

本文主要总结和翻译自Learning a Personalized Homepage。但这并不是完全和完整的翻译稿。
正如我们在之前的博客文章中所描述的那样,在Netflix,我们广泛使用个性化,并努力抓住向超过5700万用户中的每一个呈现正确内容的机会。 用户与我们的推荐互动的主要方式是通过主页,当他们在任何支持的设备上登录Netflix时,他们会看到主页。 主页的主要功能是帮助每个成员轻松找到他们喜欢的东西。 我们面临的一个问题是,我们的目录包含的视频数量超过了单个页面上显示的数量,每个成员都有自己独特的兴趣。 因此,一个算法挑战是如何最好地定制每个成员的主页以使其涵盖他们的兴趣和观看意图,并且仍然允许他们探索其它内容。
这类问题并非Netflix所独有,而是其它新闻网站,搜索引擎和在线商店等共有的。 任何需要从大量可用可能性中选择项目然后以连贯且易于导航的方式呈现项目的站点将面临同样的一般挑战。 当然,优化Netflix主页的问题有其独特的方面,比如界面限制,以及与其他媒体相比如何消费电影和电视的差异。
Why Rows Anyway?
我们将主页组织成一系列行,以便用户轻松浏览我们目录的大部分内容。 通过连续呈现连贯的视频组,为每行提供有意义的名称,并以有用的顺序呈现行,用户可以快速决定连续的整组视频是否可能包含他们有兴趣观看的内容。 这允许用户更深入地潜水并在主题中查找更多视频或跳过它们并查看另一行。
将视频分组的一种自然方式是按genre或subgenre(这个概念在之前的文章中提到过)或其他视频元数据维度(如发布日期)。 当然,连续视频之间的关系不一定是元数据,也可以是行为信息(例如协同过滤算法),我们认为用户可能观看的视频,甚至是一段朋友观看的视频 因此,每行可以为用户提供唯一且个性化的目录片段以供导航。 创建个性化主页的挑战和乐趣的一部分是找出创建有用的视频分组的新方法,我们一直在尝试这些方法。
一旦我们为页面考虑了一组可能的视频组,我们就可以开始从它们组装主页了。为此,我们首先根据我们了解的用户查找可能与用户相关的候选分组。这还涉及提供证据(或解释)以支持一行的呈现,例如该成员先前在一种类型中观看的电影。接下来,我们会过滤每个群组以处理成熟度等级的问题,或者删除之前观看过的视频。在过滤之后,我们根据适合行的排名算法对每个组中的视频进行排名,该排序算法产生视频的排序,使得组中成员的最相关视频位于行的前面。从这组行候选中,我们可以应用行选择算法来组装整页。在页面组装完成后,我们会执行额外的过滤,例如重复数据删除,以删除重复视频并将行格式化为适合设备的大小。
Page-level algorithmic challenge
我们的个性化和推荐方法主要目的是帮助我们的user找到新的东西,我们称之为discovery。但是,我们还希望让user能够轻松观看节目的下一集或重新观看他们过去观看的内容,这些内容通常不属于推荐范围。我们希望我们的建议准确,但它们也需要多样化。我们希望能够突出我们目标中的深度,以及我们在其他领域的广度,以帮助我们的成员探索甚至找到新的兴趣。我们希望我们的建议是新鲜的,并对user action例如观看节目,添加到列表或评级做出响应;但我们也想要一些稳定性,以便人们熟悉他们的主页,并且可以轻松找到他们最近推荐过的视频。最后,我们需要放置面向任务的行,例如“我的列表”。
每个设备都有不同的硬件功能,可以限制任何时候显示的视频或行数以及整个页面的大小。 因此,在生成页面时必须知道它正在为其创建页面的设备的约束,包括行数,行的最小和最大长度,页面的可见部分的大小,以及某些行是否不适用于某个设备。
Building a page algorithmically
我们可以通过几种方法在算法上构建我们的主页。 最基本的是基于规则的方法,我们使用了很长时间。 这里有一组规则定义了一个模板,该模板指示所有成员在页面上的某些位置可以进入哪些行类型。 例如,规则可以指定第一行是“keep watching”(如果有的话),然后是Top Picks(如果有的话),然后是Netflix上的Popular,然后是5个个性化的genre行,依此类推。 这种方法中唯一的personalization是以个性化的方式选择候选行,例如包括“Because you watched <video>”行。 要选择每种类型中的特定行,我们使用简单的启发式和抽样算法。 我们使用A / B测试来演化此模板,以了解为所有user放置行的合适位置。
这种方法对我们很有帮助,但它忽略了我们认为对页面质量很重要的许多方面.模板的规则随着时间的推移而增长,变得过于复杂,无法处理各种行以及它们应如何放置。
为了解决这些问题,我们可以考虑在主页上个性化行的排序。 这样做的最简单方法是将行视为排名问题中的项目,我们将其称为行排名方法。 对于这种方法,我们可以为行开发评分函数,将应用于所有候选行,按该函数排序,然后选择最优先的一些行来填充页面,从而利用大量现有的推荐方法。 然而,这样做会导致缺乏多样性,有人会得到一个微小变化的页面,例如页面上的每一行看起来主题不同,但其实都充满了不同变体的喜剧:late-night, family, romantic, action等。
