

简介
变分自编码器(Variational Autoencoder,VAE)是生成式模型(Generative Model)的一种,另一种常见的生成式模型是生成式对抗网络(Generative Adversarial Network,GAN)
这里我们介绍下VAE的原理,并用Keras实现
原理
我们经常会有这样的需求:根据很多个样本,学会生成新的样本
以MNIST为例,在看过几千张手写数字图片之后,我们能进行模仿,并生成一些类似的图片,这些图片在原始数据中并不存在,有一些变化但是看起来相似
换言之,需要学会数据x的分布,这样,根据数据的分布就能轻松地产生新样本
但数据分布的估计不是件容易的事情,尤其是当数据量不足的时候
可以使用一个隐变量z,由z经过一个复杂的映射得到x,并且假设z服从高斯分布
因此只需要学习隐变量所服从高斯分布的参数,以及映射函数,即可得到原始数据的分布
为了学习隐变量所服从高斯分布的参数,需要得到z足够多的样本
然而z的样本并不能直接获得,因此还需要一个映射函数(条件概率分布),从已有的x样本中得到对应的z样本
这看起来和自编码器很相似,从数据本身,经编码得到隐层表示,经解码还原
但VAE和AE的区别如下:
- AE中隐层表示的分布未知,而VAE中隐变量服从高斯分布
- AE中学习的是encoder和decoder,VAE中还学习了隐变量的分布,包括高斯分布的均值和方差
- AE只能从一个x,得到对应的重构x
- VAE可以产生新的z,从而得到新的x,即生成新的样本
损失函数
除了重构误差,由于在VAE中我们假设隐变量z服从高斯分布,因此encoder对应的条件概率分布,应当和高斯分布尽可能相似
可以用相对熵,又称作KL散度(Kullback–Leibler Divergence),来衡量两个分布的差异,或者说距离,但相对熵是非对称的
实现
这里以MNIST为例,学习隐变量z所服从高斯分布的均值和方差两个参数,从而可以从新的z生成原始数据中没有的x
encoder和decoder各用两层全连接层,简单一些,主要为了说明VAE的实现
加载库
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Input, Dense, Lambda
from keras.models import Model
from keras import backend as K
from keras import objectives
from keras.datasets import mnist
定义一些常数
batch_size = 100
original_dim = 784
intermediate_dim = 256
latent_dim = 2
epochs = 50
encoder部分,两层全连接层,隐层表示包括均值和方差
x = Input(shape=(original_dim,))
h = Dense(intermediate_dim, activation='relu')(x)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
Lambda层不参与训练,只参与计算,用于后面产生新的z
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0.)
return z_mean + K.exp(z_log_var / 2) * epsilon
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
decoder部分,两层全连接层,x_decoded_mean为重构的输出
decoder_h = Dense(intermediate_dim, activation='relu')
decoder_mean = Dense(original_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
自定义总的损失函数并编译模型
def vae_loss(x, x_decoded_mean):
xent_loss = original_dim * objectives.binary_crossentropy(x, x_decoded_mean)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return xent_loss + kl_loss
vae = Model(x, x_decoded_mean)
vae.compile(optimizer='rmsprop', loss=vae_loss)
加载数据并训练,CPU训练的速度还算能忍
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
vae.fit(x_train, x_train,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, x_test))
定义一个encoder,看看MNIST中的数据在隐层中变成了什么样子
encoder = Model(x, z_mean)
x_test_encoded = encoder.predict(x_test, batch_size=batch_size)
plt.figure(figsize=(6, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test)
plt.colorbar()
plt.show()
结果如下,说明在二维的隐层中,不同的数字被很好地分开了
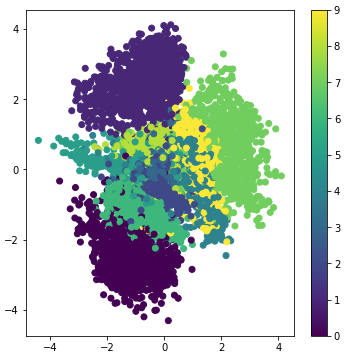
再定义一个生成器,从隐层到输出,用于产生新的样本
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(decoder_input)
_x_decoded_mean = decoder_mean(_h_decoded)
generator = Model(decoder_input, _x_decoded_mean)
用网格化的方法产生一些二维数据,作为新的z输入到生成器,并将生成的x展示出来
n = 20
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
grid_x = np.linspace(-4, 4, n)
grid_y = np.linspace(-4, 4, n)
for i, xi in enumerate(grid_x):
for j, yi in enumerate(grid_y):
z_sample = np.array([[yi, xi]])
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[(n - i - 1) * digit_size: (n - i) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure)
plt.show()
结果如下,和之前看到的隐层图是一致的,甚至能看到一些数字之间的过渡态

