

前言
1、简单聊聊:
在我脑海中我能通过这些年听到的技术名词来感受到技术的更新及趋势,这种技术发展有时候我觉得连关注的脚步都赶不上。简单回顾看看,从我能听到的技术名词来感受,最开始耳闻比较多「云计算」这玩意,后来听到比较多的是「数据挖掘」,然而本科毕业之后听到的最多便是「人工智能」,整个技术圈似乎完全被这个词所覆盖,怎么突然火起来这个?我觉得用 AlphaGo 这个可以去作个反应吧,找了下新闻资料:
2016年3月9日至15日,Google旗下的DeepMind智能系统——AlphaGo在韩国首尔对战世界围棋冠军、职业九段选手李世石(又译李世乭),这场人类与人工智能间的对决最终结果是AlphaGo以总比分4比1战胜李世石。2017年5月23日至27日,世界排名第一的中国选手柯洁和AlphaGo展开“人机大战2.0”三番棋较量,柯洁0:3败北。
这个人工智能应用的例子无疑是当下最振奋人心的事件。之后也经常听到谷歌研发无人驾驶相关新闻。我在想,无人驾驶?听上去就牛逼轰轰不得了啊,这得多难!
另外,记得去年(2017年)一个叫「区块链」的技术词在很多地方看到,这又是啥?后来去搜了下资料看看,才明白是啥玩意(有兴趣可以看阮一峰老师写的区块链入门教程)。一开始我们了解这个技术一般都是从比特币开始,比特币又是啥?想了解话网上资料很多,同时也推荐可以看看阮一峰老师写的比特币入门教程。
从上面自己的耳闻变化我能感受技术趋势的变化之快,科技发展速度真的很难想象,就比如手机 2G 到 3G 再到 4G 的变化,再过一两年不出意外 5G 也应该能体验到了,这种变化速度,真是苦逼了我们这些技术人。
上面瞎扯扯了一些,打住,说回来,还是回来人工智能这个话题来。下面来简单说说人工智能。
在开始介绍人工智能、机器学习、深度学习之前,我觉得很有必要需要先科普或者说找几篇文章了解下它们都是什么以及有什么区别:
2、人工智能:
人工智能无疑是这几年最热门的话题和焦点。什么是人工智能?
人工智能(Artificial Intelligence),英文缩写为AI,是研究计算机来模拟人的思维过程和智能行为(如学习、推理、思考、规划等)的一门学科。主要包括计算机实现智能的原理、制造类似于人脑智能的计算机,使计算机能实现更高层次的应用。
人工智能是计算机科学的一个分支,它的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
总结:人工智能—给机器赋予人的智能。
人工智能的概念很宽,所以人工智能也分很多种,我们可以按照实力将人工智能分为以下三大类。(来源人工智能三个阶段 弱人工智能 强人工智能 超人工智能 即使神也要臣服于科学)
-
弱人工智能:擅长于单个方面的人工智能。比如有能战胜象棋世界冠军的人工智能,但是它只会下象棋,你要问它怎样更好地在硬盘上储存数据,它就不知道怎么回答你了。弱人工智能是能制造出真正地推理(Reasoning)和解决问题(Problem_solving)的智能机器,但这些机器只不过看起来像是智能的,但是并不真正拥有智能,也不会有自主意识。说到底只是人类的工具。即使是弱人工智能在古代语言还原中还是文物还原中都起到极大作用,长期困扰专家的西夏文现在已经可以人工智能识别。我们现在就处于弱人工智能转向强人工智能时代
-
强人工智能:人类级别的人工智能。强人工智能是指在各方面都能和人类比肩的人工智能,人类能干的脑力活它都能干。创造强人工智能比创造弱人工智能难得多。这里的“智能”是指一种宽泛的心理能力,能够进行思考、计划、解决问题、抽象思维、理解复杂理念、快速学习和从经验中学习等操作。
强人工智能观点认为有可能制造出真正能推理(Reasoning)和解决问题(Problem_solving)的智能机器,并且,这样的机器能将被认为是有知觉的,有自我意识的。可以独立思考问题并制定解决问题的最优方案,有自己的价值观和世界观体系。有和生物一样的各种本能,比如生存和安全需求。在某种意义上可以看作一种新的文明。例如银翼杀手和人工智能中的大卫就已经是强人工智能。
-
超人工智能:牛津哲学家,知名人工智能思想家Nick Bostrom把超级智能定义为“在几乎所有领域都比最聪明的人类大脑都聪明很多,包括科学创新、通识和社交技能”。超人工智能可以是各方面都比人类强一点,也可以是各方面都比人类强万亿倍的。当达到超过人类以后人工智能的发展将呈指数级爆发,人工智能将极大的推动科学进步,纳米技术和基因工程在人工智能的辅助下将得到极大提高,即使在弱人工智能时代,都已经可以识别西夏文和希伯来文。如果能达到超人工智能,以往逝去的人甚至都可以复活。甚至秦皇汉武,武安君白起。超人工智能想复刻多少,不过瞬间的事情。如果人类能达到这个阶段没有被强人工智能取代,人类自身说不定可以永生。电影出现的超人工智能例如人工智能电影结尾出现的透明人。
现在,人类已经掌握了弱人工智能。其实弱人工智能无处不在,人工智能革命是从弱人工智能,通过强人工智能,最终到达超人工智能的旅途。这段旅途中人类可能会生还下来,可能不会,但是无论如何,世界将变得完全不一样。不过,到目前为止,人类的大脑是我们所知宇宙中最复杂的东西。因此,从弱人工智能到强人工智能的发展之路任重而道远。
3、机器学习:
机器学习(Machine Learning,ML)是人工智能研究较为年轻的分支。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。
是一门专门研究计算机来模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能的技术。简单来说,就是通过算法,使得机器能从大量的数据中学习到规律,从而对新的样本做出智能的识别或者预测未来。如现在的图像识别,语音识别,自然语言理解,天气预测等方面。
总结:「机器学习」不再通过规则行动,而是通过归纳、统计来进行结果改进,不再需要外部明确的知识,而是通过经验和数据进行结果改进。
机器学习不是万能的!
机器学习本质上还是一种统计方法,它只讲求统计意义未必考虑的是事情的本质。
对于机器学习模型来说。准确率和召回率都不可能是100%,极端case难以避免。
对于金融交易、自动驾驶等事关大笔资金安全、人身安全的场景中,不要盲目迷信 AI,不要把安全全部交给模型。正确的做法是? 规则(经验)+模型 融合。
机器学习算法有很多,可以从两个方面介绍。(来源:机器学习中常见4种学习方法、13种算法和27张速查表!)
1. 按学习方式:
- 监督学习
- 非监督学习
- 半监督学习
- 强化学习
2. 按功能和形式的类似性:
- 1.回归算法
- 2.正则化方法
- 3.决策树学习
- 4.基于实例的算法
- 5.贝叶斯方法
- 6.聚类算法
- 7.降低维度算法
- 8.关联规则学习
- 9.遗传算法(genetic algorithm)
- 10.人工神经网络
- 11.深度学习
- 12.基于核的算法
- 13.集成算法
学习算法是个非常头疼的事也是重要的学习内容(哎,数学是硬伤~),下面几本书得到很多好评,需要去看看:
- 周志华《机器学习》
- 李航《统计学方法》
- Peter Harrington《Machine Learning in Action》(中文版《机器学习实战》)
需要掌握一些经典的机器学习算法,毕竟机器学习算法要列起来实在太多了,网上找了的一张图,瞧瞧o(╥﹏╥)o
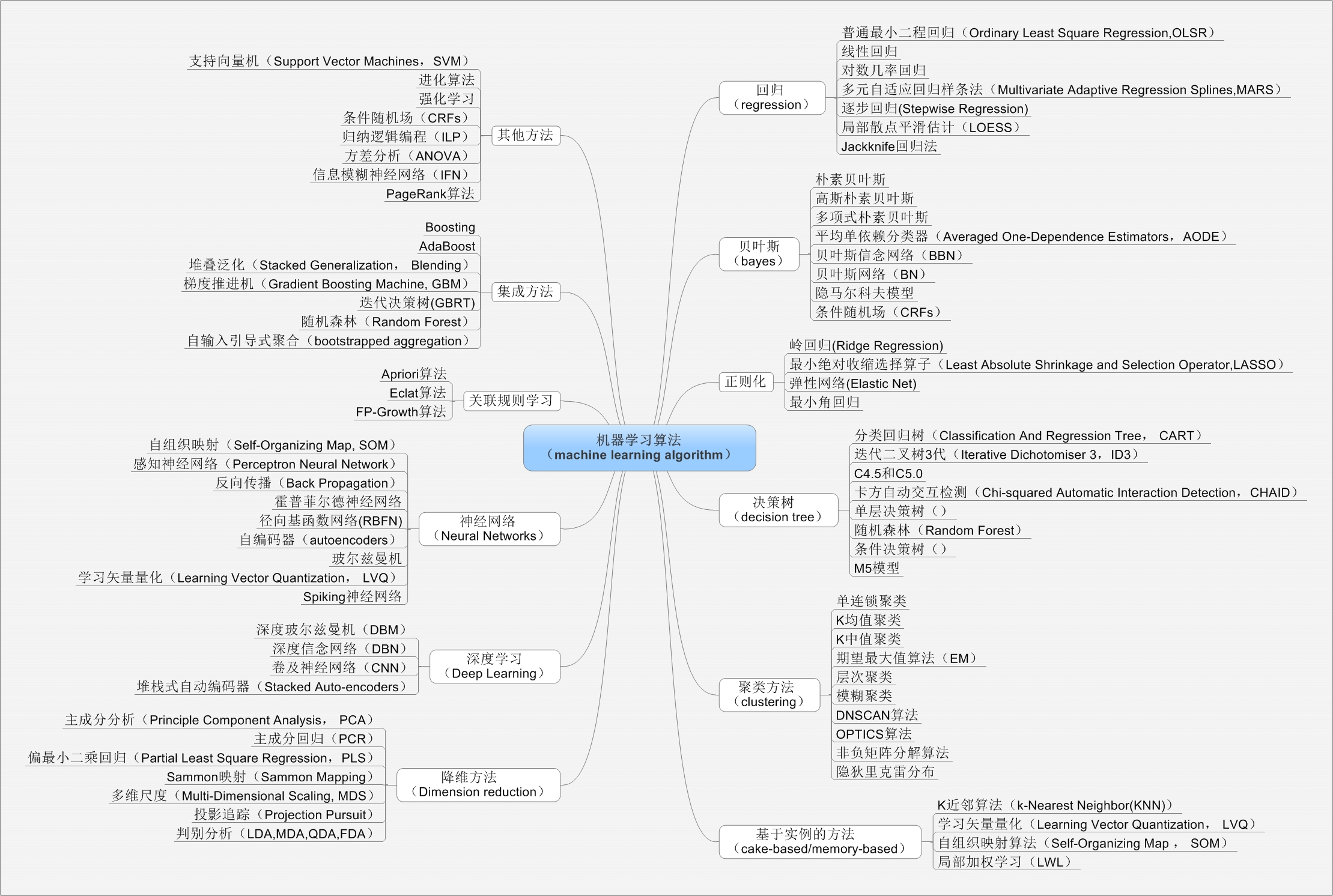
下面我们还是来看看人工智能有哪些关注的点呢?
