

memcached分布式原理与实现
0x01 概况
1.1 什么是memcached
memcached是一个分布式,开源的数据存储引擎。
memcached是一款高性能的分布式内存缓存服务器,通过减少查询次数来抵消沉重缓慢的数据集或API调用、提高应用响应速度、提高可扩展性。
在高并发的场景下, 大量的读/写请求涌向数据库, 此时磁盘IO将成为瓶颈, 从而导致过高的响应延迟, 因此缓存应运而生.
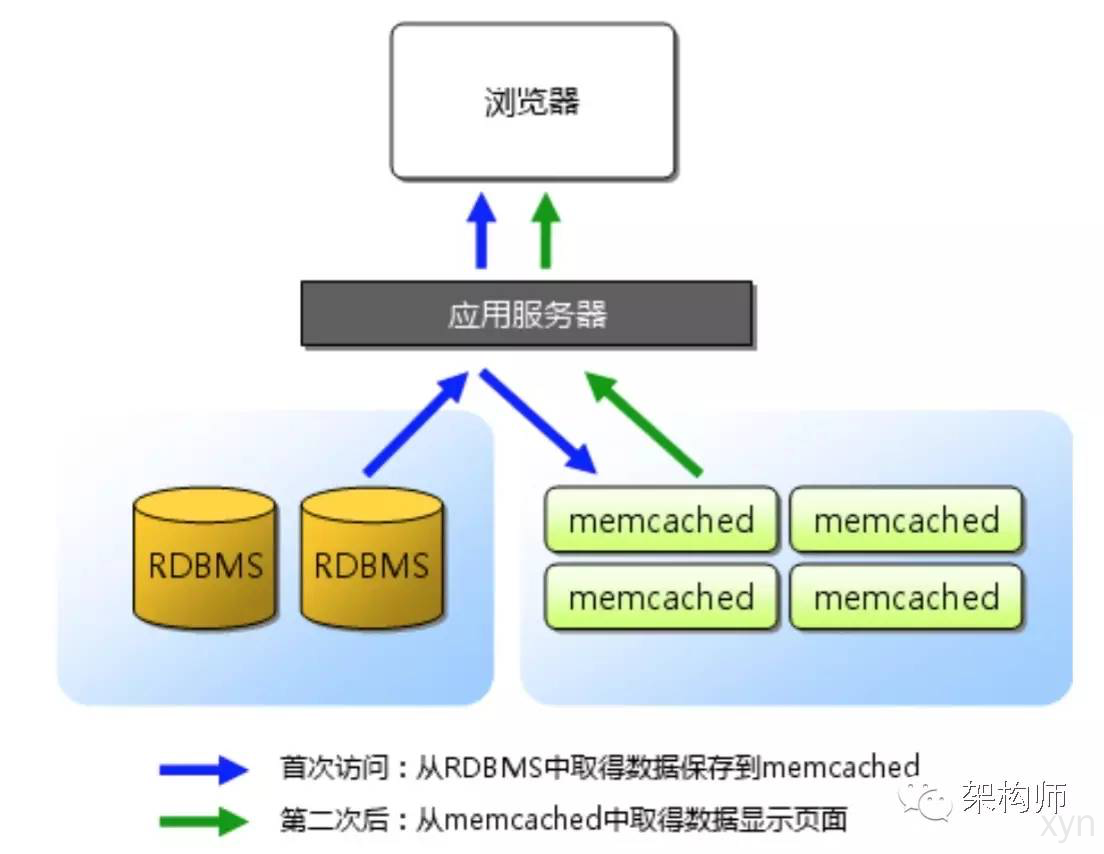
Memcached的工作方式是将关键词和他们对应的值(最大能达到1MB)保存在一个关联矩阵中(比如哈希表),延展和分布在大量的虚拟服务器中。
当然无论是单机缓存还是分布式缓存都有其适用场景和优缺点, 最常见的有redis和memcached. 本文主要是介绍memcached.
