

为什么要使用流?
这里就要提到一个网上的例子了。首先,我们需要先生成一个大文件:
const fs = require('fs');
const file = fs.createWriteStream('./test.txt');
for(let i=0; i<= 1e6; i++) {
file.write('Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.\n');
}
file.end();
这就生成了一个大概 450MB 的文件。第二步,我们需要启动一个简单的 Node 服务器。
const fs = require('fs');
const http = require('http');
const server = http.createServer();
server.on('request', (req, res) => {
fs.readFile('./test.txt', (err, data) => {
if (err) throw err;
res.end(data);
});
});
server.listen(3000);
把代码写好之后,我在本地全局安装了一个 pm2,当然了,你也可以使用系统自带任务管理器、活动监视器等等来监控内存消耗的变化,pm2 比较直观好用,我就直接使用了 pm2。
这是初始状态:
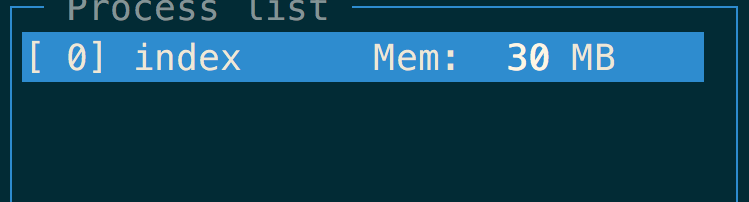
我们打开命令行,使用 curl 来访问服务器:curl http://localhost:3000 。
这时候,我们可以通过 pm2 monit index.js 来查看。
可以看到现在的内存消耗为:
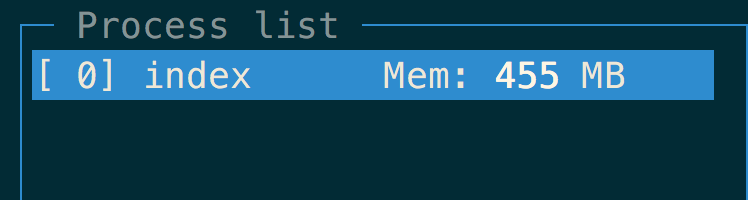
可以看到,用这种方法是将整个文件都放在了内存当中,如果文件小还好,但是当数据量非常大的时候,就会造成内存不够用的问题,并且当你将内存占个七七八八也会影响到用户访问的速度,针对这种情况,我们使用流来解决这个问题。
首先,HTTP 响应对象也是一种可写流,我们可以创建一个文件的可读流,通过 pipe 连接这两个流,我们可以看下这样的内存消耗。
const fs = require('fs');
const http = require('http');
const server = http.createServer();
server.on('request', (req, res) => {
fs.createReadStream('./test.txt').pipe(res);
});
server.listen(3000);
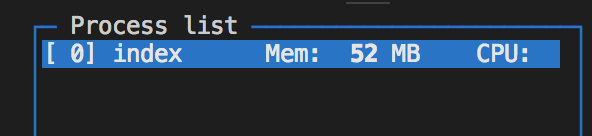
可以看到在使用流的情况下,我们内存的消耗是十分少的。感受到流的魅力了么?一起来学习吧。
从小学数学题开始
大家应该都记得,小学的时候经常碰到这样的题:有一个 x 立方米的水池,一个进水管每秒进水 a 立方米,一个出水管每秒出水 b 立方米,问啥时候水池积满?不知道大家小时候有没有骂过这道题,一边进一边出这不是有病么?哈哈,不扯远了,继续回到我们的流,这个题的模型其实和我们的流很相似,当然了,上面这个题还涉及到了流控的问题,下面再说。
在 Node.js 中,有四种基本的流类型:
- Readable: 可读流,你可以把它想象成进水管,它将数据源以流的方式一点一点的提供给下游。
- Writable: 可写流,这是作为下游来消耗上游提供的数据,你可以把它想象成出水管。
- Duplex: 双工流,即可读也可写。
- Transform: 继承自 Duplex 的双工流,它可以在写入或者读取数据的时候修改数据。
可读流
说可读流之前,先划重点:
- read() 和 _read()
- flowing 和 pause 模式
- 事件 readable 和 data
重点画出来了我们开始一点一点扒可读流,首先,我们要说的就是 read 和 _read 这两个函数,正常情况下,我们在使用可读流的时候,需要提供一个 _read 方法,负责向缓冲区补充数据,它要从数据源拉取数据,然后在这个方法中调用 push 方法把数据推到缓冲池中,当流结束时,我们需要 push(null),而 read(size) 函数是我们要消耗缓冲区的数据的时候使用的方法,不需要我们自己实现。
下面要说的是可读流分两种模式:flowing 和 pause,这两种模式决定了数据流动的方式。
flowing 模式
在 flowing 模式下,数据会源源不断的产生,每次都会触发 data 事件 ,通过监听这个事件来获取数据。
那么在什么情况下会进入 flowing 模式呢?OK,扒源码,通过看可读流的源码,知道在流的属性里有一个 flowing 的属性,这个属性初始化的时候为 null。这时候是处于 pause 模式,我们在当前文件全局搜一下 flowing = 发现当我们调用 resume() 的时候会将这个标志位设为 true,这时候就处于 flowing 模式了,那么还有没有其他的方法呢?答案是肯定的,是有的,看源码:
Readable.prototype.on = function(ev, fn) {
const res = Stream.prototype.on.call(this, ev, fn);
const state = this._readableState;
if(ev === 'data') {
state.readableListening = this.listenerCount('readable') > 0;
if (state.flowing !== false)
this.resume();
} else if ('readable'){
//...
