

- 原文地址:Practical ProGuard rules examples
- 原文作者:Wojtek Kaliciński
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Derek
- 校对者:BillShiyaoZhang
我在之前的文章中解释了 为什么每个人都应该将 ProGuard 用于他们的 Android 应用、怎么启用它以及在使用中可能面临的错误种类。这其中涉及很多理论,因为我认为理解基本原理以准备好处理任何潜在问题非常重要。
我还在一篇单独的文章中谈到了 为 Instant App 构建配置 ProGuard 的非常具体的问题。
在这里,我想谈 ProGuard 规则在中型样例应用上的实用示例:出自 Nick Butcher 的 Plaid.
从 Plaid 中吸取的教训
Plaid 实际上是研究 ProGuard 问题的一个很好的主题,因为它包含使用注解处理与代码生成、反射、Java资源加载和原生代码(JNI)的第三方库的混合体。我提取并记录下了一些适用于其他应用的实用建议:
数据类
public class User {
String name;
int age;
...
}
每个应用可能都有某种数据类(也被称为 DMOs,模型等,取决于上下文以及它们处在应用架构中的位置)。关于数据对象的事实是,通常在某些时候他们将被加载或保存(序列化)到某些其他介质中,例如网络(HTTP 请求)、数据库(通过 ORM)、磁盘上的 JSON 文件或 Firebase 数据存储。
许多简化序列化与反序列化这些字段的工具依赖于反射。GSON、Retrofit、Firebase —— 他们都检查数据类的字段名并把它们转换成另一种表现形式(例如:{“name”: “Sue”, “age”: 28}),用于传输或存储。它们将数据读入 Java 对象时也是同理 —— 它们看到键值对 “name”:”John” 并尝试通过查找 String name 字段将其应用到 Java 对象上。
结论:我们不能让 ProGuard 重命名或删除这些数据类的任何字段,因为它们必须与序列化的格式匹配。最好给整个类添加一个 @Keep 注解或者给所有模型添加通配符规则:
-keep class io.plaidapp.data.api.dribbble.model.** { *; }
警告:在测试你的应用是否容易受到这个问题的影响是可能会出错。例如,如果你在版本 N 的应用程序中将一个对象序列化成 JSON 并将其保存到磁盘而没有使用适当的 keep 规则,那么保存的数据可能看起来像这样:
{“a”: “Sue”, “b”: 28}。因为 ProGuard 将你的字段重命名为a和b,所以一切看起来似乎都有效,数据也会被正确地保存和加载。
然而,当你再一次构建你的应用并发布版本 N+1 的应用时,ProGuard 可能会决定将你的字段重命名为某些其他的,比如
c和d。因此,之前保存的数据将无法加载。
首先你必须确保你有适当的 keep 规则。
从原生层调用的 Java 代码(JNI)
Android 的 默认 ProGuard 文件(你应该总是包括它们,它们有一些非常有用的规则)已经包含了针对在原生层实现的方法的规则(-keepclasseswithmembernames class * { native <methods>; })。遗憾的是,没有一种全能的方法可以保留从反方向调用的代码:从 JNI 到 Java。
利用 JNI,完全有可能从 C / C++ 代码中构造 JVM 对象或者找到并调用 JVM 句柄的方法,而且事实上,Plaid 的一个库就是这样。
结论:因为 ProGuard 只能审查 Java 类,所以它不会知道任何在原生代码中发生的使用。我们必须通过 @Keep 注解或 -keep 规则来显式地保留这些类和成员的使用。
-keep, includedescriptorclasses
class in.uncod.android.bypass.Document { *; }
-keep, includedescriptorclasses
class in.uncod.android.bypass.Element { *; }
从 JAR/APK 打开资源
Android 有其自己的资源系统,通常不会有 ProGuard 的问题。然而,在普通的 Java 中有另一种 直接从 JAR 文件加载资源的机制。并且某些第三方库即使被编译到 Android 应用中也可能会使用这种机制(在这种情况下,它们将尝试从 APK 加载)。
