

前言
本篇文章将带来YYCache的解读,YYCache支持内存和本地两种方式的数据存储。我们先抛出两个问题:
- YYCache是如何把数据写入内存之中的?又是如何实现的高效读取?
- YYCache采用了何种方式把数据写入磁盘?
先来看看YYCache整体框架设计图
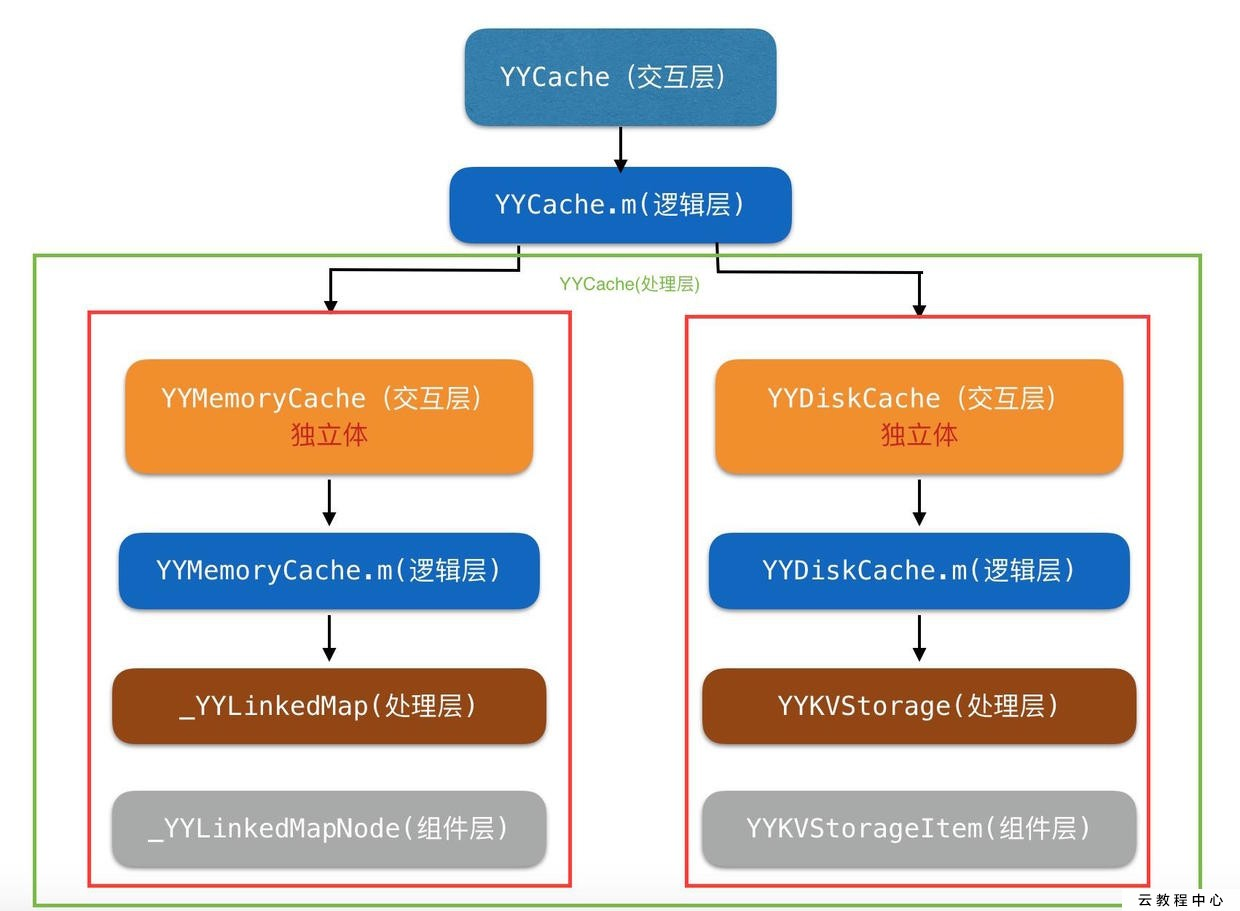
**分析下这个框架 **
从上图可以很清晰的看出这个框架的基础框架为:
交互层-逻辑层-处理层。
无论是最上层的YYCache或下面两个独立体YYMemoryCache和YYDiskCache都是这样设计的。逻辑清晰。 来看看YYMemoryCache,逻辑层是负责对交付层的一个转接和对处理层发布一些命令,比如增删改查。而处理层则是对逻辑层发布的命令进行具体对应的处理。组件层则是对处理层的一种补充,也是元数据,扩展性很好。这两个类我们都是可以单独拿出来使用的。而多添加一层YYCache,则可以让我们使用的更加方便,自动为我们同时进行内存缓存和磁盘缓存,读取的时候获得内存缓存的高速读取。
YYMemoryCache
我们使用YYMemoryCache可以把数据缓存进内存之中,它内部会创建了一个YYMemoryCache对象,然后把数据保存进这个对象之中。
但凡涉及到类似这样的操作,代码都需要设计成线程安全的。所谓的线程安全就是指充分考虑多线程条件下的增删改查操作。
要想高效的查询数据,使用字典是一个很好的方法。字典的原理跟哈希有关,总之就是把key直接映射成内存地址,然后处理冲突和和扩容的问题。对这方面有兴趣的可以自行搜索资料
YYMemoryCache内部封装了一个对象_YYLinkedMap,包含了下边这些属性:
@interface _YYLinkedMap : NSObject {
@package
CFMutableDictionaryRef _dic; //哈希字典,存放缓存数据
NSUInteger _totalCost; //缓存总大小
NSUInteger _totalCount; //缓存节点总个数
_YYLinkedMapNode *_head; //头结点
_YYLinkedMapNode *_tail; //尾结点
BOOL _releaseOnMainThread; //在主线程释放
BOOL _releaseAsynchronously;//在异步线程释放
}
@end
_dic是哈希字典,负责存放缓存数据,_head和_tail分别是双链表中指向头节点和尾节点的指针,链表中的节点单元是_YYLinkedMapNode对象,该对象封装了缓存数据的信息。
可以看出来,CFMutableDictionaryRef _dic将被用来保存数据。这里使用了CoreFoundation的字典,性能更好。字典里边保存着的是_YYLinkedMapNode对象。
@interface _YYLinkedMapNode : NSObject {
@package
__unsafe_unretained _YYLinkedMapNode *_prev; //前向前一个节点的指针
__unsafe_unretained _YYLinkedMapNode *_next; //指向下一个节点的指针
id _key; //缓存数据key
id _value; //缓存数据value
NSUInteger _cost; //节点占用大小
NSTimeInterval _time; //节点操作时间戳
}
@end
上边的代码,就能知道使用了链表的知识。但是有一个疑问,单用字典我们就能很快的查询出数据,为什么还要实现链表这一数据结构呢?
