

总的来说,Caffe 是一个比较难上手的框架。这次尝试训练 Caffe 框架下 SSD 模型的训练是我第一次使用 Caffe 框架。下面就说一说我踩过的几个坑,希望能够帮助到大家。
1 编译 Caffe 框架
这一步是我认为使用 Caffe 框架的最大障碍,编译不停出错。最后我不得不放弃转而使用 Docker 解决 Caffe 的编译安装问题。下面写出 Docker 的安装以及拉取所需镜像的方法。
Docker 安装
安装过程我是参照的 Docker 官方的安装指引,传送门在这里。
我使用的安装命令为(Ubuntu 16.04 LTS):
# If you have installed older version of docker, removing it by using command as follows
sudo apt-get remove docker docker-engine docker.io
# Docker installation
# 1. Update the apt package index
sudo apt-get update
# 2. Install packages to allow apt to use a repository over HTTPS
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common
# 3. Add Docker’s official GPG key
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 4. Add apt repository
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
# 5. INSTALL DOCKER CE
sudo apt-get update
sudo apt-get install docker-ce
# 6. Verify that Docker CE is installed correctly by running the hello-world image
sudo docker run hello-world
以上就是 Docker 的安装过程,安装完成 Docker 后,下一步就是寻找合适的镜像并拉取。如果你对 Docker 的使用并不熟悉,推荐你阅读《第一本Docker书》的前4章,阅读时间大约在2个小时,下载在这里。
寻找并拉取合适的镜像
我是在 Docker Hub 直接搜索我需要的镜像的,我的需求是 python2, gpu 版本的 Caffe 并且是 SSD 分支。 在 Bing.com 搜索「docker hub」,打开之后搜索关键词 「caffe ssd」。
# If you have nvidia-docker 1.0 installed: we need to remove it and all existing GPU containers
docker volume ls -q -f driver=nvidia-docker | xargs -r -I{} -n1 docker ps -q -a -f volume={} | xargs -r docker rm -f
sudo apt-get purge -y nvidia-docker
# Add the package repositories
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | \
sudo apt-key add -
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | \
sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
# Install nvidia-docker2 and reload the Docker daemon configuration
sudo apt-get install -y nvidia-docker2
sudo pkill -SIGHUP dockerd
# Test nvidia-smi with the latest official CUDA image
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
按照顺序依次执行就可以了,如果你遇到问题,请参照 nvidia-docker 安装官方指引。
拉取镜像:
sudo nvidia-docker run -it --name xxx -v /your/path/to/swap place(host):/your/path/to/swap place narumi/caffe-ssd-gpu /bin/bash
# -it 指定这个 Docker 容器是可交互的,不可少
# --name 指定 Docker 容器的名称,方便以后使用 。将 xxx 替换为你想要的名称,例如我指定的名称为 caffe_ssd_gpu_py2。
# -v 指定挂载目录到容器中,这样方便容器与宿主机进行文件交换。 「:」前为宿主机目录,后为容器内目录
# narumi/caffe-ssd-gpu 指定我拉取的镜像名
# /bin/bash 命令使得容器开启后自动为我打开终端
# 我自己使用的命令如下,供大家参考
sudo nvidia-docker run -it --name caffe_ssd_gpu_py2 -v /home/ubuntu/work/docker_swap:/home/swap narumi/caffe_ssd_gpu /bin/bash
# 这样,我在容器中访问 /home/swap 时就能看到我主机 /home/ubuntu/work/docker_swap 下存放的文件了
2 制作自己的数据集
这一步才是重点,下面我们将处理自己的使用的数据集。
标注数据集
因为我们将要把数据集制作为 pascal voc 格式的数据集,因此我们需要将标注信息存放在 xml 文件中。推荐使用 LabelImg 这个开源软件标注。其优点是图形化界面,并且自动生成 xml 文件,省去了很多转化的步骤,传送门在这里。 怎样使用其实非常简单,在这里略过不讲。如果你不会使用,请善用搜索。无法解决的话可以留言询问。
制作 Pascal Voc 格式数据集
在主机的交换目录下创建名为 VOCdevkit 的文件夹用于存放图片等内容。
交换目录就是刚刚创建容器时候指定的主机目录,例如我的交换目录为 /home/ubuntu/work/docker_swap
具体命令如下:
cd /home/ubuntu/work/docker_swap
mkdir VOCdevkit
cd VOCdevkit
mkdir VOC2007
cd VOC2007
mkdir Annotations # 存放 xml 文件
mkdir JPEGImages # 存放 jpg 文件
mkdir ImageSets
cd ImageSets
mkdir Main
创建完成后将 jpg 和 xml 文件放入对应目录下。然后使用 python 脚本划分一下训练集和测试集。我把我使用的脚本贴在这里:
import os
import random
# 下面两个目录改成自己的目录
xmlfilepath=r'/your/path/to/xmls'
saveBasePath=r"your/path/to/save/VOCdevkit"
trainval_percent=0.9 # 划分训练集和验证集的比例
train_percent=0.9 # trainval 中 训练集所占比例
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
print("train and val size",tv)
