

简介
介绍CGAN和ACGAN的原理,通过引入额外的Condition来控制生成的图片,并在DCGAN和WGAN的基础上进行实现
CGAN原理
样本x可以包含一些属性,或者说条件,记作y
例如MNIST中每张图片对应的数字可以是0至9
从一张图来了解CGAN(Conditional GAN)的思想
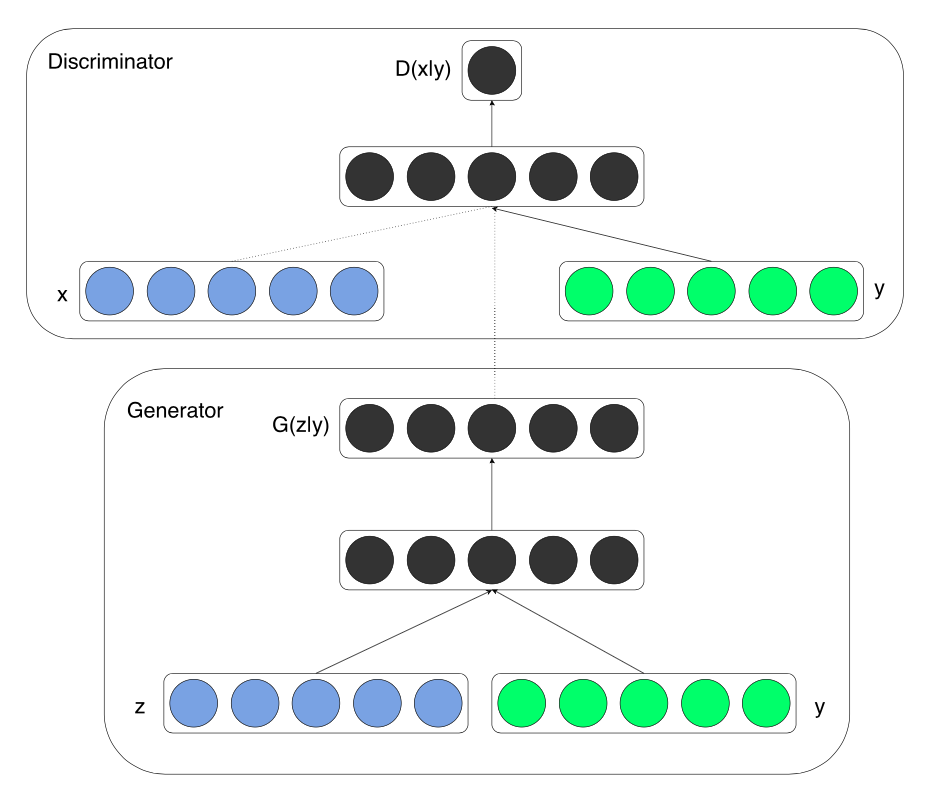
生成器G从随机噪音z和条件y生成假样本,判别器D接受真假样本和条件y,判断样本是否为满足条件y的真实样本
总的目标函数如下
实现
先用MNIST,在DCGAN的基础上稍作改动以实现CGAN
加载库
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import os, imageio
from tqdm import tqdm
加载数据,指定one_hot=True
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
定义一些常量、网络输入、辅助函数,这里加上了y_label和y_noise
batch_size = 100
z_dim = 100
WIDTH = 28
HEIGHT = 28
LABEL = 10
OUTPUT_DIR = 'samples'
if not os.path.exists(OUTPUT_DIR):
os.mkdir(OUTPUT_DIR)
X = tf.placeholder(dtype=tf.float32, shape=[None, HEIGHT, WIDTH, 1], name='X')
y_label = tf.placeholder(dtype=tf.float32, shape=[None, HEIGHT, WIDTH, LABEL], name='y_label')
noise = tf.placeholder(dtype=tf.float32, shape=[None, z_dim], name='noise')
y_noise = tf.placeholder(dtype=tf.float32, shape=[None, LABEL], name='y_noise')
is_training = tf.placeholder(dtype=tf.bool, name='is_training')
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
def sigmoid_cross_entropy_with_logits(x, y):
return tf.nn.sigmoid_cross_entropy_with_logits(logits=x, labels=y)
判别器部分
def discriminator(image, label, reuse=None, is_training=is_training):
momentum = 0.9
with tf.variable_scope('discriminator', reuse=reuse):
h0 = tf.concat([image, label], axis=3)
h0 = lrelu(tf.layers.conv2d(h0, kernel_size=5, filters=64, strides=2, padding='same'))
h1 = tf.layers.conv2d(h0, kernel_size=5, filters=128, strides=2, padding='same')
h1 = lrelu(tf.contrib.layers.batch_norm(h1, is_training=is_training, decay=momentum))
h2 = tf.layers.conv2d(h1, kernel_size=5, filters=256, strides=2, padding='same')
h2 = lrelu(tf.contrib.layers.batch_norm(h2, is_training=is_training, decay=momentum))
h3 = tf.layers.conv2d(h2, kernel_size=5, filters=512, strides=2, padding='same')
h3 = lrelu(tf.contrib.layers.batch_norm(h3, is_training=is_training, decay=momentum))
h4 = tf.contrib.layers.flatten(h3)
h4 = tf.layers.dense(h4, units=1)
return tf.nn.sigmoid(h4), h4
生成器部分
def generator(z, label, is_training=is_training):
momentum = 0.9
with tf.variable_scope('generator', reuse=None):
d = 3
z = tf.concat([z, label], axis=1)
h0 = tf.layers.dense(z, units=d * d * 512)
h0 = tf.reshape(h0, shape=[-1, d, d, 512])
h0 = tf.nn.relu(tf.contrib.layers.batch_norm(h0, is_training=is_training, decay=momentum))
h1 = tf.layers.conv2d_transpose(h0, kernel_size=5, filters=256, strides=2, padding='same')
h1 = tf.nn.relu(tf.contrib.layers.batch_norm(h1, is_training=is_training, decay=momentum))
h2 = tf.layers.conv2d_transpose(h1, kernel_size=5, filters=128, strides=2, padding='same')
h2 = tf.nn.relu(tf.contrib.layers.batch_norm(h2, is_training=is_training, decay=momentum))
h3 = tf.layers.conv2d_transpose(h2, kernel_size=5, filters=64, strides=2, padding='same')
h3 = tf.nn.relu(tf.contrib.layers.batch_norm(h3, is_training=is_training, decay=momentum))
h4 = tf.layers.conv2d_transpose(h3, kernel_size=5, filters=1, strides=1, padding='valid', activation=tf.nn.tanh, name='g')