答案就是淘汰算法,YYMemoryCache使用了LRU淘汰算法,也就是当数据超过某个限制条件后,我们会从链表的尾部开始删除数据,直到达到要求为止。
LRU
LRU全称是Least recently used,基于最近最少使用的原则,属于一种缓存淘汰算法。实现思路是维护一个双向链表数据结构,每次有新数据要缓存时,将缓存数据包装成一个节点,插入双向链表的头部,如果访问链表中的缓存数据,同样将该数据对应的节点移动至链表的头部。这样的做法保证了被使用的数据(存储/访问)始终位于链表的前部。当缓存的数据总量超出容量时,先删除末尾的缓存数据节点,因为末尾的数据最少被使用过。如下图:
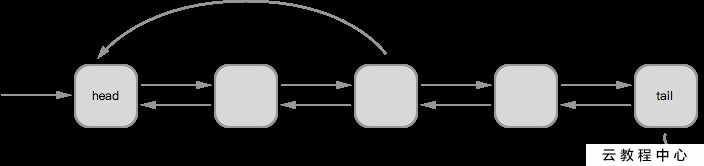
如果有一列数据已经按顺序排好了,我使用了中间的某个数据,那么就要把这个数据插入到最开始的位置,这就是一条规则,越是最近使用的越靠前。
在设计上,YYMemoryCache还提供了是否异步释放数据这一选项,在这里就不提了,我们在来看看在YYMemoryCache中用到的锁的知识。
pthread_mutex_lock是一种互斥所:
pthread_mutex_init(&_lock, NULL); // 初始化
pthread_mutex_lock(&_lock); // 加锁
pthread_mutex_unlock(&_lock); // 解锁
pthread_mutex_trylock(&_lock) == 0 // 是否加锁,0:未锁住,其他值:锁住
在OC中有很多种锁可以用,pthread_mutex_lock就是其中的一种。YYMemoryCache有这样一种设置,每隔一个固定的时间就要处理数据,及边界检测,代码如下:
边界检测
- (void)_trimRecursively {
__weak typeof(self) _self = self;
dispatch_after(dispatch_time(DISPATCH_TIME_NOW, (int64_t)(_autoTrimInterval * NSEC_PER_SEC)), dispatch_get_global_queue(DISPATCH_QUEUE_PRIORITY_LOW, 0), ^{
__strong typeof(_self) self = _self;
if (!self) return;
[self _trimInBackground];//在异步队列中执行边界检测
[self _trimRecursively];//递归调用本方法
});
}
上边的代码中,每隔_autoTrimInterval时间就会在后台尝试处理数据,然后再次调用自身,这样就实现了一个类似定时器的功能。这一个小技巧可以学习一下。
- (void)_trimInBackground {
dispatch_async(_queue, ^{
[self _trimToCost:self->_costLimit];
[self _trimToCount:self->_countLimit];
[self _trimToAge:self->_ageLimit];
});
}
_trimInBackground分别调用_trimToCost、_trimToCount和_trimToAge方法检测。
_trimToCost方法判断链表中所有节点占用大小之和totalCost是否大于costLimit,如果超过,则从链表末尾开始删除节点,直到totalCost小于等于costLimit为止。代码注释如下:
- (void)_trimToCost:(NSUInteger)costLimit {
BOOL finish = NO;
pthread_mutex_lock(&_lock);
if (costLimit == 0) {
[_lru removeAll];
finish = YES;
} else if (_lru->_totalCost <= costLimit) {
finish = YES;
}
pthread_mutex_unlock(&_lock);
if (finish) return;
NSMutableArray *holder = [NSMutableArray new];
while (!finish) {
if (pthread_mutex_trylock(&_lock) == 0) {
if (_lru->_totalCost > costLimit) {
_YYLinkedMapNode *node = [_lru removeTailNode];//删除末尾节点
if (node) [holder addObject:node];
} else {
finish = YES; //totalCost<=costLimit,检测完成
}
pthread_mutex_unlock(&_lock);
} else {
usleep(10 * 1000); //10 ms
}
}
if (holder.count) {
dispatch_queue_t queue = _lru->_releaseOnMainThread ? dispatch_get_main_queue() : YYMemoryCacheGetReleaseQueue();
dispatch_async(queue, ^{
[holder count]; // release in queue 释放了资源
});
}
}
其中每个节点的cost是人为指定的,默认是0,且costLimit默认是NSUIntegerMax,所以在默认情况下,_trimToCost方法不会删除末尾的节点。
_trimToCount方法判断链表中的所有节点个数之和是否大于countLimit,如果超过,则从链表末尾开始删除节点,直到个数之和小于等于countLimit为止。代码注释如下:
- (void)_trimToCount:(NSUInteger)countLimit {
BOOL finish = NO;
...
