

- 原文地址:How I used Python to find interesting people to follow on Medium
- 原文作者:Radu Raicea
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:Park-ma
- 校对者:mingxing47

图片来源:Old Medium logo
Medium 上有大量的内容、用户和不计其数的帖子。当你试图寻找有趣的用户来关注时,你会发现自己不知所措。
我对于有趣的用户的定义是来自你的社交网络,保持活跃状态并经常在 Medium 社区发表高质量评论的用户。
我查看了我关注的用户的最新的帖子来看看是谁在回复他们。我认为如果他们回复了我关注的用户,这就说明他们可能和我志趣相投。
这个过程很繁琐,这就让我想起了我上次实习期间学到的最有价值的一课:
任何繁琐的任务都能够并且应该是自动化完成的。
我想要我的自动化程序能够做下面的事情:
- 从我的关注中获取所有的用户
- 从每一个用户中获取最新的帖子
- 获取每一个帖子的所有评论
- 筛选出30天以前的回复
- 筛选出少于最小推荐数的回复
- 获取每个回复的作者的用户名
让我们开始吧
我首先看了看 Medium's API,却发现它很有限。它给我提供的功能太少了。通过它,我只能获取关于我自己的账号信息,而不能获取其他用户的信息。
最重要的是,Medium's API 的最后一次更新是一年多前,最近也没有要开发的迹象。
我意识到我只能依靠 HTTP 请求来获取我的数据,所以我开始使用我的 Chrome 开发者工具。
第一个目标是获取我的关注列表。
我打开我的开发者工具并进入 Network 选项卡。我过滤了除了 XHR 之外的所有内容以查看 Medium 是从什么地方来获取我的关注的。我刷新了我的个人资料页面,但是什么有趣的事情都没发生。
如果我点击我的个人资料上的关注按钮怎么样?成功啦!
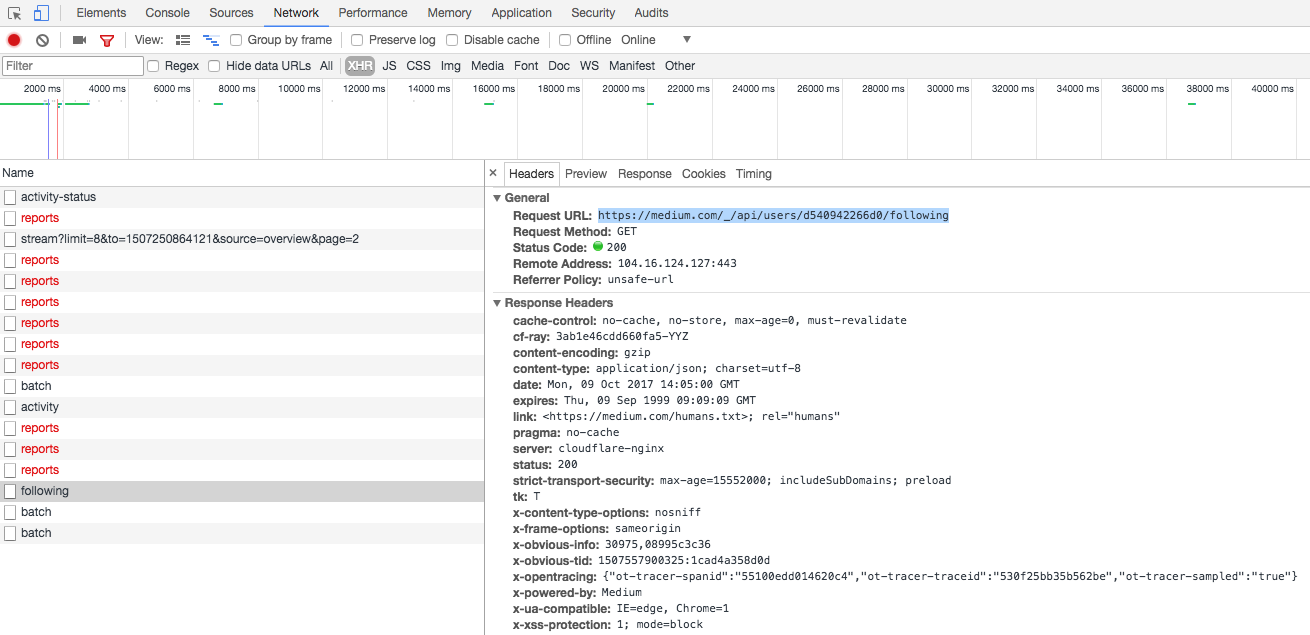
我找到用户关注列表的链接。
在这个链接中,我发现了一个非常大的 JSON 响应。它是一个格式很好的 JSON,除了在响应开头的一串字符:])}while(1);</x>
我写了一个函数整理了格式并把 JSON 转换成一个 Python 字典。
import json
def clean_json_response(response):
return json.loads(response.text.split('])}while(1);</x>')[1])
我已经找到了一个入口点,让我们开始编写代码吧。
从我的关注列表中获取所有用户
为了查询端点,我需要我的用户 ID(尽管我早就知道啦,这样做是出于教育目的)。
我在寻找获取用户 ID 的方法时发现可以通过添加 ?format=json 给 Medium 的 URL 地址来获取这个网页的 JSON 响应。我在我的个人主页上试了试。
看看,这就是我的用户 ID。
])}while(1);</x>{"success":true,"payload":{"user":{"userId":"d540942266d0","name":"Radu Raicea","username":"Radu_Raicea",
...