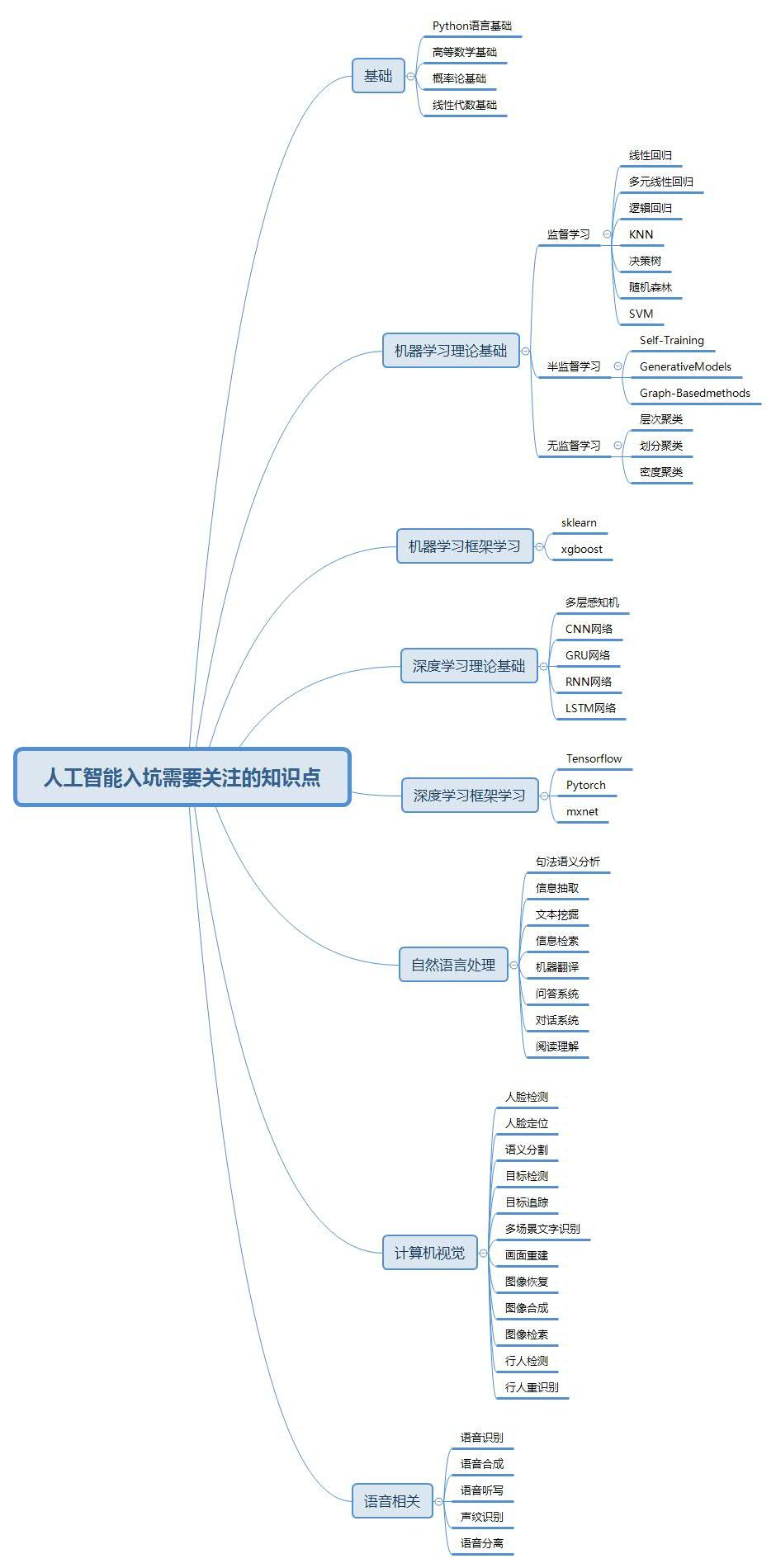
(图片来源:zhuanlan.zhihu.com/p/36554572)
像上图中提到的自然语言处理、计算机视觉、语言相关都是机器学习应用的方向,其中存在很多的研究小方向。本文主要基于计算机视觉资料做个整理及记录。
为了检验是否以及对相关内容有了认识,可以试着解释或回答如下一些问题。
Q1:机器学习、数据挖掘、模式识别、人工智能这些概念?
PR(模式识别)、DM(数据挖掘)属于 AI 的具体应用;人工智能是一种应用领域,机器学习是实现人工智能的一种手段,但是不限于此。
什么是模式识别?
模式识别是指对表征事物或现象的各种形式的(数值的、文字的和逻辑关系的)信息进行处理和分析,以对事物或现象进行描述、辨认、分类和解释的过程,是信息科学和人工智能的重要组成部分。
Q2:机器学习算法?
按学习的方式来划分,机器学习主要包括:
- 监督学习:输入数据带有标签。监督学习建立一个学习过程,将预测结果与 “训练数据”(即输入数据)的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率,比如分类和回归问题等。常用算法包括决策树、贝叶斯分类、最小二乘回归、逻辑回归、支持向量机、神经网络等。
- 非监督学习:输入数据没有标签,而是通过算法来推断数据的内在联系,比如聚类和关联规则学习等。常用算法包括独立成分分析、K-Means 和 Apriori 算法等。
- 半监督学习:输入数据部分标签,是监督学习的延伸,常用于分类和回归。常用算法包括图论推理算法、拉普拉斯支持向量机等。
- 强化学习:输入数据作为对模型的反馈,强调如何基于环境而行动,以取得最大化的预期利益。与监督式学习之间的区别在于,它并不需要出现正确的输入 / 输出对,也不需要精确校正次优化的行为。强化学习更加专注于在线规划,需要在探索(在未知的领域)和遵从(现有知识)之间找到平衡。
(参考:feisky.xyz/machine-lea…)
(参考:jizhi.im/blog/post/m…)
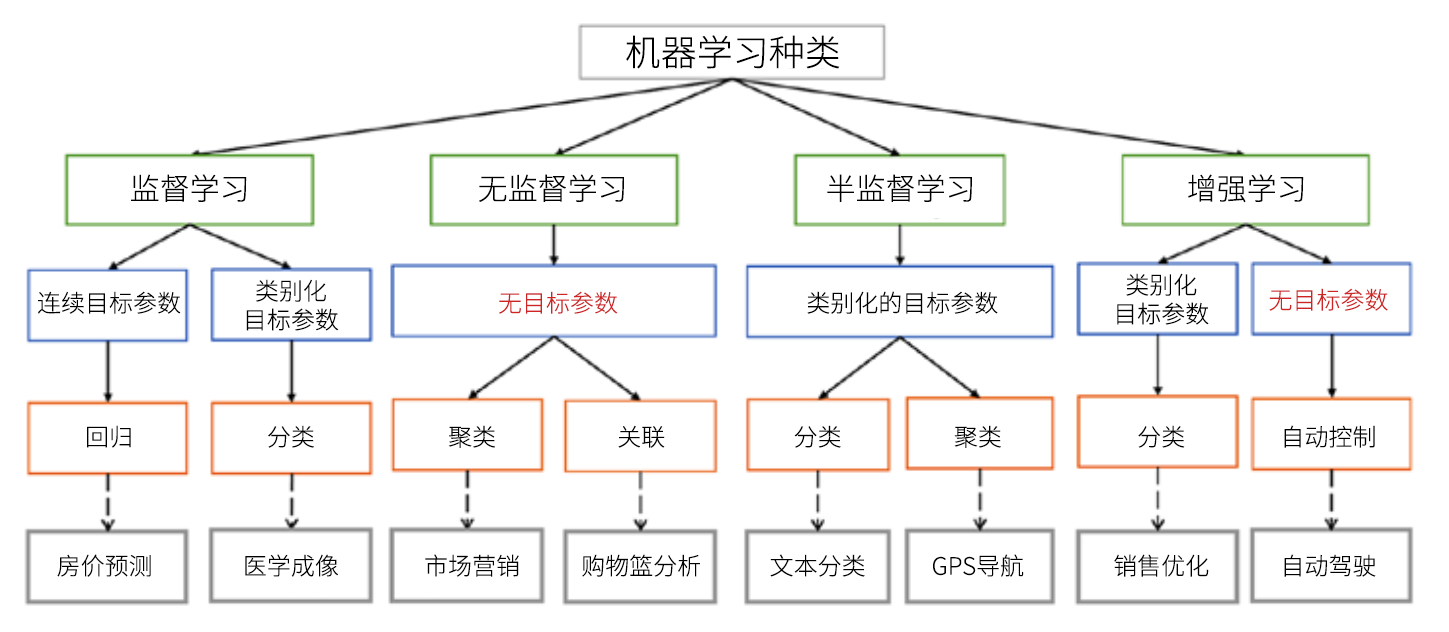
Q3:机器学习的应用有哪些?