NSMutableArray *holder = [NSMutableArray new];
while (!finish) {
if (pthread_mutex_trylock(&;_lock) == 0) {
if (_lru->_totalCount > countLimit) {
_YYLinkedMapNode *node = [_lru removeTailNode]; //删除末尾节点
if (node) [holder addObject:node];
} else {
finish = YES; //totalCount<=countLimit,检测完成
}
pthread_mutex_unlock(&;_lock);
} else {
usleep(10 * 1000); //10 ms等待一小段时间
}
}
...
}
初始化时countLimit默认是NSUIntegerMax,如果不指定countLimit,节点的总个数永远不会超过这个限制,所以_trimToCount方法不会删除末尾节点。
_trimToAge方法遍历链表中的节点,删除那些和now时刻的时间间隔大于ageLimit的节点,代码如下:
- (void)_trimToAge:(NSTimeInterval)ageLimit {
BOOL finish = NO;
...
NSMutableArray *holder = [NSMutableArray new];
while (!finish) {
if (pthread_mutex_trylock(&;_lock) == 0) {
if (_lru->_tail &;&; (now - _lru->_tail->_time) > ageLimit) { //间隔大于ageLimit
_YYLinkedMapNode *node = [_lru removeTailNode]; //删除末尾节点
if (node) [holder addObject:node];
} else {
finish = YES;
}
pthread_mutex_unlock(&;_lock);
} else {
usleep(10 * 1000); //10 ms
}
}
...
}
由于链表中从头部至尾部的节点,访问时间由晚至早,所以尾部节点和now时刻的时间间隔较大,从尾节点开始删除。ageLimit的默认值是DBL_MAX,如果不人为指定ageLimit,则链表中节点不会被删除。
当某个变量在出了自己的作用域之后,正常情况下就会被自动释放。
存储数据
调用setObject: forKey:方法存储缓存数据,代码如下:
- (void)setObject:(id)object forKey:(id)key withCost:(NSUInteger)cost {
if (!key) return;
if (!object) {
[self removeObjectForKey:key];
return;
}
pthread_mutex_lock(&;_lock); //上锁
_YYLinkedMapNode *node = CFDictionaryGetValue(_lru->_dic, (__bridge const void *)(key)); //从字典中取节点
NSTimeInterval now = CACurrentMediaTime();
if (node) { //如果能取到,说明链表中之前存在key对应的缓存数据
//更新totalCost
_lru->_totalCost -= node->_cost;
_lru->_totalCost += cost;
node->_cost = cost;
node->_time = now; //更新节点的访问时间
node->_value = object; //更新节点中存放的缓存数据
[_lru bringNodeToHead:node]; //将节点移至链表头部
} else { //如果不能取到,说明链表中之前不存在key对应的缓存数据
node = [_YYLinkedMapNode new]; //创建新的节点
node->_cost = cost;
node->_time = now; //设置节点的时间
node->_key = key; //设置节点的key
node->_value = object; //设置节点中存放的缓存数据
[_lru insertNodeAtHead:node]; //将新的节点加入链表头部
}
if (_lru->_totalCost > _costLimit) {
dispatch_async(_queue, ^{
[self trimToCost:_costLimit];
});
}
if (_lru->_totalCount > _countLimit) {
_YYLinkedMapNode *node = [_lru removeTailNode];
...
}
pthread_mutex_unlock(&;_lock); //解锁
}
首先判断key和object是否为空,object如果为空,删除缓存中key对应的数据。然后从字典中查找key对应的缓存数据,分为两种情况,如果访问到节点,说明缓存数据存在,则根据最近最少使用原则,将本次操作的节点移动至链表的头部,同时更新节点的访问时间。如果访问不到节点,说明是第一次添加key和数据,需要创建一个新的节点,把节点存入字典中,并且加入链表头部。cost是指定的,默认是0。
访问数据
调用objectForKey:方法访问缓存数据,代码注释如下:
- (id)objectForKey:(id)key {
if (!key) return nil;
pthread_mutex_lock(&;_lock);
_YYLinkedMapNode *node = CFDictionaryGetValue(_lru->_dic, (__bridge const void *)(key)); //从字典中读取key相应的节点
if (node) {
node->_time = CACurrentMediaTime(); //更新节点访问时间
[_lru bringNodeToHead:node]; //将节点移动至链表头部
}
pthread_mutex_unlock(&;_lock);
return node ? node->_value : nil;
}
该方法从字典中获取缓存数据,如果key对应的数据存在,则更新访问时间,根据最近最少使用原则,将本次操作的节点移动至链表的头部。如果不存在,则直接返回nil。
线程同步
- (void)setObject:(id)object forKey:(id)key withCost:(NSUInteger)cost {
pthread_mutex_lock(&;_lock);
//操作链表,写缓存数据
pthread_mutex_unlock(&;_lock);
}
- (id)objectForKey:(id)key {
pthread_mutex_lock(&;_lock);
//访问缓存数据
pthread_mutex_unlock(&;_lock);
}
如果存在线程A和B,线程A在写缓存的时候,上锁,线程B读取缓存数据时,被阻塞,需要等到线程A执行完写缓存的操作,调用pthread_mutex_unlock后,线程B才能读缓存数据,这个时候新的缓存数据已经写完,保证了操作的数据的同步。
总结
YYMemoryCache操作了内存缓存,相较于硬盘缓存需要进行I/O操作,在性能上快很多,因此YYCache访问缓存时,优先用的是YYMemoryCache。
YYMemoryCache实际上就是创建了一个对象实例,该对象内部使用字典和双向链表实现
