

简述: 好久没有发布原创文章,一如既往,今天开始Kotlin浅谈系列的第十讲,一起来探索Kotlin中的序列。序列(Sequences)实际上是对应Java8中的Stream的翻版。从之前博客可以了解到Kotlin定义了很多操作集合的API,没错这些函数照样适用于序列(Sequences),而且序列操作在性能方面优于集合操作.而且通过之前函数式API的源码中可以看出它们会创建很多中间集合,每个操作符都会开辟内存来存储中间数据集,然而这些在序列中就不需要。让我们一起来看看这篇博客内容:
- 1、为什么需要序列(Sequences)?
- 2、什么是序列(Sequences)?
- 3、怎么创建序列(Sequences)?
- 4、序列(Sequences)操作和集合操作性能对比
- 5、序列(Sequences)性能优化的原理
- 6、序列(Sequences)原理源码完全解析
1、为什么需要序列(Sequences)?
我们一般在Kotlin中处理数据集都是集合,以及使用集合中一些函数式操作符API,我们很少去将数据集转换成序列再去做集合操作。这是因为我们一般接触的数据量级比较小,使用集合和序列没什么差别,让我们一起来看个例子,你就会明白使用序列的意义了。
//不使用Sequences序列,使用普通的集合操作
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime}")
}
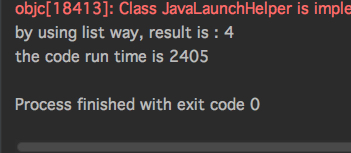
fun main(args: Array<String>) = computeRunTime {
(0..10000000)
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 10 }
.run {
println("by using list way, result is : $this")
}
}
运行结果:
//转化成Sequences序列,使用序列操作
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime}")
}
fun main(args: Array<String>) = computeRunTime {
(0..10000000)
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 10 }
.run {
println("by using sequences way, result is : $this")
}
}
运行结果:
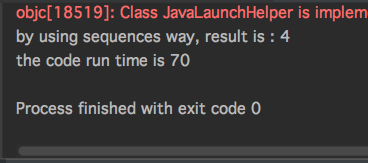
通过以上同一个功能实现,使用普通集合操作和转化成序列后再做操作的运行时间差距不仅一点点,也就对应着两种实现方式在数据集量级比较大的情况下,性能差异也是很大的。这样应该知道为什么我们需要使用Sequences序列了吧。
2、什么是序列(Sequences)?
序列操作又被称之为惰性集合操作,Sequences序列接口强大在于其操作的实现方式。序列中的元素求值都是惰性的,所以可以更加高效使用序列来对数据集中的元素进行链式操作(映射、过滤、变换等),而不需要像普通集合那样,每进行一次数据操作,都必须要开辟新的内存来存储中间结果,而实际上绝大多数的数据集合操作的需求关注点在于最后的结果而不是中间的过程,
序列是在Kotlin中操作数据集的另一种选择,它和Java8中新增的Stream很像,在Java8中我们可以把一个数据集合转换成Stream,然后再对Stream进行数据操作(映射、过滤、变换等),序列(Sequences)可以说是用于优化集合在一些特殊场景下的工具。但是它不是用来替代集合,准确来说它起到是一个互补的作用。
序列操作分为两大类:
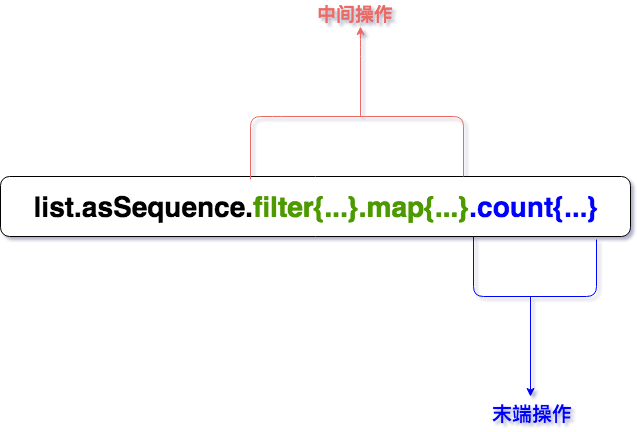
- 1、中间操作
序列的中间操作始终都是惰性的,一次中间操作返回的都是一个序列(Sequences),产生的新序列内部知道如何变换原始序列中的元素。怎样说明序列的中间操作是惰性的呢?一起来看个例子:
fun main(args: Array<String>) {
(0..6)
.asSequence()
.map {//map返回是Sequence<T>,故它属于中间操作
println("map: $it")
return@map it + 1
}
.filter {//filter返回是Sequence<T>,故它属于中间操作
println("filter: $it")
return@filter it % 2 == 0
}
}
运行结果:
以上例子只有中间操作没有末端操作,通过运行结果发现map、filter中并没有输出任何提示,这也就意味着map和filter的操作被延迟了,它们只有在获取结果的时候(也即是末端操作被调用的时候)才会输出提示。
- 2、末端操作
序列的末端操作会执行原来中间操作的所有延迟计算,欢聚,一次末端操作返回的是一个结果,返回的结果可以是集合、数字、或者从其他对象集合变换得到任意对象。上述例子加上末端操作:
fun main(args: Array<String>) {
(0..6)
.asSequence()
.map {//map返回是Sequence<T>,故它属于中间操作
println("map: $it")
return@map it + 1
}
.filter {//filter返回是Sequence<T>,故它属于中间操作
println("filter: $it")
return@filter it % 2 == 0
}
.count {//count返回是Int,返回的是一个结果,故它属于末端操作
it < 6
}
.run {
println("result is $this");
}
}
运行结果
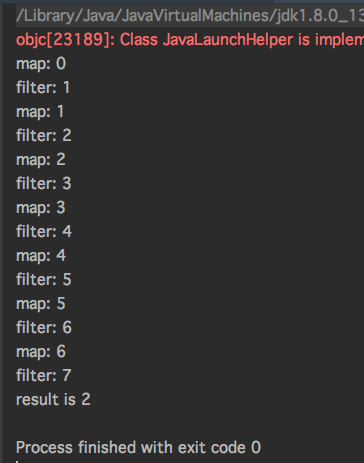
注意:判别是否是中间操作还是末端操作很简单,只需要看操作符API函数返回值的类型,如果返回的是一个Sequence<T>那么这就是一个中间操作,如果返回的是一个具体的结果类型,比如Int,Boolean,或者其他任意对象,那么它就是一个末端操作
3、怎么创建序列(Sequences)?
创建序列(Sequences)的方法主要有:
- 1、使用Iterable的扩展函数asSequence来创建。
//定义声明
public fun <T> Iterable<T>.asSequence(): Sequence<T> {
return Sequence { this.iterator() }
}
//调用实现
list.asSequence()
- 2、使用generateSequence函数生成一个序列。
//定义声明
@kotlin.internal.LowPriorityInOverloadResolution
public fun <T : Any> generateSequence(seed: T?, nextFunction: (T) -> T?): Sequence<T> =
if (seed == null)
EmptySequence
else
GeneratorSequence({ seed }, nextFunction)
//调用实现,seed是序列的起始值,nextFunction迭代函数操作
val naturalNumbers = generateSequence(0) { it + 1 } //使用迭代器生成一个自然数序列
- 3、使用序列(Sequence<T>)的扩展函数constrainOnce生成一次性使用的序列。
//定义声明
public fun <T> Sequence<T>.constrainOnce(): Sequence<T> {
// as? does not work in js
//return this as? ConstrainedOnceSequence<T> ?: ConstrainedOnceSequence(this)
return if (this is ConstrainedOnceSequence<T>) this else ConstrainedOnceSequence(this)
}
//调用实现
