

前言
在基于 HTTP 协议的网络传输中 GZip 经常被使用,Nginx 中也可以使用半行代码开启 GZip。GZip 压缩的原理是什么呢?本篇文章是我在网上阅读了一些文档后做的简单总结。
从 RFC 1952 看起
RFC 1952 是 GZIP file format specification version 4.3。该规范主要定义了 GZip 压缩的在数据格式方面的规范,以方便不同的操作系统、CPU、文件系统等之间进行文件传输交换。下面挑有意思的几个点说,感兴趣的可以阅读 RFC 1952 的原文。
GZIP 的文件格式在设计上其实是可以允许一个文件里有多个压缩数据集(compressed data sets)—— GZIP 压缩后的片段拼接而成的。但就我们大多数应用场景来说,基本上都是一个文件一个压缩数据集,如果是多个文件一起打包的话,也往往是将多个包合并成一个 tar 文件。
每个压缩数据集都是下面的结构:
| ID1 | ID2 | CM | FLG | MTIME(4字节) | XFL | OS | ---> more
|与|之间是 1 byte,都是大端字节(Big Edian)
-
其中 ID1 和 ID2 分别是 0x1f 和 0x8b,用来标识文件格式是 gzip
-
CM 标识 加密算法,目前 0-7是保留字,8 指的是 deflate 算法
-
FLG 从低地址到高地址分别是 FTEXT、FHCRC、FEXTRA、FNAME、FCOMMENT、reserved、 reserved、reserved,这里每个 bit 被设置了之后有什么意义感兴趣的话可以详细参考 RFC 1952。比较有意思的是 FEXTRA,如果它被设置了表示存在额外的拓展字段。拓展字段的结构如下:
- | SI1 | SI2 | LEN | ... LEN bytes of subfield data ... |
- SI1、SI2 是对子域的 ID,由 ASCII 码组成。如果你需要使用的话,可以向他的维护者 Jean-Loup Gailly
<gzip@prep.ai.mit.edu>发邮件申请。目前 Apollo file 就有自己的专属 ID
-
MTIME 指的是源文件最近一次修改时间,存的是 Unix 时间戳
-
XFL 是给压缩算法传的一些参数,用来标识如何解压。defalte 算法中 2 表示使用压缩率最高的算法,4 表示使用压缩速度最快的算法
