


Google Development Days China 2018近日在中国召开了。非常遗憾,小编因为不可抗性因素滞留在合肥,没办法去参加。但是小编的朋友有幸参加了会议,带来了关于tensorlfow的一手资料。这里跟随小编来关注tensorflow在生产环境下的最佳应用情况。
Google Brain软件工程师冯亦菲为我们带来了题为“用Tensorflow高层API来进行模型原型设计、训练和生产投入”的精彩报告。

冯亦菲姐姐给我们讲了一些tensorflwo的新的API的变动,最重要的是提出了一些使用tensorflow的建议。

总结出来有六个方面,分别是:
-
用Eager模式搭建原型
-
用Datasets处理数据
-
用Feature Columns提取特征
-
用Keras搭建模型
-
借用Canned Estimators
-
用SavedModel打包模型
下面我们依次来了解下这六个方面。
用Eager模式搭建原型
作为计算机界的一份子,我们知道静态图的效率自然是快快的,但是动态图的使用为我们的使用带来的很多方便。17年的时候,各大框架动态图大行其道,于是Google提出了tf.contrib.eager应对挑战。
使用Eager有什么好处呢?回想之前我们在调试tensorflow的程序时,不得不使用sess.run(),麻烦的要死,而使用Eager就可以直接的将变量打印出来,大大方便了我们的调试;好处不止这么多,在进行模型搭建的时候,以前我们需要仔细考虑下Tensor的shape,一旦出错要定位也很不容易。而使用Eager可以一边搭建网络结构,一边将shape打印出来确认下是否正确。这就使我们在搭建网络时更加方面快捷了;此外,使用Eager后,自定义Operation和Gradient也会方便很多。
下面举个简单的小例子。首先使用pip install tf-nightly(或GPU版本pip install tf-nightly-gpu)来安装Eager。
import tensorflow as tfimport tensorflow.contrib.eager as tfetfe.enable_eager_execution() #开启Eager模式a = tf.constant([5], dtype=tf.int32)for i in range(a): print (i)
使用Eager后我们可以很顺利的执行上述代码。但是如果没有Eager,就会报Tensor对象不能解释为integer的错误。从缺点上来讲,Eager的引入也势必造成额外的成本。
用Datasets处理数据
tensorflow的数据读入有三种方式:通过feeding的方式;通过管道(pipeline)的方式;直接读取变量或常量中保存的数据。Datasets属于上面提出的第二种方式,可以简化数据输入过程,而且能够提高数据的读入效率。
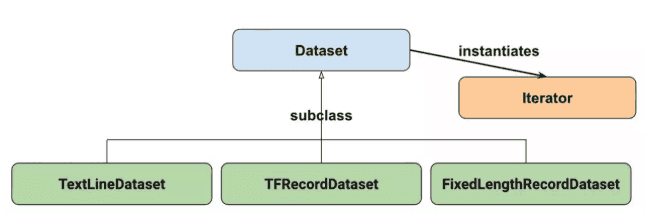
Datasets的组成如上如所示。其中:
-
Dataset:创建和转换数据集的基本;
-
TextLineDataset:从文本文件中读取行;
-
TFRecordDataset:读取TFRecord文件;
-
FixedLengthRecordDataset:从二进制文件读取固定大小的记录;
-
Iterator:提供一种一次访问一个数据集元素的方法。
对于Datasets的使用,我们可以使用Dataset的子类提供的方法,也可以直接使用基类的方法:tf.data.Dataset.from_tensors()或者tf.data.Dataset.from_tensor_slices()。
用Feature Columns提取特征