return h4
损失函数
g = generator(noise, y_noise)
d_real, d_real_logits = discriminator(X, y_label)
d_fake, d_fake_logits = discriminator(g, y_label, reuse=True)
vars_g = [var for var in tf.trainable_variables() if var.name.startswith('generator')]
vars_d = [var for var in tf.trainable_variables() if var.name.startswith('discriminator')]
loss_d_real = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_real_logits, tf.ones_like(d_real)))
loss_d_fake = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_fake_logits, tf.zeros_like(d_fake)))
loss_g = tf.reduce_mean(sigmoid_cross_entropy_with_logits(d_fake_logits, tf.ones_like(d_fake)))
loss_d = loss_d_real + loss_d_fake
优化函数
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer_d = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_d, var_list=vars_d)
optimizer_g = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_g, var_list=vars_g)
拼接图片的函数
def montage(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
m = np.ones((images.shape[1] * n_plots + n_plots + 1, images.shape[2] * n_plots + n_plots + 1)) * 0.5
for i in range(n_plots):
for j in range(n_plots):
this_filter = i * n_plots + j
if this_filter < images.shape[0]:
this_img = images[this_filter]
m[1 + i + i * img_h:1 + i + (i + 1) * img_h,
1 + j + j * img_w:1 + j + (j + 1) * img_w] = this_img
return m
训练模型,加入条件信息
sess = tf.Session()
sess.run(tf.global_variables_initializer())
z_samples = np.random.uniform(-1.0, 1.0, [batch_size, z_dim]).astype(np.float32)
y_samples = np.zeros([batch_size, LABEL])
for i in range(LABEL):
for j in range(LABEL):
y_samples[i * LABEL + j, i] = 1
samples = []
loss = {'d': [], 'g': []}
for i in tqdm(range(60000)):
n = np.random.uniform(-1.0, 1.0, [batch_size, z_dim]).astype(np.float32)
batch, label = mnist.train.next_batch(batch_size=batch_size)
batch = np.reshape(batch, [batch_size, HEIGHT, WIDTH, 1])
batch = (batch - 0.5) * 2
yn = np.copy(label)
yl = np.reshape(label, [batch_size, 1, 1, LABEL])
yl = yl * np.ones([batch_size, HEIGHT, WIDTH, LABEL])
d_ls, g_ls = sess.run([loss_d, loss_g], feed_dict={X: batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
loss['d'].append(d_ls)
loss['g'].append(g_ls)
sess.run(optimizer_d, feed_dict={X: batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
sess.run(optimizer_g, feed_dict={X: batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
sess.run(optimizer_g, feed_dict={X: batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
if i % 1000 == 0:
print(i, d_ls, g_ls)
gen_imgs = sess.run(g, feed_dict={noise: z_samples, y_noise: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, 0] for img in gen_imgs]
gen_imgs = montage(imgs)
plt.axis('off')
plt.imshow(gen_imgs, cmap='gray')
imageio.imsave(os.path.join(OUTPUT_DIR, 'sample_%d.jpg' % i), gen_imgs)
plt.show()
samples.append(gen_imgs)
plt.plot(loss['d'], label='Discriminator')
plt.plot(loss['g'], label='Generator')
plt.legend(loc='upper right')
plt.savefig('Loss.png')
plt.show()