-
OS 标识压缩程序运行的文件系统,以处理 EOF 等的问题
-
more 后面是根据 FLG 的开启情况决定的,可能会有 循环冗余校验码、源文件长度、附加信息等多种其他信息
压缩核心之 Deflate
GZIP 的核心是 Deflate,在 RFC 1951 中被标准化,并且在当时作为 LZW 的替代品有了非常广泛的使用。
Deflate 是一个同时使用 LZ77 与 Huffman Coding 的算法,这里简单介绍下这两种算法的大致思路:
LZ77
LZ77 的核心思路是如果一个串中有两个重复的串,那么只需要知道第一个串的内容和后面串相对于第一个串起始位置的距离 + 串的长度。
比如: ABCDEFGABCDEFH → ABCDEFG(7,6)H。7 指的是往前第 7 个数开始,6 指的是重复串的长度,ABCDEFG(7,6)H 完全可以表示前面的串,并且是没有二义性的。
LZ77 用 滑动窗口(sliding-window compression)来实现这个算法。具体思路是扫描头从串的头部开始扫描串,在扫描头的前面有一个长度为 N 的滑动窗口。如果发现扫描头处的串和窗口里的 最长匹配串 是相同的,则用(两个串之间的距离,串的长度)来代替后一个重复的串,同时还需要添加一个表示是真实串还是替换后的“串”的字节在前面以方便解压(此串需要在 真实串和替换“串” 之前都有存在)。
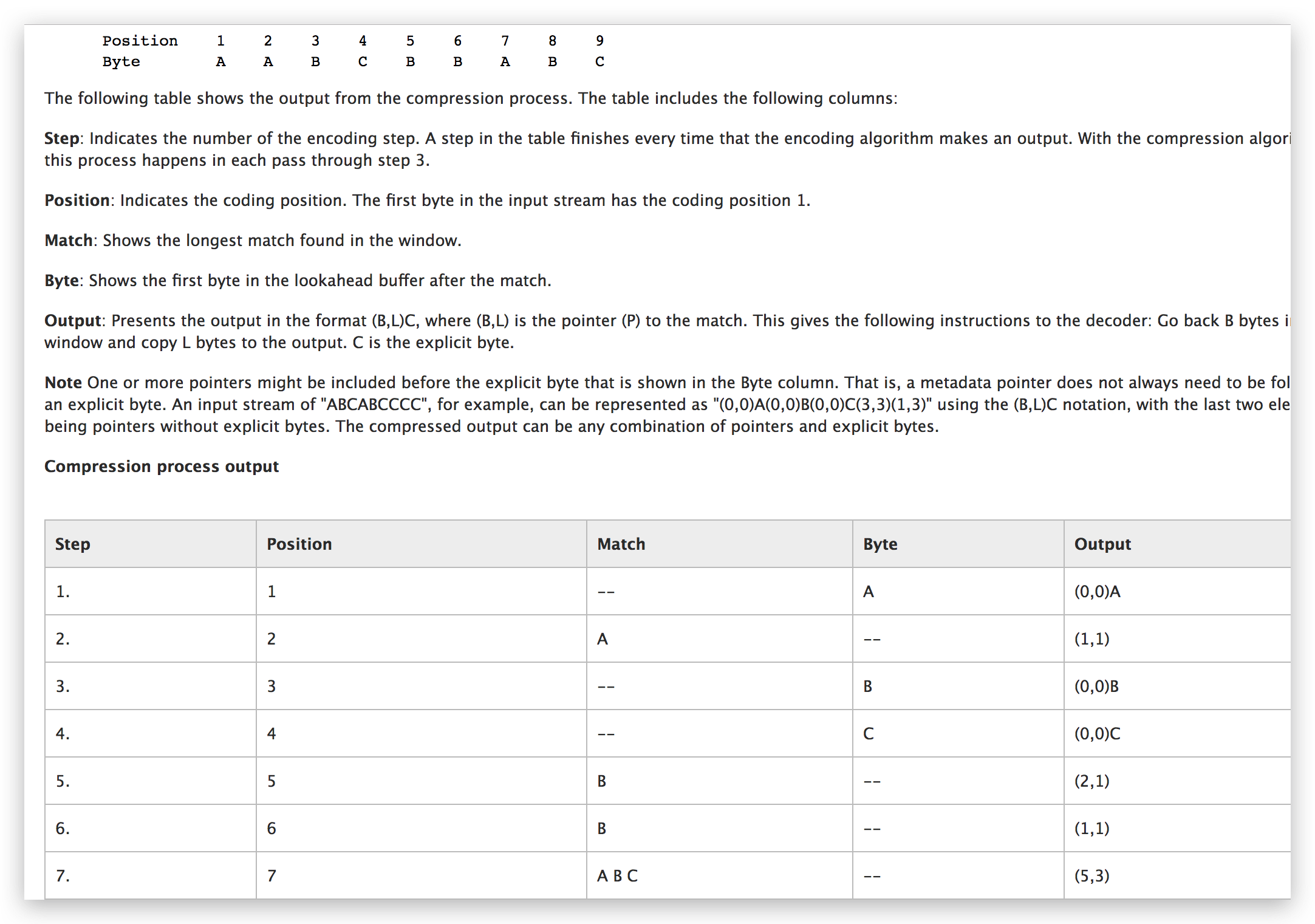
实际过程中滑动窗口的大小是固定的,匹配的串也有最小长度限制,以方便 标识+两个串之间的距离+串的长度 所占用的字节是固定的 以及 不要约压缩体积越大。更加详细的实现可以参考:Standford Edu. lz77 algorithm、 LZ77 Compression Algorithm、 LZ77压缩算法编码原理详解(结合图片和简单代码)
这里通过这个压缩机制也就能比较容易的解释为啥 CSS BEM 写法 GZIP 压缩之后可以忽略长度以及 JPEG 图片 GZIP 之后可能会变大 的情况了
解压:GZIP 的压缩因为要在窗口里寻找重复串相对来说效率是比较低的(LZ77 还是通过 Hash 等系列方法提高了很多),那解压又是怎么个情况呢?观察压缩后的整个串,每个小串前都有一个标识要标记是原始串还是替换“串”,通过这个标识就能以 O(1)的复杂度直接读完并且替换完替换“串”,整体上效率是非常可观的。
