


持续更新的github笔记,链接地址:Front-End-Basics
此篇文章的笔记地址:字符到底发生了什么变化
ES6走走看看系列,特别鸣谢奇舞读书会~
看正文之前,先思考一下,为什么你看的ES6各种权威指南里提到的
𠮷会有那么多问题,它length是2,charAt出来是乱码……
1、 JavaScript字符编码的“坑”和“填坑”
计算机内部处理的信息,都是一个些二进制值,每一个二进制位(bit)有0和1两种状态。
一个字节(byte)有八个二进制位,也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。转换成十六进制,一个字节就是0x00到OxFF。
1.1 先来聊聊字符编码的历程
先祭出一张图,建议放大看
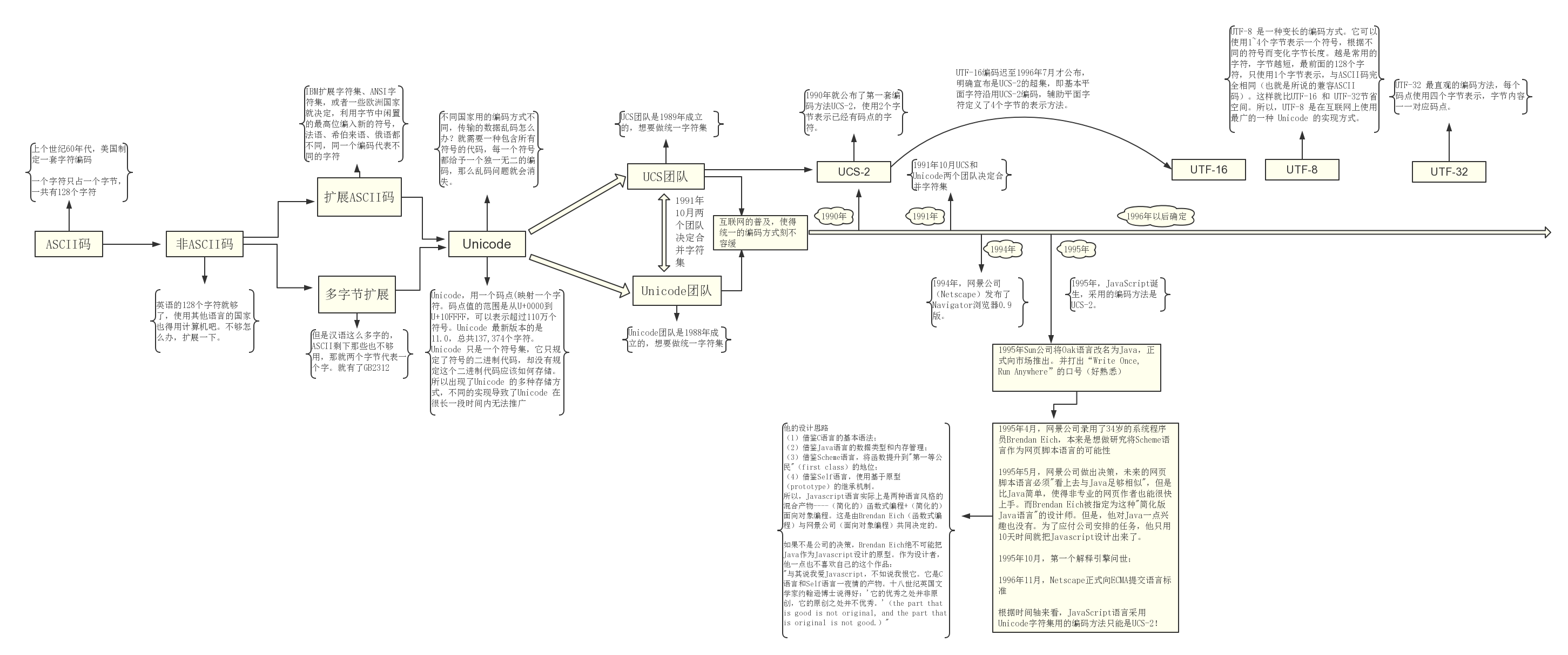
(1) ASCII 码
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码(美国信息交换标准代码),一直沿用至今。
ASCII 码一共规定了128个字符的编码,只占用了一个字节的后面7位,最前面的一位统一规定为0。
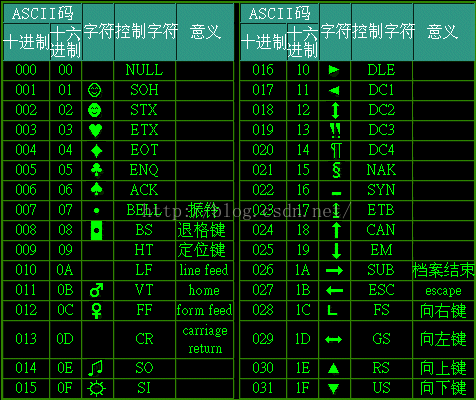
第一部分:0~31(0x00~0x1F)及127(共33个)是控制字符或通信专用字符,有些可以显示在屏幕上,有些则不能显示,但能看到其效果(如换行、退格)如下表:
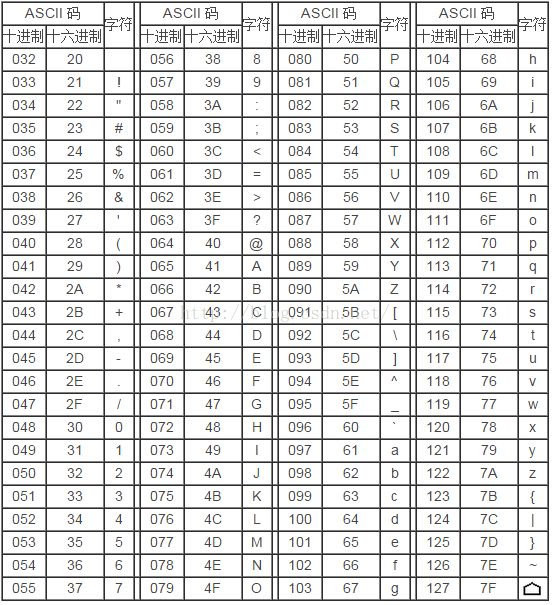
第二部分:是由20~7E共95个,这95个字符是用来表示阿拉伯数字、英文字母大小写和下划线、括号等符号,都可以显示在屏幕上如下表:
(2) 非ASCII 编码
英语用128个符号编码就够了,但是世界上可不只有英语这一种语言,先不说汉语,就是那些不说英语的欧洲国家,128个符号是不够的。
一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号,这些欧洲国家使用的编码体系,可以表示最多256个符号。大家你加你的,我加我的。因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
1981年IBM PC ROM256个字符的字符集,即IBM扩展字符集,这128个扩充字符是由IBM制定的,并非标准的ASCII码.这些字符是用来表示框线、音标和其它欧洲非英语系的字母。如下图:

在Windows 1.0(1985年11月发行)中,Microsoft没有完全放弃IBM扩展字符集,但它已退居第二重要位置。因为遵循了ANSI草案和ISO标准,纯Windows字符集被称作「ANSI字符集」。

由此可见扩展ASCII不再是国际标准。
而对于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右(《中华辞海》共收汉字87019个,日本《今昔文字镜》收录汉字超15万)。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312(中华人民共和国国家标准简体中文字符集),使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号。其实GB 2312标准共收录6763个汉字,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。
(3) Unicode