imageio.mimsave(os.path.join(OUTPUT_DIR, 'samples.gif'), samples, fps=5)
生成的手写数字图片如下,每一行对应的数字相同

保存模型,便于后续使用
saver = tf.train.Saver()
saver.save(sess, './mnist_cgan', global_step=60000)
在单机上使用模型生成手写数字图片
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
batch_size = 100
z_dim = 100
LABEL = 10
def montage(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
m = np.ones((images.shape[1] * n_plots + n_plots + 1, images.shape[2] * n_plots + n_plots + 1)) * 0.5
for i in range(n_plots):
for j in range(n_plots):
this_filter = i * n_plots + j
if this_filter < images.shape[0]:
this_img = images[this_filter]
m[1 + i + i * img_h:1 + i + (i + 1) * img_h,
1 + j + j * img_w:1 + j + (j + 1) * img_w] = this_img
return m
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('./mnist_cgan-60000.meta')
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
g = graph.get_tensor_by_name('generator/g/Tanh:0')
noise = graph.get_tensor_by_name('noise:0')
y_noise = graph.get_tensor_by_name('y_noise:0')
is_training = graph.get_tensor_by_name('is_training:0')
n = np.random.uniform(-1.0, 1.0, [batch_size, z_dim]).astype(np.float32)
y_samples = np.zeros([batch_size, LABEL])
for i in range(LABEL):
for j in range(LABEL):
y_samples[i * LABEL + j, i] = 1
gen_imgs = sess.run(g, feed_dict={noise: n, y_noise: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, 0] for img in gen_imgs]
gen_imgs = montage(imgs)
plt.axis('off')
plt.imshow(gen_imgs, cmap='gray')
plt.show()
讲条件的CelebA
了解CGAN的原理和实现之后,再尝试下别的数据集,比如之前用过的CelebA
CelebA提供了每张图片40个属性的01标注,这里将Male(是否为男性)作为条件,在WGAN的基础上实现CGAN
加载库
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
%matplotlib inline
from imageio import imread, imsave, mimsave
import cv2
import glob
from tqdm import tqdm
加载图片
images = glob.glob('celeba/*.jpg')
print(len(images))
读取图片的Male标签
tags = {}
target = 'Male'
with open('list_attr_celeba.txt', 'r') as fr:
lines = fr.readlines()
all_tags = lines[0].strip('\n').split()
for i in range(1, len(lines)):
line = lines[i].strip('\n').split()
if int(line[all_tags.index(target) + 1]) == 1:
tags[line[0]] = [1, 0] # 男
else:
tags[line[0]] = [0, 1] # 女
print(len(tags))
print(all_tags)
定义一些常量、网络输入、辅助函数
batch_size = 100
z_dim = 100
WIDTH = 64
HEIGHT = 64
LABEL = 2
LAMBDA = 10
DIS_ITERS = 3 # 5
OUTPUT_DIR = 'samples'
if not os.path.exists(OUTPUT_DIR):
os.mkdir(OUTPUT_DIR)
X = tf.placeholder(dtype=tf.float32, shape=[batch_size, HEIGHT, WIDTH, 3], name='X')
y_label = tf.placeholder(dtype=tf.float32, shape=[batch_size, HEIGHT, WIDTH, LABEL], name='y_label')
noise = tf.placeholder(dtype=tf.float32, shape=[batch_size, z_dim], name='noise')
y_noise = tf.placeholder(dtype=tf.float32, shape=[batch_size, LABEL], name='y_noise')
is_training = tf.placeholder(dtype=tf.bool, name='is_training')
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
判别器部分
def discriminator(image, label, reuse=None, is_training=is_training):
momentum = 0.9
with tf.variable_scope('discriminator', reuse=reuse):
h0 = tf.concat([image, label], axis=3)
h0 = lrelu(tf.layers.conv2d(h0, kernel_size=5, filters=64, strides=2, padding='same'))