YYDiskCache
YYDiskCache通过文件和SQLite数据库两种方式存储缓存数据.YYKVStorage核心功能类,实现了文件读写和数据库读写的功能。YYKVStorageYYKVStorage定义了读写缓存数据的三种枚举类型,即typedefNS_ENUM(NSUInteger,YYKVStorageType)
YYKVStorage
YYKVStorage最核心的思想是KV这两个字母,表示key-value的意思,目的是让使用者像使用字典一样操作数据
YYKVStorage让我们只关心3件事:
- 数据保存的路径
- 保存数据,并为该数据关联一个key
- 根据key取出数据或删除数据
同理,YYKVStorage在设计接口的时候,也从这3个方面进行了考虑。这数据功能设计层面的思想。
YYKVStorage定义了读写缓存数据的三种枚举类型,即
typedef NS_ENUM(NSUInteger, YYKVStorageType) {
//文件读取
YYKVStorageTypeFile = 0,
//数据库读写
YYKVStorageTypeSQLite = 1,
//根据策略决定使用文件还是数据库读写数据
YYKVStorageTypeMixed = 2,
};
初始化
调用initWithPath: type:方法进行初始化,指定了存储方式,创建了缓存文件夹和SQLite数据库用于存放缓存,打开并初始化数据库。下面是部分代码注释:
- (instancetype)initWithPath:(NSString *)path type:(YYKVStorageType)type {
...
self = [super init];
_path = path.copy;
_type = type; //指定存储方式,是数据库还是文件存储
_dataPath = [path stringByAppendingPathComponent:kDataDirectoryName]; //缓存数据的文件路径
_trashPath = [path stringByAppendingPathComponent:kTrashDirectoryName]; //存放垃圾缓存数据的文件路径
_trashQueue = dispatch_queue_create("com.ibireme.cache.disk.trash", DISPATCH_QUEUE_SERIAL);
_dbPath = [path stringByAppendingPathComponent:kDBFileName]; //数据库路径
_errorLogsEnabled = YES;
NSError *error = nil;
//创建缓存数据的文件夹和垃圾缓存数据的文件夹
if (![[NSFileManager defaultManager] createDirectoryAtPath:path
withIntermediateDirectories:YES
attributes:nil
error:&;error] ||
![[NSFileManager defaultManager] createDirectoryAtPath:[path stringByAppendingPathComponent:kDataDirectoryName]
withIntermediateDirectories:YES
attributes:nil
error:&;error] ||
![[NSFileManager defaultManager] createDirectoryAtPath:[path stringByAppendingPathComponent:kTrashDirectoryName]
withIntermediateDirectories:YES
attributes:nil
error:&;error]) {
NSLog(@"YYKVStorage init error:%@", error);
return nil;
}
//创建并打开数据库、在数据库中建表
//_dbOpen方法创建和打开数据库manifest.sqlite
//调用_dbInitialize方法创建数据库中的表
if (![self _dbOpen] || ![self _dbInitialize]) {
// db file may broken...
[self _dbClose];
[self _reset]; // rebuild
if (![self _dbOpen] || ![self _dbInitialize]) {
[self _dbClose];
NSLog(@"YYKVStorage init error: fail to open sqlite db.");
return nil;
}
}
//调用_fileEmptyTrashInBackground方法将trash目录中的缓存数据删除
[self _fileEmptyTrashInBackground]; // empty the trash if failed at last time
return self;
}
_dbInitialize方法调用sql语句在数据库中创建一张表,代码如下:
- (BOOL)_dbInitialize {
NSString *sql = @"pragma journal_mode = wal; pragma synchronous = normal; create table if not exists manifest (key text, filename text, size integer, inline_data blob, modification_time integer, last_access_time integer, extended_data blob, primary key(key)); create index if not exists last_access_time_idx on manifest(last_access_time);";
return [self _dbExecute:sql];
}
"pragma journal_mode = wal"表示使用WAL模式进行数据库操作,如果不指定,默认DELETE模式,是"journal_mode=DELETE"。使用WAL模式时,改写操作数据库的操作会先写入WAL文件,而暂时不改动数据库文件,当执行checkPoint方法时,WAL文件的内容被批量写入数据库。checkPoint操作会自动执行,也可以改为手动。WAL模式的优点是支持读写并发,性能更高,但是当wal文件很大时,需要调用checkPoint方法清空wal文件中的内容
dataPath和trashPath用于文件的方式读写缓存数据,当dataPath中的部分缓存数据需要被清除时,先将其移至trashPath中,然后统一清空trashPath中的数据,类似回收站的思路。_dbPath是数据库文件,需要创建并初始化,下面是路径:
在真实的编程中,往往需要把数据封装成一个对象:
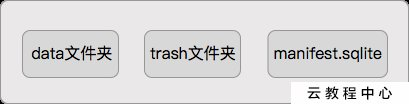
调用_dbOpen方法创建和打开数据库manifest.sqlite,调用_dbInitialize方法创建数据库中的表。调用_fileEmptyTrashInBackground方法将trash目录中的缓存数据删除
/**
YYKVStorageItem is used by `YYKVStorage` to store key-value pair and meta data.
Typically, you should not use this class directly.