机器学习已广泛应用于数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、DNA 序列测序、语音和手写识别、战略游戏和机器人等领域。
4、学习资料:
待上面的介绍有个全局的认知,可以直接开干了!关于人工智能、机器学习、深度学习入门资料,可以参考以下资料:
①机器学习
- GitBook:写给人类的机器学习
②深度学习
- 阮一峰:神经网络入门
- 零基础入门深度学习系列
- Michael Nielsen:Neural Networks and Deep Learning (中文翻译版《神经网络与深度学习》)
- GitHub:《深度学习》中文版(俗称“花书”)
【Videos】相关的学习视频资源链接直达:
-
吴恩达_机器学习:
- 官网:www.coursera.org/learn/machi…
- 或者到 B 站观看:www.bilibili.com/video/av991…
- 这还有一份笔记 GitHub:Coursera-ML-AndrewNg-Notes(建议打印,边看视频边看该份笔记,效果更佳~)
-
台湾_林轩田《机器学习基石》:www.bilibili.com/video/av162…
-
台湾_林轩田《机器学习技法》:www.bilibili.com/video/av124…
-
台大_李宏毅:(有台湾口腔)
大家可能看过《一天搞懂深度学习》的PPT,作者是台湾大学的李宏毅老师。其实,李宏毅老师还有门 深度学习的课程,视频也挂在网上。这门课主要针对初学者,而且,不需要有经典的机器学习基础(其 实,深度学习入门,比经典的机器学习更容易)。课程的内容深入浅出,训练和预测样本都是各种数码 宝贝和二次元卡通人物,绝对让你耳目一新。好像没有字幕,中文授课(台湾腔)。课程链接:speech.ee.ntu.edu.tw/~tlkagk/cou…
- B 站:李宏毅《一天搞懂深度学习》www.bilibili.com/video/av165…
- B 站:李宏毅_机器学习 www.bilibili.com/video/av105…
- B 站: 李宏毅_深度学习 www.bilibili.com/video/av977…
-
李飞飞_斯坦福 cs231n 课程:(深度学习计算机视觉课程)
- B 站(中文字幕):www.bilibili.com/video/av132…
- B 站(英文字幕):www.bilibili.com/video/av132…
5、本文目的:
本文其实没啥有价值的干货,也就是对看过的博客和资料的整理,记录下来,相当给自己梳理一遍,供参考~
(PS:深感文字能力真的好差,还好该文只是资料整理而已(# ̄~ ̄#) 各位看官见谅...... 写作真得需要经常锻炼才行QAQ...)
一、了解图像
学习计算机视觉,首先要了解图像是什么吧?
图像是指能在人的视觉系统中产生视觉印象的客观对象,包括自然景物、拍摄到的图片、用数学方法描述的图像等。图像的要素有几何要素(刻画对象的轮廓、形状等)和非几何要素(刻画对象的颜色、材质等)。<来源《数字图像处理与机器视觉》 >
我们带着问题来更多的认识吧!
1、什么是位图、矢量图?
-
百度知道:什么是位图?什么是矢量图?二者有何区别?
①位图就是点阵图,比如大小是
1024*768的图片,就是有1024*768个像素点,存储每个像素点的颜色值。矢量图是用算法来描述图形,比如一个圆,存储半径和圆心,当然还有颜色,具体到图片的某个像素点的位置是什么颜色是根据算法算出来的。
②矢量图是可以任意缩放的,比如上面说的圆,在
1024*768的时候是一个圆,图片放大20倍看还是圆,如果是位图,放大20倍,看到的就是一个一个的方块了。
一般而言,使用数字摄像机或数字照相机得到的图像都是位图图像。
2、有哪些种图像?
3、对图像处理的认识?
4、什么是数字图像?
自然界中的图像都是模拟量,在计算机普遍应用之前,电视、电影、照相机等图像记录与传输设备都是使用模拟信号对图像进行处理。但是,计算机只能处理数字量,而不能直接处理模拟图像。
什么是数字图像?简单地来说,数字图像就是能够在计算机上显示和处理的图像,可根据其特性分为两大类——位图和矢量图。位图通常使用数字阵列来表示,常见格式有 BMP、JPG、GIF 等;矢量图由矢量数据库表示,接触最多的就是 PNG 图像。<来源《数字图像处理与机器视觉》 >
5、数字图像处理的主要研究内容有哪些?简要说明。
图像增强:用于改善图像视觉质量(主观的);
图像复原:是尽可能地恢复图像本来面目(客观的);
图像编码:是在保证图像质量的前提下压缩数据,使图像便于存储和传输;
图像分割:就是把图像按其灰度或集合特性分割成区域的过程;
图像分类:是在将图像经过某些预处理(压缩、增强和复原)后,再将图像中有用物体的特征进行分割,特征提取,进而进行分类;
图像重建:是指从数据到图像的处理,即输入的是某种数据,而经过处理后得到的结果是图像。
<来源 百度知道>
6、数字图像处理与机器视觉?<来源《数字图像处理与机器视觉》第二版 P5>
从数字图像处理到数字图像分析,再发展到最前沿的图像识别技术,其核心都是对数字图像中所含有的信息的提取及与其相关的各种辅助过程。
图像处理 --> 图像分析 --> 图像识别技术。核心都是:对数字图像所含有的信息提取及与其相关的各种辅助过程。
-
数字图像处理: 就是指使用电子计算机对量化的数字图像进行处理,具体地说就是对图像进行各种加工来改善图像的外观,是对图像的修改和增强......此时的图像处理作为一种预处理步骤,输出图像将进一步供其他图像进行分析、识别算法。
-
数字图像分析: 是指对图像中感兴趣的目标进行检测和测量,以获得可观的信息。数字图像分析通常是指一副图像转化为另一种非图像的抽象形式,例如图像中某物体与测量者的距离。这一概念的外延包括边缘检测和图像分割、特征提取以及几何测量与计数等。
-
数字图像识别: 主要是研究图像中各目标的性质和相互关系,识别出目标对象的类别,从而理解图像的含义。
延伸:图像处理和计算机视觉/机器视觉区别?
图像处理:输入的是 Image --> 输出的是 Image
计算机视觉/机器视觉:输入的是 Image --> 输出的是 Feature(大致理解:对图像的理解)
7、基本的图像操作?
- 按照处理图像的数量分类:单幅图像操作(如滤波)和对多幅图像操作(如求和、求差和逻辑运算等)
- 按照参与操作的像素范围的不同:点运算和邻运算
- 根据操作的数学性质:线性操作和非线性操作
点运算指的是对图像中的每一个像素逐个进行同样的灰度变换运算。点运算可以使用下式定义:s=T(r),其中,T 为采用点运算算子,表示了再原始图像和输出图像之间的某种灰度映射关系。点运算常常用于改变图像的灰度范围及分布。点运算引其作用的性质有时也被称为对比度增强、对比度拉伸或灰度变换。
而如果讲点运算扩展,对图像的每一个小范围(领域)内的像素进行灰度变换运算,即称为领域运算或领域滤波。g(x,y)=T(f(x,y))
线性和非线性操作:若对于任意两幅(或两组)图像 F1 和 F2 及任意两个标量 a 和 b 都有:H(aF1+bF1)=aH(F1)+bH(F2),则称 H 为线性算子。不符合上述定义的算子即为非线性算子,对应的的是非线性图像操作。
① 图像的点运算:
要点: <参考《数字图像处理与机器视觉》>
- 灰度直方图
- 灰度的线性变化
- 灰度的对数变化
- 伽马变化
- 灰度阈值变化
- 分段线性变化
- 直方图均衡化
- 直方图规定化(匹配)
灰度直方图: 是个二维图,横坐标为图像中各个像素点的灰度级别,纵坐标表示具有各个灰度级别的像素在图像中出现的次数或概率。(而归一化直方图的纵坐标则对应着灰度级别在图像中出现的概率)
直方图均衡化: 又称位灰度均衡化,是指通过某种灰度映射使输入图像转换为在每一灰度级上都有近似相同的像素点数的输出图像(即输出的直方图是均匀的)。
② 图像的几何变化:
要点:<参考《数字图像处理与机器视觉》>
- 图像平移
- 图像镜像
- 图像转置
- 图像缩放
- 图像旋转
- 插值算法
- 图像配准简介
图像几何变化又称为图像空间变化,它将一副图像中的坐标位置映射到另一副图像中的新坐标位置。学习几何变化的关键是要确定这种空间映射关系,以及映射过程中的变化参数。
几何变换不改变图像的像素值,只是在图像平面上进行像素的重新安排。
一个几何变换需要两部分运算:首先是空间变换所需的运算,还需要灰度插值算法。<参考《数字图像处理与机器视觉》P92>
实现几何运算时,有两种方法。第一种称为向前映射法,其原理是将输入图像的灰度一个像素一个像素地转移到输出图像中,即从原图像坐标计算出目标图像坐标。第二中是向后映射法,它是向前映射变换的逆,即输出像素一个一个地映射回输入图像中。(参考《数字图像处理与机器视觉》P106)
我们再来看看《数字图像处理与机器视觉》该书有关几个图像研究内容的解释:
-
图像配准:图像配准技术是站在几何失真归一化的角度,以一种逆变换的思路来阐述几何变换。 百度百科:图像归一化
所谓图像匹配准就是讲同一场景的两幅或多幅图像进行对准,如人脸自动分析系统中的人脸归一化,即要使各张照片中的人脸具有近似的大小,尽量处于相同的位置。
-
图像增强:增强的目的是消除噪声,显现那些被模糊了的细节或简单地突出一副图像中读者感兴趣的特征。
增强是图像处理中非常主观的领域,这与图像复原技术刚好相反,图像复原也是改进图像外貌的一个处理领域,但它是客观的。
-
图像分割:
图像分割是指将图像中具有特殊意义的不同区域划分开来,这些区域是互不相交的,每个区域满足灰度、纹理、彩色等特征的某种相似性准则。图像分割是图像的分析过程中最重要的步骤之一,分割出来的区域可以作为后续特征提取的目标对象。<***《数字图像处理与机器视觉》P395*** >
更多内容还是得翻阅《数字图像处理与机器视觉》以及冈萨雷斯的《数字图像处理》。
8、什么是遥感图像?