val naturalNumbers = generateSequence(0) { it + 1 }
val naturalNumbersOnce = naturalNumbers.constrainOnce()
注意:只能迭代一次,如果超出一次则会抛出IllegalStateException("This sequence can be consumed only once.")异常。
4、序列(Sequences)操作和集合操作性能对比
关于序列性能对比,主要在以下几个场景下进行对比,通过性能对比你就清楚在什么场景下该使用普通集合操作还是序列操作。
- 1、同样数据操作在数据量级比较大情况下。
使用Sequences序列
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime} ms")
}
fun main(args: Array<String>) = computeRunTime {
(0..10000000)//10000000数据量级
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 100 }
.run {
println("by using sequence result is $this")
}
}
运行结果:
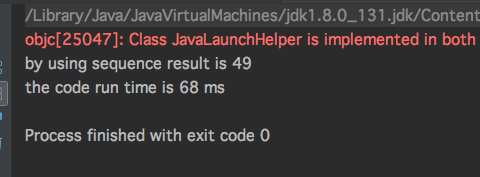
不使用Sequences序列
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime} ms")
}
fun main(args: Array<String>) = computeRunTime {
(0..10000000)//10000000数据量级
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 100 }
.run {
println("by using sequence result is $this")
}
}
运行结果:
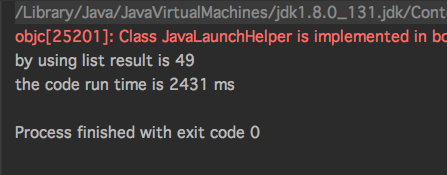
- 2、同样数据操作在数据量级比较小情况下。
使用Sequences序列
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime} ms")
}
fun main(args: Array<String>) = computeRunTime {
(0..1000)//1000数据量级
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 100 }
.run {
println("by using sequence result is $this")
}
}
运行结果:
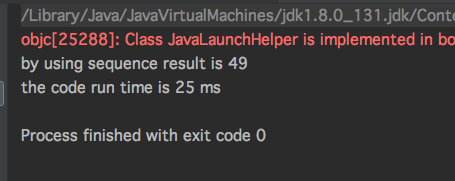
不使用Sequences序列
fun computeRunTime(action: (() -> Unit)?) {
val startTime = System.currentTimeMillis()
action?.invoke()
println("the code run time is ${System.currentTimeMillis() - startTime} ms")
}
fun main(args: Array<String>) = computeRunTime {
(0..1000)//1000数据量级
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 100 }
.run {
println("by using list result is $this")
}
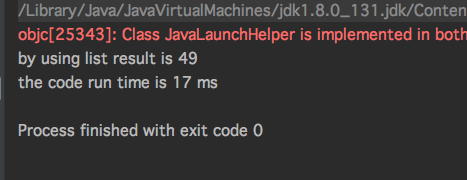
}
运行结果:
通过以上性能对比发现,在数据量级比较大情况下使用Sequences序列性能会比普通数据集合更优;但是在数据量级比较小情况下使用Sequences序列性能反而会比普通数据集合更差。关于选择序列还是集合,记得前面翻译了一篇国外的博客,里面有详细的阐述。博客地址
