

使用什么数据结构存储HASH
将每一项存在数组中,通过下标来索引。这种实现的方式问题在于:
- 要存储的key不是int,不能作为下标;
解决方案:将key从string映射成int
- 需要的key非常多,储存key所需要的空间可能非常大
解决方案:将所有可能的key映射到一个大小为m的table中,理想情况 m=n,n表示table中key的个数。问题:有可能造成冲突,即两个不同的key计算hash之后,却得到了同一个key
如何将key映射到table的索引的方案
使用hash函数。
除法
h(k)=k mod m
这种方式选择的m通常是与2的幂次方不太接近的质数
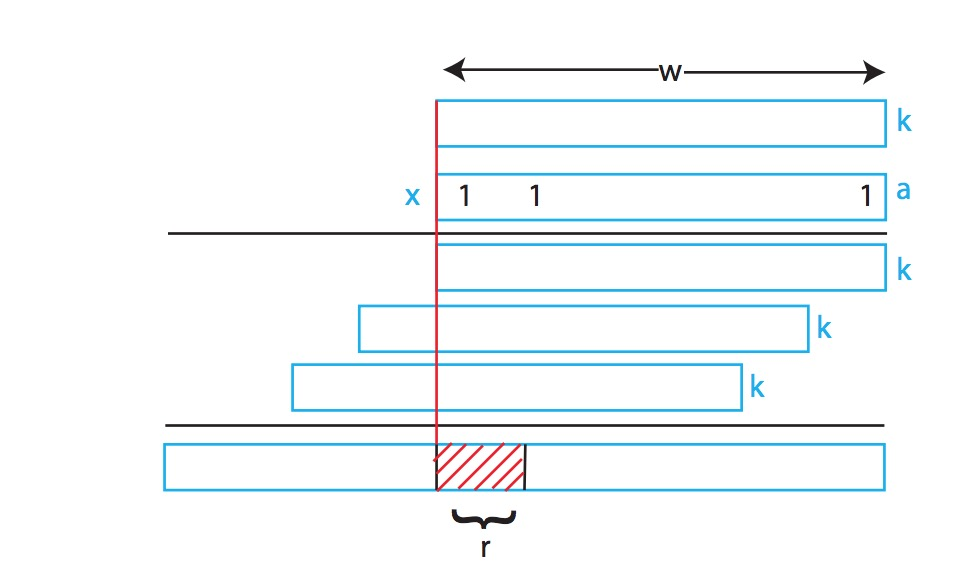
乘法
其中a是个随机数,k包含w个bit,m一般选择
取值规则如下:
全局hash
h(k)=[(ak+b)mod p]mod m
其中a,b是{0,..,p-1}中的随机值,P是一个大的质数
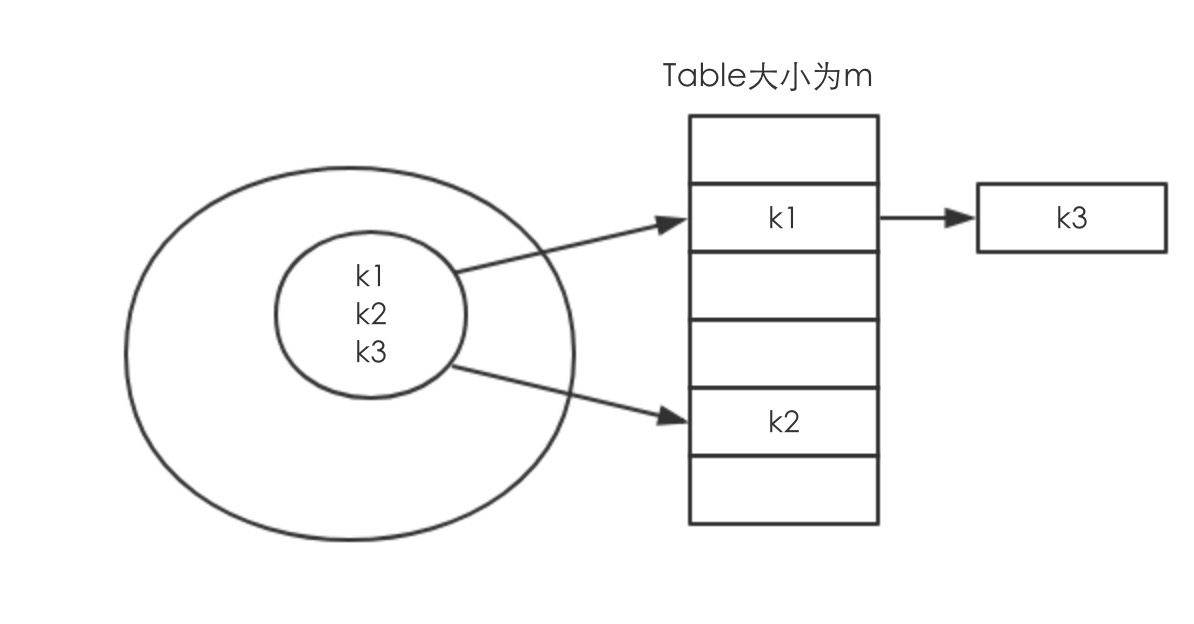
使用链表解决hash冲突
如果key是一样的,就在table的当前索引值之后加一个链表,指向新的加入的值,此时,最坏的情况就是,所有的key都hash冲突,导致最坏的查找时间为O(n)
简单一致hash
假设每个key被映射到table中的任意一个索引的概率是一样的,与其它的key通过hashing计算出来的位置无关。
在这种假设下 ,假设一共有n个key,表的大小为m,那么每个链条的长度那么一般情况下,运行时间为 O(1+α),因而可以看到在假设的前提之下,使用链表解决hash冲突是个不错的选择
使用open address来解决hash冲突
具体策略为,hash函数包括要计算hash的key和尝试的次数来得到具体的下标
假设经过3次插入数据,h(586,1)=1,h(133,1)=2,h(112,1)=4
再次插入一个数据h(226,1)=4,此时产生了冲突,增加重试的次数,得到h(226,2)=3此时还没有存储值,可以插入
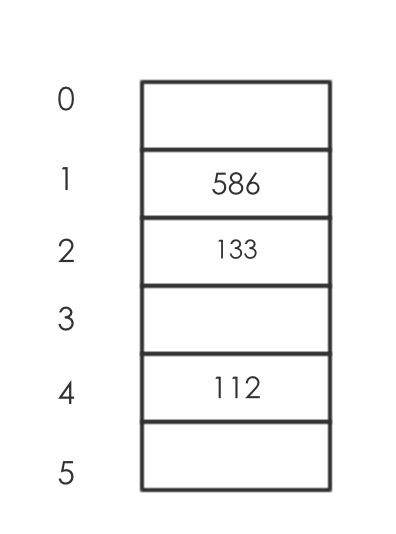
- 插入:通过给定的hash函数计算下标位置,如果计算出来的下标没有值,或者数据已经删除了,就插入,否则增加尝试的次数,再次计算
- 搜索:通过hash函数计算得到下标,如果得到的key和要搜索的key不一致,就增加尝试的次数,直到找到或者是计算得到的下标所在处没有值,就停止
- 删除:首先找到对应的值,此时,仅标记为这个数据已经删除了,但是不把存储的地方置为空
标记的方式用于解决,示例中的,加入删除了112,在查找226的过程中,计算h(226,1)==4,而之前的位置被112占据,如果删除112的时候置为空,那么此时会标记为找不到,很明显不正确,如果仅标记为已经删除则可以解决这个问题,对于带有删除标记的位置,同样可以插入,这样就解决了问题
尝试的策略选择
- 线性增长。选取h(k,i)=(h'(k)+i)mod m,其中h'(k)为一个可行的hash函数,这种场景下它是能够去遍历所有的存储数组的位置,但是这种方式存在一个问题,随着已经存储的数据越多,需要尝试的次数也就越多,最终插入和搜索将不会是常数时间
- double hash。选取
,当
和m互为素数的时候,就可以遍历所有的存储数组的位置
这种情况下,需要尝试的次数为
hash存储的表大小(m)应该是多少?
期望查找的时间是常量,那么希望,考虑到m太小,查询慢;m太大,浪费
- 需要增长m。可以首先使得m是一个较小的值,然后再使m增大为m'。考虑两种增长策略:
- m'=m+1,此时的时间花销为