1.2 缓存介绍 - 计算机体系缓存
硬盘 --> 内存 --> 三级缓存 --> 二级缓存 --> 一级缓存
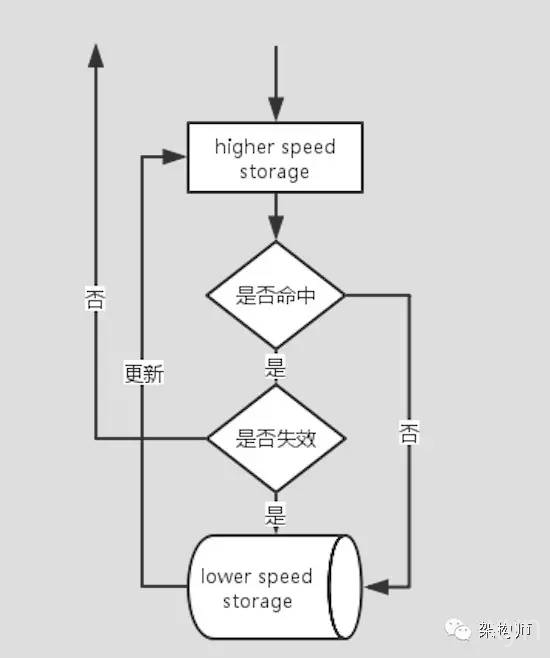
1.3 缓存介绍 - 缓存应用系统
首先访问较快的存储介质, 如果命中且未生效则返回内容. 如果命中或失效则访问较慢的存储介质将内容返回同时更新缓存.
1.4 memcached特点
| 特点 | 描述 |
|---|---|
| 协议简单 | 它是基于文本行的协议,直接通过telnet在memcached服务器上可进行存取数据操作 |
| 基于libevent事件处理 | 异步I/O, 基于事件的单进程和单线程, 使用libevent作为事件处理机制; |
| 内置内存存储方式, 非持久性存储 | 所有数据都保存在内存中,存取数据比硬盘快,当内存满后,通过LRU算法自动删除不使用的缓存,但没有考虑数据的容灾问题,重启服务,所有数据会丢失。 |
| 分布式 | 各个memcached服务器之间互不通信,各自独立存取数据,不共享任何信息。服务器并不具有分布式功能,分布式部署取决于memcache客户端。 |
0x02 安装与使用
2.1 如何启动-源码安装
# 安装依赖包
apt-get install libevent-dev
#安装Memcached
wget http://memcached.org/latest
tar -zxvf memcached-1.x.x.tar.gz
cd memcached-1.x.x
./configure && make && make test && sudo make install
#启动memcached
memcached -p 11211 -d -u root -P /tmp/memcached.pid
-P是表示使用TCP,默认端口为11211 -d表示后台启动一个守护进程(daemon) -u表示指定root用户启动,默认不能用root用户启动 -P表示进程的pid存放地点,此处“p”为大写“P” -l,后面跟IP地址,手工指定监听IP地址,默认所有IP都在监听 -m后面跟分配内存大小,以MB为单位,默认为64M -c最大运行并发连接数,默认为1024 -f 块大小增长因子,默认是1.25 -M 内存耗尽时返回错误,而不是删除项,即不用LRU算法 在64位系统中,会报libevent-1.4.so.2文件无法找到,解决办法是把32位目录里的同名文件链接至64位目录中,即像windows那样建立快捷方式。 Shell > /usr/local/lib/libevent-1.4.so.2 /usr/lib64/libevent-1.4.so.2 启动后如果发现没有端口在监听,是因为命动命令时带pid参数的“p”是大写“P”,你可能写成小写了。
2.2 如何启动-docker安装
// 运行一个内存限制为1024MB的容器:
sudo docker run -name csphere-memcached -m 1024m -d -p 11211:11211 memcached:alpine
可以查看Memcached:latest 使用的 Dockerfile, 来获取 memcached在debian下的安装方法
2.3 如何使用
| 分类 | 方法 | 描述 |
|---|---|---|
| 存 | set | 添加一个新条目到memcached或是用新的数据替换替换掉已存在的条目 |
| 存 | add | 当KEY不存在的情况下,它向memcached存数据,否则,返回NOT_STORED响应 |
| 存 | replace | 当KEY存在的情况下,它才会向memcached存数据,否则返回NOT_STORED响应 |
| 存 | cas | 改变一个存在的KEY值 ,但它还带了检查的功能 |
| 存 | append | 在这个值后面插入新值 |
| 存 | prepend | 在这个值前面插入新值 |
| 取 | get | 取单个值 ,从缓存中返回数据时,将在第一行得到KEY的名字,flag的值和返回的value长度,真正的数据在第二行,最后返回END,如KEY不存在,第一行就直接返回END |