h1 = lrelu(tf.layers.conv2d(h0, kernel_size=5, filters=128, strides=2, padding='same'))
h2 = lrelu(tf.layers.conv2d(h1, kernel_size=5, filters=256, strides=2, padding='same'))
h3 = lrelu(tf.layers.conv2d(h2, kernel_size=5, filters=512, strides=2, padding='same'))
h4 = tf.contrib.layers.flatten(h3)
h4 = tf.layers.dense(h4, units=1)
return h4
生成器部分
def generator(z, label, is_training=is_training):
momentum = 0.9
with tf.variable_scope('generator', reuse=None):
d = 4
z = tf.concat([z, label], axis=1)
h0 = tf.layers.dense(z, units=d * d * 512)
h0 = tf.reshape(h0, shape=[-1, d, d, 512])
h0 = tf.nn.relu(tf.contrib.layers.batch_norm(h0, is_training=is_training, decay=momentum))
h1 = tf.layers.conv2d_transpose(h0, kernel_size=5, filters=256, strides=2, padding='same')
h1 = tf.nn.relu(tf.contrib.layers.batch_norm(h1, is_training=is_training, decay=momentum))
h2 = tf.layers.conv2d_transpose(h1, kernel_size=5, filters=128, strides=2, padding='same')
h2 = tf.nn.relu(tf.contrib.layers.batch_norm(h2, is_training=is_training, decay=momentum))
h3 = tf.layers.conv2d_transpose(h2, kernel_size=5, filters=64, strides=2, padding='same')
h3 = tf.nn.relu(tf.contrib.layers.batch_norm(h3, is_training=is_training, decay=momentum))
h4 = tf.layers.conv2d_transpose(h3, kernel_size=5, filters=3, strides=2, padding='same', activation=tf.nn.tanh, name='g')
return h4
定义损失函数
g = generator(noise, y_noise)
d_real = discriminator(X, y_label)
d_fake = discriminator(g, y_label, reuse=True)
loss_d_real = -tf.reduce_mean(d_real)
loss_d_fake = tf.reduce_mean(d_fake)
loss_g = -tf.reduce_mean(d_fake)
loss_d = loss_d_real + loss_d_fake
alpha = tf.random_uniform(shape=[batch_size, 1, 1, 1], minval=0., maxval=1.)
interpolates = alpha * X + (1 - alpha) * g
grad = tf.gradients(discriminator(interpolates, y_label, reuse=True), [interpolates])[0]
slop = tf.sqrt(tf.reduce_sum(tf.square(grad), axis=[1]))
gp = tf.reduce_mean((slop - 1.) ** 2)
loss_d += LAMBDA * gp
vars_g = [var for var in tf.trainable_variables() if var.name.startswith('generator')]
vars_d = [var for var in tf.trainable_variables() if var.name.startswith('discriminator')]
定义优化器
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer_d = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_d, var_list=vars_d)
optimizer_g = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_g, var_list=vars_g)
拼接图片的函数
def montage(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
if len(images.shape) == 4 and images.shape[3] == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 3)) * 0.5
elif len(images.shape) == 4 and images.shape[3] == 1:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 1)) * 0.5
elif len(images.shape) == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1)) * 0.5
else:
raise ValueError('Could not parse image shape of {}'.format(images.shape))
for i in range(n_plots):
for j in range(n_plots):
this_filter = i * n_plots + j
if this_filter < images.shape[0]:
this_img = images[this_filter]
m[1 + i + i * img_h:1 + i + (i + 1) * img_h,