Huffman Coding
Huffman Coding 是大学课本中一般都会提到的算法。核心思路是通过构造 Huffman Tree 的方式给字符重新编码(核心是避免一个叶子的路径是另外一个叶子路径的前缀),以保证出现频路越高的字符占用的字节越少。关于 Huffman Tree 的构造这里不再细说,不太清楚的可以参考:Huffman Coding。
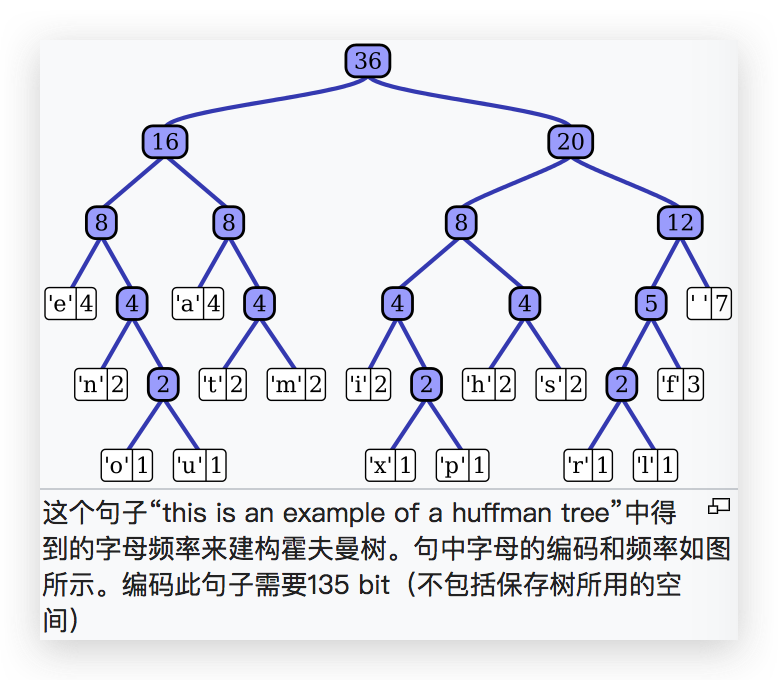
解压:Huffman Coding 之后需要维护一张 Huffman Map 表,来记录重新编码后的字符串,根据这张表,还原原始串也是非常高效的。
Deflate 综合使用了 LZ77 和 Huffman Coding 来压缩文件,相对而言又提升了很多。详细可以参考 gzip原理与实现
网站中的使用
在 RFC 2016 中 GZIP 已经成为了规定的三种标准HTTP压缩格式之一。目前绝大多数的网站都在使用 GZIP 传输 HTML、CSS、JavaScript 等资源文件。
Nginx 开启
Nginx 的 ngx_http_gzip_module 也提供了开启 GZIP 压缩的方式,有下面的一些常用配置:
# 开启
gzip on;
# 压缩等级,1-9。设置多少可以参考:http://serverfault.com/questions/253074/what-is-the-best-nginx-compression-gzip-level
gzip_comp_level 2;
# "MSIE [1-6]\." 比如禁止 IE6 使用 GZIP
gzip_disable regex ...
# 最小压缩文件长度
gzip_min_length 20;
# 使用 GZIP 压缩的最小 HTTP 版本
gzip_http_version 1.1;
# 压缩的文件类型,值是 [MIME type](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Complete_list_of_MIME_types)
gzip_types text/html;
相关探测
Nginx 上开启 GZIP 之后,理论上会按照 GZIP 配置打开压缩。那如何检测是否开启成功了呢?
