

1 基本字段
DROP TABLE IF EXISTS `dictionary`;
CREATE TABLE `dictionary` (
`id` BIGINT(8) NOT NULL AUTO_INCREMENT COMMENT '主键',
`create_at` BIGINT(8) DEFAULT 0 COMMENT '创建时间',
`create_by` BIGINT(8) DEFAULT 0 COMMENT '创建人ID',
`create_name` VARCHAR(32) DEFAULT '' COMMENT '创建人名称',
`update_at` BIGINT(8) DEFAULT 0 COMMENT '更新时间',
`update_by` BIGINT(8) DEFAULT 0 COMMENT '更新人ID',
`update_name` VARCHAR(32) DEFAULT '' COMMENT '更新人名称',
`is_del` TINYINT(1) DEFAULT 0 COMMENT '是否删除',
`is_test` TINYINT(1) DEFAULT 0 COMMENT '是否测试',
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='字典';
2 核心军规
- 不在数据库做运算:CPU计算务必移至业务层;
- 控制单表数据量:含int型不超过1000w,含char则不超过500w;合理分表;限制单库表数量在300以内;
- 控制列数量:字段数控制在20以内;
- 平衡范式与冗余:为提高效率牺牲范式设计,冗余数据;
- 拒绝3B:拒绝大sql,大事务,大批量;
3 字段类军规
-
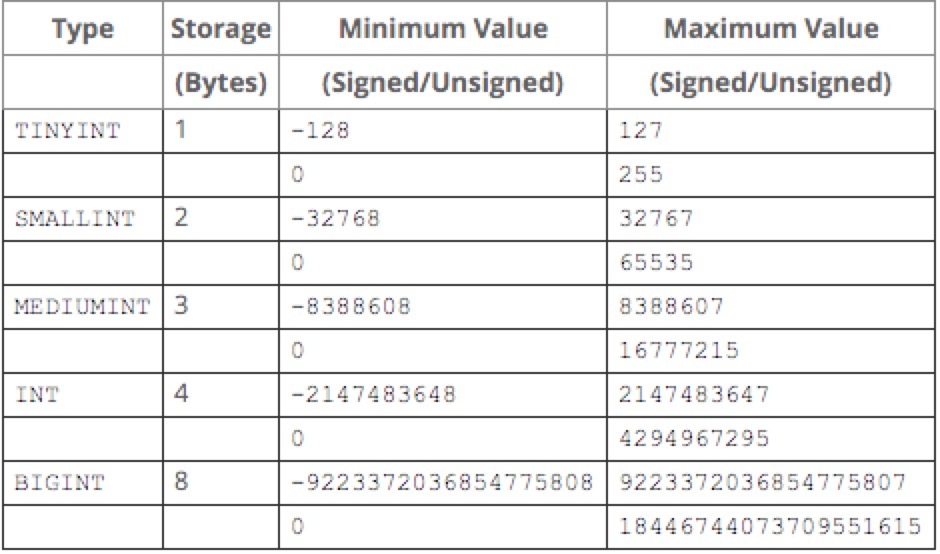
用好数值类型
tinyint(1Byte)
smallint(2Byte)
mediumint(3Byte)
int(4Byte)
bigint(8Byte)
**bad case:**int(1)/int(11)
-
字符转化为数字
用int而不是char(15)存储ip
-
优先使用enum或set
例如:
sexenum (‘F’, ‘M’) -
避免使用NULL字段
NULL字段很难查询优化
NULL字段的索引需要额外空间
NULL字段的复合索引无效
bad case:
namechar(32) default nullageint not nullgood case:
ageint not null default 0 -
少用text/blob
varchar的性能会比text高很多
实在避免不了blob,请拆表
-
不在数据库里存图片
4 索引类军规
-
谨慎合理使用索引
改善查询、减慢更新
索引一定不是越多越好(能不加就不加,要加的一定得加)
覆盖记录条数过多不适合建索引,例如“性别”
-
字符字段必须建前缀索引
-
不在索引做列运算
bad case:
select id where age +1 = 10;
-
innodb主键推荐使用自增列
主键建立聚簇索引
主键不应该被修改
字符串不应该做主键
如果不指定主键,innodb会使用唯一且非空值索引代替
-
不用外键
请由程序保证约束
5. SQL类军规
-
sql语句尽可能简单
一条sql只能在一个cpu运算
大语句拆小语句,减少锁时间
一条大sql可以堵死整个库
-
简单的事务
事务时间尽可能短
bad case:
上传图片事务
-
避免使用trig/func
触发器、函数不用
客户端程序取而代之
-
不用select *
消耗cpu,io,内存,带宽
这种程序不具有扩展性
-
OR改写为IN()
or的效率是n级别
in的效率是log(n)级别
in的个数建议控制在200以内
select id from t where phone=’159′ or phone=’136′;
改写成:
select id from t where phone in (’159′, ’136′);
-
OR改写为UNION
mysql的索引合并很弱智
select id from t where phone = ’159′ or name = ‘john’;
改写成:
select id from t where phone=’159′
union
select id from t where name=’jonh’
-
避免负向%
-
慎用count(*)
-
limit高效分页
limit越大,效率越低
select id from t limit 10000, 10;
改写成:
select id from t where id > 10000 limit 10;
-
使用union all替代union
union有去重开销
-
少用连接join
-
使用group by
分组
自动排序
-
请使用同类型比较
-
使用load data导数据
load data比insert快约20倍;
-
打散批量更新
-
性能分析工具
- show profile;
- mysqlsla;
- mysqldumpslow;
- explain;
- show slow log;
- show processlist;
- show query_response_time(percona)