}
return res;
}
我们可以关注到,当我们监听 data 事件的时候,因为当前初始化标志位为 null,所以会去调用 resume(),这时候就会进入 flowing 模式,同时,当可读流调用 pipe 的时候会去监听 data 事件,也会进入 flowing 模式。
那么当你监听 data 事件进入 flowing 模式时,整个代码流程是什么呢?
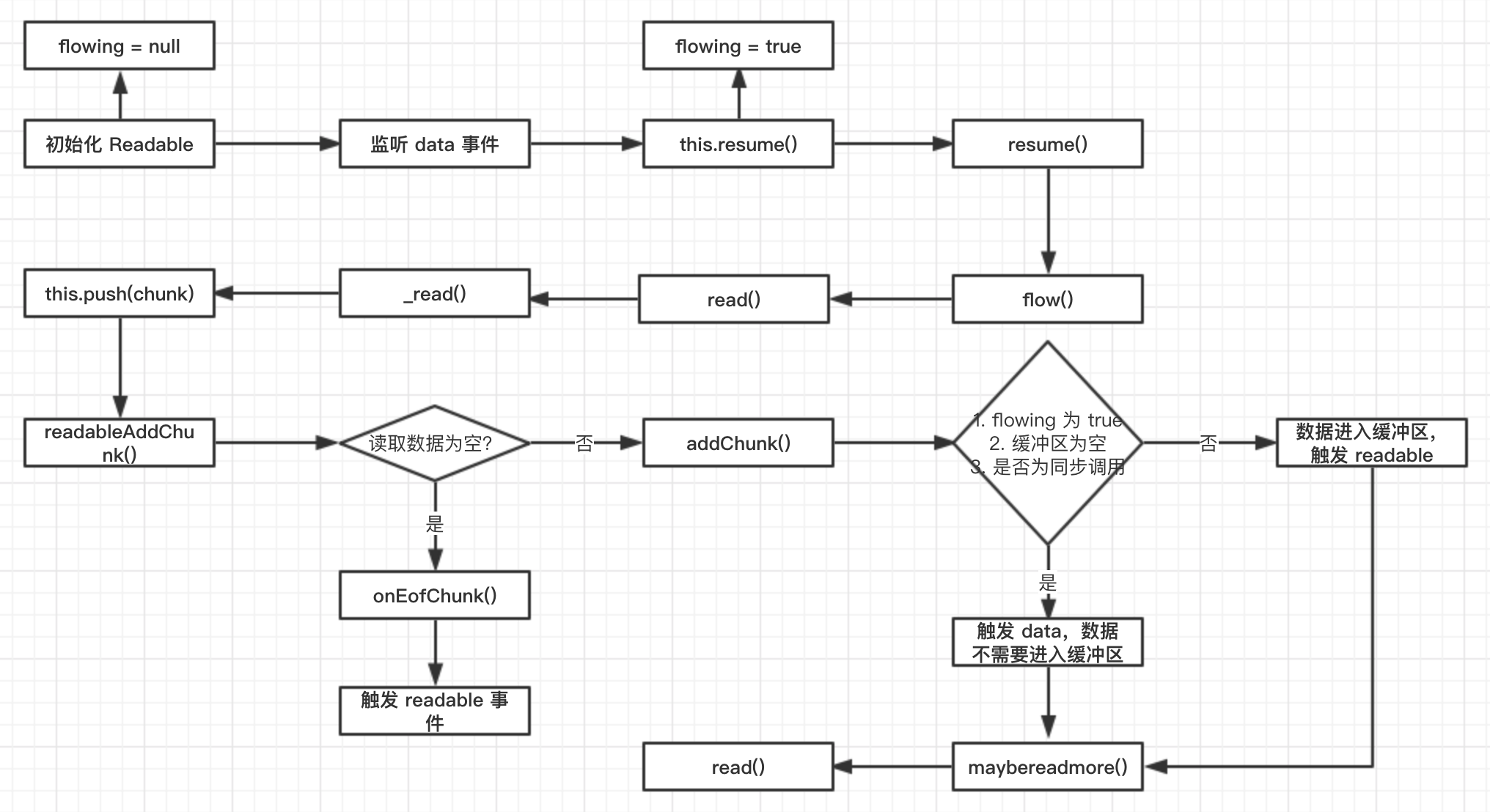
从这张图,我们能看出 flowing 模式的一个大概流程,从初始化开始,flowing = null,然后当我们监听 data 事件,会去调用 this.resume(),这时候就将 flowing 变为 true,然后调用了 resume,在这个函数里,调用了 read(0) 去触发 _read() 向缓冲区补充数据,这里要提一点的是当我们调用 read(0) 的时候,不会破坏缓冲区的数据和状态,并触发 _read 去读取数据到缓冲区。接下来就是不断的循环往复,直到 push(null) 则流结束。
pause 模式
现在知道了 flowing 模式,那么 pause 模式又是怎样的呢?首先我们来看如何进入 pause 模式:
- 刚刚说过,可读流的初始状态就是
pause模式。 - 调用
pause方法 - 调用
unpipe方法
一般来说我们很少会去使用到 pause 模式,在 pause 模式下,我们需要手动的调用 read() 函数去获取数据。
readable 和 data
这两个都是关于数据的事件,至于 end 事件,很简单,就不多说了。
那么 readable 事件代表了什么呢?readable 只负责通知消费者流里有新数据或者流读完了,至于如何使用则是消费者自己的事情了,这时候 read() 就会返回新数据或者是 null。
至于 data 事件,我们看一下上面那张图,这个事件是在流把数据传递给消费者的时候触发的。
那么我们同时监听 data 和 readable 事件会怎么样呢?从上面的图我们可以得知,当监听 data 事件的时候,流直接将数据传递给了消费者,并没有进入缓冲区,只会触发 data 事件,而只有当数据消耗完成时 push(null) 会触发 readable 事件。
可写流
可写流是作为下流来消耗上游的数据,那么开始划重点:
- _write 和 write
- finish 和 prefinishi 事件
和可读流一样,我们需要在初始化流的时候提供一个 _write() 方法,用来向底层写数据,而 write() 方法是用来向可写流提供数据的,注意在 _write 方法中的第三个参数在源码中是一个叫 onwrite 的方法,这是为了表明当前写入数据已经完成了,可以开始写入下面的数据了。可写流的终止信号是调用 end() 方法。