9、什么是滤波?
- 阮一峰:图像与滤波
二、计算机视觉
2.1 CV相关研究方向及区别
参考文章:
- 知乎:图像识别中,目标分割、目标识别、目标检测和目标跟踪这几个方面区别是什么?
- 计算机视觉领域不同的方向:目标识别、目标检测、语义分割等
- computer vision一些术语-目标识别、目标检测、目标分割、语义分割等
- 图像分割算法及与目标检测、目标识别、目标跟踪的关系
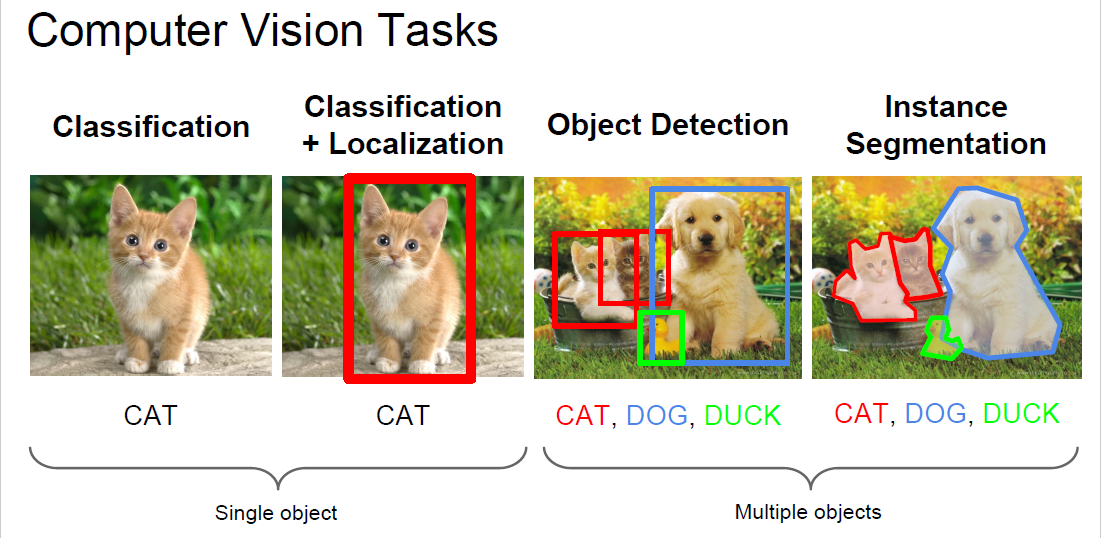
- 计算机视觉四大基本任务(分类、定位、检测、分割)——Hao Zhang的知乎回答(这个解释的也很好)
-------------------------------------------稍微总结下-----------------------------------------
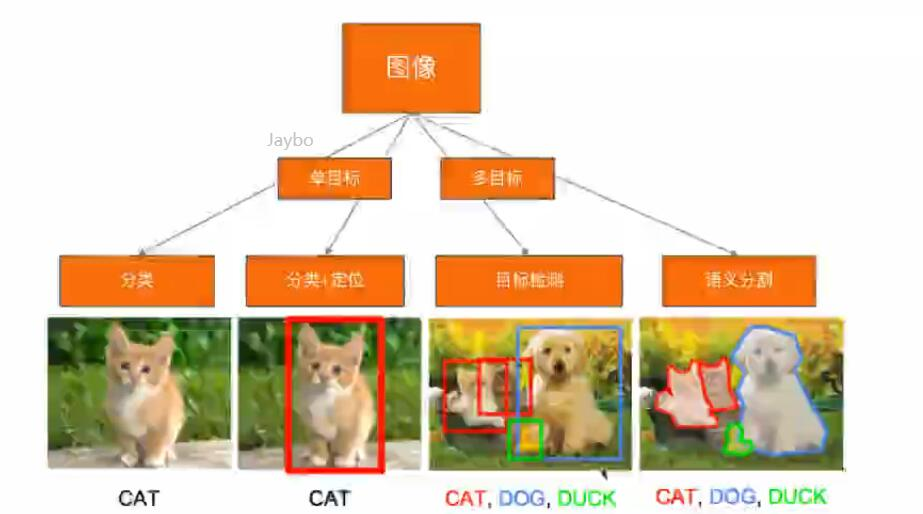
图像分类:根据图像的主要内容进行分类。
数据集:MNIST,CIFAR,ImageNet
目标检测:给定一幅图像,只需要找到一类目标所在的矩形框。
人脸检测:人脸为目标,框出一幅图片中所有人脸所在的位置,背景为非目标
汽车检测:汽车为目标、框出一幅图片中所有汽车所在的位置,背景为非目标
数据集:PASCAL,COCO
目标识别:将需要识别的目标,和数据库中的某个样例对应起来,完成识别功能。
人脸识别:人脸检测,得到的人脸,再和数据库中的某个样例对应起来,进行识别,得到人脸的具体信息
数据集:PASCAL,COCO
语义分割:对图像中的每个像素都划分出对应的类别,即对一幅图像实现像素级别的分类。
数据集:PASCAL,COCO
实例分割:对图像中的每个像素都划分出对应的类别,即实现像素级别的分类,类的具体对象,即为实例,那么实例分割不但要进行像素级别的分类,还需在具体的类别基础上区别开不同的实例。
比如说图像有多个人甲、乙、丙,语义分割结果都是人,而实例分割结果却是不同的对象。
PS:有几点需要说的!
-
目标检测和目标识别的区别?
在看到的某篇博客是这样写道的:
目标检测:就是在一张图片中找到并用box标注出所有的目标。(注意:目标检测和目标识别不同之处在于,目标检测只有两类,目标和非目标. )
目标识别:就是检测和用box标注出所有的物体,并标注类别。
在后面我的查找资料下,发现上面的认识不算是正确理解,正确理解是,目标检测是从大图中框出目标物体并识别,注意,目标检测还得识别出来框出的是什么,可参考知乎 许铁-巡洋舰科技 回答,他在回答中提到 R-CNN,这个网络不仅可以告诉你分类,还可以告诉你目标物体的坐标, 即使图片里有很多目标物体, 也一一给你找出来。
关于图像分类、点位、检测等内容,可以看看李飞飞cs231课程提到的:CS231n第八课:目标检测定位学习记录
一些其他方面的研究:
- CSDN专栏:图像配准(图像配准算法介绍及部分实现)
2.2 图像分割
2.2.1 图像分割传统方法
知乎这篇文章 图像分割 传统方法 整理 整理了一些图像分割传统的方法,当然也是来源于网络,下面小结下:
图片分割根据灰度、颜色、纹理、和形状等特征将图像进行划分区域,让区域间显差异性,区域内呈相似性。主要分割方法有:
- 基于阈值的分割
- 基于边缘的分割
- 基于区域的分割
- 基于图论的分割
- 基于能量泛函的分割
(有时间可以研读下相关传统方法怎么做的...)
2.2.2 图像分割深度学习方法(语义分割&实例分割)
重点关注的一些神经网络模型:
FCN、Unet、SegNet、DeconvNet、PSPnet、DeepLab(v1、v2、v3)等等。
这几篇文章有提到上面所说的很多神经网络模型:
- 语义分割(semantic segmentation) 常用神经网络介绍对比-FCN SegNet U-net DeconvNet
- 深度学习(十九)——FCN, SegNet, DeconvNet, DeepLab, ENet, GCN
这篇文章 十分钟看懂图像语义分割技术 把图像分割技术及发展介绍的很详细。
相关综述类/总结类文章参考:
- 从全连接层到大型卷积核:深度学习语义分割全指南
- 分割算法——可以分割一切目标(各种分割总结)
- 一文概览主要语义分割网络:FCN,SegNet,U-Net...
该文为译文,介绍了很多语义分割的神经网络模型,包括半监督下的语义分割,有一些是下文模型具体介绍还没有的列举的。可以先大致看下。
当前图像分割研究方向:
相关视频:
图像分割方面论文汇集:
-
语义分割 - Semantic Segmentation Papers
图像分割相关论文可以在该博主整理的资料找找。
-------------------------------一些常见图像分割神经网络模型具体介绍-------------------------
在介绍图像分割神经网络模型之前,先引入下该文(分割算法——可以分割一切目标(各种分割总结))的一段话:
1、会有很多人问:什么是语义分割?