Feature Columns实际上是一个数据结构,一个用于描述特征的数据结构。利用Feature Columns可以很方便的对输入训练模型前的特征进行处理。比如鸢尾花的识别,对于输入数据,每列表示不同的特征,如花瓣的长度,花萼的长度等等,我们想要对不同的列分别进行处理(或者对所有的列进行处理),使用Feature Columns就可以轻松的实现。
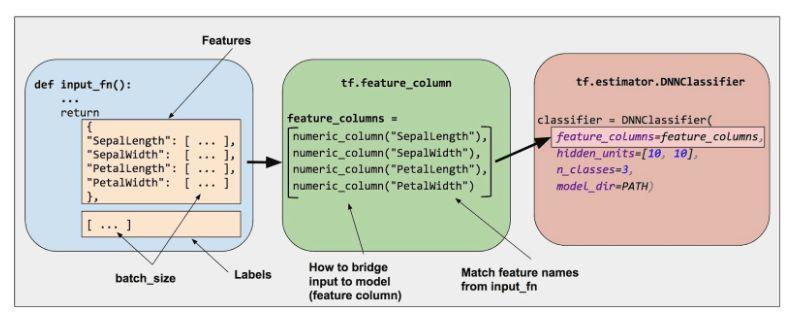
如上图所示,Feature Columns形成了对输入数据集的结构性描述。可以方便我们对每列数据进行处理,而且使得代码的可读性更强。
用Keras搭建模型
想必大家对Keras已经比较了解了,使用Keras来构建一个神经网络,简直是飞一般地速度,而且完美的兼容tensorflow。
simple_model=Sequential()simple_model.add(Dense(3,input_shape=(x.shape[1],),activation='relu',name='layer1'))simple_model.add(Dense(5,activation='relu',name='layer2'))simple_model.add(Dense(1,activation='sigmoid',name='layer3'))
构建一个模型就是如上面这么简单,而且调用API中定义好的模型更是只需要一句话,极其的方便。
借用Canned Estimators
Estimators API提供了模型选择、评估、训练等一些列功能。在1.3版本后,Google又增加了一层,称之为Canned Estimators。只需要一行代码就能够创建深度模型。Estimators可以结合上面提到的Feature Columns一起使用。
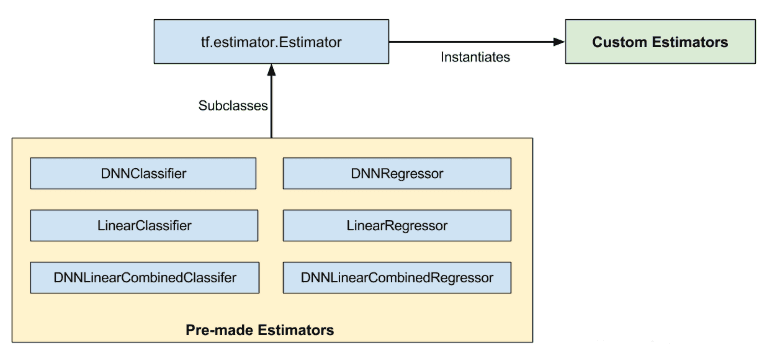
tf.estimator.Estimator是基类;Pre-made Estimators是基类的子类,是已经定义好的模型,我们可以直接拿来使用;Custom Estimators是基类的实列,并不是定义好的,需要我们自己实现模型的定义。
对于这里的模型,由三部分组成:
-
Input function:输入函数,即我们前面所说的Datasets,对于数据进行表示;
-
Model function: 实验模型的训练、验证、测试以及监控模型的参数;
-
Estimators: 控制数据流以及模型的各种运算。
用SavedModel打包模型
相比于tensorflow原版的tf.train.Saver保存模型的方式,SavedModel提供了更好的将模型部署到生成环境的手段,更适用于商业目的。
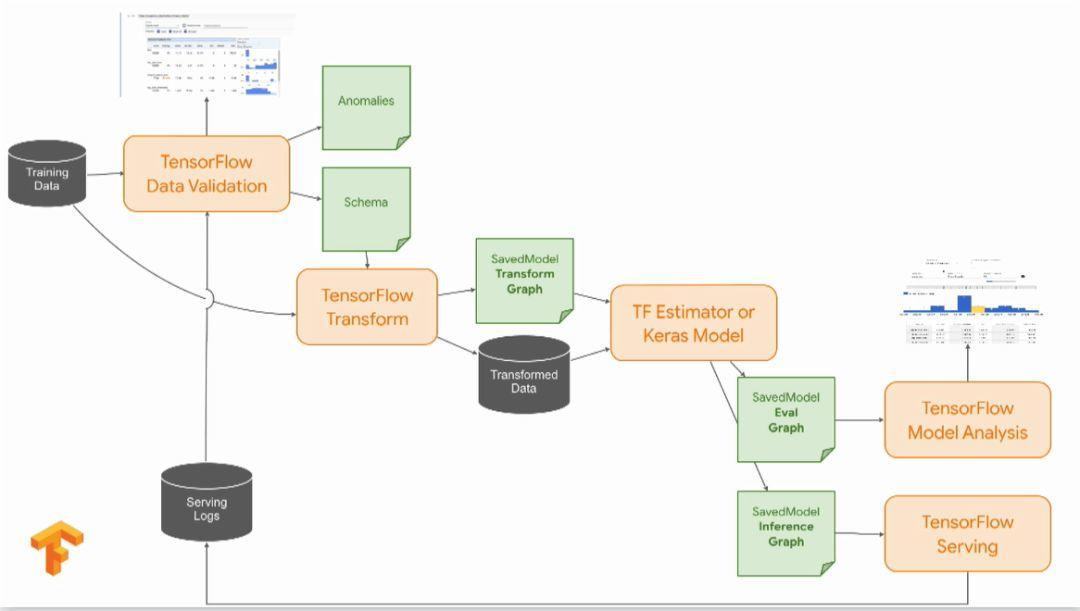
如上图右下方部分,在使用SavedModel打包模型时,可以产生两种模型:
对应于第一种模型,Tensorflow Model Analysis可以方便我们对模型进行分析,是不是存在参数的问题,抑或是模型哪里设计的不合适等等;通过分析后,感觉模型不错,我们就可以通过Tensorflow Serving进行部署。
此外,相比于Saver的方式,我们在inference时不需要再重新定义Graph(模型),如果使用Saver的话,在使用该模型时就需要再定义该模型,如果是一个程序猿设计并使用的还好,如果换成另一个猿去用这个模型,他又不知道模型的tensor的情况,那就尴尬了。所以使用SavedModel可以让我们更轻松地去使用模型。
总结
Google Developer Days给我们提供了一场盛宴,希望和大家一起学习其中的知识。如果可以,请为这篇文章点个赞吧。据说点赞的都能进Google。