问题是通常这些类会在自己的包名下寻找资源(这将转换为 JAR 或 APK 中的文件路径)。ProGuard 可能在混淆时重命名包名,因此在编译之后可能会发生类及其资源文件不再位于最终 APK 中的同一包内。
要以这种方式识别加载资源,你可以在你的代码和任何你依赖的第三方库中查找 Class.getResourceAsStream / getResource 和 ClassLoader.getResourceAsStream / getResource 的调用。
结论:我们应该保留任何使用这种机制从 APK 加载资源的类的名字。
在 Plaid 中,实际上有两个 —— 一个在 OKHttp 库中,另一个在 Jsoup 库中:
-keepnames class okhttp3.internal.publicsuffix.PublicSuffixDatabase
-keepnames class org.jsoup.nodes.Entities
如何为第三方库制定规则
在理想的世界里,每个你使用的依赖都会在 AAR 中提供他们所需要的 ProGuard 规则。有时他们会忘记这样做或只发布 JAR,这些 JAR 没有标准的方式来提供 ProGuard 规则。
在这种情况下,在开始调试应用和制定规则之前,记得查看文档。一些库的作者提供推荐的 ProGuard 规则(例如在 Plaid 中使用的 Retrofit),这可以为你节省大量时间,并让你免受挫折。遗憾的是,很多库都不会这样(例如这篇文章中提到的 Jsoup 和 Bypass 的情况)。另请注意,在某些情况下,随库提供的配置只能在禁用优化的条件下起作用,因此如果你开启了优化,那么你可能踏入了未知领域。
那么当库没有提供规则时,如何制定规则呢? 我只能给你一些提示:
- 阅读构建输出和 logcat!
- 构建警告会告诉你添加哪些
-dontwarn规则 ClassNotFoundException、MethodNotFoundException和FieldNotFoundException会告诉你添加哪些-keep规则
当你使用了 ProGuard 的应用崩溃时,你应该庆幸 —— 你将有一个开始调查的地方 :)
最糟糕的一类调试问题是你的应用工作了,但是例如屏幕没有显示或没有从网络加载数据。
在这里你需要去考虑我在本文中描述的一些场景并动手实践,甚至扎入第三方库的代码中并理解它可能失败的原因,例如当它使用反射、拦截或 JNI 时。
调试与堆栈跟踪
ProGuard 默认会删除程序执行不需要的许多代码属性和隐藏元数据。其中一些对开发者实际上很有用 —— 例如,你可能希望保留堆栈跟踪的源文件名和行号,以使调试更容易:
-keepattributes SourceFile, LineNumberTable
你也应当记得 保存构建发行版本时生成的 ProGuard 映射文件并将其上传到 Play 以便从用户遇到的任何崩溃中得到反混淆的堆栈跟踪。
如果要在使用 ProGuard 构建的应用中附加调试器来逐步执行方法代码,那么你还应该保留以下属性,以保留关于局部变量的一些调试信息(在 debug 构建类型中只需要这一行):
-keepattributes LocalVariableTable, LocalVariableTypeTable
缩小的调试构建类型
构建类型的默认配置为 debug 不使用 ProGuard。这很有道理,因为我们希望在开发时快速迭代和编译,但仍然希望使用 ProGuard 来构建发布版本以使其尽可能小和优化。
但是为了全面测试和调试任何 ProGuard 问题,最好像这样设置一个单独的、缩小的调试构建:
buildTypes {
debugMini {
initWith debug
minifyEnabled true
shrinkResources true
proguardFiles getDefaultProguardFile('proguard-android.txt'),
'proguard-rules.pro'
matchingFallbacks = ['debug']
}
}
使用这种构建类型,你将能够 连接调试器, 运行 UI 测试 (也在持续集成服务器上) 或 monkey 测试 你的应用,以便在尽可能接近发布版本的构建上发现可能的问题。
结论:当你使用 ProGuard 时,你应当总是通过端到端测试,或者手动浏览应用的所有页面来看是否有任何缺失或崩溃,以对你的构建版本进行彻底的 QA。
运行时注解,类型拦截