| 取 | get_multi | 一次性取多个值 |
| 删 | delete |
# 清空memcache数据
telnet 10.27.5.71 11211
flush_all
quit //退出telnet
2.4 php使用memcached
yum -y install libmemcached.x86_64 libmemcached-devel.x86_64
cd /usr/src
git clone https://github.com/php-memcached-dev/php-memcached.git
cd php-memcached/
git checkout php7
/alidata/server/php/bin/phpize
./configure --with-php-config=/alidata/server/php/bin/php-config
make
make install
2.5 管理与性能监控
可以通过命令行直接管理与监控也可通过nagios等监控软件进行监控 命令行:
// 如果在启动时指定了IP及端口号,这里要作相应改动,连接成功后命令
telnet 127.0.0.1 11211
| 命令 | 描述 |
|---|---|
| stats | 统计memcached的各种信息 |
| stats reset | 重新统计数据 |
| stats slabs | 显示slabs信息,可以详细看到数据的分段存储情况 |
| stats items | 显示slab中的item数目 |
| stats cachedump 1 0 | 列出slabs第一段里存的KEY值 |
| set/get | 保存/获取数据 |
| STAT evictions 0 | 表示要腾出新空间给新的item而移动的合法item数目 |
0x03 架构原理与分析
3.1 内存算法
Memcached利用slab allocation机制来分配和管理内存,它按照预先规定的大小,将分配的内存分割成特定长度的内存块,再把尺寸相同的内存块分成组,数据在存放时,根据键值 大小去匹配slab大小,找就近的slab存放,所以存在空间浪费现象。
传统的内存管理方式是,使用完通过malloc分配的内存后通过free来回收内存,这种方式容易产生内存碎片并降低操作系统对内存的管理效率。
Memcached的内存管理制效率高,而且不会造成内存碎片,但是它最大的缺点就是会导致空间浪费。因为每个 Chunk都分配了特定长度的内存空间,所以变长数据无法充分利用这些空间。如图二所示,将100个字节的数据缓存到128个字节的Chunk中,剩余的28个字节就浪费掉了。

如何避免内存浪费
- 预先计算出应用存入的数据大小,或把同一业务类型的数据存入一个Memcached服务器中,确保存入的数据大小相对均匀,这样就可以减少对内存的浪费
- 在启动时指定“-f"参数,能在某种程度上控制内存组之间的大小差异
- 在应用中使用Memcached时,通常可以不重新设置这个参数,使用默认值1.25进行部署
- 如果想优化Memcached对内存的使用,可以考虑重新计算数据的预期平均长度,调整这个参数来获得合适的设置值
3.2 删除机制(缓存策略)
Memcached的缓存策略是**LRU(最近最少使用)**加上到期失效策略。当你在memcached内存储数据项时,你有可能会指定它在缓存的失效时间,默认为永久。当memcached服务器用完分配的内时,失效的数据被首先替换,然后也是最近未使用的数据。在LRU中,memcached使用的是一种Lazy Expiration策略,自己不会监控存入的key/vlue对是否过期,而是在获取key值时查看记录的时间戳,检查key/value对空间是否过期,这样可减轻服务器的负载。
当空间占满时
- 使用LRU算法来分配空间,删除最近最少使用的key/value对
- 如果不使用LRU的话, 在启动参数上加入”-M”, 内存耗尽时,会返回报错信息
3.3 分布式概述
memcached不相互通信,那么memcached是如何实现分布式的呢?
memcached的分布式实现主要依赖客户端的实现.