之前的编码,大家在自己的国家使用都挺好的。世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号,所以一旦不同国家进行数据传输,结果就只有乱码了。
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字所表示的,这是一种所有符号的编码。
Unicode,定义很简单,用一个码点(code point)映射一个字符。码点值的范围是从U+0000到U+10FFFF,可以表示超过110万个符号。
Unicode 最新版本的是 11.0,总共137,374个字符,这么看来,还是挺够用的。
Unicode最前面的65536个字符位,称为基本平面(BMP-—Basic Multilingual Plane),它的码点范围是从U+0000到U+FFFF。最常见的字符都放在这个平面,这是Unicode最先定义和公布的一个平面。 剩下的字符都放在补充平面(Supplementary Plane),码点范围从U+010000一直到U+10FFFF,共16个。
需要注意的是,Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
// 例如下面的字符对应的码点
A的码点 U+0041
a的码点 U+0061
©的码点 U+00A9
☃的码点 U+2603
💩的码点 U+1F4A9
正是因为上面说的,没有规定怎么存储,所以出现了Unicode 的多种存储方式,不同的实现导致了Unicode 在很长一段时间内无法推广,而且本来英文字母只用一个字节存储就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
在这个时候往往需要一个强大的外力推动,大家诉诸于利益,共同实现一个目标。所以,真正意义上的互联网普及了,地球变成了村子,交流越来越多,乱码是怎么能行。
(4) UTF-8、UTF-16、UTF-32
UTF(Unicode transformation format)Unicode转换格式,是服务于Unicode的,用于将一个Unicode码点转换为特定的字节序列。 上面三种都是 Unicode 的实现方式之一。 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。
UTF-8
1992年开始设计,1993年首次被正式介绍,1996年UTF-8标准还没有正式落实前,微软的CAB(MS Cabinet)规格就明确容许在任何地方使用UTF-8编码系统。但有关的编码器实际上从来没有实现这方面的规格。2003年11月UTF-8被RFC 3629重新规范,只能使用原来Unicode定义的区域,U+0000到U+10FFFF,也就是说最多四个字节(之前可以使用一至六个字节为每个字符编码)
UTF-8 是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。越是常用的字符,字节越短,最前面的128个字符,只使用1个字节表示,与ASCII码完全相同(也就是所说的兼容ASCII码)。在英文下这样就比UTF-16 和 UTF-32节省空间。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
UTF-16
基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。
这里涉及到一个怎么判断两个字节是一个字符,还是两个字节加两个字节组成的四个字节是一个字符?
