

文 / 出门问问信息科技有限公司
来源 | TensorFlow 公众号
1、背景
热词唤醒 (Keyword Spotting) 往往是用户对语音交互体验的第一印象,要做到准确快速。因此热词检测算法要同时保证高唤醒率和低误唤醒率,能够准确地区分热词和非热词的音频信号。主流的热词检测方法,通常使用深度神经网络来从原始音频特征中提取 high-level 的抽象特征(见下图)。为了能够在计算性能和内存大小都非常有限的嵌入式设备上做到 “Always On” 和 “低延迟”,我们使用 TensorFlow Lite 作为神经网络模型的部署框架,既能够很好地兼容基于 TensorFlow 的模型训练流程,也能够提供非常高效和轻量的嵌入式端运行时 (Runtime)。
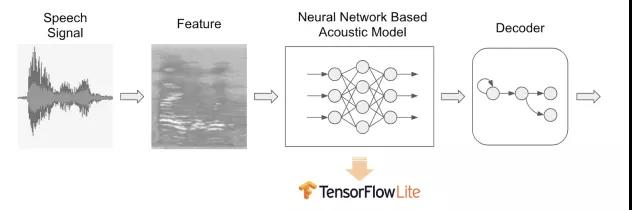
2、开发部署流程
在神经网络结构大体确定的情况下,会显著影响最终计算性能的主要是:模型量化 (Quantization),计算图的优化 (Computation Graph Optimization),以及 Ops 计算核的实现。使用 TensorFlow Lite 部署热词检测模型的开发工作主要也是在这三方面。
应用 Simulated Quantization 进行模型训练 在嵌入式设备上部署神经网络模型时,通常使用模型 “量化” (Quantization) 来减少模型参数需要的空间大小,并且提高计算吞吐量 (throughput)。使用 TensorFlow 可以在模型训练时通过增加 FakeQuant 节点来实现 “Simulated Quantization”,在前向计算 (forward) 时模拟参数定点化带来的精度损失。FakeQuant 节点可以在构建模型计算图时手动添加,对于常见的网络结构也可以使用 TensorFlow contrib/quantize 工具,自动在模型训练的计算图中匹配需要进行参数量化的 Layers,并在合适的位置加入 FakeQuant 节点。
使用 TOCO 进行模型转换
使用 TensorFlow Lite 在嵌入式平台进行部署,需要使用 TOCO 工具进行模型格式转换,同时会对神经网络的计算图进行各种变换优化,比如会去掉或者合并不必要的常量计算,会将部分激活函数计算融合到相关 FullyConnected 或者 Conv2D 节点等,以及处理模型量化 (Quantization) 相关操作。如果不涉及到 Custom Ops,在模型转换这个环节,主要需要关注的两个方面是:
1)正确处理Quantization参数和FakeQuant相关节点 2)避免转换后的计算图中出现低效的节点
Custom Ops 实现和性能优化
如果模型的神经网络结构中用到了目前 TensorFlow Lite 尚不支持的操作,可以以 Custom Op 方式实现相应计算核 (kernel)。要在 Custom Op 中实现高效计算,需要根据数据维度充分利用 SIMD 指令集的加速,并且减少不必要的内存读写。在快速原型阶段,对于 Custom Op 中的向量和矩阵运算,可以调用 tensor_util 中的函数,充分利用 TFLite 中已有的优化实现。而如果 TFLite 已有的函数不能满足需求,可以调用更加底层的高性能计算库,例如 float 类型可以调用 Eigen,int8 类型可以调用 gemmlowp,TFLite 中 Builtin Ops 的计算核提供了调用示例。
3、热词检测中使用 TensorFlow Lite 的效果
我们按照上述流程将热词检测中的神经网络推理在 TensorFlow Lite 框架中实现,并部署到小问音箱上进行性能和效果的测试。在音箱的低功耗 ARM 处理器 (Cortex-A7) 上,基于 TensorFlow Lite 的神经网络推理计算,相比于我们原有内部开发的神经网络推理框架,计算性能有 20%~30% 的提升。考虑到我们内部推理框架已经针对 8-bit 低精度模型和 ARM 计算平台进行了相当充分的性能优化,因此我们认为 TensorFlow Lite 在嵌入式平台上的计算性能表现是非常优秀的。用 TensorFlow Lite 进行模型部署,结合 TensorFlow 用于模型训练,使我们整个深度学习开发流程更为统一和高效。例如,得益于 Simulated Quantization,我们在模型量化过程中能够更好地处理例如 BatchNorm 等网络结构,并且在训练阶段可以 fine-tune 模拟量化后的模型,因此应用 TensorFlow Lite 以及相关的训练和部署流程之后,我们的热词检测模型在相同误唤醒水平下唤醒率会有约 3% 的提升。此外,根据我们实际经验,使用 TensorFlow Lite 可以让我们应用和优化新模型结构的开发周期,从大于一个月缩短到小于一个星期,极大地提升了嵌入式端深度学习开发的迭代速度。
此内容为精简版,想要阅读完整版案例说明,请点击此链接☛ www.tensorflowers.cn/t/6306