语义分割其实就是对图片的每个像素都做分类。其中,较为重要的语义分割数据集有:VOC2012 以及 MSCOCO 。
2、比较流行经典的几种方法
传统机器学习方法:如像素级的决策树分类,参考 TextonForest 以及 Random Forest based classifiers。再有就是深度学习方法。
深度学习最初流行的分割方法是,打补丁式的分类方法 (patch classification) 。逐像素地抽取周围像素对中心像素进行分类。由于当时的卷积网络末端都使用全连接层 (full connected layers) ,所以只能使用这种逐像素的分割方法。
但是到了 2014 年,来自伯克利的 Fully Convolutional Networks(FCN) 卷积网络,去掉了末端的全连接层。随后的语义分割模型基本上都采用了这种结构。除了全连接层,语义分割另一个重要的问题是池化层。池化层能进一步提取抽象特征增加感受域,但是丢弃了像素的位置信息。但是语义分割需要类别标签和原图像对齐,因此需要从新引入像素的位置信息。有两种不同的架构可以解决此像素定位问题。
- 第一种是编码-译码架构。编码过程通过池化层逐渐减少位置信息、抽取抽象特征;译码过程逐渐恢复位置信息。一般译码与编码间有直接的连接。该类架构中 U-net 是最流行的。
- 第二种是膨胀卷积 (dilated convolutions) 【这个核心技术值得去阅读学习】,抛弃了池化层。
☛【2014】FCN:
Fully Convolutional Networks 是 Jonathan Long 和 Evan Shelhamer 于 2015 年提出的网络结构。
Fully convolutional networks for semantic segmentation 是 2015 年发表在 CVPR 上的一片论文,提出了全卷积神经网络的概念,差点得了当前的最佳论文,没有评上的原因好像是有人质疑,全卷积并不是一个新的概念,因为全连接层也可以看作是卷积层,只不过卷积核是原图大小而已。
论文:使用全卷积网络进行语义分割《Fully Convolutional Networks for Semantic Segmentation》 [Paper-v1] [Paper-v2] (最新提交时间:2015.03.08)
主要贡献:
- 推广端到端卷积网络在语义分割领域的应用
- 修改 Imagenet 预训练网络并应用于语义分割领域
- 使用解卷积层进行上采样
- 使用跳跃连接,改善上采样的粒度程度
相关中文资料:
☛【2015】U-Net:
U-Net 是基于 FCN 的一个语义分割网络,适合用来做医学图像的分割。数据集下载并代码实战看这篇:全卷机神经网络图像分割(U-net)-keras实现
论文:生物医学图像分割的卷积神经网络《U-Net: Convolutional Networks for Biomedical Image Segmentation》[Paper] (最新提交时间:2015.05.18)
官网:lmb.informatik.uni-freiburg.de/people/ronn…
相关中文资料:
☛【2015】SegNet:
SegNet 是 Vijay Badrinarayanan 于 2015 年提出的,它是一个 encoder-decoder 结构的卷积神经网络。
论文:用于图像分割的一种深度卷积编码器-解码器架构《SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2016.11.10)
主要贡献:
- 将最大池化索引(Maxpooling indices)转移到解码器,从而改善分割分辨率。
DEMO 网站:mi.eng.cam.ac.uk/projects/se…
相关中文资料:
☛【2015】Dilated Convolutions:
论文:使用空洞卷积进行多尺度背景聚合《Multi-Scale Context Aggregation by Dilated Convolutions》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2016.04.30)
主要贡献:
- 使用空洞卷积,一种可进行稠密预测的卷积层。
- 提出「背景模块」(context module),该模块可使用空洞卷积进行多尺度背景聚合。
☛【2015】DeconvNet:
DeconvNet 是韩国的 Hyeonwoo Noh 于 2015 年提出的。
DeconvNet 是一个 convolution-deconvolution 结构的神经网络,和 SegNet 非常相似。是一篇 2015 年 ICCV 上的文章:Learning Deconvolution Network for Semantic Segmentation
论文:学习反卷积网络进行语义分割《Learning Deconvolution Network for Semantic Segmentation》[Paper] (最新提交时间:2015.05.17)
相关中文资料:
☛【2016】RefineNet:
论文:使用多路径精炼网络进行高分辨率语义分割《RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2016.11.25)
主要贡献:
- 具备精心设计解码器模块的编码器-解码器架构
- 所有组件遵循残差连接设计
相关中文资料:
☛【2016】PSPNet:
论文:金字塔场景解析网络《Pyramid Scene Parsing Network》[Paper-v1] [Paper-v2] (最新提交时间:2017.04.27)
主要贡献:
- 提出金字塔池化模块帮助实现背景聚合
- 使用辅助损失(auxiliary loss)。
相关中文资料:
☛【2017】Large Kernel Matters:
论文:大型核的问题——通过全局卷积网络改善语义分割《Large Kernel Matters -- Improve Semantic Segmentation by Global Convolutional Network》[Paper] (最新提交时间:2017.03.08)
主要贡献:
- 提出使用带有大型卷积核的编码器-解码器结构
☛【2014 、2016、2017】DeepLab(v1、v2、v3、v3+):
【2014】v1:使用深度卷积网络和全连接 CRF 进行图像语义分割《Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs》[Paper-v1] [Paper-v2] [Paper-v3] [Paper-v4] (最新提交时间 :2016.06.07)
相关中文资料:
【2016】v2:使用深度卷积网络、带孔卷积和全连接 CRF 进行图像语义分割《DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs》[Paper-v1] [Paper-v2] (最新提交时间:2017.05.12)
相关中文资料:
v1 & v2 主要贡献:
- 使用带孔/空洞卷积。
- 提出金字塔型的空洞池化(ASPP)
- 使用全连接 CRF
【2017】v3:重新思考使用空洞卷积进行图像语义分割《Rethinking Atrous Convolution for Semantic Image Segmentation》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2017.12.05)
v3 主要贡献:
- 改进了金字塔型的空洞池化(ASPP)
- 模型级联了多个空洞卷积
与 DeepLab v2 和空洞卷积论文一样,该研究也使用空洞/扩张卷积来改进 ResNet 模型。
相关中文资料:
【2017】v3+:用于语义图像分割的具有可变分离卷积的编码器 - 解码器《Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2018.08.22)
谷歌开源的语义图像分割模型 DeepLab-v3+,DeepLab-v3+ 结合了空间金字塔池化模块和编码器-解码器结构的优势,是自三年前的 DeepLab 以来的最新、性能最优的版本。GitHub 地址:github.com/tensorflow/…
相关中文资料:
☛【2017】Mask R-CNN:
论文:《Mask R-CNN》[Paper-v1] [Paper-v2] [Paper-v3] (最新提交时间:2018.01.24)
相关中文资料:
☛【2018】《Searching for Efficient Multi-Scale Architectures for Dense Image Prediction》
为密集的图像预测寻找高效的多尺度架构
arxiv:1809.04184 (2018) Paper-v1(2018.09.11)
相关中文资料:
图像分割衡量标准:
2.2.3 关于图像分割的比赛、数据集
比赛:
图像分割数据集:
目前有一些常用于训练语义分割模型的数据集:(较为重要的语义分割数据集有:VOC2012 以及 MSCOCO)
-
Pascal VOC 2012:有 20 类目标,这些目标包括人类、机动车类以及其他类,可用于目标类别或背景的分割
这里是它的主页,这里是leader board,很多公司和团队都参与了这个挑战,很多经典论文都是采用这个挑战的数据集和结果发表论文,包括 RCNN、FCN 等。关于这个挑战,有兴趣可以读一下这篇论文。
-
Cityscapes:50 个城市的城市场景语义理解数据集
-
Pascal Context:有 400 多类的室内和室外场景
-
Stanford Background Dataset:至少有一个前景物体的一组户外场景。
!!!延伸——深度学习视觉领域相关数据集介绍:
-
ImageNet 数据集是目前深度学习图像领域应用得非常多的一个数据集,关于图像分类、定位、检测等研究工作大多基于此数据集展开。
