

【火炉炼AI】机器学习026-股票数据聚类分析-近邻传播算法
(本文所使用的Python库和版本号: Python 3.6, Numpy 1.14, scikit-learn 0.19, matplotlib 2.2, tushare 1.2)
有一位朋友很擅长炒股,听说其资产已经达到了两百多万,我听后对其敬佩得五体投地,遂虚心向其请教炒股之秘诀,他听后,点了一根烟,深深地吸了一口,然后慢悠悠地告诉我,秘诀其实很简单,你先准备一千万,炒着炒着就能炒到两百万。。。我听后狂喷鼻血。。。
虽然没有取到真经,但我仍不死心,仍然觉得人工智能应该可以用于炒股,AI的能力都能够轻松解决围棋这一世界性难题,难道还不能打败股票市场吗?
下面我们用机器学习的方法来研究一下股票数据,由于股票数据之间没有任何标记,故而这是一类比较典型的无监督学习问题。但在我们着手股票研究之前,需要了解一下什么是近邻传播算法。
1. 近邻传播算法简介
近邻传播聚类算法(Affinity Propagation, AP)是2007年在Science杂志上提出的一种新的聚类算法,它根据N个数据点之间的相似度进行聚类,这些相似度可以是对称的,即两个数据点相互之间的相似度一样(如欧式距离),也可以是不对称的,即两个数据点相互之间的相似度不等,这些相似度组成N*N的相似度矩阵S。
这种算法会同时考虑所有数据点都是潜在的代表点,通过结点之间的信息传递,最后得到高质量的聚类,这个信息的传递,是基于sum-product或者max-product的更新原则,在任意一个时刻,这个信息幅度都代表着近邻的程度,也就是一个数据点选择另一个数据点作为代表点有多靠谱,这也是近邻传播名字的由来。
关于算法原理和公式推导,有很多很好地文章,比如python 实现 AP近邻传播聚类算法和Affinity propagation 近邻传播算法,读者可以阅读这些文章进行深入研究。
2. 准备股票数据
2.1 从网上获取股票数据
股票数据虽然可以从网上获取,但是要想轻易地得到结构化的数据,还是要花费一番功夫的,幸好,我找到了一个很好地财经类python接口模块--tushare,这个模块可以快速的从网站上爬取股票数据,并可以轻松保存和做进一步的数据分析,用起来非常方便。
下面我先自定义了三个工具函数,用于辅助我从网上下载股票数据和对股票数据进行整理。如下代码:
# 准备数据集,使用tushare来获取股票数据
# 准备几个函数,用来获取数据
import tushare as ts
def get_K_dataframe(code,start,end):
'''get day-K data of code, from start date to end date
params:
code: stock code eg: 600123, 002743
start: start date, eg: 2016-10-01
end: end date, eg: 2016-10-31
return:
dataframe with columns [date, open, close, high, low]
'''
df=ts.get_k_data(code,start=start,end=end)
df.drop(['volume'],axis=1, inplace=True)
return df
这个函数获取单只股票的估计数据,其时间跨度为start到end,返回获取到的股票数据DataFrame。当然,一次获取一只股票的数据太慢了,下面这个函数我们可以一次获取多只股票数据。
def get_batch_K_df(codes_list,start,end):
'''get batch stock K data'''
df=pd.DataFrame()
print('fetching data. pls wait...')
for code in codes_list:
# print('fetching K data of {}...'.format(code))
df=df.append(get_K_dataframe(code,start,end))
return df
此处我选择上证50指数的成分股作为研究对象
2.2 对股票数据进行规整
由于tushare模块已经将股票数据进行了基本的规整,此处我们只需要将数据处理成我们项目所需要的样子即可。
此处对股票数据的规整包括有几个方面:
1,计算需要聚类的数据,此处我用收盘价减去开盘价作分析,即一天的涨跌幅度。或许用一天的涨幅%形式可能更合适。
2,由于上面的get_batch_k_df()函数获取的批量股票数据都是将多个股票数据在纵向上合并而来,故而此处我们要将各种不同股票的涨跌幅度放在DataFrame的列上,以股票代码为列名。
3,在pd.merge()过程中,由于有的股票在某些交易日停牌,所以没有数据,这几个交易日就被删掉(因为后面的聚类算法中不允许存在NaN),所以相当于要选择所有股票都有交易数据的日期,这个选择相当于取股票数据的交集,最终得到很少一部分数据,数据量太少时,得到的聚类结果也没有太多说服力。故而我的解决方法是,删除一些交易日明显很少的股票,不对其进行pd.merge(),最终得到603个交易日的有效数据,选取了41只股票,舍弃了9只停牌日太多的股票。
这三部分的规整过程我都集成到一个函数中实现,如下是这个函数的代码:
# 数据规整函数,用于对获取的df进行数据处理
def preprocess_data(stock_df,min_K_num=1000):
'''preprocess the stock data.