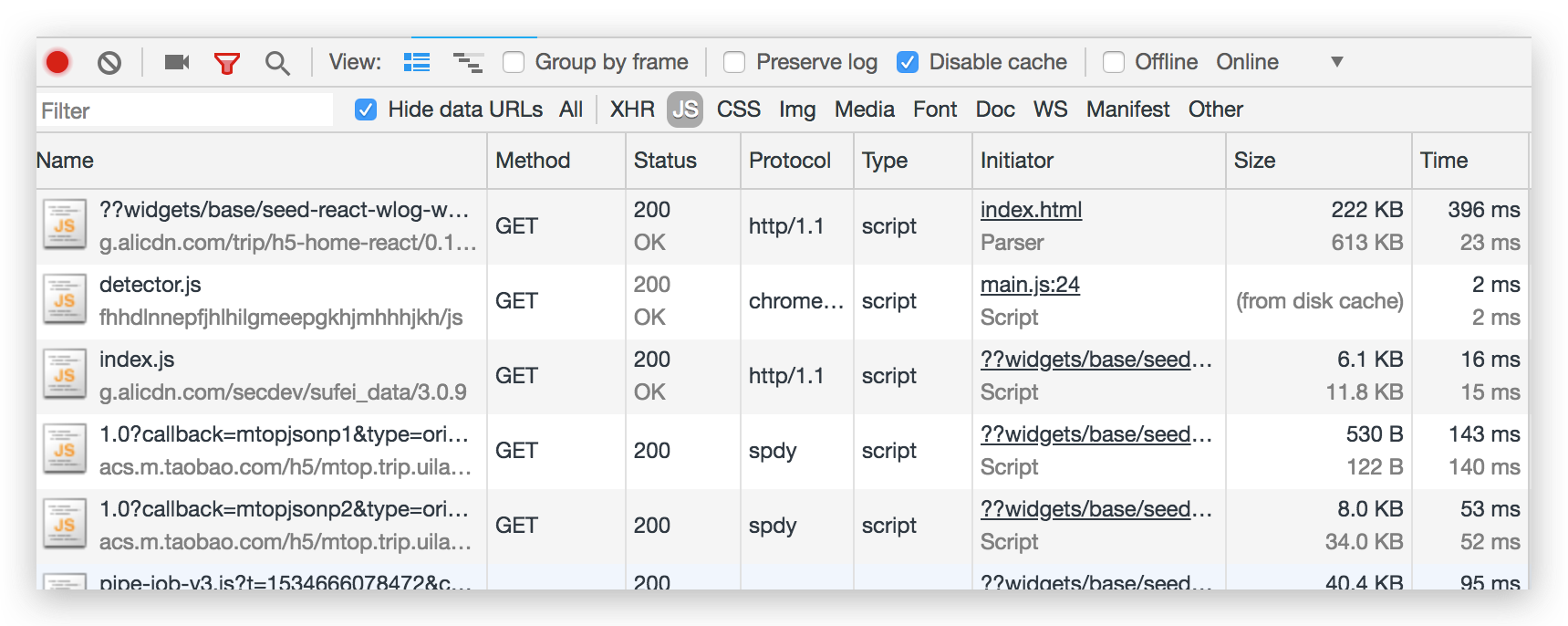
打开浏览器,访问你的网站,看 Chrome 的 Network,如果 Size 上有两个不一样大小的体积(如:222KB 和 613KB),则代表 GZIP 已经成功开启。
那浏览器又是如何和服务器配合的呢?