ImageNet 数据集有 1400 多万幅图片,涵盖 2 万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注,具体信息如下:
1)Total number of non-empty synsets: 21841
2)Total number of images: 14,197,122
3)Number of images with bounding box annotations: 1,034,908
4)Number of synsets with SIFT features: 1000
5)Number of images with SIFT features: 1.2 million
ImageNet 数据集文档详细,有专门的团队维护,使用非常方便,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。
ImageNet 数据集是一个非常优秀的数据集,但是标注难免会有错误,几乎每年都会对错误的数据进行修正或是删除,建议下载最新数据集并关注数据集更新。
与 ImageNet 数据集对应的有一个享誉全球的“ImageNet国际计算机视觉挑战赛(ILSVRC)”,目前包含的比赛项目有:
- 目标定位
- 目标检测
- 视频序列的目标检测
- 场景分类
- 场景分析
数据集大小:~1TB(ILSVRC 2016 比赛全部数据)
注:ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)比赛用的子数据集,其中:
- 训练集:1281167 张图片+标签
- 验证集:50000 张图片+标签
- 测试集:100000 张图片
补充点内容:MNIST 将初学者领进了深度学习领域,而 ImageNet 数据集对深度学习的浪潮起了巨大的推动作用。深度学习领域大牛 Hinton 在 2012 年发表的论文《ImageNet Classification with Deep Convolutional Neural Networks》在计算机视觉领域带来了一场“革命”,此论文的工作正是基于 ImageNet 数据集。
-
COCO 数据集是大规模物体检测(detection)、分割(segmentation)和图说(captioning)数据集,包括 330K 图像(其中超过 200K 有注释),150 万图像实例,80 个物体类别,91 种物质(stuff)类别,每幅图有 5 条图说,250000 带有关键点的人体。
COCO 数据集由微软赞助,其对于图像的标注信息不仅有类别、位置信息,还有对图像的语义文本描述,COCO 数据集的开源使得近两三年来图像分割语义理解取得了巨大的进展,也几乎成为了图像语义理解算法性能评价的“标准”数据集。Google 的开源 show and tell 生成模型就是在此数据集上测试的。 目前包含的比赛项目有:
- 目标检测
- 图像标注
- 人体关键点检测
数据集大小:~40GB
补充点内容:MS COCO(Microsoft Common Objects in Context,常见物体图像识别)竞赛是继 ImageNet 竞赛(已停办)后,计算机视觉领域最受关注和最权威的比赛之一,是图像(物体)识别方向最重要的标杆(没有之一),也是目前国际领域唯一能够汇集谷歌、微软、Facebook 三大巨头以及国际顶尖院校共同参与的大赛。
-
PASCAL VOC 挑战赛是视觉对象的分类识别和检测的一个基准测试,提供了检测算法和学习性能的标准图像注释数据集和标准的评估系统。PASCAL VOC 图片集包括 20 个目录:人类;动物(鸟、猫、牛、狗、马、羊);交通工具(飞机、自行车、船、公共汽车、小轿车、摩托车、火车);室内(瓶子、椅子、餐桌、盆栽植物、沙发、电视)。
PASCAL VOC 挑战赛在 2012 年后便不再举办,但其数据集图像质量好,标注完备,非常适合用来测试算法性能。
数据集大小:~2GB
-
CIFAR-10 包含 10 个类别,50000 个训练图像,彩色图像大小:32x32,10000 个测试图像。
CIFAR-100 与 CIFAR-10 类似,包含 100 个类,每类有 600 张图片,其中 500 张用于训练,100 张用于测试;这 100 个类分组成 20 个超类。图像类别均有明确标注。
CIFAR 对于图像分类算法测试来说是一个非常不错的中小规模数据集。
数据集大小:~170MB
-
深度学习领域的“Hello World!”!MNIST是一个手写数字数据集,它有 60000 个训练样本集和 10000 个测试样本集,每个样本图像的宽高为 28*28。需要注意的是,此数据集是以二进制存储的,不能直接以图像格式查看。 最早的深度卷积网络 LeNet 便是针对此数据集的,当前主流深度学习框架几乎无一例外将 MNIST 数据集的处理作为介绍及入门第一教程。
数据集大小:~12MB
-
KITTI 由德国卡尔斯鲁厄理工学院(Karlsruhe Institute of Technology)和丰田芝加哥技术研究院(Toyota Technological Institute at Chicago)于2012年联合创办,是目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集。用于评测 3D 目标(机动车、非机动车、行人等)检测、3D 目标跟踪、道路分割等计算机视觉技术在车载环境下的性能。KITTI包含市区、乡村和高速公路等场景采集的真实图像数据,每张图像中多达 15 辆车和 30 个行人,还有各种程度的遮挡。
-
Cityscapes 也是自动驾驶相关方面的数据集,重点关注于像素级的场景分割和实例标注。
-
在这个数据集上,基于深度学习的系统 DeepID2 可以达到 99.47% 的识别率。
遥感、卫星图像常用数据集:
遥感、卫星图像分割:
图像分割方面的代码:
2.2.4 关于图像分割的最新研究及关注点
最新的一些相关研究:(更新于 2018-09-12)
- 学界 | 上海交大卢策吾团队开源PointSIFT刷新点云语义分割记录
- 优于Mask R-CNN,港中文&腾讯优图提出PANet实例分割框架
- MIT提出精细到头发丝的语义分割技术,打造效果惊艳的特效电影
- 论文阅读 - Semantic Soft Segmentation
- Polygon-RNN++ | 图像分割数据集自动标注
- 谷歌等祭出图像语义理解分割神器,PS再也不用专业设计师!
关注的一些大牛&实验室&期刊等:
- 南开大学媒体计算实验室_程明明:mmcheng.net/zh/code-dat… (解压密码:
mmcheng.net) - Liang-Chieh Chen:个人主页
DeepLab v1/v2/v3/v3+、最新研究神经网络搜索实现语义分割《Searching for Efficient Multi-Scale Architectures for Dense Image Prediction》作者都是他。
- Facebook AI 实验室科学家&香港中文大学博士:何凯明
- 斯坦福人工智能研究院:李飞飞
- 等等......(以后在补充~)
- 顶级会议、期刊等
- ICCV(IEEE International Conference on Computer Vision,国际计算机视觉大会):由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。
- CVPR(IEEE Conference on Computer Vision and Pattern Recognition,IEEE国际计算机视觉与模式识别会议):该会议是由IEEE举办的计算机视觉和模式识别领域的顶级会议。
- ECCV(European Conference on Computer Vision,欧洲计算机视觉国际会议):两年一次,是计算机视觉三大会议(另外两个是ICCV和CVPR)之一。每次会议在全球范围录用论文300篇左右,主要的录用论文都来自美国、欧洲等顶尖实验室及研究所,中国大陆的论文数量一般在10-20篇之间。ECCV2010的论文录取率为27%。
- 等其他.....
2.2.5 图像分割学习与实践
1、李沫 文章:语义分割和数据集 YouTube 视频:动手学深度学习第十课:语义分割
图片分类关心识别图片里面的主要物体,物体识别则进一步找出图片的多个物体以及它们的方形边界框。本小节我们将介绍语义分割(semantic segmentation),它在物体识别上更进一步的找出物体的精确边界框。换句话说,它识别图片中的每个像素属于哪类我们感兴趣的物体还是只是背景。下图演示猫和狗图片在语义分割中的标注。可以看到,跟物体识别相比,语义分割预测的边框更加精细。
在计算机视觉里,还有两个跟语义分割相似的任务。一个是图片分割(image segmentation),它也是将像素划分到不同的类。不同的是,语义分割里我们赋予像素语义信息,例如属于猫、狗或者背景。而图片分割则通常根据像素本身之间的相似性,它训练时不需要像素标注信息,其预测结果也不能保证有语义性。例如图片分割可能将上图中的狗划分成两个区域,其中一个嘴巴和眼睛,其颜色以黑色为主,另一个是身体其余部分,其主色调是黄色。 另一个应用是实例分割(instance segementation),它不仅需要知道每个像素的语义,即属于那一类物体,还需要进一步区分物体实例。例如如果图片中有两只狗,那么对于预测为对应狗的像素是属于地一只狗还是第二只。

2、雷锋网:浙大博士生刘汉唐:带你回顾图像分割的经典算法 | 分享总结
2.3 目标检测
需要关注的一些神经网络模型:
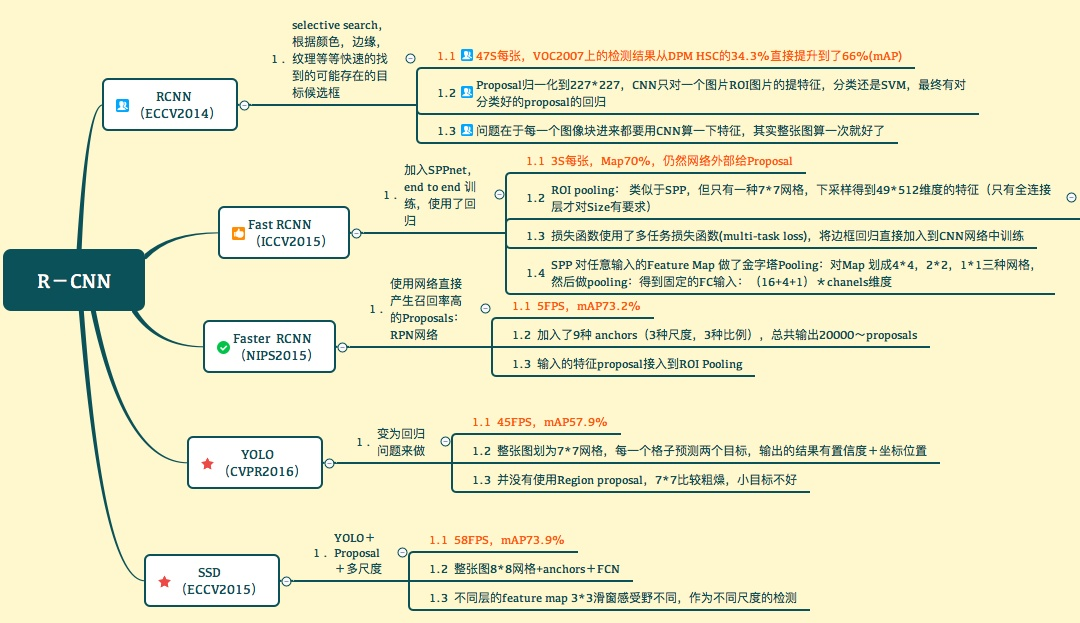
- 一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
- 三年来,CNN在图像分割领域经历了怎样的技术变革?