Notice: min_K_num: the minimum stock K number.
because some stocks was halt trading in this time period,
the some K data was missing.
if the K data number is less than min_K_num, the stock is discarded.'''
df=stock_df.copy()
df['diff']=df.close-df.open # 此处用收盘价与开盘价的差值做分析
df.drop(['open','close','high','low'],axis=1,inplace=True)
result_df=None
#下面一部分是将不同的股票diff数据整合为不同的列,列名为股票代码
for name, group in df[['date','diff']].groupby(df.code):
if len(group.index)<min_K_num: continue
if result_df is None:
result_df=group.rename(columns={'diff':name})
else:
result_df=pd.merge(result_df,
group.rename(columns={'diff':name}),
on='date',how='inner') # 一定要inner,要不然会有很多日期由于股票停牌没数据
result_df.drop(['date'],axis=1,inplace=True)
# 然后将股票数据DataFrame转变为np.ndarray
stock_dataset=np.array(result_df).astype(np.float64)
# 数据归一化,此处使用相关性而不是协方差的原因是在结构恢复时更高效
stock_dataset/=np.std(stock_dataset,axis=0)
return stock_dataset,result_df.columns.tolist()
函数定义好了之后,我们就可以获取股票数据,并对其进行规整分析,如下所示:
# 上面准备了各种函数,下面开始准备数据集
# 我们此处分析上证50指数的成分股,看看这些股票有哪些特性
sz50_df=ts.get_sz50s()
stock_list=sz50_df.code.tolist()
# print(stock_list) # 没有问题
batch_K_data=get_batch_K_df(stock_list,start='2013-09-01',end='2018-09-01') # 查看最近五年的数据
print(batch_K_data.info())
------------------------输---------出--------------------------------
fetching data. pls wait...
<class 'pandas.core.frame.DataFrame'>
Int64Index: 56246 entries, 158 to 1356
Data columns (total 6 columns):
date 56246 non-null object
open 56246 non-null float64
close 56246 non-null float64
high 56246 non-null float64
low 56246 non-null float64
code 56246 non-null object
dtypes: float64(4), object(2)
memory usage: 3.0+ MB
None
--------------------------------完-------------------------------------
stock_dataset,selected_stocks=preprocess_data(batch_K_data,min_K_num=1100)
print(stock_dataset.shape) # (603, 41) 由此可以看出得到了603个交易日的数据,其中有41只股票被选出。
# 其他的9只股票因为不满足最小交易日的要求而被删除。这603个交易日是所有41只股票都在交易,都没有停牌的数据。
print(selected_stocks) # 这是实际使用的股票列表
-------------------------------------输---------出---------------
(603, 41) ['600000', '600016', '600019', '600028', '600029', '600030', '600036', '600048', '600050', '600104', '600111', '600276', '600340', '600519', '600547', '600585', '600690', '600703', '600887', '600999', '601006', '601088', '601166', '601169', '601186', '601288', '601318', '601328', '601336', '601390', '601398', '601601', '601628', '601668', '601688', '601766', '601800', '601818', '601857', '601988', '603993']
---------------------------------------完------------------------
到此为止,股票数据也从网上下载下来了,我们也对其进行了数据处理,可以满足后面聚类算法的要求了。
########################小**********结###############################
1,tushare一个非常好用的获取股票数据,基金数据,区块连数据等各种财经数据的模块,强烈推荐。
2,此处我自定义了几个函数,get_K_dataframe(), get_batch_K_df()和preprocess_data()都是具有一定通用性的,以后要获取股票数据或者处理股票数据,可以直接搬用或在此基础上稍微修改即可。
3,作为演示,此处我只获取了上证50只股票的最近五年数据,并且删除掉一些停牌太多的股票,得到了41只股票的共603个有效交易日数据。
#################################################################
3. 用近邻传播算法聚类股票数据
首先我们构建了协方差图模型,从相关性中学习其图结构
# 从相关性中学习其图形结构
from sklearn.covariance import GraphLassoCV
edge_model=GraphLassoCV()
edge_model.fit(stock_dataset)
然后再构建近邻传播算法结构模型,并训练LassoCV graph中的相关性数据
# 使用近邻传播算法构建模型,并训练LassoCV graph
from sklearn.cluster import affinity_propagation
_,labels=affinity_propagation(edge_model.covariance_)
此处已经构建并训练了该聚类算法模型,但是怎么看结果了?