5、序列(Sequences)性能优化的原理
看到上面性能的对比,相信此刻的你迫不及待想要知道序列(Sequences)内部性能优化的原理吧,那么我们一起来看下序列内部的原理。来个例子
fun main(args: Array<String>){
(0..10)
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.count { it < 6 }
.run {
println("by using sequence result is $this")
}
}
- 1、基本原理描述
序列操作: 基本原理是惰性求值,也就是说在进行中间操作的时候,是不会产生中间数据结果的,只有等到进行末端操作的时候才会进行求值。也就是上述例子中0~10中的每个数据元素都是先执行map操作,接着马上执行filter操作。然后下一个元素也是先执行map操作,接着马上执行filter操作。然而普通集合是所有元素都完执行map后的数据存起来,然后从存储数据集中又所有的元素执行filter操作存起来的原理。
集合普通操作: 针对每一次操作都会产生新的中间结果,也就是上述例子中的map操作完后会把原始数据集循环遍历一次得到最新的数据集存放在新的集合中,然后进行filter操作,遍历上一次map新集合中数据元素,最后得到最新的数据集又存在一个新的集合中。
- 2、原理图解
//使用序列
fun main(args: Array<String>){
(0..100)
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.find { it > 3 }
}
//使用普通集合
fun main(args: Array<String>){
(0..100)
.map { it + 1 }
.filter { it % 2 == 0 }
.find { it > 3 }
}
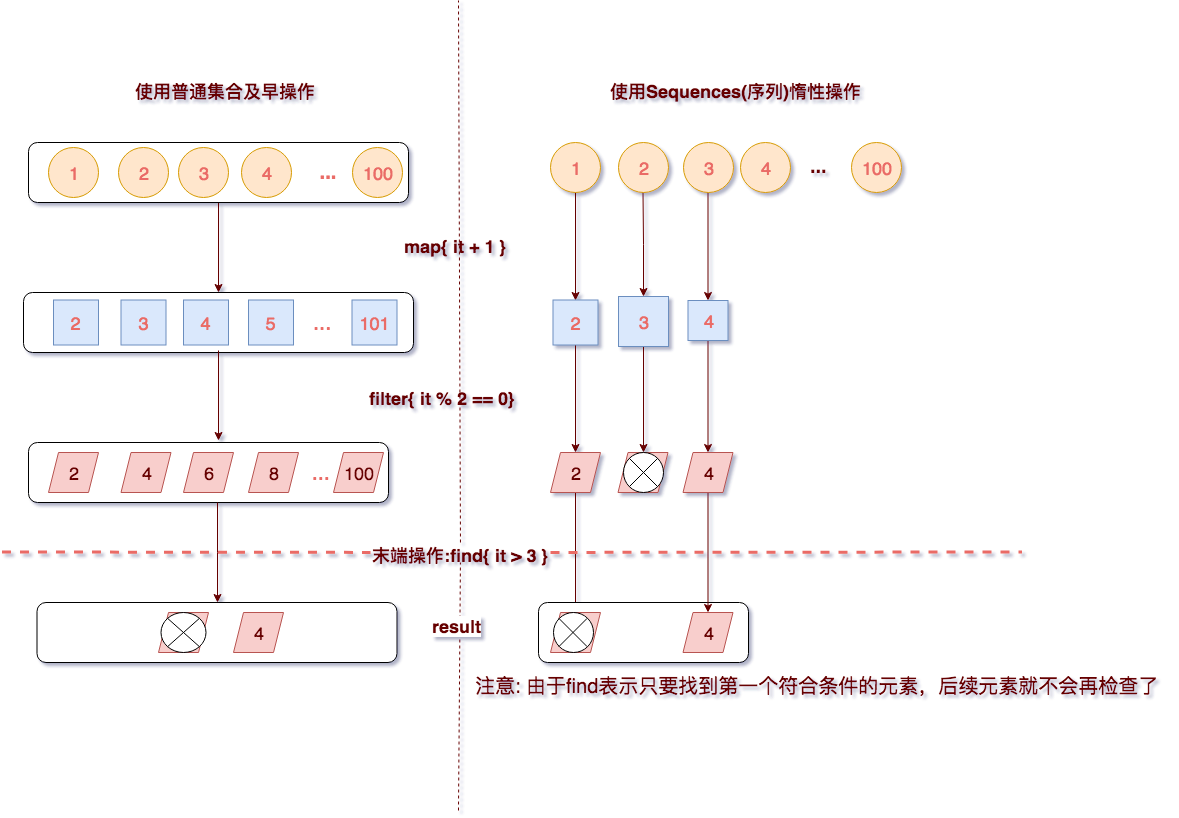
通过以上的原理转化图,会发现使用序列会逐个元素进行操作,在进行末端操作find获得结果之前提早去除一些不必要的操作,以及find找到一个符合条件元素后,后续众多元素操作都可以省去,从而达到优化的目的。而集合普通操作,无论是哪个元素都得默认经过所有的操作。其实有些操作在获得结果之前是没有必要执行的以及可以在获得结果之前,就能感知该操作是否符合条件,如果不符合条件提前摒弃,避免不必要操作带来性能的损失。
6、序列(Sequences)原理源码完全解析
//使用序列
fun main(args: Array<String>){
(0..100)
.asSequence()
.map { it + 1 }
.filter { it % 2 == 0 }
.find { it > 3 }
}
//使用普通集合
fun main(args: Array<String>){
(0..100)
.map { it + 1 }
.filter { it % 2 == 0 }
.find { it > 3 }
}
通过decompile上述例子的源码会发现,普通集合操作会针对每个操作都会生成一个while循环,并且每次都会创建新的集合保存中间结果。而使用序列则不会,它们内部会无论进行多少中间操作都是共享同一个迭代器中的数据,想知道共享同一个迭代器中的数据的原理吗?请接着看内部源码实现。
使用集合普通操作反编译源码
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
byte var1 = 0;
Iterable $receiver$iv = (Iterable)(new IntRange(var1, 100));
//创建新的集合存储map后中间结果
Collection destination$iv$iv = (Collection)(new ArrayList(CollectionsKt.collectionSizeOrDefault($receiver$iv, 10)));
Iterator var4 = $receiver$iv.iterator();