1 + j + j * img_w:1 + j + (j + 1) * img_w] = this_img
return m
整理数据
X_all = []
Y_all = []
for i in tqdm(range(len(images))):
image = imread(images[i])
h = image.shape[0]
w = image.shape[1]
if h > w:
image = image[h // 2 - w // 2: h // 2 + w // 2, :, :]
else:
image = image[:, w // 2 - h // 2: w // 2 + h // 2, :]
image = cv2.resize(image, (WIDTH, HEIGHT))
image = (image / 255. - 0.5) * 2
X_all.append(image)
image_name = images[i][images[i].find('/') + 1:]
Y_all.append(tags[image_name])
X_all = np.array(X_all)
Y_all = np.array(Y_all)
print(X_all.shape, Y_all.shape)
查看数据样例
for i in range(10):
plt.imshow((X_all[i, :, :, :] + 1) / 2)
plt.show()
print(Y_all[i, :])
定义随机产生批数据的函数
def get_random_batch():
data_index = np.arange(X_all.shape[0])
np.random.shuffle(data_index)
data_index = data_index[:batch_size]
X_batch = X_all[data_index, :, :, :]
Y_batch = Y_all[data_index, :]
yn = np.copy(Y_batch)
yl = np.reshape(Y_batch, [batch_size, 1, 1, LABEL])
yl = yl * np.ones([batch_size, HEIGHT, WIDTH, LABEL])
return X_batch, yn, yl
训练模型
sess = tf.Session()
sess.run(tf.global_variables_initializer())
zs = np.random.uniform(-1.0, 1.0, [batch_size // 2, z_dim]).astype(np.float32)
z_samples = []
y_samples = []
for i in range(batch_size // 2):
z_samples.append(zs[i, :])
y_samples.append([1, 0])
z_samples.append(zs[i, :])
y_samples.append([0, 1])
samples = []
loss = {'d': [], 'g': []}
for i in tqdm(range(60000)):
for j in range(DIS_ITERS):
n = np.random.uniform(-1.0, 1.0, [batch_size, z_dim]).astype(np.float32)
X_batch, yn, yl = get_random_batch()
_, d_ls = sess.run([optimizer_d, loss_d], feed_dict={X: X_batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
_, g_ls = sess.run([optimizer_g, loss_g], feed_dict={X: X_batch, noise: n, y_label: yl, y_noise: yn, is_training: True})
loss['d'].append(d_ls)
loss['g'].append(g_ls)
if i % 500 == 0:
print(i, d_ls, g_ls)
gen_imgs = sess.run(g, feed_dict={noise: z_samples, y_noise: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, :] for img in gen_imgs]
gen_imgs = montage(imgs)
plt.axis('off')
plt.imshow(gen_imgs)
imsave(os.path.join(OUTPUT_DIR, 'sample_%d.jpg' % i), gen_imgs)
plt.show()
samples.append(gen_imgs)
plt.plot(loss['d'], label='Discriminator')
plt.plot(loss['g'], label='Generator')
plt.legend(loc='upper right')
plt.savefig('Loss.png')
plt.show()
mimsave(os.path.join(OUTPUT_DIR, 'samples.gif'), samples, fps=10)
结果如下,对于每一组图片,噪音部分相同但条件不同,男左女右

保存模型
saver = tf.train.Saver()
saver.save(sess, './celeba_cgan', global_step=60000)
ACGAN
再通过一张图了解ACGAN(Auxiliary Classifier GAN)的原理
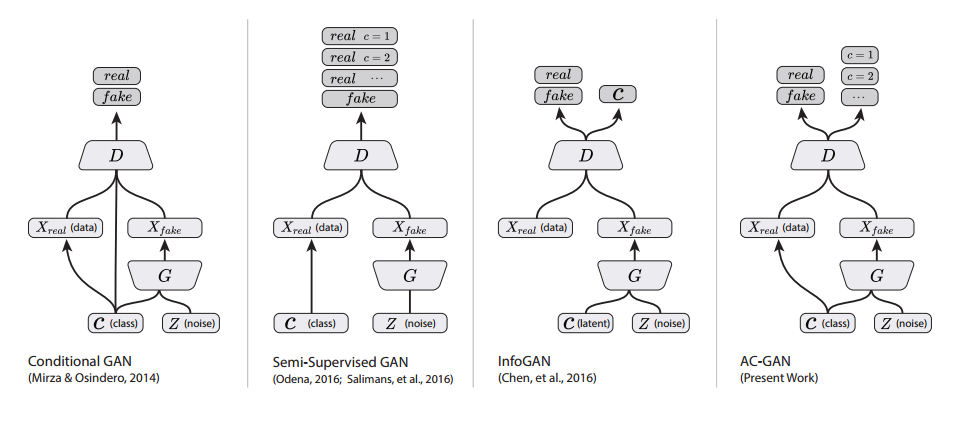
和CGAN不同的是,C不直接输入D。D不仅需要判断每个样本的真假,还需要完成一个分类任务即预测C,通过增加一个辅助分类器实现
对D而言,损失函数如下
对G而言,损失函数如下
还是以CelebA的Male作为条件,在WGAN的基础上实现ACGAN
加载库
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import os
import matplotlib.pyplot as plt
%matplotlib inline
from imageio import imread, imsave, mimsave
import cv2
import glob
from tqdm import tqdm
加载图片
images = glob.glob('celeba/*.jpg')
print(len(images))
读取图片的Male标签
tags = {}
target = 'Male'