如下代码:
n_labels=max(labels)
# 对这41只股票进行了聚类,labels里面是每只股票对应的类别标号
print('Stock Clusters: {}'.format(n_labels+1)) # 10,即得到10个类别
sz50_df2=sz50_df.set_index('code')
# print(sz50_df2)
for i in range(n_labels+1):
# print('Cluster: {}----> stocks: {}'.format(i,','.join(np.array(selected_stocks)[labels==i]))) # 这个只有股票代码而不是股票名称
# 下面打印出股票名称,便于观察
stocks=np.array(selected_stocks)[labels==i].tolist()
names=sz50_df2.loc[stocks,:].name.tolist()
print('Cluster: {}----> stocks: {}'.format(i,','.join(names)))
------------------------输---------出--------------------------------
Stock Clusters: 10
Cluster: 0----> stocks: 宝钢股份,南方航空,华夏幸福,海螺水泥,中国神华
Cluster: 1----> stocks: 中信证券,保利地产,招商证券,华泰证券
Cluster: 2----> stocks: 北方稀土,洛阳钼业
Cluster: 3----> stocks: 恒瑞医药,三安光电
Cluster: 4----> stocks: 山东黄金
Cluster: 5----> stocks: 贵州茅台,青岛海尔,伊利股份
Cluster: 6----> stocks: 中国联通,大秦铁路,中国铁建,中国中铁,中国建筑,中国中车,中国交建
Cluster: 7----> stocks: 中国平安,新华保险,中国太保,中国人寿
Cluster: 8----> stocks: 浦发银行,民生银行,招商银行,上汽集团,兴业银行,北京银行,农业银行,交通银行,工商银行,光大银行,中国银行
Cluster: 9----> stocks: 中国石化,中国石油
-----------------------------完-------------------------------------