我写了一函数从给出的用户名中提取用户 ID 。同样,我使用了 clean_json_response 函数来去除响应开头的不想要的字符串。
我还定义了一个叫 MEDIUM 的常量,它用来存储所有 Medium 的 URL 地址都包含的字符串。
import requests
MEDIUM = 'https://medium.com'
def get_user_id(username):
print('Retrieving user ID...')
url = MEDIUM + '/@' + username + '?format=json'
response = requests.get(url)
response_dict = clean_json_response(response)
return response_dict['payload']['user']['userId']
通过用户 ID ,我查询了 /_/api/users/<user_id>/following 端点,从我的关注列表里获取了用户名列表。
当我在开发者工具中做这时,我注意到 JSON 响应只有八个用户名。很奇怪!
当我点击 “Show more people”,我找到了缺少的用户名。原来 Medium 使用分页的方式来展示关注列表。
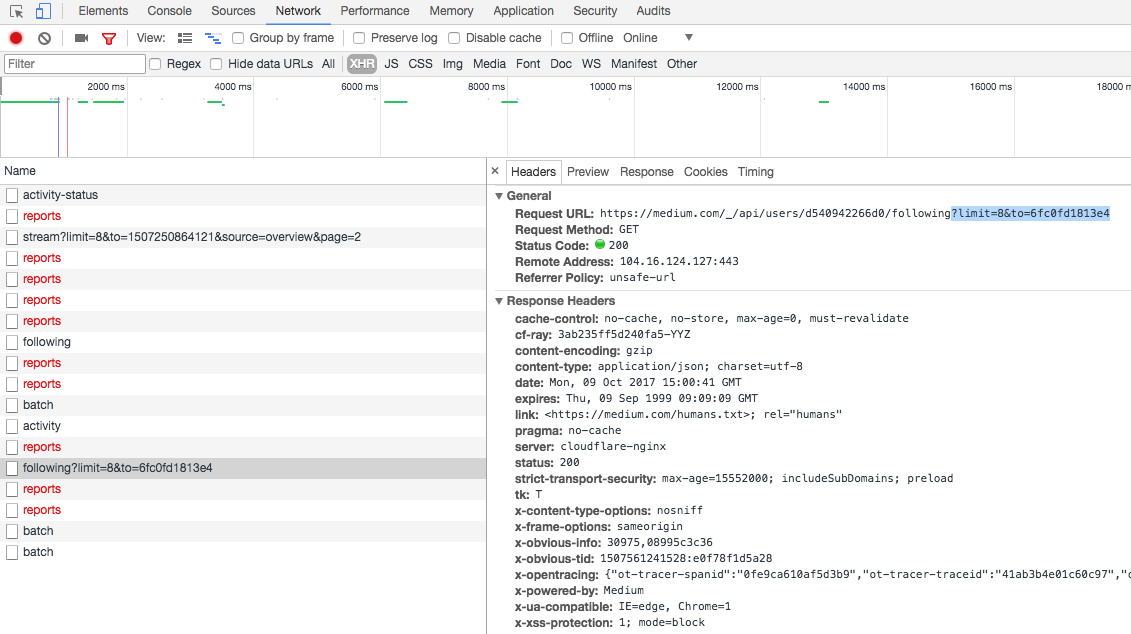
Medium 使用分页的方式来展示关注列表。
分页通过指定 limit(每页元素)和 to(下一页的第一个元素)来工作,我必须找到一种方式来获取下一页的 ID。
在从 /_/api/users/<user_id>/following 获取的 JSON 响应的尾部,我看到了一个有趣的 JSON 键值对。
...
"paging":{"path":"/_/api/users/d540942266d0/followers","next":{"limit":8,"to":"49260b62a26c"}}},"v":3,"b":"31039-15ed0e5"}
到了这一步,很容易就能写出一个循环从我的关注列表里面获取所有的用户名。
def get_list_of_followings(user_id):
print('Retrieving users from Followings...')
next_id = False
followings = []
while True:
if next_id:
# 如果这不是关注列表的第一页
url = MEDIUM + '/_/api/users/' + user_id
+ '/following?limit=8&to=' + next_id
else:
# 如果这是关注列表的第一页
url = MEDIUM + '/_/api/users/' + user_id + '/following'
response = requests.get(url)
response_dict = clean_json_response(response)
payload = response_dict['payload']
for user in payload['value']:
followings.append(user['username'])
try:
# 如果找不到 "to" 键,我们就到达了列表末尾,
# 并且异常将会抛出。
next_id = payload['paging']['next']['to']
except:
break
return followings
获取每个用户最新的帖子
我得到了我关注的用户列表之后,我就想获取他们最新的帖子。我可以通过发送这个请求 [https://medium.com/@<username>/latest?format=json](https://medium.com/@username/latest?format=json) 来实现这个功能。
于是我写了一个函数,这个函数的参数是用户名列表,然后返回一个包含输入进来的所有用户最新发表的帖子 ID 的 Python 列表。
def get_list_of_latest_posts_ids(usernames):
print('Retrieving the latest posts...')