当数据到达客户端, 客户端实现的算法会根据”键”来决定保存的memcached服务器. 服务器选定后, 命令他保存数据. 取的时候也一样, 客户端根据”键”选择服务器, 使用保存时候的相同算法就能保存选中和存的时候相同的服务器.
也就是说,存取数据分二步走,第一步,选择服务器,第二步存取数据。
使用什么算法选择服务器呢?
client 使用Hash算法来完成数据分散存储.
3.4 分布式算法(Hash算法)
当向memcached集群存入/取出key/value时,memcached客户端程序根据一定的算法计算存入哪台服务器,然后再把key/value值存到此服务器中。也就是说,存取数据分二步走,第一步,选择服务器,第二步存取数据。
常用的算法有两种: 余数计算分散法 和 一致性Hash算法.
3.4.1 余数计算分散法
- 标准的memcached分布式算法
CRC($key)%N
客户端首先根据key来计算CPC, 然后结果对服务器取模得到memcached服务器节点
- 被匹配到的服务器无法连接时
- rehash: 尝试将连接的次数加到key后面, 重新hash
- 添加/移除服务器
- 余数计算分散发相当简单,数据分散也很优秀
- 几乎所有的缓存都会失效, 缓存重组的代价相当的大。
- 权重不易实现
3.4.2 一致性hash算法
将server的hash值分配至0~2^32的圆环上, 用同样的方法求出存储数值键的hash值并映射到圆上. 然后从数据映射到的位置开始顺时针查找, 将数据存放至找到的第一台服务器上. 如果超过0~2^32还找不到, 则将数据存放至第一台服务器.
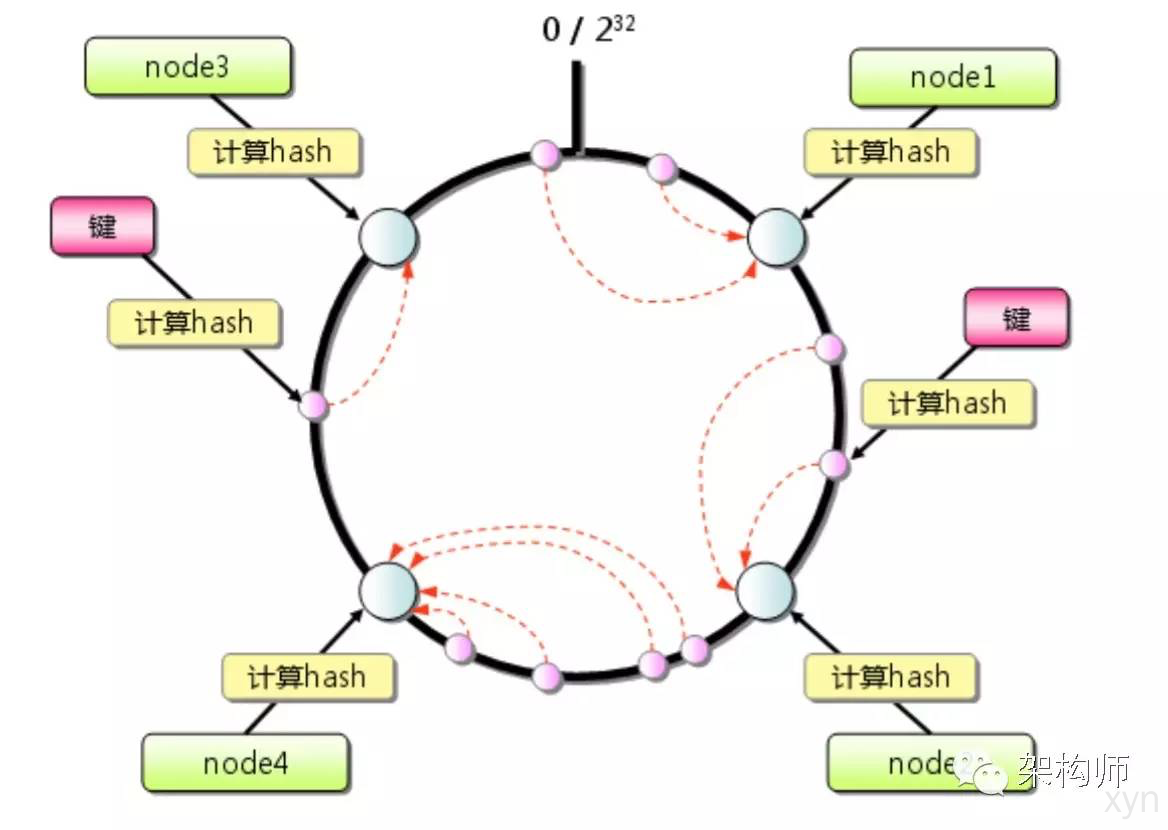
如果新添/删除一台server, 在一致性hash算法下会有什么影响?