- m'=2m,此时的时间花销为
- m'=m+1,此时的时间花销为
- 需要缩小m。如果删除了表中的很多数据,原来的占据空间过大,存在浪费,最好减少空间的浪费
- m'=n/2,将m变为原来的一半。假设仅有8个元素,如果再插入一个元素,需要一次增长达到16,此时再删除一个元素,又要缩减到8,每次都需要移动原来的
元素
- m'=n/4,使得m变为原来的一半。这个时候并不会出现上面的问题
- m'=n/2,将m变为原来的一半。假设仅有8个元素,如果再插入一个元素,需要一次增长达到16,此时再删除一个元素,又要缩减到8,每次都需要移动原来的
hash的运用
给定两个字符串s和t,需要判断s是否在t中出现。
最简单的方法是两次遍历:
for i in range(len(t)-len(s)):
for j in range(len(s)):
依次对比是否能够成功匹配
它的执行规则为遍历整个的字符串,然后依次去匹配短字符串s是否存在原来的数组中,没有找到,依次后移
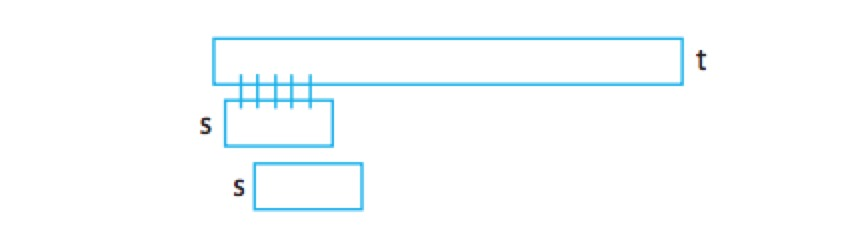
Karp-Rabin算法
使用Karp-Rabin算法提高速度,对于要匹配的字符串s,可以直接算出它的hash值,对于字符串t,需要首选获取一个长度为|s|的字符串,同样可以计算它的hash值


- r.skip(oldChar)
- r.append(newChar)
- 计算新的hash值
如果在上面的计算过程都能够在常量时间内完成,那么总共的花销为O(|t|)。具体实施如下:
def rhCombinationMatch(self):
winLength = len(self.findStr)
//构建要查找的字符串RollingHash对象
winRh = RollingHashCombination(self.findStr)
lineLen = len(self.lines)
//构建要多次计算的字符串的RollingHash对象
matchRh = RollingHashCombination(self.lines[0:winLength])
for i in range(0,lineLen-winLength+1):
//判断两个的hash值是否一致
if matchRh.hash() == winRh.hash():
sequence=self.lines[i:i+winLength]
# 如果一致,排除hash冲突的影响,看下字符串是否相等
if sequence == self.findStr:
self.count+=1
if i+winLength<lineLen:
//没有匹配到,变换新的字符串,去掉第一个,加上下一个
matchRh.slide(self.lines[i],self.lines[i+winLength])
构建的RollingHash对象如下,它主要负责去将每一个步骤组装起来
class RollingHashCombination(object):
"""
将rolling hash的每一步组合起来
"""
def __init__(self,s):
base = 7
p=499999
self.rhStepByStep = RollingHashStepByStep(base,p)
for c in s:
self.rhStepByStep.append(c)
self.chash = self.rhStepByStep.hash()
def hash(self):
return self.chash
//依次删掉之前的值 , 添加新的值
def slide(self,preChar,nextChar):
"""