int it;
//对应map操作符生成一个while循环
while(var4.hasNext()) {
it = ((IntIterator)var4).nextInt();
Integer var11 = it + 1;
//将map变换的元素加入到新集合中
destination$iv$iv.add(var11);
}
$receiver$iv = (Iterable)((List)destination$iv$iv);
//创建新的集合存储filter后中间结果
destination$iv$iv = (Collection)(new ArrayList());
var4 = $receiver$iv.iterator();//拿到map后新集合中的迭代器
//对应filter操作符生成一个while循环
while(var4.hasNext()) {
Object element$iv$iv = var4.next();
int it = ((Number)element$iv$iv).intValue();
if (it % 2 == 0) {
//将filter过滤的元素加入到新集合中
destination$iv$iv.add(element$iv$iv);
}
}
$receiver$iv = (Iterable)((List)destination$iv$iv);
Iterator var13 = $receiver$iv.iterator();//拿到filter后新集合中的迭代器
//对应find操作符生成一个while循环,最后末端操作只需要遍历filter后新集合中的迭代器,取出符合条件数据即可。
while(var13.hasNext()) {
Object var14 = var13.next();
it = ((Number)var14).intValue();
if (it > 3) {
break;
}
}
}
使用序列(Sequences)惰性操作反编译源码
- 1、整个序列操作源码
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
byte var1 = 0;
//利用Sequence扩展函数实现了fitler和map中间操作,最后返回一个Sequence对象。
Sequence var7 = SequencesKt.filter(SequencesKt.map(CollectionsKt.asSequence((Iterable)(new IntRange(var1, 100))), (Function1)null.INSTANCE), (Function1)null.INSTANCE);
//取出经过中间操作产生的序列中的迭代器,可以发现进行map、filter中间操作共享了同一个迭代器中数据,每次操作都会产生新的迭代器对象,但是数据是和原来传入迭代器中数据共享,最后进行末端操作的时候只需要遍历这个迭代器中符合条件元素即可。
Iterator var3 = var7.iterator();
//对应find操作符生成一个while循环,最后末端操作只需要遍历filter后新集合中的迭代器,取出符合条件数据即可。
while(var3.hasNext()) {
Object var4 = var3.next();
int it = ((Number)var4).intValue();
if (it > 3) {
break;
}
}
}
- 2、抽出其中这段关键code,继续深入:
SequencesKt.filter(SequencesKt.map(CollectionsKt.asSequence((Iterable)(new IntRange(var1, 100))), (Function1)null.INSTANCE), (Function1)null.INSTANCE);
- 3、把这段代码转化分解成三个部分:
//第一部分
val collectionSequence = CollectionsKt.asSequence((Iterable)(new IntRange(var1, 100)))
//第二部分