- Mask R-CNN实例分割通用框架,检测,分割和特征点定位一次搞定(多图)
论文下载:
- 【2014】R-CNN 论文地址: arxiv.org/abs/1311.25…
- 【2015】Fast R-CNN 论文地址: arxiv.org/abs/1504.08…
- 【2016】Faster R-CNN 论文地址: arxiv.org/abs/1506.01…
- 【2017】Mask R-CNN 论文地址: arxiv.org/abs/1703.06…
R-CNN:是将 CNN 用于物体检测的早期应用。
R-CNN 的目标是:导入一张图片,通过方框正确识别主要物体在图像的哪个地方。
输入:图像 输出:方框+每个物体的标签
Fast R-CNN:它加速、简化了 R-CNN。
Faster R-CNN:名字很直白,它加速了选区推荐。
Mask R-CNN:把 Faster R-CNN 拓展到像素级的图像分割。
Mask R-CNN:一种目标实例分割(object instance segmentation)框架。该框架较传统方法操作更简单、更灵活。研究人员把实验成果《Mask R-CNN》发布在了arXiv上,并表示之后会开源相关代码。
一般来说,目标分割的难点在于,它需要正确识别出图像中所有物体的方向,并且要将不同物体精准区分开。因此,这里面涉及到两个任务:
- 用物体识别技术识别物体,并用边界框表示出物体边界;
- 用语义分割给像素分类,但不区分不同的对象实例。
PS:知乎问答 如何评价rcnn、fast-rcnn和faster-rcnn这一系列方法? 也提到了目标检测涉及到的模型 RCNN、Fast RCNN、Faster RCNN、YOLO、SSD 等,并且 B 站也有相关视频可以观看,比如 Mask R-CNN实战之蒙版弹幕黑科技实现 YOLO RCNN 目标检测
相关视频:
2.4 计算机视觉牛人博客及代码
参考:
三、ML和DL入门
3.1 写在前面
认识:
目前我们通过机器学习去解决这些问题的思路都是这样的(以视觉感知为例子):
从开始的通过传感器(例如 CMOS)来获得数据。然后经过预处理、特征提取、特征选择,再到推理、预测或者识别。最后一个部分,也就是机器学习的部分,绝大部分的工作是在这方面做的,也存在很多的 paper 和研究。 而中间的三部分,概括起来就是特征表达。良好的特征表达,对最终算法的准确性起了非常关键的作用,而且系统主要的计算和测试工作都耗在这一大部分。但,这块实际中一般都是人工完成的。靠人工提取特征。
机器学习如何入门:
- 知乎:机器学习该怎么入门?
机器学习资料及学习路线:
- 2018年,你想要的机器/深度学习资料都在这!
- 关于机器学习,这可能是目前最全面最无痛的入门路径和资源!
- 机器学习和深度学习视频资料精选(附学习资料)
- 知乎:纯新手自学入门机器/深度学习指南(附一个月速成方案)
- 关于机器学习,这可能是目前最全面最无痛的入门路径和资源!
- 知乎:学习攻略 | 机器学习 学习路线图
- MachineLearning(机器学习) 学习路线图
一些优秀 GitHub 仓库及资料:
- GitHub:MachineLearning
- 邱锡鹏:神经网络与深度学习 PDF
- 《机器学习实战》书籍中的代码 GitHub:machinelearninginaction
优秀博客:
- 刘建平Pinard:www.cnblogs.com/pinard/cate…
- Poll的笔记:www.cnblogs.com/maybe2030
- Charlotte77:www.cnblogs.com/charlotte77…
- ......
3.2 机器学习
- 理解梯度下降
- 小谈导数、梯度和极值
- 知乎回答:神经网络激励函数的作用是什么?有没有形象的解释?
- Logistic Regression(逻辑回归)原理及公式推导(该文对逻辑回归公式怎么来的写的很清楚~)
机器学习十大常用算法:轻松看懂机器学习十大常用算法
1. 决策树
2. 随机森林算法
3. 逻辑回归
4. SVM
5. 朴素贝叶斯
6. K最近邻算法
7. K均值算法
8. Adaboost 算法
9. 神经网络
10. 马尔可夫
机器学习实践:
3.3 深度学习
深度学习的发展:
入门文章:
-
What's Deep Learning and why it is so powerful ?
介绍什么是深度学习、深度学习为什么这么屌、深度学习的应用和潜力 3 个问题。
-
阮一峰:神经网络入门
问题:
- 什么是数据标注:互联网数据标注员是做什么的?有什么发展前途吗?
深度学习笔记类:
-
吴恩达老师的深度学习课程笔记及资源 GitHub:deeplearning_ai_books
博文:
-
油管视频:课时71 神经网络 反向传播
-
红色石头:6 种激活函数核心知识点,请务必掌握!
讲解了为什么时候激活函数,6 种激活函数——Sigmoid、tanh、ReLU、Leaky ReLU、ELU、Maxout 的优缺点等内容。
有的激活函数可能会导致梯度消失或爆炸。(为什么会这样?请先熟悉反向传播怎么计算的...下次来细讲下。)
为什么说都说神经网络是个黑箱?
-

神经网络游乐场:playground
深度学习这块,几个层次:(来源 Charlotte:三个月教你从零入门深度学习)
demo侠:下载了目前所有流行的框架,对不同框里的例子都跑一跑,看看结果,觉得不错就行了,进而觉得,嘛,深度学习也不过如此嘛,没有多难啊。这种人,我在面试的时候遇到了不少,很多学生或者刚转行的上来就是讲一个demo,手写数字识别,cifar10数据的图像分类等等,然而你问他这个手写数字识别的具体过程如何实现的?现在效果是不是目前做好的,可以再优化一下吗?为什么激活函数要选这个,可以选别的吗?CNN的原理能简单讲讲吗?懵逼了。
调参侠:此类人可能不局限于跑了几个demo,对于模型里的参数也做了一些调整,不管调的好不好,先试了再说,每个都试一下,学习率调大了准确率下降了,那就调小一点,那个参数不知道啥意思,随便改一下值测一下准确率吧。这是大多数初级深度学习工程师的现状。当然,并不是这样不好,对于demo侠来说,已经进步了不少了,起码有思考。然而如果你问,你调整的这个参数为什么会对模型的准确率带来这些影响,这个参数调大调小对结果又会有哪些影响,就又是一问三不知了。
懂原理侠:抱歉我起了个这么蠢的名字。但是,进阶到这一步,已经可以算是入门了,可以找一份能养活自己的工作了。CNN,RNN,LSTM信手拈来,原理讲的溜的飞起,对于不同的参数对模型的影响也是说的有理有据,然而,如果你要问,你可以手动写一个CNN吗?不用调包,实现一个最基础的网络结构即可,又gg了。
懂原理+能改模型细节侠:如果你到了这一步,恭喜你,入门了。对于任何一个做机器学习/深度学习的人来说,只懂原理是远远不够的,因为公司不是招你来做研究员的,来了就要干活,干活就要落地。既然要落地,那就对于每一个你熟悉的,常见的模型能够自己手动写代码运行出来,这样对于公司的一些业务,可以对模型进行适当的调整和改动,来适应不同的业务场景。这也是大多数一二线公司的工程师们的现状。然而,对于模型的整体架构能力,超大数据的分布式运行能力,方案设计可能还有所欠缺,本人也一直在这个阶段不停努力,希望能够更进一步。
超大数据操控侠:到这一阶段,基本上开始考虑超大数据的分布式运行方案,对整体架构有一个宏观的了解,对不同的框架也能指点一二。海量数据的分布式运行如何避免网络通信的延迟,如何更高效更迅速的训练都有一定经验。这类人,一般就是我这种虾米的领导了。
模型/框架架构师:前面说了一堆都是对现有的框架/模型处理的经验,这个阶段的大侠,哦,不对,是大师可以独立设计开发一套新框架/算法来应对现有的业务场景,或者解决一直未解决的历史遗留问题。没啥好说了,膜拜!
3.3.1 CNN(卷积神经网络)
1、认识
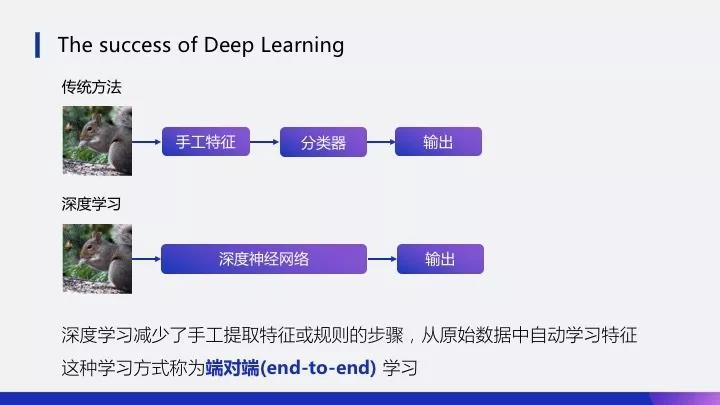
假设有一张图,要做分类,传统方法需要手动提取一些特征,比如纹理啊,颜色啊,或者一些更高级的特征。然后再把这些特征放到像随机森林等分类器,给到一个输出标签,告诉它是哪个类别。而深度学习是输入一张图,经过神经网络,直接输出一个标签。特征提取和分类一步到位,避免了手工提取特征或者人工规则,从原始数据中自动化地去提取特征,是一种端到端(end-to-end)的学习。相较于传统的方法,深度学习能够学习到更高效的特征与模式。
补充点内容:端对端怎么理解?——参考:知乎该问答 什么是 end-to-end 神经网络?。看后,我的理解:就是输入是原始数据,输出是最后的结果,只关心输入和输出,中间的步骤全部都不管。
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理(写的非常好的一篇文章)
- 图文并茂地讲解卷积神经网络(可以看到如何卷积计算过程)
- 深度 | 从入门到精通:卷积神经网络初学者指南(附论文)(这篇文章写的非常全面,值得看)
- 知乎:能否对卷积神经网络工作原理做一个直观的解释?