删掉之前的值 , 添加新的值
"""
self.rhStepByStep.skip(preChar)
self.rhStepByStep.append(nextChar)
self.chash = self.rhStepByStep.hash()
举例假设有5个字符串为"ABCDEF",要找的字符串长度为3,而hash值仅根据ASCII来直接拼接,真整个计算过程匹配如下:
- 第一个匹配的字符串为 "abc",对应的hash值为 656667
- 没有找到,首先移除第一个字符,按照100进制来计算,有 656667-65*100^2
- 在后面添加一个字符D,计算结果为 6667*100+68
因而原始的字符从656667演变成了666768。假设
- n(0) 旧数字
- n(1) 新数字
- old 要删除的元素
- new 要增加的元素
- base表示进制
- k表示要比较的字串的长度
那么n(1) = (n(0)-old*base^(K-1))*base+new,假设旧数字的hash值是 h1,新数字的hash是
h2=[(n(0)-old*base^(K-1))*base+new] mod p
=[(n(0) mode p)*base -old *(base^(k) mod p) +new ] mod p //对同行一个数求两次余数不会改变结果
使magic = base(k) mod p 而 h1 = n(0) mod p,h2= [h1base -oldmagic +new ]mod p
代码实现如下,负责每个步骤hash值的计算
class RollingHashStepByStep(object):
"""
对RollingHash进行一步一步的拆分,可以分成两个步骤,每个步骤都会生成对应的hash值
"""
def __init__(self, base,p):
"""
得到一个rollinghash初始值
"""
super(RollingHashStepByStep, self).__init__()
self.base = base
# 质数
self.p = p
# 刚开始没有元素
self.chash= 0
# 刚开始没有元素 magic = magic ** k %p k=0
self.magic= 1
self.ibase = base ** (-1)
# 保证数据小
def append(self,newChar):
"""
在原有的hash基础上增加一个字符,计算其hash值
"""
# old 返回一个字串的 ASCII值
new10=ord(newChar)
self.chash = (self.chash * self.base + new10 ) % self.p
#滑动窗口中增加一个元素,根据magic的定义 magic是base的长度的次方
self.magic = (self.magic * self.base)
def skip(self,oldChar):
"""
在原有的hash基础上去掉一个字符,计算其hash值
"""
# hash-old*magic 可能是负值 old < base magic <p
self.magic =int(self.magic * self.ibase)
# todo 进制计算,为什么传进来的数字不需要转换成对应的进制 在不用base的地方进行解答
old10 =ord(oldChar);
self.chash = (self.chash-old10*self.magic + self.p * self.base ) % self.p
def hash(self):
return self.chash