with open('list_attr_celeba.txt', 'r') as fr:
lines = fr.readlines()
all_tags = lines[0].strip('\n').split()
for i in range(1, len(lines)):
line = lines[i].strip('\n').split()
if int(line[all_tags.index(target) + 1]) == 1:
tags[line[0]] = [1, 0] # 男
else:
tags[line[0]] = [0, 1] # 女
print(len(tags))
print(all_tags)
定义一些常量、网络输入、辅助函数
batch_size = 100
z_dim = 100
WIDTH = 64
HEIGHT = 64
LABEL = 2
LAMBDA = 10
DIS_ITERS = 3 # 5
OUTPUT_DIR = 'samples'
if not os.path.exists(OUTPUT_DIR):
os.mkdir(OUTPUT_DIR)
X = tf.placeholder(dtype=tf.float32, shape=[batch_size, HEIGHT, WIDTH, 3], name='X')
Y = tf.placeholder(dtype=tf.float32, shape=[batch_size, LABEL], name='Y')
noise = tf.placeholder(dtype=tf.float32, shape=[batch_size, z_dim], name='noise')
is_training = tf.placeholder(dtype=tf.bool, name='is_training')
def lrelu(x, leak=0.2):
return tf.maximum(x, leak * x)
判别器部分,去掉条件输入,增加分类输出
def discriminator(image, reuse=None, is_training=is_training):
momentum = 0.9
with tf.variable_scope('discriminator', reuse=reuse):
h0 = lrelu(tf.layers.conv2d(image, kernel_size=5, filters=64, strides=2, padding='same'))
h1 = lrelu(tf.layers.conv2d(h0, kernel_size=5, filters=128, strides=2, padding='same'))
h2 = lrelu(tf.layers.conv2d(h1, kernel_size=5, filters=256, strides=2, padding='same'))
h3 = lrelu(tf.layers.conv2d(h2, kernel_size=5, filters=512, strides=2, padding='same'))
h4 = tf.contrib.layers.flatten(h3)
Y_ = tf.layers.dense(h4, units=LABEL)
h4 = tf.layers.dense(h4, units=1)
return h4, Y_
生成器部分,没有任何改动
def generator(z, label, is_training=is_training):
momentum = 0.9
with tf.variable_scope('generator', reuse=None):
d = 4
z = tf.concat([z, label], axis=1)
h0 = tf.layers.dense(z, units=d * d * 512)
h0 = tf.reshape(h0, shape=[-1, d, d, 512])
h0 = tf.nn.relu(tf.contrib.layers.batch_norm(h0, is_training=is_training, decay=momentum))
h1 = tf.layers.conv2d_transpose(h0, kernel_size=5, filters=256, strides=2, padding='same')
h1 = tf.nn.relu(tf.contrib.layers.batch_norm(h1, is_training=is_training, decay=momentum))
h2 = tf.layers.conv2d_transpose(h1, kernel_size=5, filters=128, strides=2, padding='same')
h2 = tf.nn.relu(tf.contrib.layers.batch_norm(h2, is_training=is_training, decay=momentum))
h3 = tf.layers.conv2d_transpose(h2, kernel_size=5, filters=64, strides=2, padding='same')
h3 = tf.nn.relu(tf.contrib.layers.batch_norm(h3, is_training=is_training, decay=momentum))
h4 = tf.layers.conv2d_transpose(h3, kernel_size=5, filters=3, strides=2, padding='same', activation=tf.nn.tanh, name='g')
return h4
定义损失函数,加上分类部分对应的损失。理论上分类问题应该用交叉熵作为损失函数,这里使用MSE效果也不错
g = generator(noise, Y)
d_real, y_real = discriminator(X)
d_fake, y_fake = discriminator(g, reuse=True)
loss_d_real = -tf.reduce_mean(d_real)
loss_d_fake = tf.reduce_mean(d_fake)
loss_cls_real = tf.losses.mean_squared_error(Y, y_real)
loss_cls_fake = tf.losses.mean_squared_error(Y, y_fake)
loss_d = loss_d_real + loss_d_fake + loss_cls_real
loss_g = -tf.reduce_mean(d_fake) + loss_cls_fake
alpha = tf.random_uniform(shape=[batch_size, 1, 1, 1], minval=0., maxval=1.)
