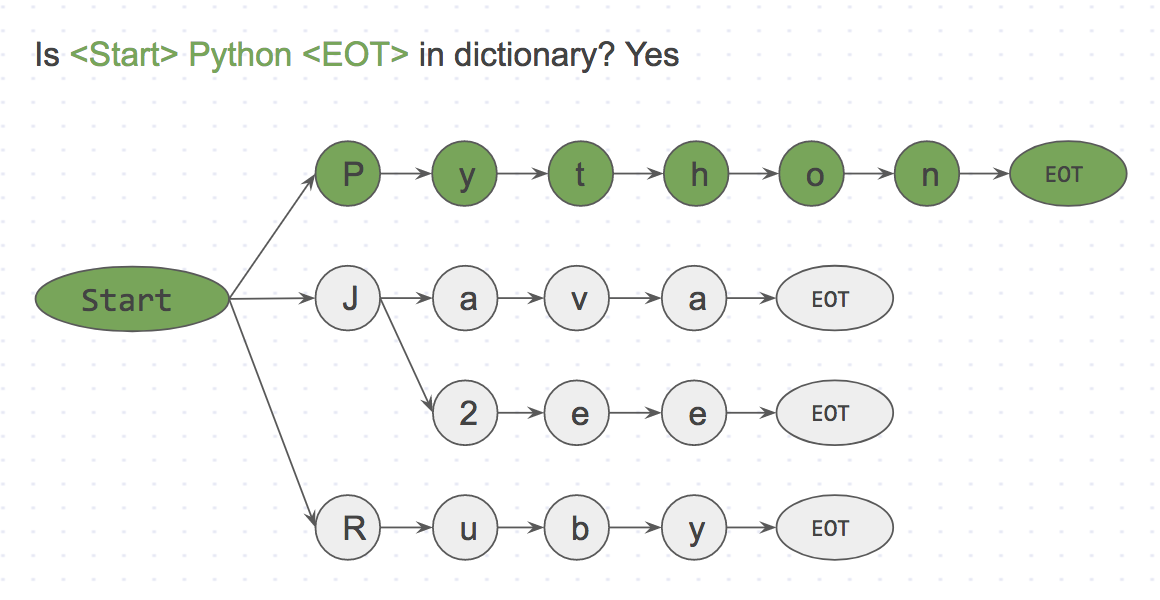
首先,使用语料库创建 Trie 词典。看起来有点像这样:
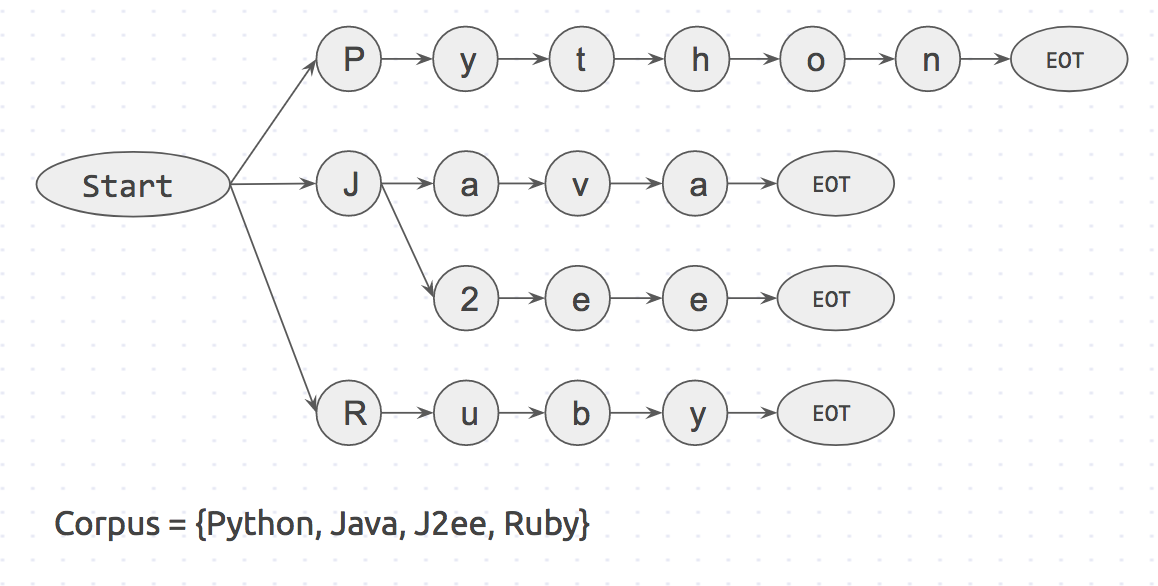
Trie 词典的语料库。
用 start 和 EOT(End Of Term)表示像 空格,标点 和 换行 这样的单词边界。关键词只有在其两侧都有单词边界时才匹配。这样可以防止 pineapple 匹配到 apple。
接下来我们将输入一个输入字符串 I like Python 并逐个字符地搜索它。
第 1 步:<start>I<EOT> 在字典中吗?不在。
第 2 步:<start>like<EOT> 在字典中吗?不在。
第 3 步:<start>Python<EOT> 在字典中吗?在。
<Start>Python<EOT> 在字典中。
因为这是逐个字符的匹配,所以我们可以很容易地在 <start>l 处就跳过 <start>like<EOT>,因为词典的 <start> 后面没有 l 这个字母。这样可以快速跳过不在语料库中的单词。
FlashText 算法只遍历输入字符串 'I like Python' 的每个字符。字典哪怕有高达百万个关键词,对运行时也没有影响。这就是 FlashText 算法的真正力量。
那么什么时候应该使用 FlashText?
简单的答案:当关键词数 > 500 时
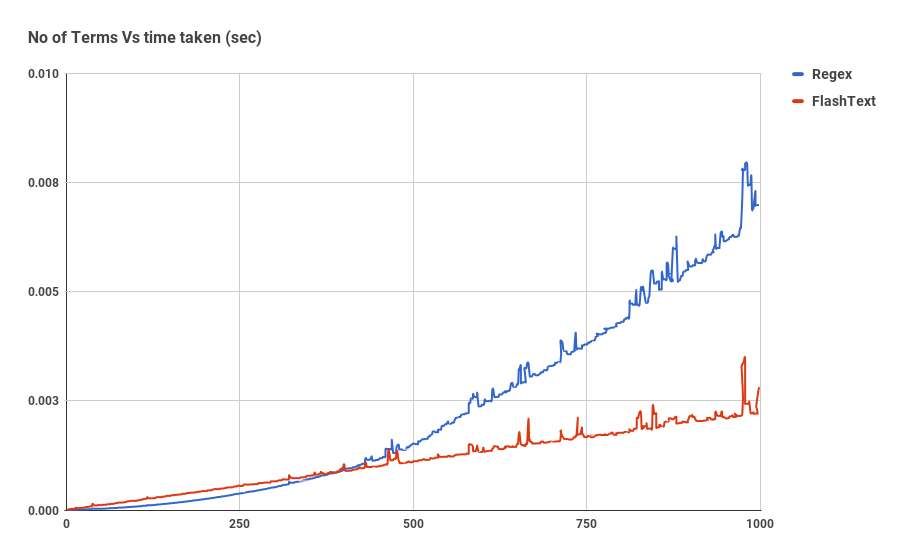
对于搜索,FlashText 在大约超过 500 个关键词后性能优于正则表达式。
复杂的答案:正则表达式可以基于特殊字符搜索关键词,如 ^,$,*,\d,.,FlashText 不支持这个。
因此,如果您想像 word\dvec 这样匹配部分词,最好不要用 FlashText。但像 word2vec 这样提取完整的单词,就非常适合了。
用 FlashText 查找关键词
# pip install flashtext
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('Bay Area')
keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.')
keywords_found
# ['New York', 'Bay Area']
使用 FlashText 的简单提取示例
用 FlashText 替换关键词
您也可以替换句子中的关键词,而不是提取它。我们用这作为数据处理流程中的数据清理步骤。
from flashtext.keyword import KeywordProcessor
keyword_processor = KeywordProcessor()
keyword_processor.add_keyword('Big Apple', 'New York')
keyword_processor.add_keyword('New Delhi', 'NCR region')
new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.')
new_sentence
# 'I love New York and NCR region.'
使用 FlashText 的简单替换示例
如果您认识谁在用文本数据、实体识别、自然语言处理或 Word2vec,请考虑与他们共享此博文。
这个库对我们非常有用,我相信它对其他人也很有用。
终于讲完了,感谢捧场 😊
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
