温馨小提示
全文加上代码总6.8k个字,阅读大约10分钟,谢谢你的点击,愿能解决你的问题;
前言
前几天在小猪群里,有同学问,有人知道怎么做豆瓣自动回复功能吗?然后群里就各种大神出马相助,各种填代码给资料的,也有同学说用selenium模拟下就好了等等,其实大家都说的对,伸手党固然不好,但是考虑到让一个不了解的同学去做这个事,的确有门槛,更别说查资料用selenium了;

豆瓣回复功能尝试
一开始的想法,也是用selenium的,但是想着,还是先模拟下,看看豆瓣的回复流程吧;
先打开需要回复的帖子,然后接着登录豆瓣,然后回到刚刚这个帖子上,观察下界面,回复按钮就在底部,点击发送就是评论了;

那我们就抓包看下请求吧,浏览器按F12,选择network,点击左边红色按钮两次,把之前的数据都清除;
接着就输入内容,点击发送按钮,然后查看network界面,不难找到发送评论的请求,从名字上看,也能确认是发送评论的请求;
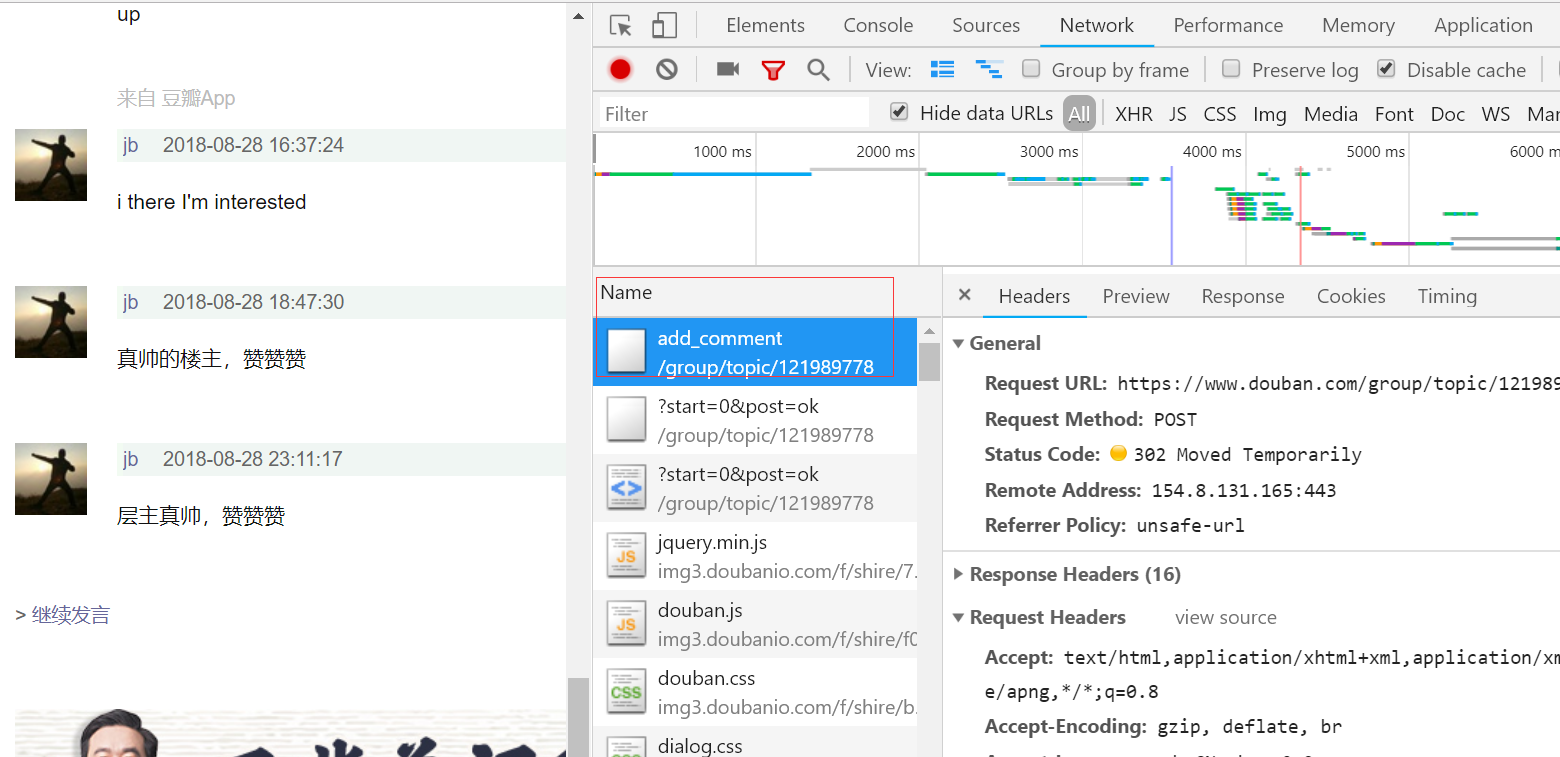
https://www.douban.com/group/topic/121989778/add_comment
而且发现,请求的时候,要带4个参数:
ck=TXEg
rv_comment=层主真帅,赞赞赞 #这个就是要回复的内容
start=0
submit_btn=发送
既然如此,那就用postman试一下吧:
请求头参数用了常规的cookie、user-agent、referer、host;
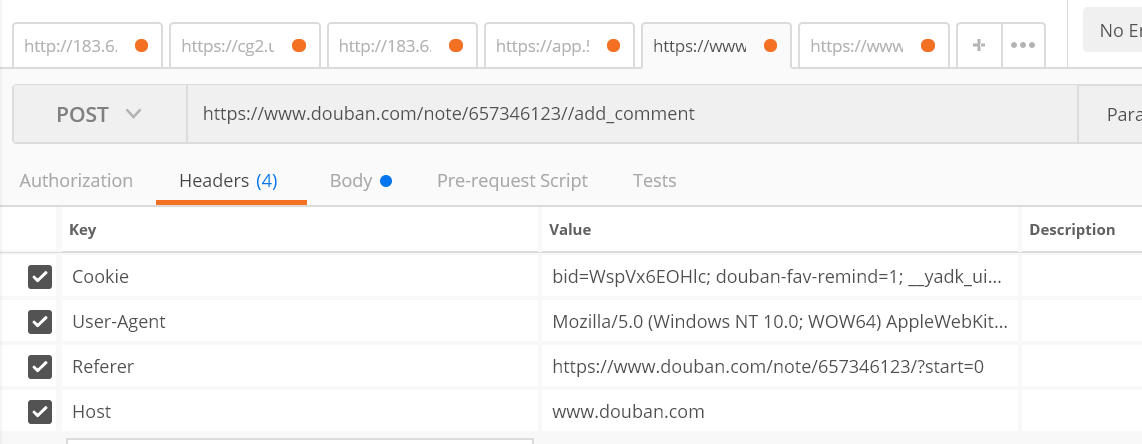
而body这块,虽然上面抓包看到有4个参数,但是实际验证只需要2个即可,发送的内容就是jbtest;
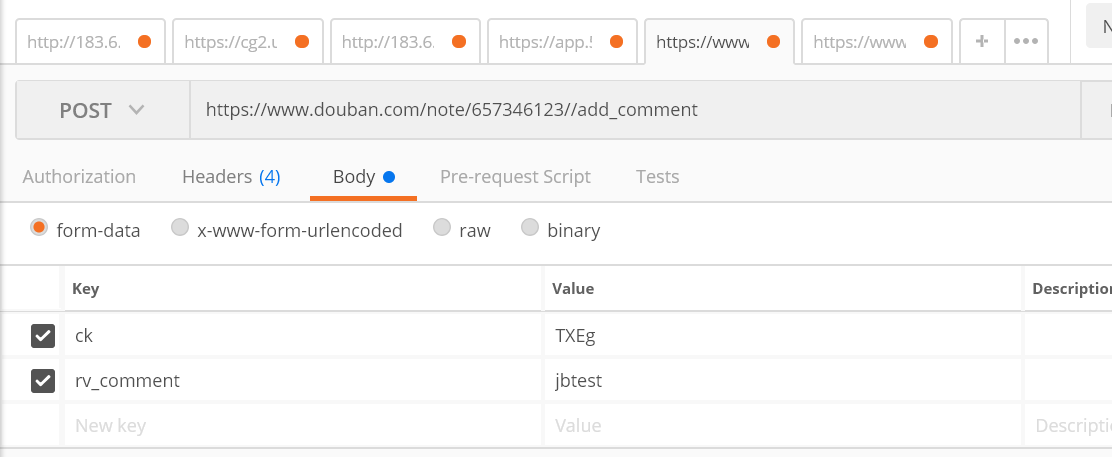
那在postman上点击send,然后在那个帖子上刷新下页面,居然能看到刚刚回复的内容
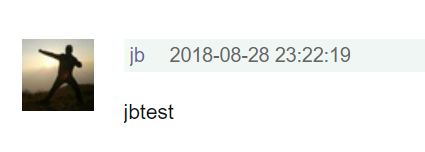
看来,豆瓣回复功能只需要调接口就行了,都不用selenium了;
既然如此,不能写出下面这代码:
import requests
#豆瓣具体帖子回复的接口,格式是帖子链接+/add_comment
db_url = "https://www.douban.com/group/topic/121989778//add_comment"
headers = {
"Host": "www.douban.com",
"Referer": "https://www.douban.com/group/topic/121989778/?start=0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Cookie":"your cookie" #这里需要输入你自己的cookie信息,如果遇到转义字符,转
义字符前面加\即可
}
params = {
"ck": "TXEg",
"rv_comment": "jbtest11111",#或者替换成想评论的东西
}
requests.post(db_url,headers=headers, data=params)
上面的代码就是定义请求头跟body参数,像豆瓣的评论接口发一个请求即可,运行下脚本,刷新下网页:
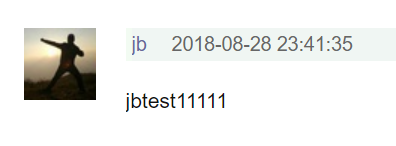
没问题,回复功能多简单,so easy;
自动功能
嗯,回复功能可以了,那Python有没有类似定时器的功能?定时执行上面的post请求就好了?
答案是有的,那就是APScheduler;
APScheduler简介
APScheduler是Python的一个定时任务框架,可以很方便的满足用户定时执行或者周期执行任务的需求,
它提供了基于日期date、固定时间间隔interval 、以及类似于Linux上的定时任务crontab类型的定时任务。
并且该框架不仅可以添加、删除定时任务,还可以将任务存储到数据库中,实现任务的持久化,所以使用起来非常方便。
官方简介链接:apscheduler.readthedocs.io/en/3.3.1/
安装
1)利用pip安装:(推荐)
pip install apscheduler
2)基于源码安装:pypi.python.org/pypi/APSche…
python setup.py install
4种组件
APScheduler有四种组件:
1)triggers(触发器):
触发器包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行,除了他们自己初始化配置外,触发器完全是无状态的。
2)job stores(作业存储):
用来存储被调度的作业,默认的作业存储器是简单地把作业任务保存在内存中,其它作业存储器可以将任务作业保存到各种数据库中,支持MongoDB、Redis、SQLAlchemy存储方式。
当对作业任务进行持久化存储的时候,作业的数据将被序列化,重新读取作业时在反序列化。
3)executors(执行器):
执行器用来执行定时任务,只是将需要执行的任务放在新的线程或者线程池中运行。
当作业任务完成时,执行器将会通知调度器。
对于执行器,默认情况下选择ThreadPoolExecutor就可以了,但是如果涉及到一下特殊任务如比较消耗CPU的任务则可以选择ProcessPoolExecutor,当然根据根据实际需求可以同时使用两种执行器。
4)schedulers(调度器):
调度器是将其它部分联系在一起,一般在应用程序中只有一个调度器,应用开发者不会直接操作触发器、任务存储以及执行器,相反调度器提供了处理的接口。
通过调度器完成任务的存储以及执行器的配置操作,如可以添加。修改、移除任务作业。
APScheduler提供了多种调度器,常用的调度器有:
| 名称 | 场景 |
|---|---|
| BlockingScheduler | 适合于只在进程中运行单个任务的情况 |
| BackgroundScheduler | 适合于要求任何在程序后台运行的情况 |
| AsyncIOScheduler | 适合于使用asyncio框架的情况 |
| GeventScheduler | 适合于使用gevent框架的情况 |
| TornadoScheduler | 适合于使用Tornado框架的应用 |
| TwistedScheduler | 适合使用Twisted框架的应用 |
| QtScheduler | 适合使用QT的情况 |
简单的例子
from apscheduler.schedulers.blocking import BlockingScheduler
import time
# 实例化一个调度器
scheduler = BlockingScheduler()
def job1():
print "%s: 执行任务" % time.asctime()
# 添加任务并采用固定时间间隔,触发方式为3s一次
scheduler.add_job(job1, 'interval', seconds=3)
# 开始运行调度器
scheduler.start()
执行后的效果:

很简单有没有,先初始化,然后add_job,最后start就好了,那下面,再详细讲解下不同组件提供的功能吧;
定时任务
trigger提供任务的触发方式,共有3种方式:
-
date:只在某个时间点执行一次,用法:run_data(datetime|str)
scheduler.add_job(my_job, 'date', run_date=date(2017, 9, 8), args=[]) scheduler.add_job(my_job, 'date', run_date=datetime(2017, 9, 8, 21, 30, 5), args=[]) scheduler.add_job(my_job, 'date', run_date='2017-9-08 21:30:05', args=[]) sched.add_job(my_job, args=[[])
- interval: 每隔一段时间执行一次,用法:weeks=0 | days=0 | hours=0 | minutes=0 | seconds=0, start_date=None, end_date=None, timezone=None
scheduler.add_job(my_job, 'interval', hours=2) scheduler.add_job(my_job, 'interval', hours=2, start_date='2017-9-8 21:30:00', end_date= '2018-06-15 21:30:00)
@scheduler.scheduled_job('interval', id='my_job_id', hours=2) def my_job(): print("Hello World")
- cron: 使用同linux下crontab的方式,即定时任务;,用法:(year=None, month=None, day=None, week=None, day_of_week=None, hour=None, minute=None, second=None, start_date=None, end_date=None, timezone=None)
sched.add_job(my_job, 'cron', hour=3, minute=30) sched.add_job(my_job, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2017-10-30')
@sched.scheduled_job('cron', id='my_job_id', day='last sun') def some_decorated_task(): print("I am printed at 00:00:00 on the last Sunday of every month!")
一般来说,使用的比较多的是interval方式,可以重点留意下;
定时任务实战
1)APScheduler怎么设置范围时间任务,比如我想要在10:00~11:00这个范围的时间内随机一个时间点去执行任务
print(get_time()+"jbtest")
t= random.randint(1,10) # # 1~10秒随机
scheduler.add_job(myjob, 'interval', seconds=t,start_date='2018-09-05 10:00:00', end_date='2018-09-05 11:00:00') # 估计就满足你的需求了吧
scheduler.start()
2)如果不想具体的时间,而是某个范围的话:
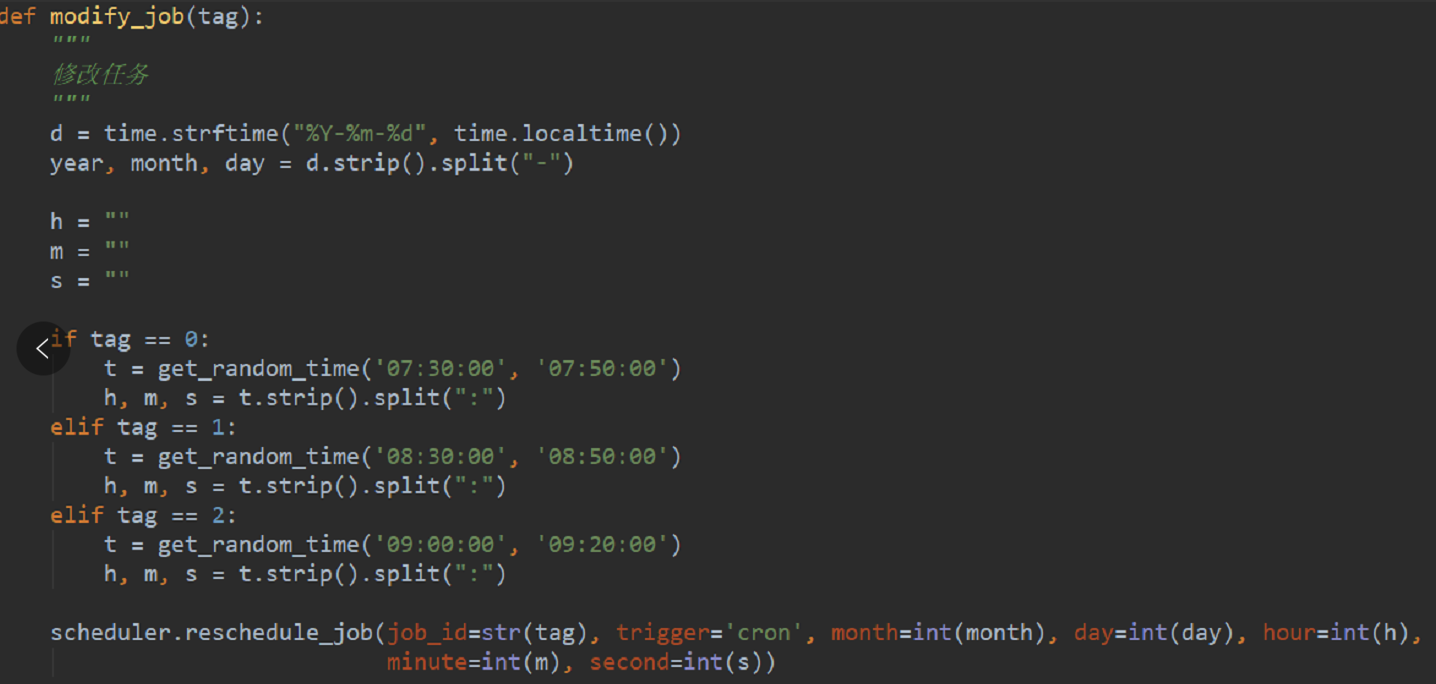
3)区间直接 sched.scheduled_job('cron', day_of_week='mon-fri', hour='0-9', minute='30-59', second='*/3') 在周一到周五其间,每天的0点到9点之间,在30分到59分之间执行,执行频次为3秒。
任务操作
添加任务add_job
add_job可以返回一个apscheduler.job.Job实例,因而可以对它进行修改或者删除,而使用修饰器添加的任务添加之后就不能进行修改。
获得任务列表get_jobs
可以通过get_jobs方法来获取当前的任务列表,也可以通过get_job()来根据job_id来获得某个任务的信息。
并且apscheduler还提供了一个print_jobs()方法来打印格式化的任务列表。
scheduler.add_job(my_job, 'interval', seconds=5, id='my_job_id' name='test_job')
print scheduler.get_job('my_job_id')
print scheduler.get_jobs()
修改任务 modify_job
修改任务的属性可以使用apscheduler.job.Job.modify()或者modify_job()方法,可以修改除了id的其它任何属性。
job = scheduler.add_job(my_job, 'interval', seconds=5, id='my_job' name='test_job')
job.modify(max_instances=5, name='my_job')
删除任务remove_job
删除调度器中的任务有可以用remove_job()根据job ID来删除指定任务或者使用remove(),
如果使用remove()需要事先保存在添加任务时返回的实例对象,任务删除后就不会在执行。
# 根据任务实例删除
job = scheduler.add_job(myfunc, 'interval', minutes=2)
job.remove()
# 根据任务id删除
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
scheduler.remove_job('my_job_id')
任务的暂停pause_job和继续resume_job
暂停与恢复任务可以直接操作任务实例或者调度器来实现。
当任务暂停时,它的运行时间会被重置,暂停期间不会计算时间。
job = scheduler.add_job(myfunc, 'interval', minutes=2)
# 根据任务实例
job.pause()
job.resume()
# 根据任务id暂停
scheduler.add_job(myfunc, 'interval', minutes=2, id='my_job_id')
scheduler.pause_job('my_job_id') # 暂停
scheduler.resume_job('my_job_id') #恢复
任务的修饰modify和重设reschedule_job
修饰:job.modify(max_instances=6, name='Alternate name')
重设:scheduler.reschedule_job('my_job_id', trigger='cron', minute='*/5')
调度器操作
开启 scheduler.start()
可以使用start()方法启动调度器,BlockingScheduler需要在初始化之后才能执行start(),
对于其他的Scheduler,调用start()方法都会直接返回,然后可以继续执行后面的初始化操作
from apscheduler.schedulers.blocking import BlockingScheduler
def my_job():
print "Hello world!"
scheduler = BlockingScheduler()
scheduler.add_job(my_job, 'interval', seconds=5)
scheduler.start()
关闭 scheduler.shotdown(wait=True | False)
使用下边方法关闭调度器:
scheduler.shutdown()
默认情况下调度器会关闭它的任务存储和执行器,并等待所有正在执行的任务完成,如果不想等待,可以进行如下操作:
scheduler.shutdown(wait=False)
暂停 scheduler.pause()
继续 scheduler.resume()
豆瓣自动回复
看了那么多APScheduler的简介,上面也有例子了,结合第一部分豆瓣的例子,不难写出下面的代码:
import requests
from apscheduler.schedulers.blocking import BlockingScheduler
#豆瓣具体帖子回复的接口,格式是帖子链接+/add_comment
db_url = "https://www.douban.com/group/topic/121989778//add_comment"
scheduler = BlockingScheduler()
headers = {
"Host": "www.douban.com",
"Referer": "https://www.douban.com/group/topic/121989778/?start=0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/68.0.3440.106 Safari/537.36",
"Cookie":"your cookie" #这里需要输入你自己的cookie信息,如果遇到转义字符,转
义字符前面加\即可
}
params = {
"ck": "TXEg",
"rv_comment": "jbtest11111",
}
def my_job():
requests.post(db_url,headers=headers, data=params)
#每隔10S就请求一次
scheduler.add_job(my_job,"interval",seconds=10,id="db")
scheduler.start()
效果如下:
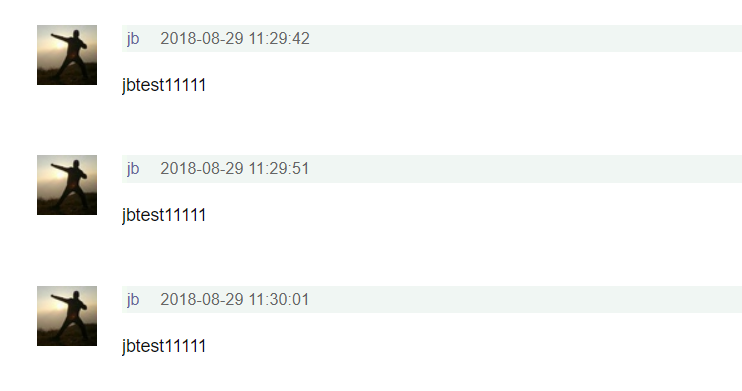
的确是每隔10S发送一次,good~
做到这里,你以为完事了?
嗯,怎么说呢,如果是一个帖子的话,是完事了,但是如下是以下2种场景之一,还需要折腾:
1)同一个帖子,需要短时间内回复,这个短时间没法定义,可能
几分钟都算,除非是像正常用户几个小时回复一次就可能没问题;
2)N个帖子都要回复,而且回复间隔比较短,类似问题1;
那这两种情况,会导致什么问题?当然是触发豆瓣的防爬虫啦:
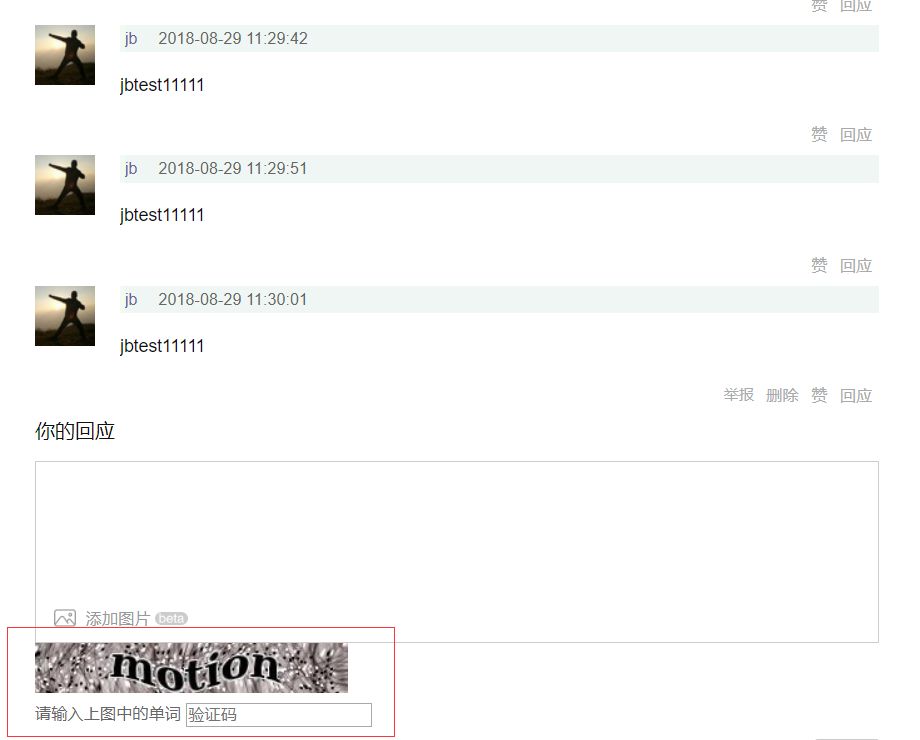
目前发现,每次评论就算相隔1分钟,只要满3次,就一定会弹出这个验证码进行验证;
获取验证码ID
按照一开始的套路,那我们F12看下输入验证码后发起请求的参数:
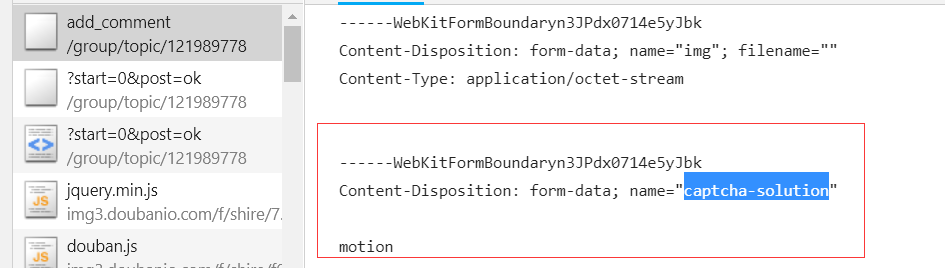
验证码信息:
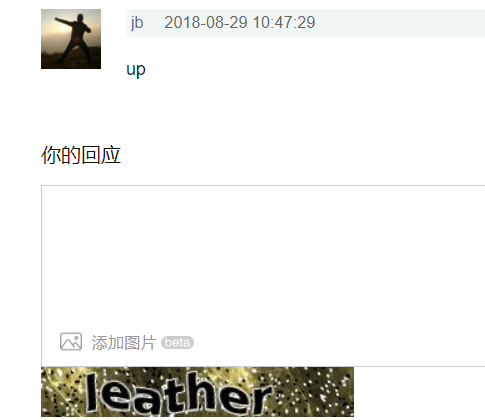
postman请求内容:
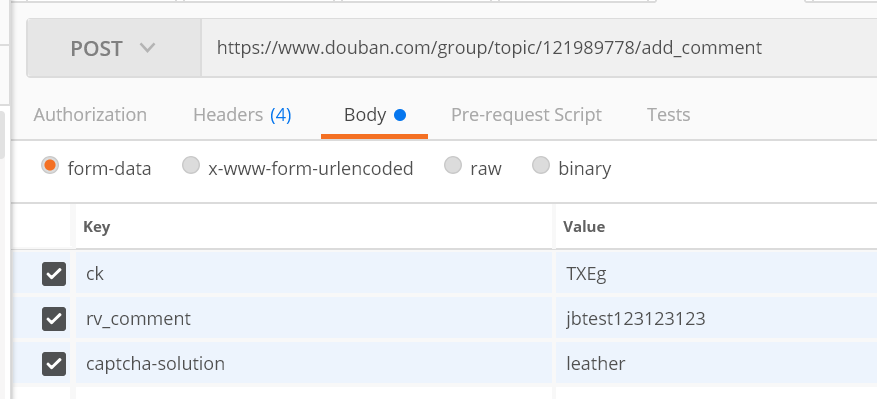
点击send,然后原来的网页刷新一下,结果如下:
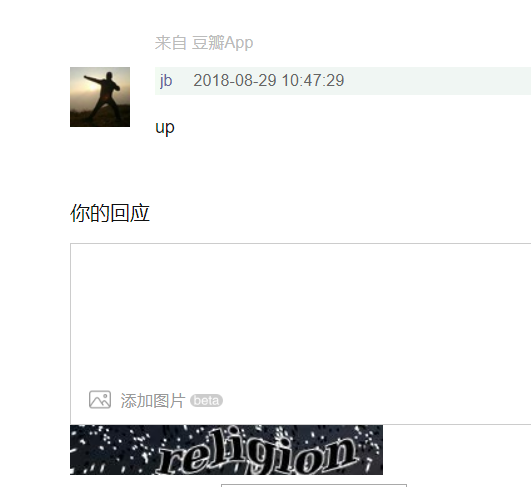
对的,内容没有变,因为这样肯定是不生效的,哪有那么容易;
验证码场景:
现在有网址T,有用户A和B两个人同事访问T
T给A返回的验证码是X,给B返回的验证码是Y,这两个验证码都正确
如果A输入B的验证码,是验证不通过的
那服务器怎么区分A和B?那就是用cookie;
cookie是标示唯一身份的,比如有些网站,登录一次后会自动登录,但是如果清除了cookie,就无法自动登录了,而且这cookie是个别人不一样的; 说到这里,服务器后台生成验证码的流程就很容易理解了:
先随机生产一个随机字符串
然后和cookie绑定
再写到图片上返回给你
更多的验证码生成信息,可以读一下这篇文章;
此时,可能你有疑问,用postman的时候,cookie应该是跟PC点击发送是一样的,但是为什么还不行?
因为cookie只是最简单的绑定条件,这么看来,豆瓣还有其他条件的,那我们重新看一下,PC点击发送的时候,除了验证码,还有发送什么?
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="ck"
TXEg
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="rv_comment"
反反复复
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="img"; filename=""
Content-Type: application/octet-stream
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="captcha-solution"
produce
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="captcha-id"
woMrwYOVwn67NNfl9lv9vhRz:en
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="start"
0
------WebKitFormBoundaryDjMAMsD95W3eYF1i
Content-Disposition: form-data; name="submit_btn"
发送
------WebKitFormBoundaryDjMAMsD95W3eYF1i--
上面这些信息都是点击发送时,请求里面的body,大致看了下,之前分析的时候,少了captcha-id这个参数,猜测这是就是关键;
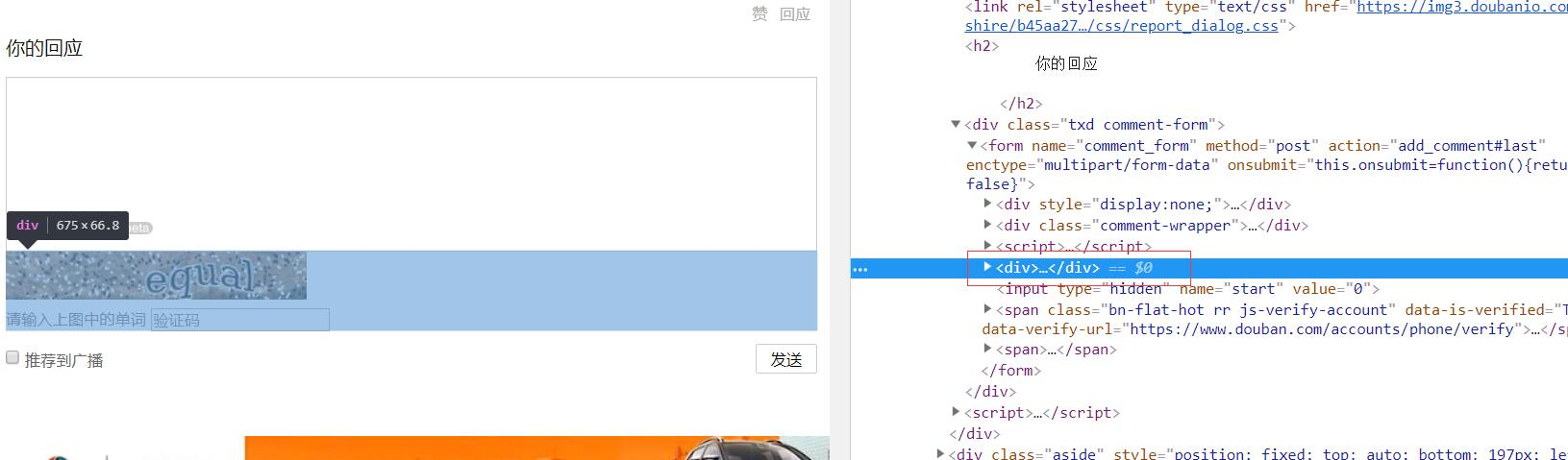
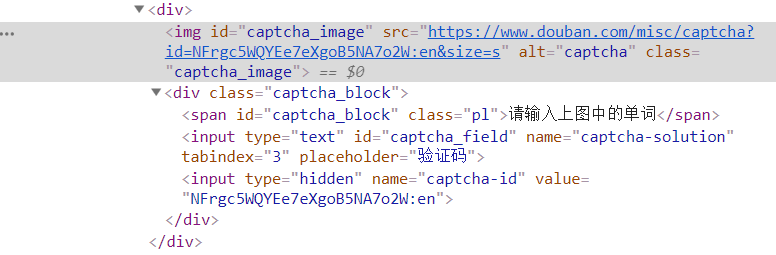
简单尝试了下,发现这个captcha-id每次都会不一样,而且从请求里面也看不出啥,既然这个ID可能跟验证码有绑定关系,那我们就解析下这个网页的结构,看下能不能找到这个字段?
点击F12,定位到验证码这块:

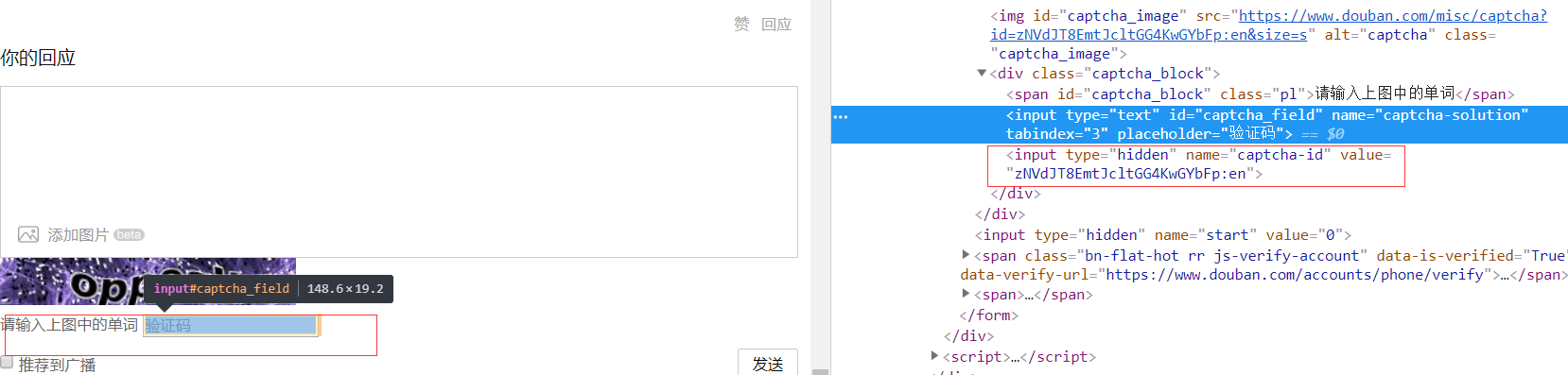
一定位到输入验证码的框里面,嘤嘤嘤,看发现了啥,这不就是想要的captcha-id吗?