val mapSequence = SequencesKt.map(collectionSequence, (Function1)null.INSTANCE)
//第三部分
val filterSequence = SequencesKt.filter(mapSequence, (Function1)null.INSTANCE)
- 4、解释第一部分代码:
第一部分反编译的源码很简单,主要是调用Iterable<T>中扩展函数将原始数据集转换成Sequence<T>对象。
public fun <T> Iterable<T>.asSequence(): Sequence<T> {
return Sequence { this.iterator() }//传入外部Iterable<T>中的迭代器对象
}
更深入一层:
@kotlin.internal.InlineOnly
public inline fun <T> Sequence(crossinline iterator: () -> Iterator<T>): Sequence<T> = object : Sequence<T> {
override fun iterator(): Iterator<T> = iterator()
}
通过外部传入的集合中的迭代器方法返回迭代器对象,通过一个对象表达式实例化一个Sequence<T>,Sequence<T>是一个接口,内部有个iterator()抽象函数返回一个迭代器对象,然后把传入迭代器对象作为Sequence<T>内部的迭代器,也就是相当于给迭代器加了Sequence序列的外壳,核心迭代器还是由外部传入的迭代器对象,有点偷梁换柱的概念。
- 5、解释第二部分的代码:
通过第一部分,成功将普通集合转换成序列Sequence,然后现在进行map操作,实际上调用了Sequence<T>扩展函数map来实现的
val mapSequence = SequencesKt.map(collectionSequence, (Function1)null.INSTANCE)
进入map扩展函数:
public fun <T, R> Sequence<T>.map(transform: (T) -> R): Sequence<R> {
return TransformingSequence(this, transform)
}
会发现内部会返回一个TransformingSequence对象,该对象构造器接收一个Sequence<T>类型对象,和一个transform的lambda表达式,最后返回一个Sequence<R>类型对象。我们先暂时解析到这,后面会更加介绍。
- 6、解释第三部分的代码:
通过第二部分,进行map操作后,然后返回的还是Sequence对象,最后再把这个对象进行filter操作,filter也还是Sequence的扩展函数,最后返回还是一个Sequence对象。
val filterSequence = SequencesKt.filter(mapSequence, (Function1)null.INSTANCE)
进入filter扩展函数:
public fun <T> Sequence<T>.filter(predicate: (T) -> Boolean): Sequence<T> {
return FilteringSequence(this, true, predicate)
}
会发现内部会返回一个FilteringSequence对象,该对象构造器接收一个Sequence<T>类型对象,和一个predicate的lambda表达式,最后返回一个Sequence<T>类型对象。我们先暂时解析到这,后面会更加介绍。
- 7、Sequences源码整体结构介绍
代码结构图: 图中标注的都是一个个对应各个操作符类,它们都实现Sequence<T>接口
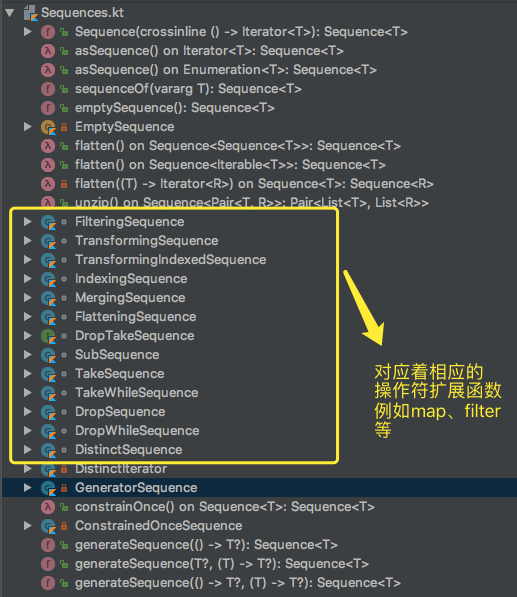
首先,Sequence<T>是一个接口,里面只有一个抽象函数,一个返回迭代器对象的函数,可以把它当做一个迭代器对象外壳。
public interface Sequence<out T> {