那么可写流是如何监听流结束事件呢?答案是有两个事件可以监听,一个是 prefinish,另一个是 finish。
这两个事件的区别是,finish 是在流的所有数据都写入底层并且回调函数都执行了才会触发,而 prefinish 的触发条件是所有的数据都写入底层,这两者之间还是有一定差异的。
Duplex 和 Tranform
Duplex 的代码量非常少,因为它同时继承了可读流和可写流,它同时包含了这两种流原型上的方法,同时包含了两种流的属性。所以我们既可以实现 _read 将它当成可读流也可以实现 _write 将其当成可写流来使用。
而 Transform 继承了 Duplex,并且关联了两个缓存池,我们向流中写入数据,就能够进行转换,然后再读取,那为什么可以这样操作呢?
我们去看看源码,Transform 自己实现了 _write 和 _read 方法,注意的是这里使用的是同一个缓存,我们来看这么一段代码。
const { Transform } = require('stream')
var transform = Transform({
transform: function (buf, _, next) {
next(null, buf.toString().replace('a', 'b'))
}
})
// 'b'
transform.pipe(process.stdout)
transform.write('a')
transform.end()
上面的代码主要流程是这样的,Transform 调用了继承自可写流的 write 方法,然后这个方法调用自己实现的 _write 将写入的数据存到了 Transform 的缓存中,然后将其转换成 buffer,在其后 _read 函数被调用,在这个函数中调用了在初始化的时候传入转换函数 _transform 对数据进行转换,在转换过后就是 readable.pipe(writable) 的模式了。
还有一点是,Transform 还有一个 _flush 函数,在 prefinish 触发时就会调用它,说明写流结束了。
神器 pipe
在我们进行可写流和可读流的对接的时候我们要处理各种事件,以及流控的问题,就像我们在上面提到的那道题,如果读流速度太快,而写流速度慢,就会导致速度不匹配的问题,而 pipe 实现了一套背压平衡机制来控制两边的速度。
那关于 pipe 的源码解析等等可以去看看这篇文章。
总结
在 Node 里,流是非常重要的一个模块,它能够很好的处理大文件,以及对数据的处理能力。这次对流的学习也是收获了不少东西,与君共勉!