解决方法是:在基本平面内,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
具体来说,辅助平面的字符位共有220个,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小210),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小210),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示(代理对的概念)。
所以,当我们遇到两个字节,发现它的码点在U+D800到U+DBFF之间,就可以断定,紧跟在后面的两个字节的码点,应该在U+DC00到U+DFFF之间,这四个字节必须放在一起解读。
UTF-16编码介于UTF-32与UTF-8之间,同时结合了定长和变长两种编码方法的特点。
UTF-32
UTF-32 最直观的编码方法,每个码点使用四个字节表示,字节内容一一对应码点。
UTF-32的优点在于,转换规则简单直观,查找效率高。缺点在于浪费空间,同样内容的英语文本,它会比ASCII编码大三倍。这个缺点很致命,导致实际上没有人使用这种编码方法,HTML 5标准就明文规定,网页不得编码成UTF-32。
(5) UCS UCS-2
国际标准化组织(ISO)的ISO/IEC JTC1/SC2/WG2工作组是1984年成立的,想要做统一字符集,并与1989年开始着手构建UCS(通用字符集),也叫ISO 10646标准,当然另一个想做统一字符集的是1988年成立的Unicode团队,等到他们发现了对方的存在,很快就达成一致:世界上不需要两套统一字符集(幸亏知道的早啊)。
1991年10月,两个团队决定合并字符集。也就是说,从今以后只发布一套字符集,就是Unicode标准,并且修订此前发布的字符集,UCS的码点将与Unicode完全一致。(两个标准同时是存在)
UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是基本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即基本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。
两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2。
UCS-2 使用2个字节表示已经有码点的字符,第一个字节在前,就是"大尾方式"(Big endian),第二个字节在前就是"小尾方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大尾方式;如果头两个字节是FF FE,就表示该文件采用小尾方式。
1.2 JavaScript 编码方法存在的问题
最上面给出的图中字符的发展历史和JavaScript的诞生时间对比下,可以知道JavaScript如果要想用Unicode字符集,比较恰的选择是UCS-2编码方法,UTF-8,UTF-16都来的晚了一些,UCS-4倒是有的,但是英文字符本来一个字节就可以的,现在也要用4个字节,还是挺严重的事情的。96年那个时候,电脑普遍配置内存 8MB-16MB,硬盘850MB—1.2GB。
ECMAScript 6 之前,JavaScript字符编码方式使用UCS-2,是导致之后JavaScript对位于辅助平面的字符(超过两个字节的字符)操作出现异常情况的根本原因。
ECMAScript 6 强制使用UTF-16字符串编码来解决字符超过两个字节时出现异常的问题,并按照这种字符编码来标准化字符串操作。
// 存在的问题
const text = '😂';
console.log(text.length) //打印 2 ,其实是一个Emoji表情符
console.log(/^.$/.test(text)) // false , 正则匹配也出了问题,说不是一个字符
console.log(/^..$/.test(text)) // true , 是两个字符
console.log(text.charAt(0)) // � 前后两个字节码位都是落在U+D800到U+DFFF这个空段,打印不出东西
console.log(text.charAt(1)) // �
console.log(text.charCodeAt(0)) // 55357 转成十六进制 0xd83d
console.log(text.charCodeAt(1) //56834 转成十六进制 0xde02
// 经过查询Unicode的字符表,😂的码位是U+1f602
console.log('\u1f602' === '😂') //false
console.log('\ud83d\ude02' === '😂') // true
扩展:� 的Unicode码点是 U+FFFD,通常用来表示Unicode转换时无法识别的字符(也就是乱码)
1.3 ECMAScript 6 解决字符编码的问题
(1) 为解决charCodeAt()方法获取字符码位错误的问题,新增codePointAt()方法
codePointAt()方法完全支持UTF-16,参数接收的是编码单元的位置而非字符位置,返回与字符串中给定位置对应的码位,即一个整数。
对于BMP字符集中的字符,codePointAt()方法的返回值跟charCodeAt()相同,而对于非BMP字符集来说,返回值不同。
const text = '😂';
console.log(text.charCodeAt(0)) // 位置0处的一个编码单元 55357
console.log(text.charCodeAt(1)) // 位置1处的一个编码单元 56834
console.log(text.codePointAt(0)) // 位置0处的编码单元开始的码位,此例是从这个编码单位开始的两个编码单元组合的字符(四个字节),所以会打印出所有码位,即四字节的码位 128514 即0x1f602,大于0xffff,也证明了是占四个字节的存储空间。