/**
* Returns an [Iterator] that returns the values from the sequence.
*
* Throws an exception if the sequence is constrained to be iterated once and `iterator` is invoked the second time.
*/
public operator fun iterator(): Iterator<T>
}
Sequence核心类UML类图
这里只画出了某几个常用操作符的类图
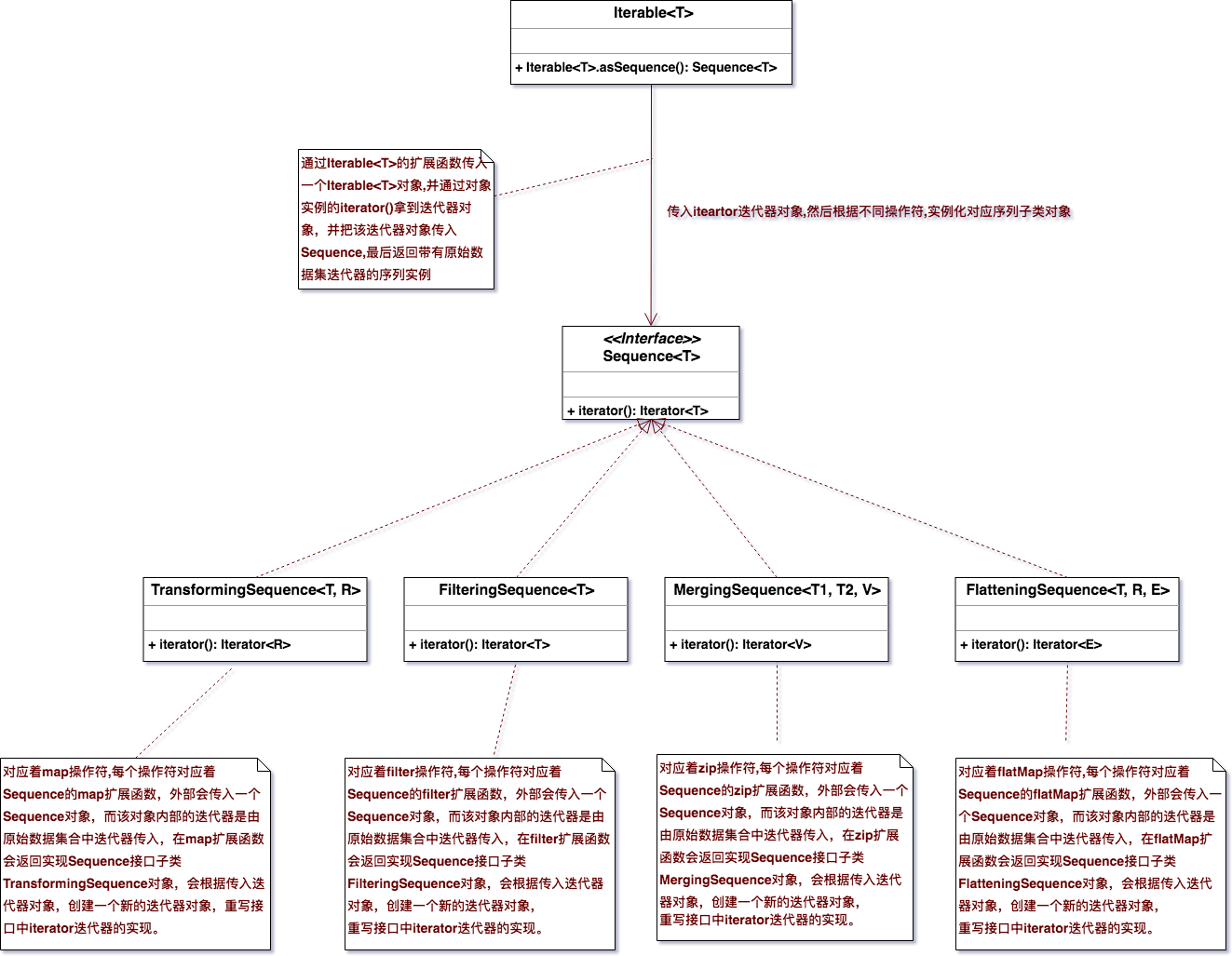
注意: 通过上面的UML类关系图可以得到,共享同一个迭代器中的数据的原理实际上就是利用Java设计模式中的状态模式(面向对象的多态原理)来实现的,首先通过Iterable<T>的iterator()返回的迭代器对象去实例化Sequence,然后外部调用不同的操作符,这些操作符对应着相应的扩展函数,扩展函数内部针对每个不同操作返回实现Sequence接口的子类对象,而这些子类又根据不同操作的实现,更改了接口中iterator()抽象函数迭代器的实现,返回一个新的迭代器对象,但是迭代的数据则来源于原始迭代器中。
- 8、接着上面TransformingSequence、FilteringSequence继续解析.
通过以上对Sequences整体结构深入分析,那么接着TransformingSequence、FilteringSequence继续解析就非常简单了。我们就以TransformingSequence为例:
//实现了Sequence<R>接口,重写了iterator()方法,重写迭代器的实现
internal class TransformingSequence<T, R>
constructor(private val sequence: Sequence<T>, private val transformer: (T) -> R) : Sequence<R> {
override fun iterator(): Iterator<R> = object : Iterator<R> {//根据传入的迭代器对象中的数据,加以操作变换后,构造出一个新的迭代器对象。
val iterator = sequence.iterator()//取得传入Sequence中的迭代器对象
override fun next(): R {
return transformer(iterator.next())//将原来的迭代器中数据元素做了transformer转化传入,共享同一个迭代器中的数据。
}
override fun hasNext(): Boolean {
return iterator.hasNext()
}
}
internal fun <E> flatten(iterator: (R) -> Iterator<E>): Sequence<E> {
return FlatteningSequence<T, R, E>(sequence, transformer, iterator)
}
}
- 9、源码分析总结
序列内部的实现原理是采用状态设计模式,根据不同的操作符的扩展函数,实例化对应的Sequence子类对象,每个子类对象重写了Sequence接口中的iterator()抽象方法,内部实现根据传入的迭代器对象中的数据元素,加以变换、过滤、合并等操作,返回一个新的迭代器对象。这就能解释为什么序列中工作原理是逐个元素执行不同的操作,而不是像普通集合所有元素先执行A操作,再所有元素执行B操作。这是因为序列内部始终维护着一个迭代器,当一个元素被迭代的时候,就需要依次执行A,B,C各个操作后,如果此时没有末端操作,那么值将会存储在C的迭代器中,依次执行,等待原始集合中共享的数据被迭代完毕,或者不满足某些条件终止迭代,最后取出C迭代器中的数据即可。

欢迎关注Kotlin开发者联盟,这里有最新Kotlin技术文章,每周会不定期翻译一篇Kotlin国外技术文章。如果你也喜欢Kotlin,欢迎加入我们~~~