由于包含一些随机因素,所以每次生成的结果会存在一些差异
如果将全连接层换成CNN,应该可以得到更好的表示结果
拓展
掌握以上内容后,用相同的方法,可以在FashionMNIST这个数据集上再跑一遍,数据集规模和MNIST完全相同

只需改动四行即可
from keras.datasets import fashion_mnist
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
grid_x = np.linspace(-3, 3, n)
grid_y = np.linspace(-3, 3, n)
完整代码如下
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from keras.layers import Input, Dense, Lambda
from keras.models import Model
from keras import backend as K
from keras import objectives
from keras.datasets import fashion_mnist
batch_size = 100
original_dim = 784
intermediate_dim = 256
latent_dim = 2
epochs = 50
x = Input(shape=(original_dim,))
h = Dense(intermediate_dim, activation='relu')(x)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(batch_size, latent_dim), mean=0.)
return z_mean + K.exp(z_log_var / 2) * epsilon
z = Lambda(sampling, output_shape=(latent_dim,))([z_mean, z_log_var])
decoder_h = Dense(intermediate_dim, activation='relu')
decoder_mean = Dense(original_dim, activation='sigmoid')
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
def vae_loss(x, x_decoded_mean):
xent_loss = original_dim * objectives.binary_crossentropy(x, x_decoded_mean)
kl_loss = -0.5 * K.sum(1 + z_log_var - K.square(z_mean) - K.exp(z_log_var), axis=-1)
return xent_loss + kl_loss
vae = Model(x, x_decoded_mean)
vae.compile(optimizer='rmsprop', loss=vae_loss)
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
vae.fit(x_train, x_train,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(x_test, x_test))
encoder = Model(x, z_mean)
x_test_encoded = encoder.predict(x_test, batch_size=batch_size)
plt.figure(figsize=(6, 6))
plt.scatter(x_test_encoded[:, 0], x_test_encoded[:, 1], c=y_test)
plt.colorbar()
plt.show()
decoder_input = Input(shape=(latent_dim,))
_h_decoded = decoder_h(decoder_input)
_x_decoded_mean = decoder_mean(_h_decoded)
generator = Model(decoder_input, _x_decoded_mean)
n = 20
digit_size = 28
figure = np.zeros((digit_size * n, digit_size * n))
grid_x = np.linspace(-3, 3, n)
grid_y = np.linspace(-3, 3, n)
for i, xi in enumerate(grid_x):
for j, yi in enumerate(grid_y):
z_sample = np.array([[yi, xi]])
x_decoded = generator.predict(z_sample)
digit = x_decoded[0].reshape(digit_size, digit_size)
figure[(n - i - 1) * digit_size: (n - i) * digit_size,
j * digit_size: (j + 1) * digit_size] = digit
plt.figure(figsize=(10, 10))
plt.imshow(figure)
plt.show()
我们来看一下隐层的表示,同样起到了很好的分类效果
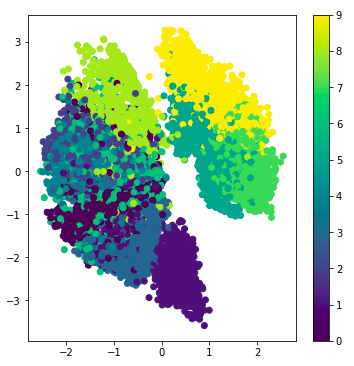
然后再来生成一些图形,可以看到不同种类衣服之间的过渡
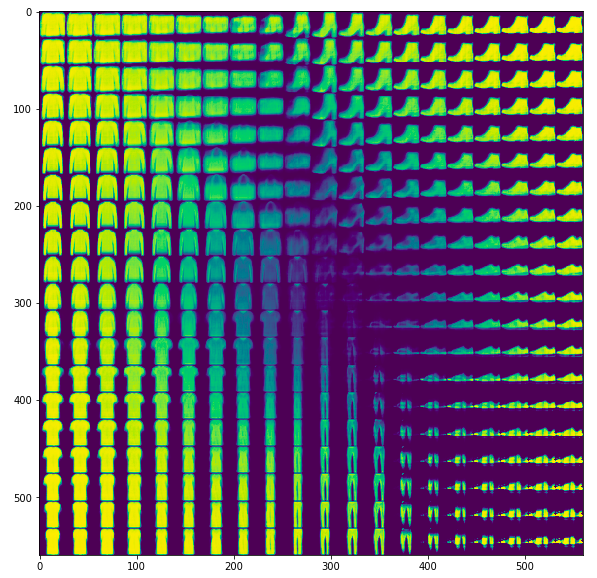
参考
- Auto-Encoding Variational Bayes:arxiv.org/pdf/1312.61…
- Tutorial on Variational Autoencoders:arxiv.org/pdf/1606.05…
- Building Autoencoders in Keras:blog.keras.io/building-au…
- Fashion-MNIST database of fashion articles:keras.io/datasets/#f…
- 【啄米日常】变分编码器VAE:zhuanlan.zhihu.com/p/25269592
