


什么是kafka
Apache Kafka® 是 一个分布式流处理平台
上面是官网的介绍,和一般的消息处理系统相比,不同之处在于:
- kafka是一个分布式系统,易于向外扩展
- 它同时为发布和订阅提供高吞吐量
- 它支持多订阅者,当失败时能自动平衡消费者
- 消息的持久化
和其他的消息系统之间的对比:
| 对比指标 | kafka | activemq | rabbitmq | rocketmq |
|---|---|---|---|---|
| 背景 | Kafka 是LinkedIn 开发的一个高性能、分布式的消息系统,广泛用于日志收集、流式数据处理、在线和离线消息分发等场景 | ActiveMQ是一种开源的,实现了JMS1.1规范的,面向消息(MOM)的中间件, 为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。 | RabbitMQ是一个由erlang开发的AMQP协议(Advanced Message Queue )的开源实现。 | RocketMQ是阿里巴巴在2012年开源的分布式消息中间件,目前已经捐赠给Apache基金会,已经于2016年11月成为 Apache 孵化项目 |
| 开发语言 | Java、Scala | Java | Erlang | Java |
| 协议支持 | 自己实现的一套 | JMS协议 | AMQP | JMS、MQTT |
| 持久化 | 支持 | 支持 | 支持 | 支持 |
| producer容错 | 在kafka中提供了acks配置选项, acks=0 生产者在成功写入悄息之前不会等待任何来自服务器的响应 acks=1 只要集群的首领节点收到消息,生产者就会收到一个来自服务器的成功响应 acks=all 只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应,这种模式最安全 | 发送失败后即可重试 | 有ack模型。 ack模型可能重复消息 ,事务模型保证完全一致 | 和kafka类似 |
| 吞吐量 | kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高 | rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。 | kafka在topic数量不多的情况下吞吐量比rocketMq高,在topic数量多的情况下rocketMq比kafka高 | |
| 负载均衡 | kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上 | rabbitMQ的负载均衡需要单独的loadbalancer进行支持 | NamerServer进行负载均衡 |
架构图:
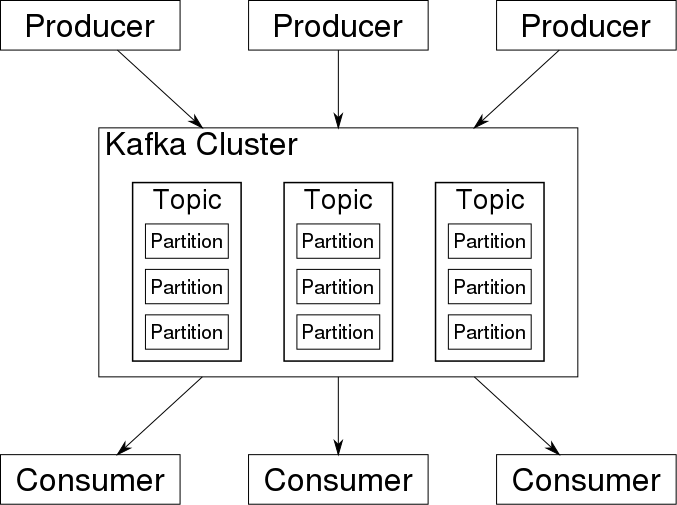
使用实例:
producer:
public class Producer extends Thread {
private final KafkaProducer<Integer, String> producer;
private final String topic;
private final Boolean isAsync;
public Producer(String topic, Boolean isAsync) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put(ProducerConfig.CLIENT_ID_CONFIG, "DemoProducer");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
producer = new KafkaProducer<>(props);
this.topic = topic;
this.isAsync = isAsync;
}
@Override
public void run() {
int messageNo = 1;
while (true) {
String messageStr = "Message_" + messageNo;
long startTime = System.currentTimeMillis();
if (isAsync) { // Send asynchronously
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr), new DemoCallBack(startTime, messageNo, messageStr));
} else { // Send synchronously
try {
producer.send(new ProducerRecord<>(topic,
messageNo,
messageStr)).get();
System.out.println("Sent message: (" + messageNo + ", " + messageStr + ")");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
}
++messageNo;
}
}
class DemoCallBack implements Callback {
private final long startTime;
private final int key;
private final String message;
public DemoCallBack(long startTime, int key, String message) {
this.startTime = startTime;
this.key = key;
this.message = message;
}
/**
* A callback method the user can implement to provide asynchronous handling of request completion. This method will
* be called when the record sent to the server has been acknowledged. Exactly one of the arguments will be
* non-null.
*
* @param metadata The metadata for the record that was sent (i.e. the partition and offset). Null if an error
* occurred.