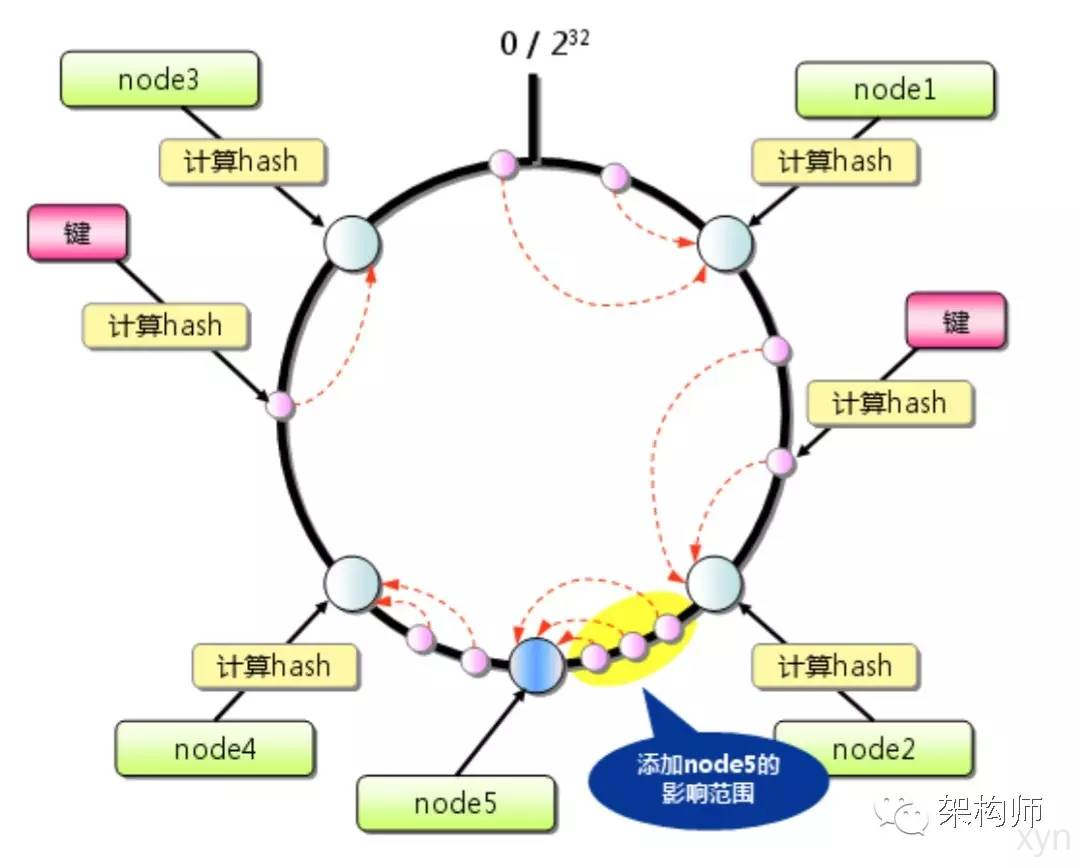
如图, 新添/删除server时, 只在圆上增加服务器的逆时针方向的第一台服务器上的键会受到影响。
优化一致性hash算法
- 一般的一致性hash算法最大限度的抑制了键的重新分配, 并且有的实现方式还采用了虚拟节点的思想
- 服务器的映射地点的分布非常的不均匀, 导致数据访问倾斜, 大量的key被映射到同一台服务器上.