interpolates = alpha * X + (1 - alpha) * g
grad = tf.gradients(discriminator(interpolates, reuse=True), [interpolates])[0]
slop = tf.sqrt(tf.reduce_sum(tf.square(grad), axis=[1]))
gp = tf.reduce_mean((slop - 1.) ** 2)
loss_d += LAMBDA * gp
vars_g = [var for var in tf.trainable_variables() if var.name.startswith('generator')]
vars_d = [var for var in tf.trainable_variables() if var.name.startswith('discriminator')]
定义优化器
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
optimizer_d = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_d, var_list=vars_d)
optimizer_g = tf.train.AdamOptimizer(learning_rate=0.0002, beta1=0.5).minimize(loss_g, var_list=vars_g)
拼接图片的函数
def montage(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
if len(images.shape) == 4 and images.shape[3] == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 3)) * 0.5
elif len(images.shape) == 4 and images.shape[3] == 1:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 1)) * 0.5
elif len(images.shape) == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1)) * 0.5
else:
raise ValueError('Could not parse image shape of {}'.format(images.shape))
for i in range(n_plots):
for j in range(n_plots):
this_filter = i * n_plots + j
if this_filter < images.shape[0]:
this_img = images[this_filter]
m[1 + i + i * img_h:1 + i + (i + 1) * img_h,
1 + j + j * img_w:1 + j + (j + 1) * img_w] = this_img
return m
整理数据
X_all = []
Y_all = []
for i in tqdm(range(len(images))):
image = imread(images[i])
h = image.shape[0]
w = image.shape[1]
if h > w:
image = image[h // 2 - w // 2: h // 2 + w // 2, :, :]
else:
image = image[:, w // 2 - h // 2: w // 2 + h // 2, :]
image = cv2.resize(image, (WIDTH, HEIGHT))
image = (image / 255. - 0.5) * 2
X_all.append(image)
image_name = images[i][images[i].find('/') + 1:]
Y_all.append(tags[image_name])
X_all = np.array(X_all)
Y_all = np.array(Y_all)
print(X_all.shape, Y_all.shape)
查看数据样例
for i in range(10):
plt.imshow((X_all[i, :, :, :] + 1) / 2)
plt.show()
print(Y_all[i, :])
定义随机产生批数据的函数
def get_random_batch():
data_index = np.arange(X_all.shape[0])
np.random.shuffle(data_index)
data_index = data_index[:batch_size]
X_batch = X_all[data_index, :, :, :]
Y_batch = Y_all[data_index, :]
return X_batch, Y_batch
训练模型,根据ACGAN作相应调整
sess = tf.Session()
sess.run(tf.global_variables_initializer())
zs = np.random.uniform(-1.0, 1.0, [batch_size // 2, z_dim]).astype(np.float32)
z_samples = []
y_samples = []
for i in range(batch_size // 2):
z_samples.append(zs[i, :])
y_samples.append([1, 0])
z_samples.append(zs[i, :])
y_samples.append([0, 1])
samples = []
loss = {'d': [], 'g': []}
for i in tqdm(range(60000)):
for j in range(DIS_ITERS):
n = np.random.uniform(-1.0, 1.0, [batch_size, z_dim]).astype(np.float32)
X_batch, Y_batch = get_random_batch()
_, d_ls = sess.run([optimizer_d, loss_d], feed_dict={X: X_batch, Y: Y_batch, noise: n, is_training: True})
_, g_ls = sess.run([optimizer_g, loss_g], feed_dict={X: X_batch, Y: Y_batch, noise: n, is_training: True})
loss['d'].append(d_ls)
loss['g'].append(g_ls)
if i % 500 == 0:
print(i, d_ls, g_ls)
gen_imgs = sess.run(g, feed_dict={noise: z_samples, Y: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, :] for img in gen_imgs]