添加多样性的一种简单方法是使用评分函数从行排名方法切换到逐级方法,该评分函数既考虑行又考虑其与先前行和先前已为页面选择的视频的关系。 在这种情况下,可以采用简单的贪心方法,选择最大化此函数的行作为要使用的下一行,然后将下一个位置的所有行重新评分。 这种贪心的选择可能无法产生最佳页面。 使用具有k行前瞻的分阶段方法可以产生比贪心选择更优化的页面,但是它带来了增加的计算成本。
然而,即使是阶段式算法也不能保证产生最佳页面,因为固定的时间范围可能会限制在页面下方填充更好的行的能力。 如果我们可以定义整页评分函数,我们可以尝试通过适当选择行和视频来填充页面来优化它。 当然,页面组合的搜索空间很大,因此直接优化定义整个页面质量的函数在算力上是很难实现的。
使用任何这些方法解决页面优化问题时,还需要考虑之前提到的各种约束,例如重复数据删除,过滤和特定于设备的约束。 这些约束中的每一个都增加了优化问题的复杂性。
在形成主页时,考虑成员如何浏览页面也是重要的,即,考虑他们可能在会话中注意页面上的哪些位置。 将最相关的视频放置在最有可能被看到的位置(通常是左上角),可以减少成员查找与观看相关的内容的时间。 然而,在二维页面上建模导航是困难的,特别是考虑到不同的人可能导航模式不同,人们的导航模式可能随时间而变化,基于交互设计在不同设备类型之间存在导航差异,并且导航 显然取决于所显示内容的相关性。 通过精确的导航模型,我们可以更好地了解视频和行的位置以及页面上的重点。
Machine Learning for page generation
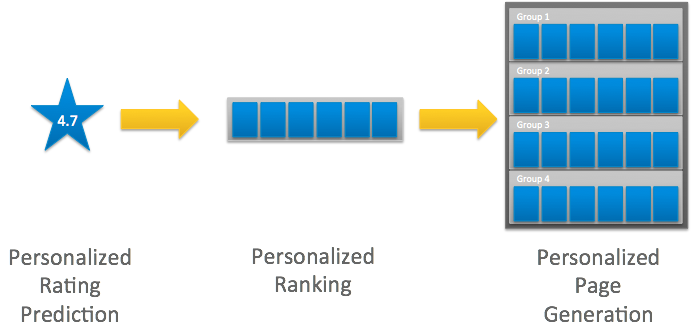
构建个性化页面的核心是评分功能,可以评估行或页面的质量。 虽然我们可以使用启发式或直觉来构建这样的评分函数并使用A / B测试进行调整,但我们更愿意从数据中学习一个好的函数,以便我们可以轻松地合并新的数据源并平衡主页的各个不同方面。 为此,我们可以使用我们为user创建不同的主页,他们实际看到的内容,他们的interactions以及他们的playback进行训练,从而用机器学习算法创建评分功能。
我们可以使用大量features来represent rows。由于行包含一组视频,因此我们可以在行表示中聚合使用这些视频的features。这些feature可以是简单的元数据或更有用的基于model的features,它们表示给用户推荐特定视频的理想程度。当然,我们有许多不同的推荐方法,可以使用ensemble方法把它们聚合起来。我们还可以查看与行相关的一些feature,例如对于对特定genre感兴趣的user有多少,以及当前user过去是否已消耗该行或类似行。我们还可以添加简单的描述性feature,例如这一行连续多少个视频,该行放置在页面上的位置,以及我们在过去显示该行的频率。我们还可以通过查看行与其余行的相似程度或行中的视频与其余部分的视频相似程度,将多样性纳入评分。
用于行评分的机器学习模型存在若干挑战。一个挑战是处理presentation bias,由于用户只能在我们显示的主页上选择视频播放,没被显示的训练数据就可能产生偏差。更复杂的是,页面上某行的位置会极大地影响user是否能实际看到该并选择从中进行播放。为了处理这些presentation和position bias,我们需要非常小心地选择训练数据。关于如何在模型中选择视频归属的行也存在挑战;视频可能在过去的某一行中播放过,但这是否意味着如果该视频被放置在不同的行的第一个位置,该user会选择相同的视频?多样性的引入也具有挑战性,因为页面上不同位置的潜在行的特征空间已经很大,但当页面的其余部分考虑到多样性时,可能的特征空间变得更大也更难以搜索。
Page-level metrics
与任何算法方法一样,要应对这些挑战,选择一个好的指标非常重要。 在页面生成中最重要的是如何评估在离线实验期间由特定算法产生的页面的质量。 虽然我们最终将在A / B测试中在线测试任何潜在的算法改进,但我们希望能够将我们宝贵的A / B测试资源集中在我们有证据可能提高页面质量的算法上。 我们还需要能够在A / B测试之前调整这些算法的参数。

当然,Recall是一个基本指标,需要选择m和n的值,但我们同样可以扩展指标如NDCG或MRR到二维情况。 我们还可以调整导航模型例如Expected Reciprocal Rank,以在页面中包含二维导航。 通过定义这样的page-level metrics,我们可以使用它们来评估用于生成页面的任何算法方法的变化,不仅仅是algorithms for ordering the rows,还有selection, filtering, 和ranking algorithms。
Other Challenges
在设计主页时,不乏挑战性的问题。 例如:何时考虑其他上下文变量(例如一天中的时间或设备),以及我们如何填充主页? 我们如何在找到最佳页面和计算成本之间找到适当的权衡? 我们如何在user关键的前几个会话期间形成主页,而这恰恰是在我们获得最少信息的时候? 我们需要考虑并权衡每个问题的重要性,以便不断改进Netflix主页。
Conclusion
个性化页面生成是一个具有挑战性的问题,涉及平衡多种因素,我们认为这只是一个开始。