print("traub suze",tr)
ftrainval = open(os.path.join(saveBasePath,'VOC2007/ImageSets/Main/trainval.txt'), 'w')
ftest = open(os.path.join(saveBasePath,'VOC2007/ImageSets/Main/test.txt'), 'w')
ftrain = open(os.path.join(saveBasePath,'VOC2007/ImageSets/Main/train.txt'), 'w')
fval = open(os.path.join(saveBasePath,'VOC2007/ImageSets/Main/val.txt'), 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()
运行完毕后 VOCdevkit/VOC2007/ImageSets 下应该有4个 txt 文本。
修改 create_list.sh 与 create_data.sh 并生成 LMDB files
首先在 Caffe 根目录下的 data 目录内创建一个名为 VOC2007 的目录,然后执行下列命令:
cd /opt/caffe/data
mkdir VOC2007
cp VOC0712/create_* VOC2007/
cp VOC0712/labelmap_voc.prototxt VOC2007/
cd VOC2007
# 修改 label map
vim labelmap_voc.prototxt
# 如果提示没有vim,使用 sudo apt-get install vim 安装一下
# labelmap_voc.prototxt 中内容修改为自己需要的内容
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "label1" # label 为你自己数据集里label的名称,替换即可
label: 1
display_name: "label1"
}
item {
name: "label2"
label: 2
display_name: "label2"
}
item {
name: "label3"
label: 3
display_name: "label3"
}
item {
name: "label4"
label: 4
display_name: "label4"
}
...
# 修改好后 :wq 保存
# 修改 create_list.sh
vim create_list.sh
#!/bin/bash
# 如果你目录严格按照我上面提供的命令创建的话,那么下面 root_dir 等不用修改,直接用我的就行
# 如果你自定义了目录名,需要根据自己的定义修改
root_dir=/opt/caffe/data/VOCdevkit
sub_dir=ImageSets/Main
bash_dir="$(cd "$(dirname "${BASH_SOURCE[0]}")" && pwd)"
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in VOC2007
do
# 注意下面这一段需要注释掉
# if [[ $dataset == "test" && $name == "VOC2007" ]]
# then
# continue
# fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir/$name/$sub_dir/$dataset.txt
img_file=$bash_dir/$dataset"_img.txt"
cp $dataset_file $img_file
sed -i "s/^/$name\/JPEGImages\//g" $img_file
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
paste -d' ' $img_file $label_file >> $dst_file
rm -f $label_file
rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
$bash_dir/../../build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt"
fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle(<STDIN>);' > $rand_file
mv $rand_file $dst_file
fi
done
# 修改好 :wq 保存退出
# 修改 create_data.sh
vim create_data.sh
# 同样,如果你严格按照我的命令定义了目录名,就不需要修改
# 如果你修改了我上述命令中的目录名,需要你改的地方有 root_dir, data_root_dir, dataset_name, mapfile
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
root_dir="/opt/caffe"
cd $root_dir
redo=1
data_root_dir="/opt/caffe/data/VOCdevkit"
dataset_name="VOC2007"
mapfile="/opt/caffe/data/$dataset_name/labelmap_voc.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python $root_dir/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir $root_dir/data/$dataset_name/$subset.txt $data_root_dir/$dataset_name/$db/$dataset_name"_"$subset"_"$db examples/$dataset_name
done
# 修改好后 :wq 保存退出
都修改好后执行脚本生成 LMDB
# 进入 Caffe 根目录
cd /opt/caffe
./data/VOC2007/create_list.sh
./data/VOC2007/create_data.sh
3 修改 ssd_pascal.py 并开始训练
终于进行到最后一步了,这一步相对来说很简单。
# Caffe root dir
cd /opt/caffe
vim example/ssd/ssd_pascal.py
# 82 行修改 LMDB 文件位置信息
# 上一步执行 *.sh 文件时候输出了 LMDB file 的存放位置
# The database file for training data. Created by data/VOC0712/create_data.sh
train_data = "/opt/caffe/data/VOCdevkit/VOC2007/lmdb/VOC2007_trainval_lmdb"
# The database file for testing data. Created by data/VOC0712/create_data.sh
test_data = "/opt/caffe/data/VOCdevkit/VOC2007/lmdb/VOC2007_test_lmdb"
# 258 行修改必要信息
# Stores the test image names and sizes. Created by data/VOC0712/create_list.sh
name_size_file = "data/VOC2007/test_name_size.txt"