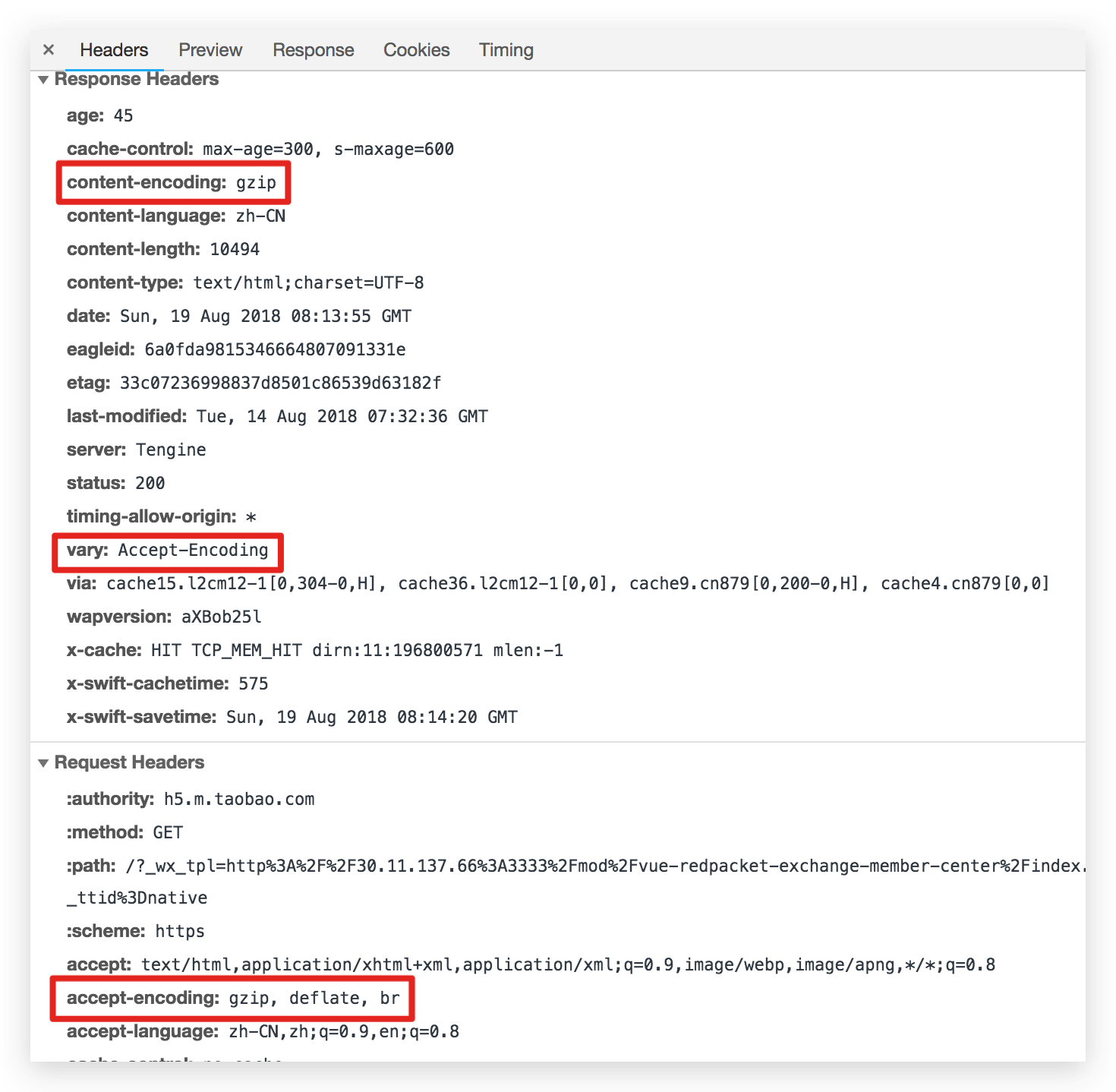
浏览器在请求资源的时候再 header 里面带上 accept-encoding: gzip 的参数。Nginx 在接收到 Header 之后,发现如果有这个配置,则发送 GZIP 之后的文件(返回的 header 里也包含相关的说明),如果没有则发送源文件。浏览器根据 response header 来处理要不要针对返回的文件进行解压缩然后展示。
参考文档
- RFC 1952 - GZIP file format specification version 4.3
- RFC 1951 - DEFLATE Compressed Data Format Specification version 1.3
- DEFLATE - 维基百科,自由的百科全书
- LZW - 维基百科,自由的百科全书
- LZ77 - 维基百科,自由的百科全书
- Standford Edu. lz77 algorithm
- LZ77 Compression Algorithm
- LZ77压缩算法编码原理详解(结合图片和简单代码)
- 霍夫曼编码 - 维基百科,自由的百科全书
- gzip原理与实现
- Module ngx_http_gzip_module
- What is the best nginx compression gzip level?
- MDN - 完整的MIME类型列表
- 你真的了解 gzip 吗?