爱是怀疑,那我们就来用postman验证一下吧;
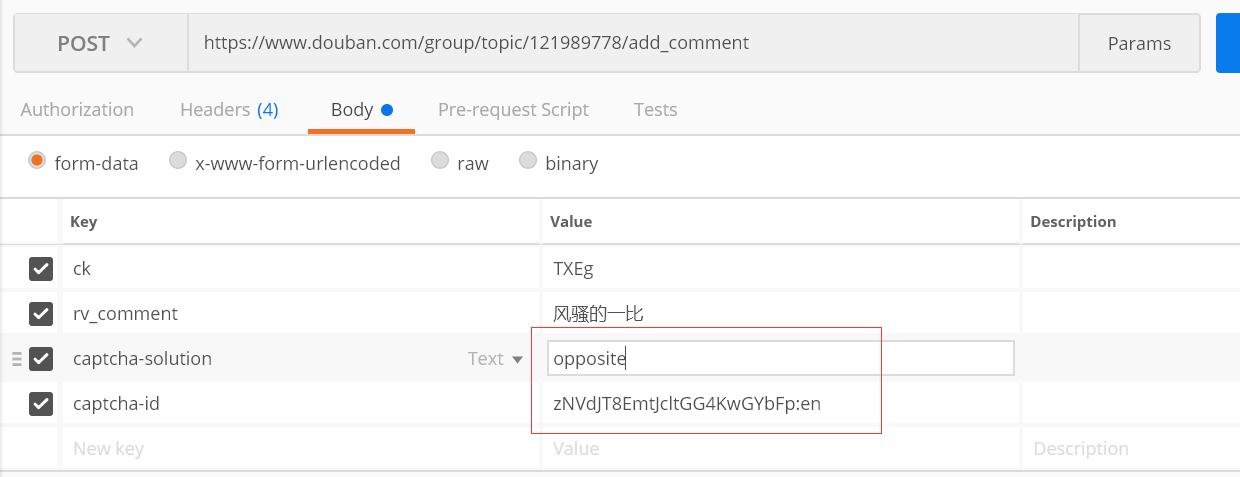
哈哈哈哈,可以了,再次嘤嘤嘤~
那现在的逻辑,应该是修改成这样:
1)打开帖子页面,判断是否需要输入验证码,如果需要,获取captcha-id跟验证码,
然后post请求captcha-id和验证码
2)如果不需要输入验证码,那就直接post请求即可
既然如此,对比下需要输入验证码跟不需要验证码时的网页结构吧;
需要验证码:
不需要验证码:
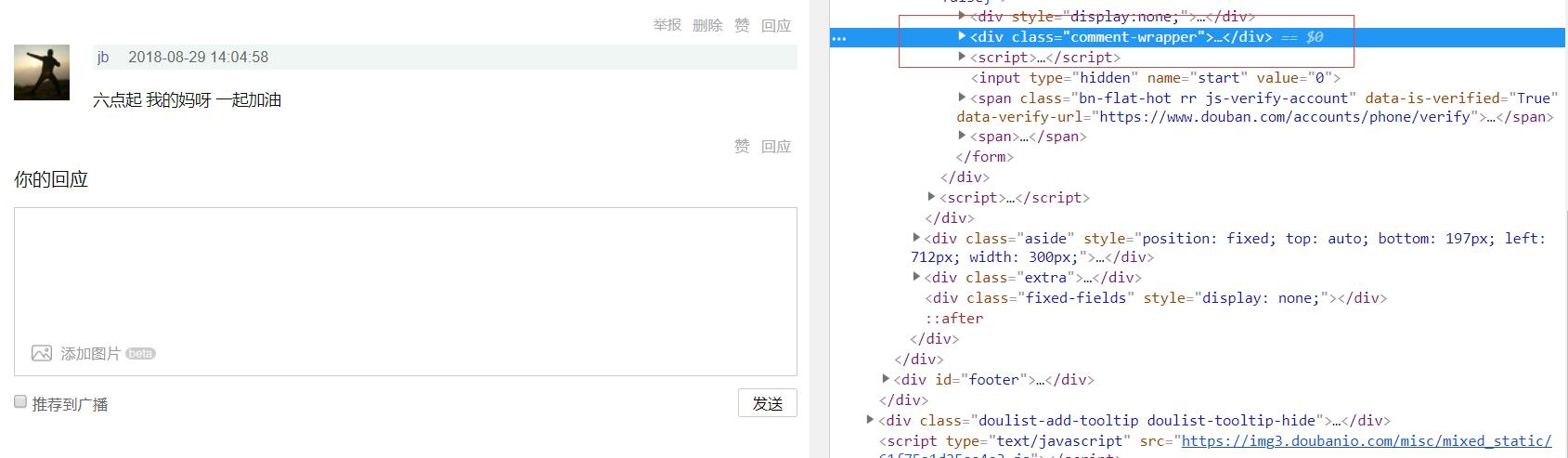
对比可知,需要输入验证码的时候,会多了一个div标签,这个div标签展开了,二维码的下载链接也能找到,captcha-id也能找到,既然如此,使用xpath就能判断了,判断captcha_image,如果能获取到,就是需要验证码;
简单做了下实验,看看能不能获取到这个captcha,有以下代码:
import requests
from lxml import html
response = requests.get(db_url).content
selector = html.fromstring(response)
captcha = selector.xpath("//img[@id=\"captcha_image\"]/@src")
print(captcha)
但是结果返回的是[],意思就是没有获取到这个值
把response打印出来,真的是没有这个值,这里且慢,一开始JB的想法是,没有这个值,就说明这块数据是JS生成的,那我们研究看下怎么获取JS生成的网页数据,然后就霹雳吧啦的介绍selenium;
事实证明,并不需要那么复杂(浪费了半天时间了。。),还是上面这串代码:
import requests
from lxml import html
response = requests.get(db_url,verify=False).content
print(response)
把response打印出来,结果发现内容长这样:
response = requests.get(db_url,verify=False).content.decode()
效果图,这样就能看到中文了:
这个解决方案,花了半天无意发现的,算是get 到一个小点了,以后request后一定要decode,不用还用selenium就跑远了;
获取二维码下载地址
按照下面的内容,就可以写出这样的代码:
response = requests.post(db_url,headers=headers, data=params,verify=False).content.decode()
selector = html.fromstring(response)
captcha = selector.xpath("//img[@id=\"captcha_image\"]/@src")
print(captcha)
然后再想需要回复的帖子回复三次,让验证码出现,然后再执行这个脚本,不然验证码不出现,就会获取为[]的:

这样,就能获取到验证码图片啦,按照上面说的,如果是有验证码,就获取图片链接跟验证码ID,如果没有,则直接post请求,因此不难写出下面的代码;
import requests
from apscheduler.schedulers.blocking import BlockingScheduler
from lxml import html
# 豆瓣具体帖子链接
db_url = "https://www.douban.com/note/657346123/"
# 豆瓣具体帖子回复的接口,格式是帖子链接+/add_comment
db_url_commet = "https://www.douban.com/note/657346123///add_comment"
scheduler = BlockingScheduler()
headers = {
"Host": "www.douban.com",
"Referer": "https://www.douban.com/group/topic/121989778/?start=0",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"Cookie":"your cookie" #这里需要输入你自己的cookie信息,如果遇到转义字符,转
义字符前面加\即可
}
params = {
"ck": "TXEg",
"rv_comment": "jbtest11111",
}
def my_job():
# 获取网页信息
response = requests.post(db_url, headers=headers, data=params, verify=False).content.decode()
selector = html.fromstring(response)
captcha_image = selector.xpath("//img[@id=\"captcha_image\"]/@src")
if(captcha_image):
print(captcha_image)
captcha_id = selector.xpath("//input[@name=\"captcha-id\"]/@value")
print(captcha_id)
else:
# 发起请求请求
requests.post(db_url_commet, headers=headers, data=params, verify=False)
# 每隔10S就请求一次
scheduler.add_job(my_job, "interval", seconds=2, id="db")
scheduler.start()
效果图:

Ok,这样就能获取到二维码图片跟图片对应的ID了,那接下来要干嘛?
识别二维码
既然能获取二维码图片,而请求的时候又要带上这个字段,那就意味着,必须先下载这个图片,然后去识别这种图片,然后放到请求上一起提交;
下载图片&命名:
import requests
import re
i = "https://www.douban.com/misc/captcha?id=9iGoXeJXeos3E1JukgkltEVp:en&size=s"
captcha_name = re.findall("id=(.*?):",i) #findall返回的是一个列表
filename = "douban_%s.jpg" % (str(captcha_name[0]))
print("文件名为:"+filename)
#创建文件名
with open(filename, 'wb') as f:
#以二进制写入的模式在本地构建新文件
header = {
'User-Agent': '"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",'
,'Referer': i}
f.write(requests.get(i,headers=header).content)
print("%s下载完成" % filename)
# urllib.request.urlretrieve(requests.get(i,headers=header), "%s%s%s.jpg" %
(dir, image_title, num))
ok,此时图片下载完成了,比如上面下载的这张,是这样的验证码:

tesserocr
那我们要识别它,就先试试tesserocr的识别率如何,有关tesserocr的文章,请点击这里了解下,里面有详细简介,这里不重复说明:
import tesserocr
from PIL import Image
#新建Image对象
image = Image.open("5.jpg")
#进行置灰处理
image = image.convert('L')
#这个是二值化阈值
threshold = 4
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
#通过表格转换成二进制图片,1的作用是白色,不然就全部黑色了
image = image.point(table,"1")
image.show()
#调用tesserocr的image_to_text()方法,传入image对象完成识别
result = tesserocr.image_to_text(image)
print(result)
经过多次调试处理,发现把二值化阈值调到4,是最优的效果,二值化后的验证码长这样:

啧啧啧,这样定制的二值化都不行,就不再尝试了,不然每个图片都这么定制化去做,还得做?
百度OCR
既然tesserocr效果不好,那就试试百度的OCR吧,(有关百度OCR的文章,请点击这里查看):
from aip import AipOcr
from PIL import Image
import os
""" 你的 APPID AK SK """
config = {
"appId": '',
"apiKey":'',
"secretKey":''
}
client = AipOcr(**config)
""" 读取图片 """
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
def get_image_str(image_path):
image = get_file_content(image_path)
""" 调用通用文字识别, 图片参数为本地图片 """
result = client.basicAccurate(image)
#结果拼接返回输出s
if 'words_result' in result:
return ''.join([w['words'] for w in result['words_result']])
if __name__ == "__main__":
print(get_image_str("5.jpg"))
直接运行后的结果:
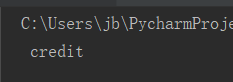
啧啧啧,果然是BAT,果然是高精准的,能识别呢,那我们继续试试不同验证码,结果发现,下面这张运行后,什么都识别不出来(看来也不是万能的);

既然如此,那我们把刚刚tesserocr的二值化处理放到这里,会不会有效果?代码如下:
""" 读取图片 """
def get_file_content(filePath):
# 新建Image对象
image = Image.open(filePath)
# 进行置灰处理
image = image.convert('L')
threshold = 15
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
# 通过表格转换成二进制图片,1的作用是白色,不然就全部黑色了
image = image.point(table, "1")
image.save(os.path.join(os.getcwd(), os.path.basename(filePath)))
with open(filePath, 'rb') as fp:
return fp.read()
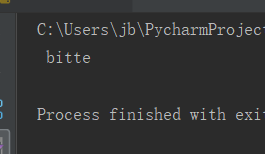
执行后发现,识别率还是感人,其实之前也测试过,这种验证码的确存在部分记录失败的情况:
既然百度(免费)的都不行,那我们就换个收费吧,收费的打码平台,数超级鹰名气比较大了;
超级鹰
官网地址:www.chaojiying.com/
打开官网,有个免费测试,点击后发现要登录,那就先注册了;
结果发现那个免费测试还是要题分,要关注公众号绑定账号才送1000题分,这个就是免费测试,懒得折腾,直接充钱吧;
超级鹰是按量级收费,量大便宜,标准价格:1元=1000题分,不同验证码类型,需要的题分不一样,详情可以到这里查询:www.chaojiying.com/price.html#
充值后,返回到刚刚那个免费测试界面进行测试
等待一会,网页就会有弹窗:
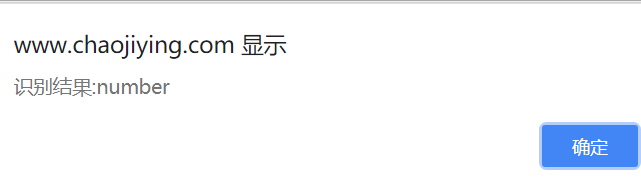
上传的验证码如下:

对比下,结果完全正确,收费的果然牛逼,这个也是连百度的都搞不定的;
那我们换一种微博的验证码:

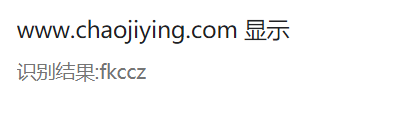
啧啧啧,无难度啊;

超级鹰也支持接入,首页底部有个api文档说明,点击进去发现支持各种语言,找到Python,把demo下载下来,api文档链接:www.chaojiying.com/api-14.html
源码是基于2.X写的,不难看懂,但是网上有同学重新整理下,简洁很多,就把这个代码贴出来吧,作者:coder-pig:
from hashlib import md5
import requests
# 超级鹰参数
cjy_params = {
'user': '448975523',
'pass2': md5('你的密码'.encode('utf8')).hexdigest(),
'softid': '96001',
}
# 超级鹰请求头
cjy_headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
# 超级鹰识别验证码
def cjy_fetch_code(im, codetype):
cjy_params.update({'codetype': codetype})
files = {'userfile': ('ccc.jpg', im)}
resp = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=cjy_params, files=files,
headers=cjy_headers).json()
# 错误处理
if resp.get('err_no', 0) == 0:
return resp.get('pic_str')
# 调用代码
if __name__ == '__main__':
im = open('captcha.jpg', 'rb').read()
print(cjy_fetch_code(im, 1902))
执行后,发现验证码是对的,同时,一次请求大概是3S左右;

ok,验证码破解这块就到这里了,想接入超级鹰、百度,tesserocr,又或者是自己写个人工智能算法,任君选择;
豆瓣自动回复功能-终
为了效果着想,这里采用了超级鹰来破解,先看看log:
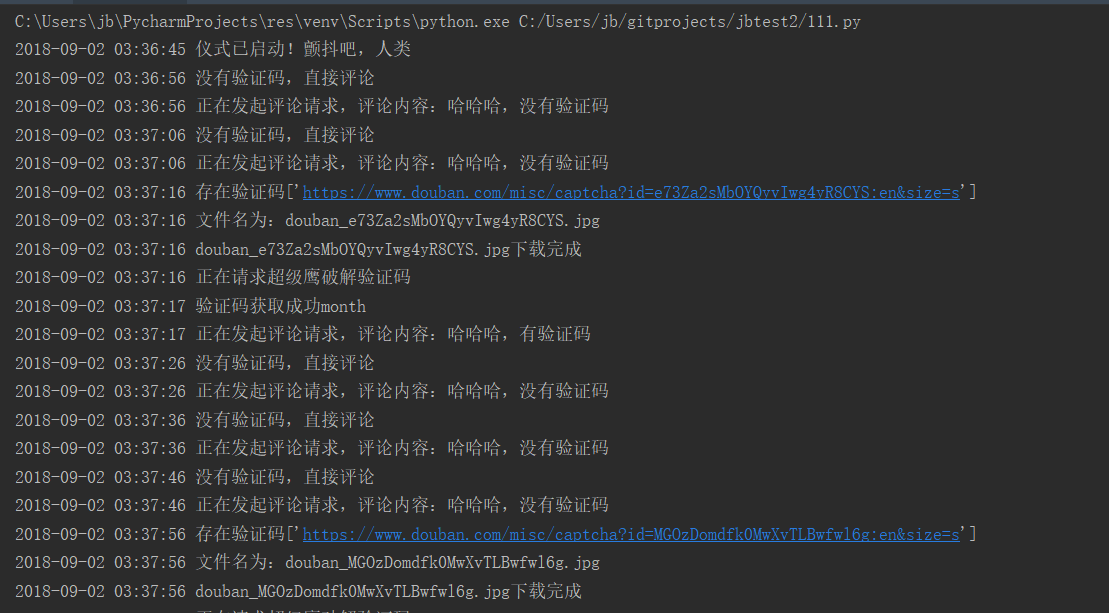
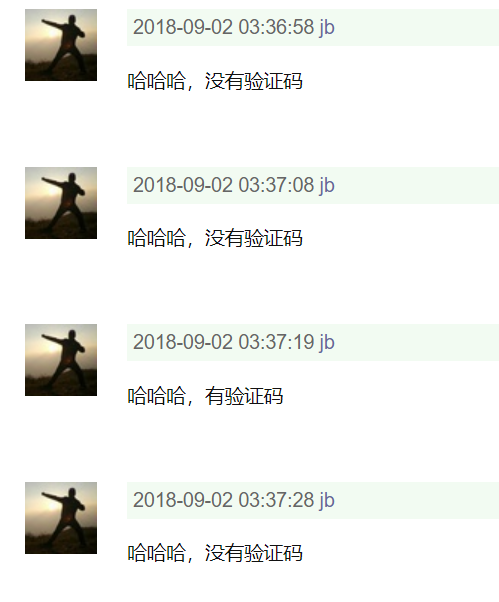
从豆瓣记录上看,嗯,破解了,good;
上面整合下就是所有的代码了;
还可以有的小优化
是不是这样就完了?
非也,因为现在我们用的是收费的,所以验证码的准确率由超级鹰担保了,但是假如用免费的,识别率感人,从用户角度,会关心哪些验证码失败,希望有个通知,此时就可以接入server酱,一旦验证码验证失败就微信通知,效果如下:

感兴趣的可以去server酱官网了解下:sc.ftqq.com/3.version
18.9.13更新
今天执行脚本发现,脚本没有报错,但是呢,执行后不会生效(对应帖子没有相关评论,而且也不会出现验证码),jb,一脸懵逼,然后用postman尝试也不行,后来通过网页模拟及postman一步步模拟后,发现问题根源是,请求的时候,body的ck字段的内容是会变化的,之前默认是写着:
"ck": "TXEg"
也许有同学好奇什么时候会变化,经测试发现,当用户退出登录后,这个字段就会变化,而对于脚本来说,肯定不会出去啦,那就转化成当cookie失效时,这个字段的内容会发生变化;
而cookie失效的解决方案也是用的,用selenium每次登录获取cookie,这样就不会存在cookie失效的情况了,但这里不介绍这点,后面在写selenium的时候再介绍;
这里会简单介绍下ck的值怎么获取的;
在网页上模拟评论,然后能获得ck的值,然后复制,去到网页的HTML搜索,就会出现这个值是怎么获取的了;
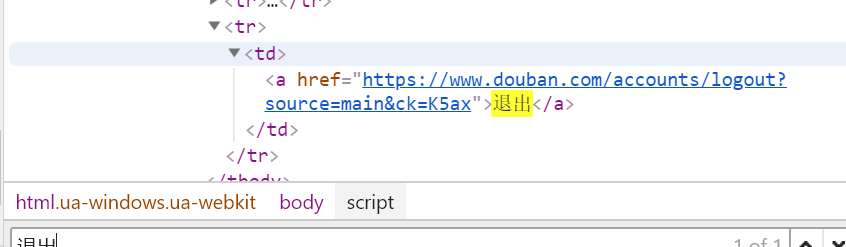
没错,就是退出按钮url的最后4个字母,这里的话,用xpath获取到这个url,再获取这4个字母就好了;
于是乎写了个xpath
selector.xpath("//div/ul/li/div/table/tbody/tr/td/a/@href")
结果发现,怎么拿都拿不到,后来response.content的内容输出看了下,的确没发现这个退出按钮的代码;
这就意味着,这块是JS生成的,想获取JS生成后的HTML,目前只能用selenium,但是这里还有个问题,selenium想拼接一个自定义的cookie是非常非常的麻烦,之前折腾很久都不行,所以这条路就放弃了;
既然selenium不指望了,那是不是还有其他法子? 所以就拿ck这个key一路去找,结果发现cookie上有这个值:
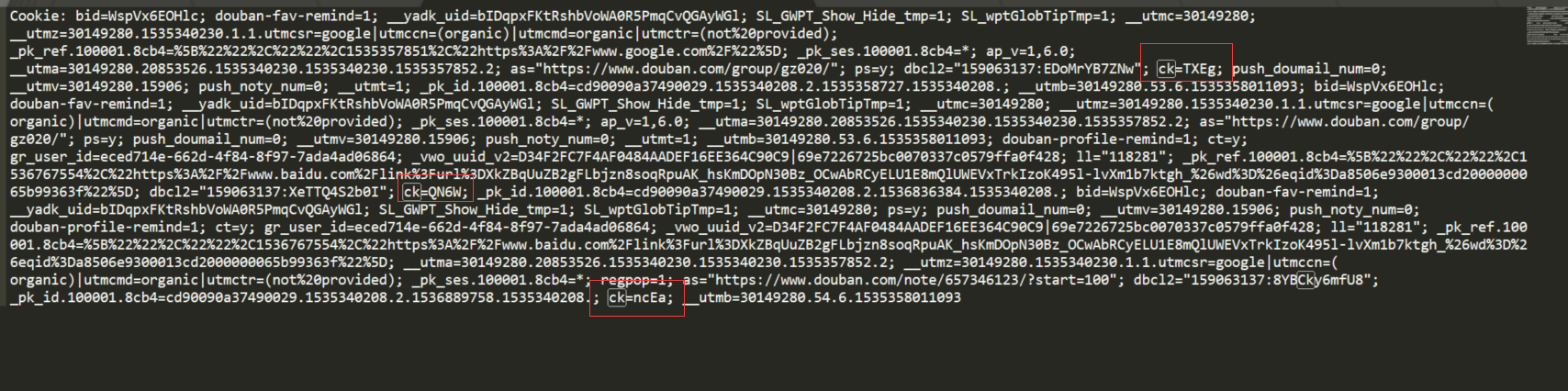
这里面有3个值,第一个就是之前代码hardcore的内容,对比了下,我们要的值是最后一个ck的value,也做了几个重新登录的操作,如果cookie最后一个ck值变的话,那这个退出按钮的ck值也会跟着变,抛开cookie过期的想法,ck这个就直接获取cookie的最后一个ck内容;
#获取ck对应的value,通过cookie获取最后一个ck的值
def get_ck():
# 这个废了,不能用selenium
# ck_value = selector.xpath("//div/ul/li/div/table/tbody/tr/td/a/@href")
text = re.findall("ck=(.*?);",headers["Cookie"])[-1]
return text
久违的自动顶贴又回来了
小结
呼,奋斗到4点,终于撸完了,其实自动回帖功能很简单,周一下午看到,当天晚上就搞定了,然后在折腾验证码的问题,包括想尝试调优,不用收费的,结果折腾好几晚读不行,
再然后就是response的html代码问题,一开始以为是js加载的,结果发现是需要decode,跟JS一点关系都没有,其中还有一晚是整理selenium的知识,因为当时认为跟JS有关系,就搞这玩意,后面会看一本selenium的事,再整一篇selenium介绍文字吧;
回到文章,本文介绍的内容比较多,大概分为3块如下:
1)如何分析豆瓣评论接口;
2)介绍python定时任务框架APScheduler
3)验证码破解(tesserocr、百度OCR、超级鹰)
其实也没什么特别好讲的,很简单的东西,只是繁琐而已,之所以花那么多时间,是思维被扩散了,就这样吧,谢谢大家;