*/
@interface YYKVStorageItem : NSObject
@property (nonatomic, strong) NSString *key; //缓存数据的key
@property (nonatomic, strong) NSData *value; //缓存数据的value
@property (nullable, nonatomic, strong) NSString *filename; //缓存文件名(文件缓存时有用)
@property (nonatomic) int size; //数据大小
@property (nonatomic) int modTime; //数据修改时间(用于更新相同key的缓存)
@property (nonatomic) int accessTime; //数据访问时间
@property (nullable, nonatomic, strong) NSData *extendedData; //附加数据
@end
缓存数据是按一条记录的格式存入数据库的,这条SQL记录包含的字段如下:
key(键)、fileName(文件名)、size(大小)、inline_data(value/二进制数据)、modification_time(修改时间)、last_access_time(最后访问时间)、extended_data(附加数据)
**写入缓存数据 **
- (BOOL)saveItemWithKey:(NSString *)key value:(NSData *)value filename:(NSString *)filename extendedData:(NSData *)extendedData {
if (key.length == 0 || value.length == 0) return NO;
if (_type == YYKVStorageTypeFile && filename.length == 0) {
return NO;
}
//如果有文件名,说明需要写入文件中
if (filename.length) {
if (![self _fileWriteWithName:filename data:value]) { //写数据进文件
return NO;
}
//写文件进数据库
if (![self _dbSaveWithKey:key value:value fileName:filename extendedData:extendedData]) {
[self _fileDeleteWithName:filename]; //写失败,同时删除文件中的数据
return NO;
}
return YES;
} else {
if (_type != YYKVStorageTypeSQLite) {
NSString *filename = [self _dbGetFilenameWithKey:key]; //从文件中删除缓存
if (filename) {
[self _fileDeleteWithName:filename];
}
}
//写入数据库
return [self _dbSaveWithKey:key value:value fileName:nil extendedData:extendedData];
}
}
该方法首先判断fileName即文件名是否为空,如果存在,则调用_fileWriteWithName方法将缓存的数据写入文件系统中,同时将数据写入数据库,需要注意的是,调用_dbSaveWithKey:value:fileName:extendedData:方法会创建一条SQL记录写入表中
代码注释如下:
- (BOOL)_dbSaveWithKey:(NSString *)key value:(NSData *)value fileName:(NSString *)fileName extendedData:(NSData *)extendedData {
//构建sql语句,将一条记录添加进manifest表
NSString *sql = @"insert or replace into manifest (key, filename, size, inline_data, modification_time, last_access_time, extended_data) values (?1, ?2, ?3, ?4, ?5, ?6, ?7);";
sqlite3_stmt *stmt = [self _dbPrepareStmt:sql]; //准备sql语句,返回stmt指针
if (!stmt) return NO;
int timestamp = (int)time(NULL);
sqlite3_bind_text(stmt, 1, key.UTF8String, -1, NULL); //绑定参数值对应"?1"
sqlite3_bind_text(stmt, 2, fileName.UTF8String, -1, NULL); //绑定参数值对应"?2"
sqlite3_bind_int(stmt, 3, (int)value.length);
if (fileName.length == 0) { //如果fileName不存在,绑定参数值value.bytes对应"?4"
sqlite3_bind_blob(stmt, 4, value.bytes, (int)value.length, 0);
} else { //如果fileName存在,不绑定,"?4"对应的参数值为null
sqlite3_bind_blob(stmt, 4, NULL, 0, 0);
}
sqlite3_bind_int(stmt, 5, timestamp); //绑定参数值对应"?5"
sqlite3_bind_int(stmt, 6, timestamp); //绑定参数值对应"?6"
sqlite3_bind_blob(stmt, 7, extendedData.bytes, (int)extendedData.length, 0); //绑定参数值对应"?7"
int result = sqlite3_step(stmt); //开始执行sql语句
if (result != SQLITE_DONE) {
if (_errorLogsEnabled) NSLog(@"%s line:%d sqlite insert error (%d): %s", __FUNCTION__, __LINE__, result, sqlite3_errmsg(_db));
return NO;
}
return YES;
}
该方法首先创建sql语句,value括号中的参数"?"表示参数需要通过变量绑定,"?"后面的数字表示绑定变量对应的索引号,如果VALUES (?1, ?1, ?2),则可以用同一个值绑定多个变量
然后调用_dbPrepareStmt方法构建数据位置指针stmt,标记查询到的数据位置,sqlite3_prepare_v2()方法进行数据库操作的准备工作,第一个参数为成功打开的数据库指针db,第二个参数为要执行的sql语句,第三个参数为stmt指针的地址,这个方法也会返回一个int值,作为标记状态是否成功
接着调用sqlite3_bind_text()方法将实际值作为变量绑定sql中的"?"参数,序号对应"?"后面对应的数字。不同类型的变量调用不同的方法,例如二进制数据是sqlite3_bind_blob方法
同时判断如果fileName存在,则生成的sql语句只绑定数据的相关描述,不绑定inline_data,即实际存储的二进制数据,因为该缓存之前已经将二进制数据写进文件。这样做可以防止缓存数据同时写入文件和数据库,造成缓存空间的浪费。如果fileName不存在,则只写入数据库中,这时sql语句绑定inline_data,不绑定fileName
最后执行sqlite3_step方法执行sql语句,对stmt指针进行移动,并返回一个int值。
删除缓存数据
removeItemForKey:方法
该方法删除指定key对应的缓存数据,区分type,如果是YYKVStorageTypeSQLite,调用_dbDeleteItemWithKey:从数据库中删除对应key的缓存记录,如下:
- (BOOL)_dbDeleteItemWithKey:(NSString *)key {
NSString *sql = @"delete from manifest where key = ?1;"; //sql语句
sqlite3_stmt *stmt = [self _dbPrepareStmt:sql]; //准备stmt
if (!stmt) return NO;
sqlite3_bind_text(stmt, 1, key.UTF8String, -1, NULL); //绑定参数
int result = sqlite3_step(stmt); //执行sql语句
...