从结果中可以看出,这41只股票已经被划分为10个簇群,从这个聚类结果中,我们也可以看到,比较类似的股票都被划分到同一个簇群中,比如Cluster1中大部分都是证券公司,而Cluster6中都是“铁公基”类股票,而Cluster8中都是银行类的股票。这和我们普遍认为的概念分类的股票相吻合。
虽然此处我们进行了合理分类,但是我还将这种分类结果绘制到图中,便于直观感受他们的簇群距离,所以我此处自定义了一个函数visual_stock_relationship()专门来可视化聚类算法的结果。这个函数的代码太长,此处我就不贴代码了,可以参考我的github上代码,得到的聚类结果为:
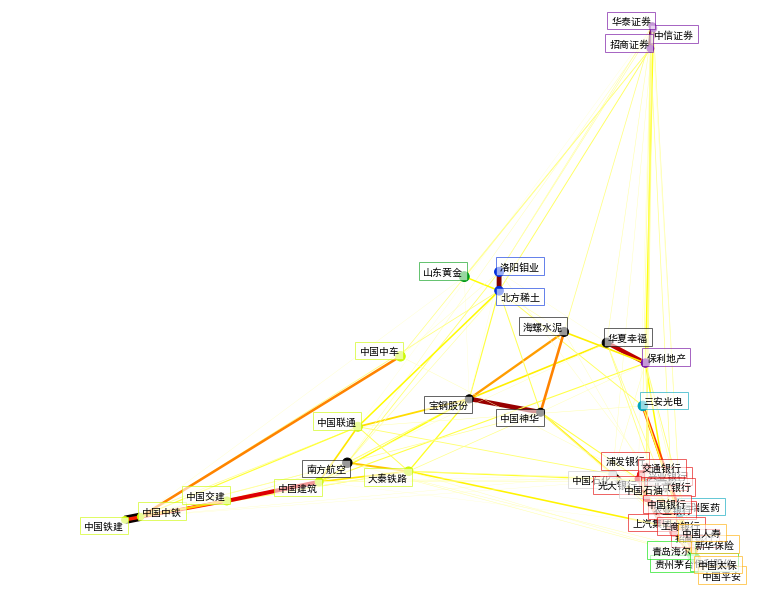
这个图看起来一团糟,但是每一部分都代表不同的含义:
1,这个图形结合了本项目的股票数据,GraphLassoCV图结构模型,近邻传播算法的分类结果,故而可以说是整个项目的结晶。
2,图中每一个节点代表一只股票,旁边有股票名称,节点的颜色表示该股票所属类别的种类,用节点颜色来区分股票所属簇群。
3,GraphLassoCV图结构模型中的稀疏逆协方差信息用节点之间的线条来表示,线条越粗,表示股票之间的关联性越强。
4,股票在图形中的位置是由2D嵌套算法来决定的,距离越远,表示其相关性越弱,簇间距离越远。
这个图得来不易,花了我整整一天时间来做这个项目,汗,里面的各种股票数据处理,太让我头疼了,所以再来具体研究一下这张图。
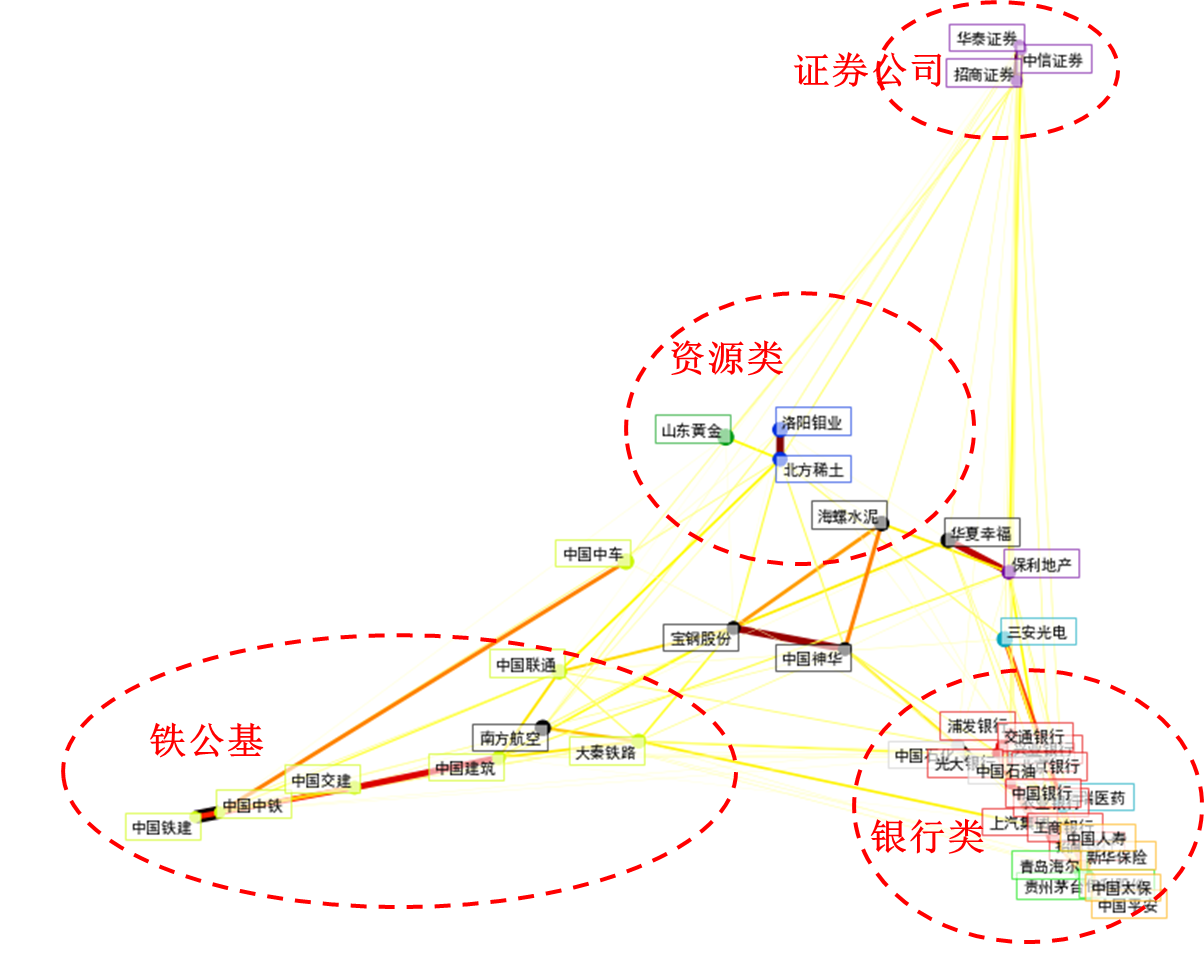
########################小**********结###############################
1,本项目仅仅使用股票的收盘价与开盘价的差值,就聚类得到了股票所属类别的信息,看来聚类的确可以用于股票内在结构的分类。
2,本项目先用GraphLassoCV得到股票原始数据之间的相关性图,然后再用近邻传播算法对GraphLassoCV的相关性进行聚类,这种方式和以前我们直接用数据集来训练聚类算法不一样。
3,使用其他股票数据,比如涨幅,成交量,或换手率,也许可以挖掘出更多有用的股票结构信息,从而为我们的股票投资带来帮助。
4,股票市场风险太大,没事还是好好工作,好好研究AI,奉劝各位一句:珍爱生命,远离股市,切记,切记!!!
#################################################################
注:本部分代码已经全部上传到(我的github)上,欢迎下载。
参考资料:
1, Python机器学习经典实例,Prateek Joshi著,陶俊杰,陈小莉译