YJango的回答:www.zhihu.com/question/39…
- 卷积神经网络CNN(1)——图像卷积与反卷积(后卷积,转置卷积)
在计算机中,图像是如何被表达和存储的呢?

2、卷积过程
卷积的计算过程:(图文并茂地讲解卷积神经网络)
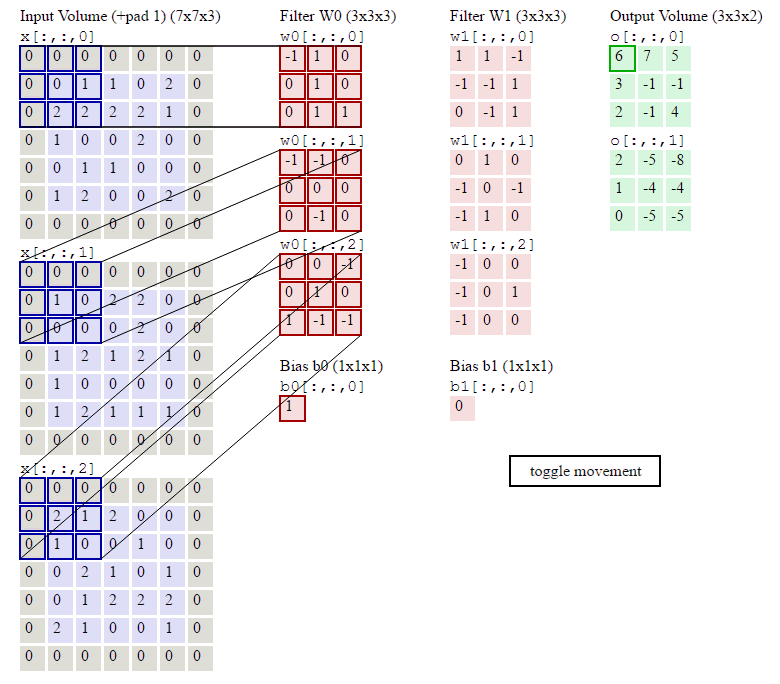
下面这张图为李宏毅深度学习视频课程的截图:
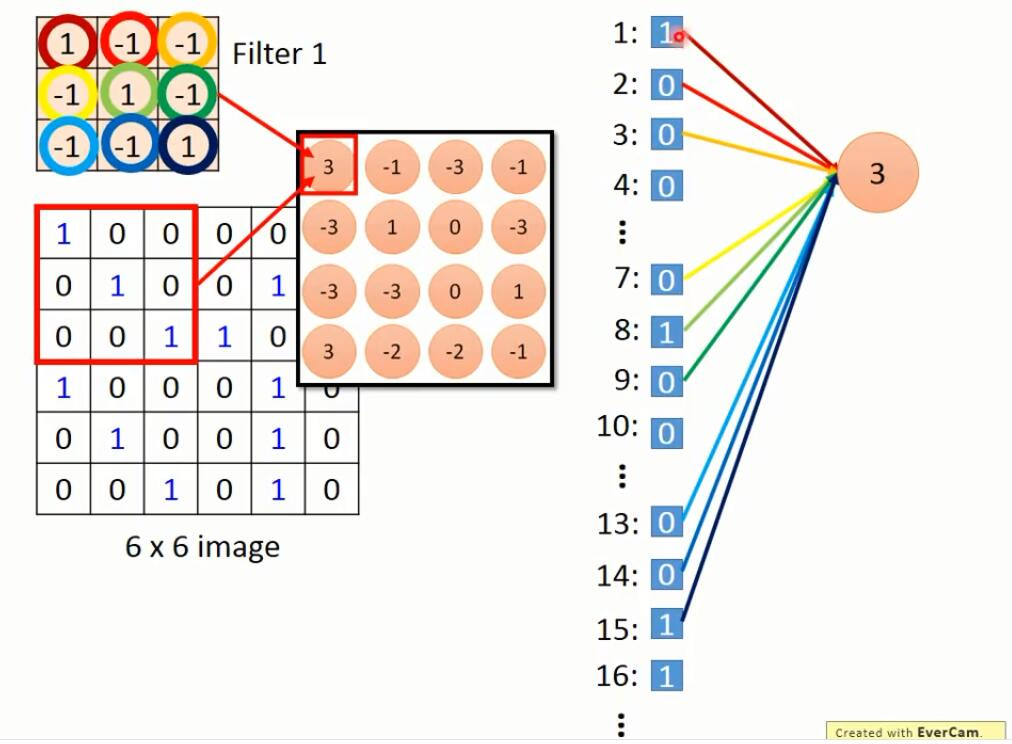
左区域的三个大矩阵是原式图像的输入,RGB三个通道用三个矩阵表示,大小为773。
Filter W0表示1个filter助手,尺寸为3*3,深度为3(三个矩阵);Filter W1也表示1个filter助手。因为卷积中我们用了2个filter,因此该卷积层结果的输出深度为2(绿色矩阵有2个)。
Bias b0是Filter W0的偏置项,Bias b1是Filter W1的偏置项。
OutPut是卷积后的输出,尺寸为3*3,深度为2。
思考:
①为什么每次滑动是2个格子?
滑动的步长叫stride记为S。S越小,提取的特征越多,但是S一般不取1,主要考虑时间效率的问题。S也不能太大,否则会漏掉图像上的信息。
②由于filter的边长大于S,会造成每次移动滑窗后有交集部分,交集部分意味着多次提取特征,尤其表现在图像的中间区域提取次数较多,边缘部分提取次数较少,怎么办?
一般方法是在图像外围加一圈0,细心的同学可能已经注意到了,在演示案例中已经加上这一圈0了,即+pad 1。 +pad n表示加n圈0.
③一次卷积后的输出特征图的尺寸是多少呢?
特征映射矩阵尺寸计算公式:[(原图片尺寸-卷积尺寸+2Pad)/步长]+1 注意:在一层卷积操作里可以有多个filter,他们是尺寸必须相同。

3、学习资料
- 魏秀参:《解析卷积神经网络—深度学习实践手册》
- ......
4、问题
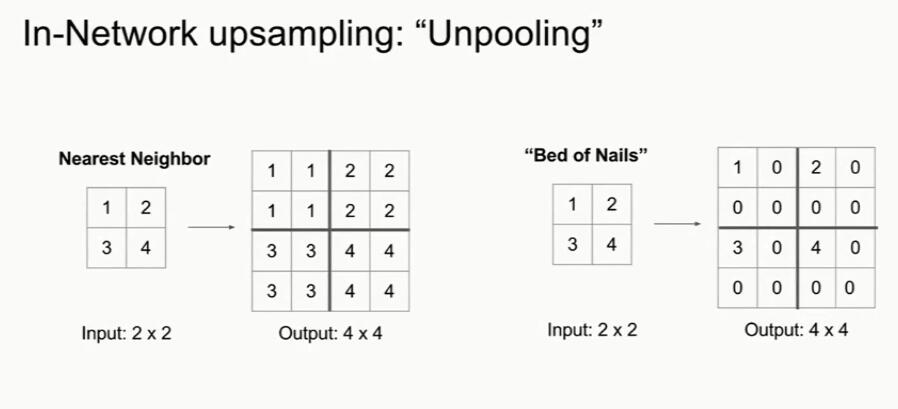
Q1:什么是上采样?
3.3.2 深度学习框架
1、TensorFlow
1)文档
- TensorFlow中文社区
- tensorflow学习笔记(该笔记学习于书籍:《Tensorflow实战Google深度学习框架》)
2)视频
-
B 站:深度学习框架Tensorflow学习与应用、或油管上观看前 10 周视频(共 12 周) :tensorflow教程(十课)
-
油管视频:TF Girls 修炼指南 、或 B 站观看: TF Girls 修炼指南
-
油管视频:51CTO视频 深度学习框架-Tensorflow案例实战视频课程、或 B 站观看:深度学习框架-Tensorflow案例实战视频课程
2、实战
① MNIST 手写数字识别
MNIST 数据集已经是一个被”嚼烂”了的数据集,很多教程都会对它”下手”,几乎成为一个 “典范”。不过有些人可能对它还不是很了解, 下面来介绍一下。
MNIST 数据集可在 yann.lecun.com/exdb/mnist/ 获取,它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz(9.9 MB, 解压后 47 MB, 包含 60,000 个样本)Training set labels: train-labels-idx1-ubyte.gz(29 KB, 解压后 60 KB, 包含 60,000 个标签)Test set images: t10k-images-idx3-ubyte.gz(1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)Test set labels: t10k-labels-idx1-ubyte.gz(5KB, 解压后 10 KB, 包含 10,000 个标签)MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据。
更详细教程及介绍:MNIST 数据
代码:
- tensorflow入门-mnist手写数字识别系列
- CNN实现MNIST手写数字识别
- 一文全解:使用Tensorflow搭建卷积神经网络CNN识别手写数字图片
- Tensorflow 实现 MNIST 手写数字识别
- 神经网络实现手写数字识别(MNIST)
3.4 数据集
计算机视觉:
四、一些思考
- 周志华:关于机器学习的一点思考 - 师的观点客观、清晰
- 崔庆才:分享我对爬虫和 AI 行业的一点看法,顺便打个广告
2018.08.12 未完...... 以上就当是自己对看到的文章、学习资料的梳理,感觉也挺乱的,只希望看到该文的你对你有那么点用处就好~(以后有时间再更新、或重新整理....)
2018.09.26 增加了「3.4 数据集」、「四、一些思考」,以及文中少许修改。
2018.09.27 添加了图像分割神经网络模型的一些介绍以及论文下载地址等内容。