return YES;
}
如果是YYKVStorageTypeFile或者YYKVStorageTypeMixed,说明可能缓存数据之前可能被写入文件中,判断方法是调用_dbGetFilenameWithKey:方法从数据库中查找key对应的SQL记录的fileName字段。该方法的流程和上面的方法差不多,只是sql语句换成了select查询语句。如果查询到fileName,说明数据之前写入过文件中,调用_fileDeleteWithName方法删除数据,同时删除数据库中的记录。否则只从数据库中删除SQL记录
removeItemForKeys:方法
该方法和上一个方法类似,删除一组key对应的缓存数据,同样区分type,对于YYKVStorageTypeSQLite,调用_dbDeleteItemWithKeys:方法指定sql语句删除一组记录,如下:
- (BOOL)_dbDeleteItemWithKeys:(NSArray *)keys {
if (![self _dbCheck]) return NO;
//构建sql语句
NSString *sql = [NSString stringWithFormat:@"delete from manifest where key in (%@);", [self _dbJoinedKeys:keys]];
sqlite3_stmt *stmt = NULL;
int result = sqlite3_prepare_v2(_db, sql.UTF8String, -1, &;stmt, NULL);
...
//绑定变量
[self _dbBindJoinedKeys:keys stmt:stmt fromIndex:1];
result = sqlite3_step(stmt); //执行参数
sqlite3_finalize(stmt); //对stmt指针进行关闭
...
return YES;
}
其中_dbJoinedKeys:方法是拼装,?,?,?格式,_dbBindJoinedKeys:stmt:fromIndex:方法绑定变量和参数,如果?后面没有参数,则sqlite3_bind_text方法的第二个参数,索引值依次对应sql后面的"?"
如果是YYKVStorageTypeFile或者YYKVStorageTypeMixed,通过_dbGetFilenameWithKeys:方法返回一组fileName,根据每一个fileName删除文件中的缓存数据,同时删除数据库中的记录,否则只从数据库中删除SQL记录
removeItemsLargerThanSize:方法删除那些size大于指定size的缓存数据。同样是区分type,删除的逻辑也和上面的方法一致。_dbDeleteItemsWithSizeLargerThan方法除了sql语句不同,操作数据库的步骤相同。_dbCheckpoint方法调用sqlite3_wal_checkpoint方法进行checkpoint操作,将数据同步到数据库中
读取缓存数据
getItemValueForKey:方法
该方法通过key访问缓存数据value,区分type,如果是YYKVStorageTypeSQLite,调用_dbGetValueWithKey:方法从数据库中查询key对应的记录中的inline_data。如果是YYKVStorageTypeFile,首先调用_dbGetFilenameWithKey:方法从数据库中查询key对应的记录中的filename,根据filename从文件中删除对应缓存数据。如果是YYKVStorageTypeMixed,同样先获取filename,根据filename是否存在选择用相应的方式访问。代码注释如下:
- (NSData *)getItemValueForKey:(NSString *)key {
if (key.length == 0) return nil;
NSData *value = nil;
switch (_type) {
case YYKVStorageTypeFile:
{
NSString *filename = [self _dbGetFilenameWithKey:key]; //从数据库中查找filename
if (filename) {
value = [self _fileReadWithName:filename]; //根据filename读取数据
if (!value) {
[self _dbDeleteItemWithKey:key]; //如果没有读取到缓存数据,从数据库中删除记录,保持数据同步
value = nil;
}
}
}
break;
case YYKVStorageTypeSQLite:
{
value = [self _dbGetValueWithKey:key]; //直接从数据中取inline_data
}
break;
case YYKVStorageTypeMixed: {
NSString *filename = [self _dbGetFilenameWithKey:key]; //从数据库中查找filename
if (filename) {
value = [self _fileReadWithName:filename]; //根据filename读取数据
if (!value) {
[self _dbDeleteItemWithKey:key]; //保持数据同步
value = nil;
}
} else {
value = [self _dbGetValueWithKey:key]; //直接从数据中取inline_data
}
}
break;
}
if (value) {
[self _dbUpdateAccessTimeWithKey:key]; //更新访问时间
}
return value;
}
调用方法用于更新该数据的访问时间,即sql记录中的last_access_time字段。
getItemForKey:方法
该方法通过key访问数据,返回YYKVStorageItem封装的缓存数据。首先调用_dbGetItemWithKey:excludeInlineData:从数据库中查询,下面是代码注释:
- (YYKVStorageItem *)_dbGetItemWithKey:(NSString *)key excludeInlineData:(BOOL)excludeInlineData {
//查询sql语句,是否排除inline_data
NSString *sql = excludeInlineData ? @"select key, filename, size, modification_time, last_access_time, extended_data from manifest where key = ?1;" : @"select key, filename, size, inline_data, modification_time, last_access_time, extended_data from manifest where key = ?1;";
sqlite3_stmt *stmt = [self _dbPrepareStmt:sql]; //准备工作,构建stmt
if (!stmt) return nil;
sqlite3_bind_text(stmt, 1, key.UTF8String, -1, NULL); //绑定参数
YYKVStorageItem *item = nil;
int result = sqlite3_step(stmt); //执行sql语句
if (result == SQLITE_ROW) {
item = [self _dbGetItemFromStmt:stmt excludeInlineData:excludeInlineData]; //取出查询记录中的各个字段,用YYKVStorageItem封装并返回
} else {
if (result != SQLITE_DONE) {
if (_errorLogsEnabled) NSLog(@"%s line:%d sqlite query error (%d): %s", __FUNCTION__, __LINE__, result, sqlite3_errmsg(_db));
}
}
return item;
}