gen_imgs = montage(imgs)
plt.axis('off')
plt.imshow(gen_imgs)
imsave(os.path.join(OUTPUT_DIR, 'sample_%d.jpg' % i), gen_imgs)
plt.show()
samples.append(gen_imgs)
plt.plot(loss['d'], label='Discriminator')
plt.plot(loss['g'], label='Generator')
plt.legend(loc='upper right')
plt.savefig('Loss.png')
plt.show()
mimsave(os.path.join(OUTPUT_DIR, 'samples.gif'), samples, fps=10)
结果如下,比CGAN的结果好一些,崩掉的情况比较少,而且人脸更真实更清晰

保存模型
saver = tf.train.Saver()
saver.save(sess, './celeba_acgan', global_step=60000)
在单机上加载模型,进行以下两个尝试:
- 固定噪音,渐变条件;
- 固定条件,渐变噪音。
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
batch_size = 100
z_dim = 100
LABEL = 2
def montage(images):
if isinstance(images, list):
images = np.array(images)
img_h = images.shape[1]
img_w = images.shape[2]
n_plots = int(np.ceil(np.sqrt(images.shape[0])))
if len(images.shape) == 4 and images.shape[3] == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 3)) * 0.5
elif len(images.shape) == 4 and images.shape[3] == 1:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1, 1)) * 0.5
elif len(images.shape) == 3:
m = np.ones(
(images.shape[1] * n_plots + n_plots + 1,
images.shape[2] * n_plots + n_plots + 1)) * 0.5
else:
raise ValueError('Could not parse image shape of {}'.format(images.shape))
for i in range(n_plots):
for j in range(n_plots):
this_filter = i * n_plots + j
if this_filter < images.shape[0]:
this_img = images[this_filter]
m[1 + i + i * img_h:1 + i + (i + 1) * img_h,
1 + j + j * img_w:1 + j + (j + 1) * img_w] = this_img
return m
sess = tf.Session()
sess.run(tf.global_variables_initializer())
saver = tf.train.import_meta_graph('./celeba_acgan-60000.meta')
saver.restore(sess, tf.train.latest_checkpoint('./'))
graph = tf.get_default_graph()
g = graph.get_tensor_by_name('generator/g/Tanh:0')
noise = graph.get_tensor_by_name('noise:0')
Y = graph.get_tensor_by_name('Y:0')
is_training = graph.get_tensor_by_name('is_training:0')
# 固定噪音,渐变条件
n = np.random.uniform(-1.0, 1.0, [10, z_dim]).astype(np.float32)
ns = []
y_samples = []
for i in range(100):
ns.append(n[i // 10, :])
y_samples.append([i % 10 / 9, 1 - i % 10 / 9])
gen_imgs = sess.run(g, feed_dict={noise: ns, Y: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, :] for img in gen_imgs]
gen_imgs = montage(imgs)
gen_imgs = np.clip(gen_imgs, 0, 1)
plt.figure(figsize=(8, 8))
plt.axis('off')
plt.imshow(gen_imgs)
plt.show()
# 固定条件,渐变噪音
n = np.random.uniform(-1.0, 1.0, [5, 2, z_dim]).astype(np.float32)
ns = []
y_samples = []
for i in range(5):
for k in range(2):
for j in range(10):
start = n[i, 0, :]
end = n[i, 1, :]
ns.append(start + j * (end - start) / 9)
if k == 0:
y_samples.append([0, 1])
else:
y_samples.append([1, 0])
gen_imgs = sess.run(g, feed_dict={noise: ns, Y: y_samples, is_training: False})
gen_imgs = (gen_imgs + 1) / 2
imgs = [img[:, :, :] for img in gen_imgs]
gen_imgs = montage(imgs)
gen_imgs = np.clip(gen_imgs, 0, 1)
plt.figure(figsize=(8, 8))
plt.axis('off')
plt.imshow(gen_imgs)
plt.show()
由女变男的过程

人脸两两之间的渐变

参考
- Conditional Generative Adversarial Nets:arxiv.org/abs/1411.17…
- Conditional Image Synthesis With Auxiliary Classifier GANs:arxiv.org/abs/1610.09…