console.log(text.codePointAt(1)) // 位置1处的编码单元开始的码位 56834
(2) 为解决超过两个字节的码点与字符转换问题,新增了fromCodePoint()方法
// 打印😂
console.log(String.fromCharCode(128514)) // 打印失败
console.log(String.fromCharCode(55357,56834)) // 参数可以接收一组序列数字,表示 Unicode 值。打印成功 😂
console.log(String.fromCodePoint(128514)) // 打印成功 😂
console.log(String.fromCodePoint(0x1f602)) // 可以接收不同进制的参数,打印成功 😂
(3) 为解决正则表达式无法正确匹配超过两个字节的字符问题,ES6定义了一个支持Unicode的 u 修饰符
const text = '😂';
console.log(/^.$/.test(text)) // false , 正则匹配出了问题,说不是一个字符
console.log(/^..$/.test(text)) // true , 是两个字符
console.log(/^.$/u.test(text)) // true, 加入 u 修饰符,匹配正确
注意:u修饰符是语法层面的变更,在不支持ES6的JavaScript的引擎中使用它会导致语法错误,可以使用RegExp构造函数和try……catch来检测,避免发生语法错误
(4) 为解决超过\uffff码点的字符无法直接用码点表示的问题,引入了\u{xxxxx}
console.log('\u1f602' === '😂') //false
console.log('\ud83d\ude02' === '😂') // true
console.log('\u{1f602}' === '😂') // true
(5) 解决字符串中有四个字节的字符的length问题
const text = '笑哭了😂';
// 解决一
// 上线UTF-16如果是在辅助平面(占4个字节)的话,会有代理对,U+D800-U+DBFF和U+DC00-U+DFFF
var surrogatePair = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g; // 匹配UTF-16的代理对
function firstGetRealLength(string) {
return string
// 把代理对改为一个BMP的字符,然后获取长度
.replace(surrogatePair, '_')
.length;
}
firstGetRealLength(text); // 4
// 解决二(推荐)
// 字符串是可迭代的,可以用Array.from()来转化成数组计算length
function secondGetRealLength(string) {
return Array.from(string).length;
}
secondGetRealLength(text); // 4
// 解决三
// 使用正则新增加的修饰符u
function thirdGetRealLength(string) {
let result = text.match(/[\s\S]/gu);
return result?result.length:0;
}
thirdGetRealLength(text); // 4
(5) 解决字符串中有四个字节的字符的字符串反转问题
const text = '笑哭了😂';
function reverse(string) {
return string.split('').reverse().join('');
}
function reversePlus(string) {
return Array.from(string).reverse().join('');
}
console.log(reverse(text)) // ��了哭笑 因为😂是\ud83d\ude02反转后是\ude02\ud83d,不是一个合法的代理对(高低字节范围不同)
console.log(reversePlus(text)) // 😂了哭笑
2、 ECMAScript 6 模板字面量
模板字面量的填补的ES5的一些特性
- 多行字符串
- 基本的字符串格式化,有将变量的值嵌入字符串的能力
- HTML转义,向HTML中插入经过安全转换后的字符串的能力
(1)多行字符串中反撇号中的所有空白符都属于字符串的一部分
let message = `a
b`;
console.log(message.length) //15
(2)标签模板:模板字符串可以紧跟在一个函数名后面,该函数将被调用来处理这个模板字符串。这被称为“标签模板”功能(tagged template)。
标签模板其实不是模板,而是函数调用的一种特殊形式。“标签”指的就是函数,紧跟在后面的模板字符串就是它的参数。
let a = 5;
let b = 10;
function tag(s, v1, v2) {
console.log(s[0]);
console.log(s[1]);
console.log(s[2]);
console.log(v1);
console.log(v2);
return "OK";
}
// 标签模板调用
tag`Hello ${ a + b } world ${ a * b }`;
// 等同于
tag(['Hello ', ' world ', ''], 15, 50);
//打印
// "Hello "
// " world "
// ""
// 15
// 50
// "OK"
“标签模板”的一个重要应用,就是过滤 HTML 字符串,防止用户输入恶意内容。标签模板的另一个应用,就是多语言转换(国际化处理)。
参考链接
谈谈Unicode编码——其中有“大尾”和“小尾”的来源描述小人国呦