post_ids = []
for username in usernames:
url = MEDIUM + '/@' + username + '/latest?format=json'
response = requests.get(url)
response_dict = clean_json_response(response)
try:
posts = response_dict['payload']['references']['Post']
except:
posts = []
if posts:
for key in posts.keys():
post_ids.append(posts[key]['id'])
return post_ids
获取每个帖子的所有评论
有了帖子的列表,我通过 https://medium.com/_/api/posts/<post_id>/responses 提取了所有的评论。
这个函数参数是帖子 ID Python 列表然后返回评论的Python列表。
def get_post_responses(posts):
print('Retrieving the post responses...')
responses = []
for post in posts:
url = MEDIUM + '/_/api/posts/' + post + '/responses'
response = requests.get(url)
response_dict = clean_json_response(response)
responses += response_dict['payload']['value']
return responses
筛选这些评论
一开始,我希望评论达到点赞的最小值。但是我意识到这可能并不能很好的表达出社区对于评论的赞赏程度,因为一个用户可以对同一条评论进行多次点赞。
相反,我使用推荐数来进行筛选。推荐数和点赞数差不多,但它不能多次推荐。
我希望这个最小值是可以动态调整的。所以我传递了名为 recommend_min 的变量。
下面的函数的参数是每一条评论和 recommend_min 变量。它用来检查评论的推荐数是否到达最小值。
def check_if_high_recommends(response, recommend_min):
if response['virtuals']['recommends'] >= recommend_min:
return True
我还希望得到最近的评论。因此我通过这个函数过滤掉超过 30 天的评论。
from datetime import datetime, timedelta
def check_if_recent(response):
limit_date = datetime.now() - timedelta(days=30)
creation_epoch_time = response['createdAt'] / 1000
creation_date = datetime.fromtimestamp(creation_epoch_time)
if creation_date >= limit_date:
return True
获取评论作者的用户名
在完成评论的筛选工作之后,我使用下面的函数来抓取所有作者的用户 ID。
def get_user_ids_from_responses(responses, recommend_min):
print('Retrieving user IDs from the responses...')
user_ids = []
for response in responses:
recent = check_if_recent(response)
high = check_if_high_recommends(response, recommend_min)
if recent and high:
user_ids.append(response['creatorId'])
return user_ids
当你试图访问某个用户的个人资料时,你会发现用户 ID 是没用的。这时我写了一个函数通过查询 /_/api/users/<user_id> 端点来获取用户名。
def get_usernames(user_ids):
print('Retrieving usernames of interesting users...')
usernames = []
for user_id in user_ids:
url = MEDIUM + '/_/api/users/' + user_id
response = requests.get(url)
response_dict = clean_json_response(response)
payload = response_dict['payload']
usernames.append(payload['value']['username'])
return usernames
把所以函数组合起来
在完成所有函数之后,我创建了一个管道来获取我的推荐用户列表。
def get_interesting_users(username, recommend_min):
print('Looking for interesting users for %s...' % username)
user_id = get_user_id(username)
usernames = get_list_of_followings(user_id)
posts = get_list_of_latest_posts_ids(usernames)
responses = get_post_responses(posts)
users = get_user_ids_from_responses(responses, recommend_min)
return get_usernames(users)
这个脚本程序终于完成啦!为了测试这个程序,你必须调用这个管道。
interesting_users = get_interesting_users('Radu_Raicea', 10)
print(interesting_users)

图片来源: Know Your Meme
最后,我添加了一个选项,可以把结果和时间戳存储在一个 CSV 文件里面。
import csv
def list_to_csv(interesting_users_list):
with open('recommended_users.csv', 'a') as file:
writer = csv.writer(file)
now = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
interesting_users_list.insert(0, now)
writer.writerow(interesting_users_list)
interesting_users = get_interesting_users('Radu_Raicea', 10)
list_to_csv(interesting_users)
关于这个项目的源文件可以在这里找到。
如果你还不会 Python,阅读 TK 的 Python 教程:Learning Python: From Zero to Hero。
如果你对其他让用户感兴趣的标准有建议,请在下面留言!
总结···
- 我编写一个适用于 Medium 的 Python 脚本。
- 这个脚本返回一个用户列表,里面的用户都是活跃的且在你的关注的用户的最新帖子下面发表过有趣的评论。
- 你可以从列表里取出用户,用他的用户名而不是你的来运行这个脚本。
点击我的关于开源许可的初级教程以及如何把它们添加到你的项目中!
更多更新,请关注我的 Twitter。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