# The pretrained model. We use the Fully convolutional reduced (atrous) VGGNet.
pretrain_model = "models/VGGNet/VGG_ILSVRC_16_layers_fc_reduced.caffemodel"
# Stores LabelMapItem.
label_map_file = "data/VOC2007/labelmap_voc.prototxt"
# MultiBoxLoss parameters.
num_classes = 5 # 修改为你要的分类数+1。例如我是4分类,我写了 4+1=5
# 332 行修改 GPU 信息
gpus = "0,1" # 你要开启几个 GPU 加速就写几个,编号从0开始。我用两张 1080TI 就写了 0,1
# 337 修改 batch size 大小
batch_size = 32 # 这个数字大小看你显存大小填写, 允许范围内越大越好
# 359 行修改测试集图片数
num_test_image = 1000 # 根据你测试集图片数实际填写
# 图片数为 $caffe_root/data/VOCdevkit/VOC2007/ImageSets/Main/test.txt 的行数
# 修改好后 :wq 保存退出
下一步就是训练,但是开始之前,先下载预训练的 base model 放入对应位置,减少训练时间并提高效率 为了方便大家下载,我上传到百度网盘了,密码: ip6v。如果你想自己下载,去 github 下载,链接。
# 下载好的 caffe model 放在一开始指定的交换区
cd /opt/caffe/model
mkdir VGGNet
cp /home/swap/VGG_ILSVRC_16_layers_fc_reduced.caffemodel /ope/caffe/model/
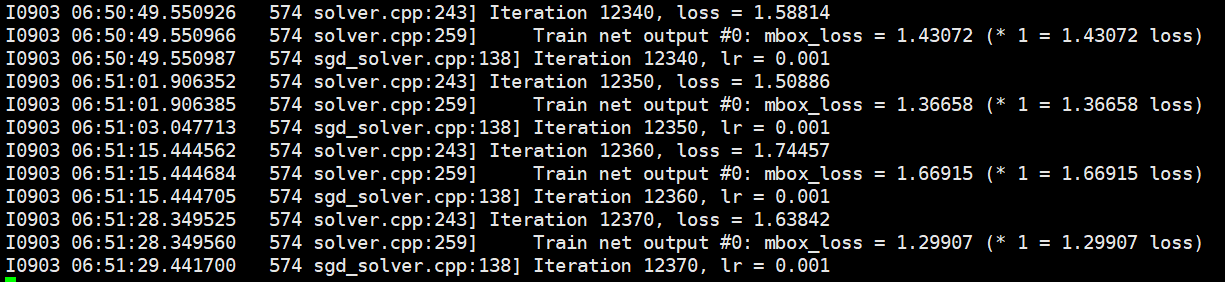
开始训练
cd /opt/caffe
python example/ssd/ssd_pascal.py
结语
至此,恭喜你可以使用 Caffe 框架训练属于自己的 SSD 模型了, SSD 的官方实现的 github 地址为 链接。如果你有任何问题,可以求助于 github 讨论区或者留言问询。
另外,欢迎关注我。最近会写很多关于目标检测方面的文章,包括一些论文翻译以及论文解读。还可能写一点算法实现的内容。
谢谢阅读。