sql语句是查询符合key值的记录中的各个字段,例如缓存的key、大小、二进制数据、访问时间等信息, excludeInlineData表示查询数据时,是否要排除inline_data字段,即是否查询二进制数据,执行sql语句后,通过stmt指针和_dbGetItemFromStmt:excludeInlineData:方法取出各个字段,并创建YYKVStorageItem对象,将记录的各个字段赋值给各个属性,代码注释如下:
- (YYKVStorageItem *)_dbGetItemFromStmt:(sqlite3_stmt *)stmt excludeInlineData:(BOOL)excludeInlineData {
int i = 0;
char *key = (char *)sqlite3_column_text(stmt, i++); //key
char *filename = (char *)sqlite3_column_text(stmt, i++); //filename
int size = sqlite3_column_int(stmt, i++); //数据大小
const void *inline_data = excludeInlineData ? NULL : sqlite3_column_blob(stmt, i); //二进制数据
int inline_data_bytes = excludeInlineData ? 0 : sqlite3_column_bytes(stmt, i++);
int modification_time = sqlite3_column_int(stmt, i++); //修改时间
int last_access_time = sqlite3_column_int(stmt, i++); //访问时间
const void *extended_data = sqlite3_column_blob(stmt, i); //附加数据
int extended_data_bytes = sqlite3_column_bytes(stmt, i++);
//用YYKVStorageItem对象封装
YYKVStorageItem *item = [YYKVStorageItem new];
if (key) item.key = [NSString stringWithUTF8String:key];
if (filename && *filename != 0) item.filename = [NSString stringWithUTF8String:filename];
item.size = size;
if (inline_data_bytes > 0 &;&; inline_data) item.value = [NSData dataWithBytes:inline_data length:inline_data_bytes];
item.modTime = modification_time;
item.accessTime = last_access_time;
if (extended_data_bytes > 0 &;&; extended_data) item.extendedData = [NSData dataWithBytes:extended_data length:extended_data_bytes];
return item; //返回YYKVStorageItem对象
}
最后取出YYKVStorageItem对象后,判断filename属性是否存在,如果存在说明缓存的二进制数据写进了文件中,此时返回的YYKVStorageItem对象的value属性是nil,需要调用_fileReadWithName:方法从文件中读取数据,并赋值给YYKVStorageItem的value属性。代码注释如下:
- (YYKVStorageItem *)getItemForKey:(NSString *)key {
if (key.length == 0) return nil;
//从数据库中查询记录,返回YYKVStorageItem对象,封装了缓存数据的信息
YYKVStorageItem *item = [self _dbGetItemWithKey:key excludeInlineData:NO];
if (item) {
[self _dbUpdateAccessTimeWithKey:key]; //更新访问时间
if (item.filename) { //filename存在,按照item.value从文件中读取
item.value = [self _fileReadWithName:item.filename];
...
}
}
return item;
}
getItemForKeys:方法
返回一组YYKVStorageItem对象信息,调用_dbGetItemWithKeys:excludeInlineData:方法获取一组YYKVStorageItem对象。访问逻辑和getItemForKey:方法类似,sql语句的查询条件改为多个key匹配。
getItemValueForKeys:方法
返回一组缓存数据,调用getItemForKeys:方法获取一组YYKVStorageItem对象后,取出其中的value,存入一个临时字典对象后返回。
YYDiskCache
YYDiskCache是上层调用YYKVStorage的类,对外提供了存、删、查、边界控制的方法。内部维护了三个变量,如下:
@implementation YYDiskCache {
YYKVStorage *_kv;
dispatch_semaphore_t _lock;
dispatch_queue_t _queue;
}
_kv用于缓存数据,_lock是信号量变量,用于多线程访问数据时的同步操作。
初始化方法
nitWithPath:inlineThreshold:方法用于初始化,下面是代码注释:
- (instancetype)initWithPath:(NSString *)path
inlineThreshold:(NSUInteger)threshold {
...
YYKVStorageType type;
if (threshold == 0) {
type = YYKVStorageTypeFile;
} else if (threshold == NSUIntegerMax) {
type = YYKVStorageTypeSQLite;
} else {
type = YYKVStorageTypeMixed;
}
YYKVStorage *kv = [[YYKVStorage alloc] initWithPath:path type:type];
if (!kv) return nil;
_kv = kv;
_path = path;
_lock = dispatch_semaphore_create(1);
_queue = dispatch_queue_create("com.ibireme.cache.disk", DISPATCH_QUEUE_CONCURRENT);
_inlineThreshold = threshold;
_countLimit = NSUIntegerMax;
_costLimit = NSUIntegerMax;
_ageLimit = DBL_MAX;
_freeDiskSpaceLimit = 0;
_autoTrimInterval = 60;
[self _trimRecursively];
...
return self;
}
根据threshold参数决定缓存的type,默认threshold是20KB,会选择YYKVStorageTypeMixed方式,即根据缓存数据的size进一步决定。然后初始化YYKVStorage对象,信号量、各种limit参数。
写缓存
setObject:forKey:方法存储数据,首先判断type,如果是YYKVStorageTypeSQLite,则直接将数据存入数据库中,filename传nil,如果是YYKVStorageTypeFile或者YYKVStorageTypeMixed,则判断要存储的数据的大小,如果超过threshold(默认20KB),则需要将数据写入文件,并通过key生成filename。YYCache的作者认为当数据代销超过20KB时,写入文件速度更快。代码注释如下:
- (void)setObject:(id<NSCoding>)object forKey:(NSString *)key {
...
value = [NSKeyedArchiver archivedDataWithRootObject:object]; //序列化
...