ProGuard 默认会删除代码中的所有注解甚至一些剩余的类型信息。对于一些库来说,这不是个问题 —— 那些在编译时处理注解与生成代码的库(例如 Dagger2 或 Glide 等等)可能以后程序运行时不需要这些注解。
还有另外一类实际上在运行时检查注解或查看参数与异常的类型信息的工具。例如 Retrofit 就这样做,通过使用 Proxy 对象来拦截方法调用,然后查看注解和类型信息来决定什么内容该放入 HTTP 请求或从 HTTP 请求中读取。
结论:有时需要并保留在运行时而不是编译时被取的类型信息与注解。你可以查看 ProGuard 手册中的属性列表。
-keepattributes *Annotation*, Signature, Exception
如果你使用默认的Android ProGuard 配置文件(
getDefaultProguardFile('proguard-android.txt')),那么前两个选项 —— 注解和签名 —— 是专门为你准备的。如果你没有使用默认的配置文件,那么你必须保证你自己添加它们(如果你知道你的应用需要他们,那么重复它们也没有什么坏处)。
将所有内容移至默认包
默认情况下,ProGuard 配置中不会添加 -repackageclasses 选项。如果你已经在混淆你的代码并且使用适当的 keep 规则解决了任何问题,那么你可以添加这个选项以进一步减小 DEX 的大小。它的工作原理是将所有类移至默认(根)包,从而实质上释放了被像 「com.example.myapp.somepackage」这样的字符串所占用的空间。
-repackageclasses
ProGuard 优化
正如我之前提到的,ProGuard 可以为你做三件事:
- 它摆脱了未使用的代码,
- 重命名标识符从而使代码更小,
- 对整个程序进行优化。
在我看来,每个人都应该尝试并配置他们的构建来使1. 和 2. 工作。
为了解锁 3.(额外的优化),你必须使用其他默认的 ProGuard 配置文件。在你的 build.gradle 中,将 proguard-android.txt 参数改为 proguard-android-optimize.txt:
release {
minifyEnabled true
proguardFiles
getDefaultProguardFile('proguard-android-optimize.txt'),
'proguard-rules.pro'
}
这会是你的发布构建更慢,但可能会让你的应用运行地更快和进一步缩小代码体积,这要归功于方法内联、类合并与更侵略性的代码删除等优化。但要做好准备,它可能会引入新的、更难诊断的错误,因此谨慎使用,如果有任何不起作用,务必禁用某些特定的优化或完全禁用优化配置。
就 Plaid 来说,ProGuard 优化干扰了 Retrofit 如何使用没有具体实现的代理对象,并剥离了一些实际需要的方法参数。我必须在我的配置中添加这一行:
-optimizations !method/removal/parameter
你可以在 ProGuard 中找到 可能的优化列表以及如何禁用它们。
何时使用 @Keep 和 -keep
@Keep 的支持在默认的 Android ProGuard 规则文件中实际上是通过一系列 -keep 规则实现的,因此它们基本上是等效的。指定 -keep 规则更灵活,因为它提供通配符,你也可以使用不同的变体,这些变体稍有不同(-keepnames、-keepclasseswithmembers 以及更多)。
每当需要一个简单的「保留这个类」或「保留这个方法」规则时,我实际上更喜欢在类或成员上添加 @Keep 注解的简单性,因为它离代码很近,几乎就像文档一样。
如果其他开发者想要在我之后重构代码,他们会立即知道被 @Keep 标记的类 / 成员需要特殊处理,而不必记住和参考 ProGuard 配置并且冒着破坏某些东西的风险。IDE 中大部分的代码重构也应当自动保留类的 @Keep 注解。
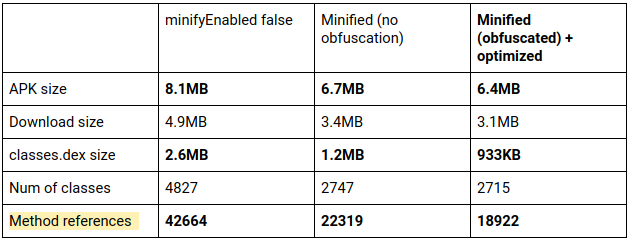
Plaid 统计信息
这有一些来自 Plaid 的统计信息,它们展示了我通过使用 ProGuard 删除了多少代码。在有更多依赖和更大 DEX 的更复杂的应用上,节省的可能更多。
如果发现译文存在错误或其他需要改进的地方,欢迎到 掘金翻译计划 对译文进行修改并 PR,也可获得相应奖励积分。文章开头的 本文永久链接 即为本文在 GitHub 上的 MarkDown 链接。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