* @param exception The exception thrown during processing of this record. Null if no error occurred.
*/
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
long elapsedTime = System.currentTimeMillis() - startTime;
if (metadata != null) {
System.out.println(
"message(" + key + ", " + message + ") sent to partition(" + metadata.partition() +
"), " +
"offset(" + metadata.offset() + ") in " + elapsedTime + " ms");
} else {
exception.printStackTrace();
}
}
}
}
consumer:
public class Consumer extends Thread {
private final KafkaConsumer<Integer, String> consumer;
private final String topic;
public Consumer(String topic) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, KafkaProperties.KAFKA_SERVER_URL + ":" + KafkaProperties.KAFKA_SERVER_PORT);
props.put(ConsumerConfig.GROUP_ID_CONFIG, "DemoConsumer");
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.IntegerDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
consumer = new KafkaConsumer<>(props);
this.topic = topic;
}
@Override
public void run() {
while (true) {
consumer.subscribe(Collections.singletonList(this.topic));
ConsumerRecords<Integer, String> records = consumer.poll(Duration.ofSeconds(1).getSeconds());
for (ConsumerRecord<Integer, String> record : records) {
System.out.println("Received message: (" + record.key() + ", " + record.value() + ") at offset " + record.offset());
}
}
}
}
properties:
public class KafkaProperties {
public static final String TOPIC = "topic1";
public static final String KAFKA_SERVER_URL = "localhost";
public static final int KAFKA_SERVER_PORT = 9092;
public static final int KAFKA_PRODUCER_BUFFER_SIZE = 64 * 1024;
public static final int CONNECTION_TIMEOUT = 100000;
public static final String TOPIC2 = "topic2";
public static final String TOPIC3 = "topic3";
public static final String CLIENT_ID = "SimpleConsumerDemoClient";
private KafkaProperties() {}
}
相关名词:
- Producer :消息生产者,向Broker发送消息的客户端
- Consumer :消息消费者,从Broker读取消息的客户端,消费者<=消息的分区数量
- broker :消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群
- topic : 主题,Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic
- Partition : 分区,物理上的概念,一个topic可以分为多个partition,每个partition内部是有序的,kafka默认根据key%partithon确定消息发送到具体的partition
- ConsumerGroup : 每个Consumer属于一个特定的Consumer Group,一条消息可以发送到多个不同的Consumer Group,但是一个Consumer Group中只能有一个Consumer能够消费该消息
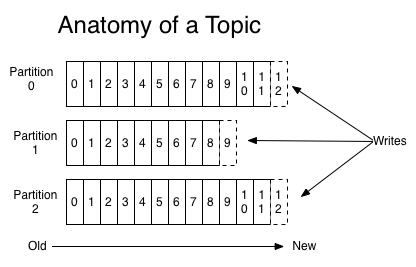
Topic 和 Partition
- 一个Topic中的消息会按照指定的规则(默认是key的hash值%分区的数量,当然你也可以自定义),发送到某一个分区上面;
- 每一个分区都是一个顺序的、不可变的消息队列,并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的
- 消费者所持有的元数据就是这个偏移量,也就是消费者在这个log(分区)中的位置。这个偏移量由消费者控制:正常情况当消费者消费消息的时候,偏移量也线性的的增加
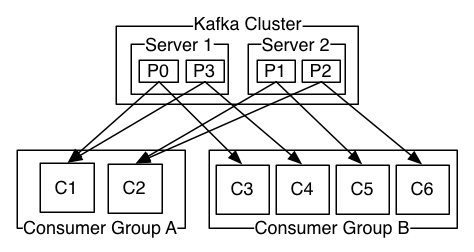
Consumer 和 Partition
- 通常来讲,消息模型可以分为两种, 队列和发布-订阅式。队列的处理方式 是一个消费者组从队列的一端拉取数据,这个数据消费完就没了。在发布-订阅模型中,消息被广播给所有的消费者,接受到消息的消费者都能处理此消息。在Kafka模型中抽象出来了:消费者组(consumer group)
- 消费者组(consumer group):每个组中有若干个消费者,如果所有的消费者都在一个组中,那么这个就变成了队列模型;如果笑消费者在不同的组中,这就成了发布-订阅模型
- 一个分区里面的数据只会由一个分组中的消费者处理,同分组的其他消费者不会重复处理
- 消费者组中的消费者数量<=分区数量,如果大于分区数量,多出来的消费者会处于收不到消息的状态,造成不必要的浪费。
最后
小尾巴走一波,欢迎关注我的公众号,不定期分享编程、投资、生活方面的感悟:)