NSString *filename = nil;
if (_kv.type != YYKVStorageTypeSQLite) {
if (value.length > _inlineThreshold) { //value大于阈值,用文件方式存储value
filename = [self _filenameForKey:key];
}
}
Lock();
[_kv saveItemWithKey:key value:value filename:filename extendedData:extendedData]; //filename存在,数据库中不写入value,即inline_data字段为空
Unlock();
}
//读缓存
objectForKey:方法调用YYKVStorage对象的getItemForKey:方法读取数据,返回YYKVStorageItem对象,取出value属性,进行反序列化。
//删除缓存
removeObjectForKey:方法调用YYKVStorage对象的removeItemForKey:方法删除缓存数据
边界控制
在前一篇文章中,YYMemoryCache实现了内存缓存的LRU算法,YYDiskCache也试了LRU算法,在初始化的时候调用_trimRecursively方法每个一定时间检测一下缓存数据大小是否超过容量。
数据同步
YYMemoryCache使用了互斥锁来实现多线程访问数据的同步性,YYDiskCache使用了信号量来实现,下面是两个宏:
#define Lock() dispatch_semaphore_wait(self->_lock, DISPATCH_TIME_FOREVER)
#define Unlock() dispatch_semaphore_signal(self->_lock)
读写缓存数据的方法中都调用了宏:
- (void)setObject:(id<NSCoding>)object forKey:(NSString *)key
{
...
Lock();
[_kv saveItemWithKey:key value:value filename:filename extendedData:extendedData];
Unlock();
}
- (id<NSCoding>)objectForKey:(NSString *)key {
Lock();
YYKVStorageItem *item = [_kv getItemForKey:key];
Unlock();
...
}
初始化方法创建信号量,dispatch_semaphore_create(1),值是1。当线程调用写缓存的方法时,调用dispatch_semaphore_wait方法使信号量-1。同时线程B在读缓存时,由于信号量为0,遇到dispatch_semaphore_wait方法时会被阻塞。直到线程A写完数据时,调用dispatch_semaphore_signal方法时,信号量+1,线程B继续执行,读取数据。关于iOS中各种互斥锁性能的对比。
我们看一些接口设计方面的内容:
#pragma mark - Attribute
///=============================================================================
/// @name Attribute
///=============================================================================
@property (nonatomic, readonly) NSString *path; ///< The path of this storage.
@property (nonatomic, readonly) YYKVStorageType type; ///< The type of this storage.
@property (nonatomic) BOOL errorLogsEnabled; ///< Set `YES` to enable error logs for debug.
#pragma mark - Initializer
///=============================================================================
/// @name Initializer
///=============================================================================
- (instancetype)init UNAVAILABLE_ATTRIBUTE;
+ (instancetype)new UNAVAILABLE_ATTRIBUTE;
/**
The designated initializer.
@param path Full path of a directory in which the storage will write data. If
the directory is not exists, it will try to create one, otherwise it will
read the data in this directory.
@param type The storage type. After first initialized you should not change the
type of the specified path.
@return A new storage object, or nil if an error occurs.
@warning Multiple instances with the same path will make the storage unstable.
*/
- (nullable instancetype)initWithPath:(NSString *)path type:(YYKVStorageType)type NS_DESIGNATED_INITIALIZER;
接口中的属性都是很重要的信息,我们应该尽量利用好它的读写属性,尽量设计成只读属性。默认情况下,不是只读的,都很容易让其他开发者认为,该属性是可以设置的。
对于初始化方法而言,如果某个类需要提供一个指定的初始化方法,那么就要使用NS_DESIGNATED_INITIALIZER给予提示。同时使用UNAVAILABLE_ATTRIBUTE禁用掉默认的方法。接下来要重写禁用的初始化方法,在其内部抛出异常:
- (instancetype)init {
@throw [NSException exceptionWithName:@"YYKVStorage init error" reason:@"Please use the designated initializer and pass the 'path' and 'type'." userInfo:nil];
return [self initWithPath:@"" type:YYKVStorageTypeFile];
}
上边的代码大家可以直接拿来用,千万不要怕程序抛出异常,在发布之前,能够发现潜在的问题是一件好事。使用了上边的一个小技巧后呢,编码水平是不是有所提升?
再给大家简单分析分析下边一样代码:
- (nullable instancetype)initWithPath:(NSString *)path type:(YYKVStorageType)type NS_DESIGNATED_INITIALIZER;
上边我们关心的是nullable关键字,表示可能为空,与之对应的是nonnull,表示不为空。可以说,他们都跟swift有关系,swift中属性或参数是否为空都有严格的要求。因此我们在设计属性,参数,返回值等等的时候,要考虑这些可能为空的情况。
// 设置中间的内容默认都是nonnull
NS_ASSUME_NONNULL_BEGIN
NS_ASSUME_NONNULL_END
总结
YYCache库的分析到此为止,其中有许多代码值得学习。例如二级缓存的思想,LRU的实现,SQLite的WAL机制。文中许多地方的分析和思路,表达的不是很准确和清楚,希望通过今后的学习和练习,提升自己的水平,总之路漫漫其修远兮...