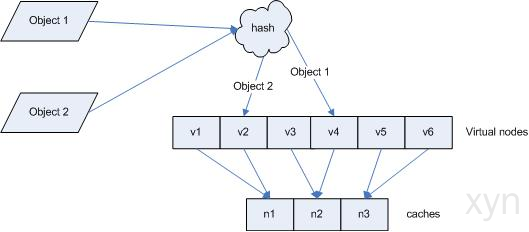
- 虚拟节点: 每台机器计算出多个hash值, 每个值对应环上的一个节点位置
- key的映射方式不变, 就多了层从虚拟节点到再映射到物理机的过程
优化后: 在物理机很少的情况下, 只要虚拟节点足够多, 也能使的key分布相对均匀. 提升了算法的平衡性.
3.5 Hash算法的衡量指标
3.5.1 是单调性(Monotonicity)
单调性是指如果已经有一些内容通过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应能够保证原有已分配的内容可以被映射到新的缓冲中去,而不会被映射到旧的缓冲集合中的其他缓冲区。
3.5.2 平衡性
平衡性是指哈希的结果能够尽可能分布到所有的缓冲中去,这样可以使得所有的缓冲空间都得到利用。
hash 算法并不是保证绝对的平衡
0x04 常见问题
4.1 memcached与redis的区别?
| 对比点 | memcached | redis |
|---|---|---|
| 数据结构 | 单一(存储数据的类型都是String字符串类型) | 丰富(String、List、Set、Sortedset、Hash) |
| 内存使用率 | 使用简单的key-value存储,Memcached的内存利用率更高 | Redis采用hash结构来做key-value存储,由于其组合式的压缩,其内存利用率会高于Memcached |
| 持久化 | 不可以 | 可以(可以把数据随时存储在磁盘上) |
| 数据同步 | 不可以 | 可以 |
| 多核 | 可以使用多核(多线程) | 单核 |
| 数据大小 | 单个key(变量)存放的数据有1M的限制 | 单个key(变量)存放的数据有1GB的限制 |
| 计算能力 | 无 | 本身有一定的计算功能 |
- Redis在存储小数据时比Memcached性能更高
- 在100k以上的数据中,Memcached性能要高于Redis
- memcached增加了网络IO的次数和数据体积
memcached和redis对过期数据的处理
Redis是懒处理,对有有效期的数据会做有效期的标识,在指定时间会对有过期时间的数据做处理。随机取出一部分数据,检查是否有过期数据,如果过期数据超过25/100,则反复此过程
4.2 memcache为什么快?
它使用libevent,可以应付任意数量打开的连接(使用epoll,而非poll),使用非阻塞网络IO,分布式散列对象到不同的服务器,查询复杂度是O(1)。
4.3 Memcache缓存命中率?
缓存命中率 = get_hits/cmd_get * 100%
4.4 Memcache集群实现
一致性Hash
0x05 总结
a. 在软件工程的项目实战中, 经常会遇到时间/空间的权衡, 缓存是权衡中被研究出的一种典型的技术, 而memcached又是此类技术中的佼佼者.
b. 在高并发环境下,大量的读、写请求涌向数据库,此时磁盘IO将成为瓶颈,从而导致过高的响应延迟,因此缓存应运而生。
c. 本文在理解缓存基本概念的情况下介绍了memcached的分布式算法实现原理
