


简介
引自维基百科计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是指用摄影机和计算机代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图像处理,用计算机处理成为更适合人眼观察或传送给仪器检测的图像。
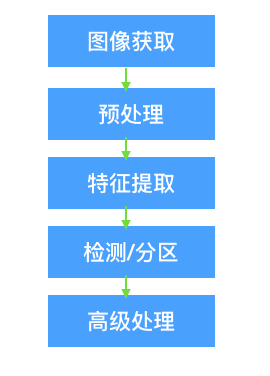
计算机视觉系统的结构形式很大程度上依赖于其具体应用方向。计算机视觉系统的具体实现方法同时也由其功能决定——是预先固定的抑或是在运行过程中自动学习调整。尽管如此,计算机视觉的都需要具备以下处理步骤:
引自维基百科人脸识别,特指利用分析比较人脸视觉特征信息进行身份鉴别的计算机技术。 广义的人脸识别实际包括构建人脸识别系统的一系列相关技术,包括人脸图像采集、人脸定位、人脸识别预处理、身份确认以及身份查找等;而狭义的人脸识别特指通过人脸进行身份确认或者身份查找的技术或系统。
人脸识别是计算机视觉的一种应用,iOS中常用的有四种实现方式:CoreImage、Vision、OpenCV、AVFoundation,下面一一介绍几种方式的实现步骤。
CoreImage
自从 iOS 5(大概在2011年左右)之后,iOS 开始支持人脸识别,只是用的人不多。人脸识别 API 让开发者不仅可以进行人脸检测,还能识别微笑、眨眼等表情。
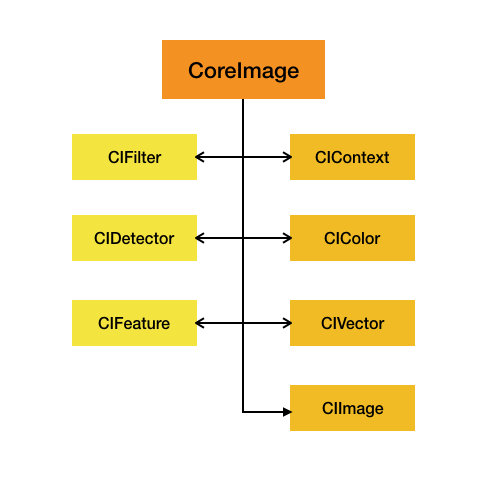
操作部分:
- 滤镜(CIFliter):CIFilter 产生一个CIImage。典型的,接受一到多的图片作为输入,经过一些过滤操作,产生指定输出的图片。
- 检测(CIDetector):CIDetector 检测处理图片的特性,如使用来检测图片中人脸的眼睛、嘴巴、等等。
- 特征(CIFeature):CIFeature 代表由 detector处理后产生的特征。
图像部分:
- 画布(CIContext):画布类可被用与处理Quartz 2D 或者 OpenGL。可以用它来关联CoreImage类。如滤镜、颜色等渲染处理。
- 颜色(CIColor): 图片的关联与画布、图片像素颜色的处理。
- 向量(CIVector): 图片的坐标向量等几何方法处理。
- 图片(CIImage): 代表一个图像,可代表关联后输出的图像。
实现代码如下:
guard let personciImage = CIImage(image: personPic.image!) else { return }
let accuracy = [CIDetectorAccuracy: CIDetectorAccuracyHigh]
let faceDetector = CIDetector(ofType: CIDetectorTypeFace, context: nil, options: accuracy)
let faces = faceDetector?.features(in: personciImage)
// 转换坐标系
let ciImageSize = personciImage.extent.size
var transform = CGAffineTransform(scaleX: 1, y: -1)
transform = transform.translatedBy(x: 0, y: -ciImageSize.height)
for face in faces as! [CIFaceFeature] {
print("Found bounds are \(face.bounds)")
// 应用变换转换坐标
var faceViewBounds = face.bounds.applying(transform)
// 在图像视图中计算矩形的实际位置和大小
let viewSize = personPic.bounds.size
let scale = min(viewSize.width / ciImageSize.width, viewSize.height / ciImageSize.height)
let offsetX = (viewSize.width - ciImageSize.width * scale) / 2
let offsetY = (viewSize.height - ciImageSize.height * scale) / 2
faceViewBounds = faceViewBounds.applying(CGAffineTransform(scaleX: scale, y: scale))
faceViewBounds.origin.x += offsetX
faceViewBounds.origin.y += offsetY
let faceBox = UIView(frame: faceViewBounds)
faceBox.layer.borderWidth = 3
faceBox.layer.borderColor = UIColor.red.cgColor
faceBox.backgroundColor = UIColor.clear
personPic.addSubview(faceBox)
if face.hasLeftEyePosition {
print("Left eye bounds are \(face.leftEyePosition)")
}
if face.hasRightEyePosition {
print("Right eye bounds are \(face.rightEyePosition)")
}
}
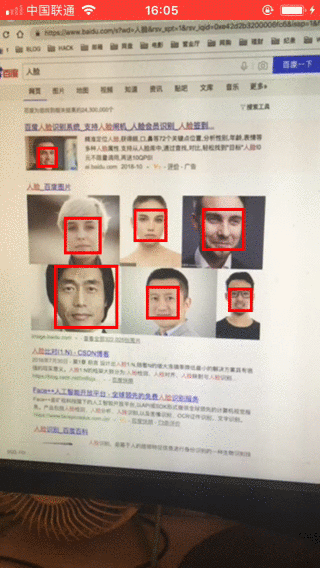
运行APP,效果如下:

Vision
Vision 是 Apple 在 WWDC 2017 推出的图像识别框架,它基于 Core ML,所以可以理解成 Apple 的工程师设计了一种算法模型,然后利用 Core ML 训练,最后整合成一个新的框架,相比开源模型然后让开发者自己整合起来,这种方式更安全也更方便我们使用。
Vision 支持多种图片类型,如:
- CIImage
- NSURL
- NSData
- CGImageRef
- CVPixelBufferRef
Vision使用中的角色有: Request,RequestHandler,results和results中的Observation数组。
Request类型: 有很多种,比如图中列出的 人脸识别、特征识别、文本识别、二维码识别等。

使用概述:
我们在使用过程中是给各种功能的 Request 提供给一个 RequestHandler,Handler 持有需要识别的图片信息,并将处理结果分发给每个 Request 的 completion Block 中。可以从 results 属性中得到 Observation 数组。
observations数组中的内容根据不同的request请求返回了不同的observation,如:VNFaceObservation、VNTextObservation、VNBarcodeObservation、VNHorizonObservation,不同的Observation都继承于VNDetectedObjectObservation,而VNDetectedObjectObservation则是继承于VNObservation。每种Observation有boundingBox,landmarks等属性,存储的是识别后物体的坐标,点位等,我们拿到坐标后,就可以进行一些UI绘制。
代码实现如下:
@IBOutlet weak var imageView: UIImageView!
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
let handler = VNImageRequestHandler.init(cgImage: (imageView.image?.cgImage!)!, orientation: CGImagePropertyOrientation.up)
let request = reqReq()
DispatchQueue.global(qos: .userInteractive).async {
do {
try handler.perform([request])
}
catch {
print("e")
}
}
}
func reqReq() -> VNDetectFaceRectanglesRequest {
let request = VNDetectFaceRectanglesRequest(completionHandler: { (request, error) in
DispatchQueue.main.async {
if let result = request.results {
let transform = CGAffineTransform(scaleX: 1, y: -1).translatedBy(x: 0, y: -self.imageView!.frame.size.height)
let translate = CGAffineTransform.identity.scaledBy(x: self.imageView!.frame.size.width, y: self.imageView!.frame.size.height)
//遍历所有识别结果
for item in result {
//标注框
let faceRect = UIView(frame: CGRect.zero)
faceRect.layer.borderWidth = 3
faceRect.layer.borderColor = UIColor.red.cgColor
faceRect.backgroundColor = UIColor.clear
self.imageView!.addSubview(faceRect)
if let faceObservation = item as? VNFaceObservation {
let finalRect = faceObservation.boundingBox.applying(translate).applying(transform)
faceRect.frame = finalRect
}
}
}
}
})
return request
}
运行APP,效果如下:

OpenCV
OpenCV (Open Source Computer Vision Library)是一个在BSD许可下发布的开源库,因此它是免费提供给学术和商业用途。有C++、C、Python和Java接口,支持Windows、Linux、MacOS、iOS和Android等系统。OpenCV是为计算效率而设计的,而且密切关注实时应用程序的发展和支持。该库用优化的C/C++编写,可以应用于多核处理。在启用OpenCL的基础上,它可以利用底层的异构计算平台的硬件加速。
OpenCV 起始于 1999 年 Intel 的一个内部研究项目。从那时起,它的开发就一直很活跃。进化到现在,它已支持如 OpenCL 和 OpenGL 等现代技术,也支持如 iOS 和 Android 等平台。
下面是在官方文档中列出的最重要的模块:
- core:简洁的核心模块,定义了基本的数据结构,包括稠密多维数组
Mat和其他模块需要的基本函数。 - imgproc:图像处理模块,包括线性和非线性图像滤波、几何图像转换 (缩放、仿射与透视变换、一般性基于表的重映射)、颜色空间转换、直方图等等。
- video:视频分析模块,包括运动估计、背景消除、物体跟踪算法。
- calib3d:包括基本的多视角几何算法、单体和立体相机的标定、对象姿态估计、双目立体匹配算法和元素的三维重建。
- features2d:包含了显著特征检测算法、描述算子和算子匹配算法。
- objdetect:物体检测和一些预定义的物体的检测 (如人脸、眼睛、杯子、人、汽车等)。
- ml:多种机器学习算法,如 K 均值、支持向量机和神经网络。
- highgui:一个简单易用的接口,提供视频捕捉、图像和视频编码等功能,还有简单的 UI 接口 (iOS 上可用的仅是其一个子集)。
- gpu:OpenCV 中不同模块的 GPU 加速算法 (iOS 上不可用)。
- ocl:使用 OpenCL 实现的通用算法 (iOS 上不可用)。
- 一些其它辅助模块,如 Python 绑定和用户贡献的算法。
cv::Mat 是 OpenCV 的核心数据结构,用来表示任意 N 维矩阵。因为图像只是 2 维矩阵的一个特殊场景,所以也是使用 cv::Mat 来表示的。也就是说,cv::Mat 将是你在 OpenCV 中用到最多的类。
如前面所说,OpenCV 是一个 C++ 的 API,因此不能直接在 Swift 和 Objective-C 代码中使用,但能在 Objective-C++ 文件中使用。
Objective-C++ 是 Objective-C 和 C++ 的混合物,让你可以在 Objective-C 类中使用 C++ 对象。clang 编译器会把所有后缀名为 .mm 的文件都当做是 Objective-C++。一般来说,它会如你所期望的那样运行,但还是有一些使用 Objective-C++ 的注意事项。内存管理是你最应该格外注意的点,因为 ARC 只对 Objective-C 对象有效。当你使用一个 C++ 对象作为类属性的时候,其唯一有效的属性就是 assign。因此,你的 dealloc 函数应确保 C++ 对象被正确地释放了。
第二重要的点就是,如果你在 Objective-C++ 头文件中引入了 C++ 头文件,当你在工程中使用该 Objective-C++ 文件的时候就泄露了 C++ 的依赖。任何引入你的 Objective-C++ 类的 Objective-C 类也会引入该 C++ 类,因此该 Objective-C 文件也要被声明为 Objective-C++ 的文件。这会像森林大火一样在工程中迅速蔓延。所以,应该把你引入 C++ 文件的地方都用 #ifdef __cplusplus 包起来,并且只要可能,就尽量只在 .mm实现文件中引入 C++ 头文件。
要获得更多如何混用 C++ 和 Objective-C 的细节,请查看 Matt Galloway 写的这篇教程。
基于OpenCV,iOS应用程序可以实现很多有趣的功能,也可以把很多复杂的工作简单化。一般可用于:
- 对图片进行灰度处理
- 人脸识别,即特征跟踪
- 训练图片特征库(可用于模式识别)
- 提取特定图像内容(根据需求还原有用图像信息)
代码实现如下:
- (void)viewDidLoad {
[super viewDidLoad];
//预设置face探测的参数
[self preSetFace];
//image转mat
cv::Mat mat;
UIImageToMat(self.imageView.image, mat);
//执行face
[self processImage:mat];
}
- (void)preSetFace {
NSString *faceCascadePath = [[NSBundle mainBundle] pathForResource:@"haarcascade_frontalface_alt2"
ofType:@"xml"];
const CFIndex CASCADE_NAME_LEN = 2048;
char *CASCADE_NAME = (char *) malloc(CASCADE_NAME_LEN);
CFStringGetFileSystemRepresentation( (CFStringRef)faceCascadePath, CASCADE_NAME, CASCADE_NAME_LEN);
_faceDetector.load(CASCADE_NAME);
free(CASCADE_NAME);
}
- (void)processImage:(cv::Mat&)inputImage {
// Do some OpenCV stuff with the image
cv::Mat frame_gray;
//转换为灰度图像
cv::cvtColor(inputImage, frame_gray, CV_BGR2GRAY);
//图像均衡化
cv::equalizeHist(frame_gray, frame_gray);
//分类器识别
_faceDetector.detectMultiScale(frame_gray, _faceRects,1.1,2,0,cv::Size(30,30));
vector<cv::Rect> faces;
faces = _faceRects;
// 在每个人脸上画一个红色四方形
for(unsigned int i= 0;i < faces.size();i++)
{
const cv::Rect& face = faces[i];
cv::Point tl(face.x,face.y);
cv::Point br = tl + cv::Point(face.width,face.height);
// 四方形的画法
cv::Scalar magenta = cv::Scalar(255, 0, 0, 255);
cv::rectangle(inputImage, tl, br, magenta, 3, 8, 0);
}
UIImage *outputImage = MatToUIImage(inputImage);
self.imageView.image = outputImage;
}
运行APP,效果如下:

AVFoundation
AVFoundation照片和视频捕捉功能是从框架搭建之初就是它的强项。 从iOS 4.0 我们就可以直接访问iOS的摄像头和摄像头生成的数据(照片、视频)。目前捕捉功能仍然是苹果公司媒体工程师最关注的领域。
AVFoundation实现视频捕捉的步骤如下:
- 捕捉设备
AVCaptureDevice为摄像头、麦克风等物理设备提供接口。大部分我们使用的设备都是内置于MAC或者iPhone、iPad上的。当然也可能出现外部设备。但是AVCaptureDevice 针对物理设备提供了大量的控制方法。比如控制摄像头聚焦、曝光、白平衡、闪光灯等。
- 捕捉设备的输入
注意:为捕捉设备添加输入,不能添加到AVCaptureSession 中,必须通过将它封装到一个AVCaptureDeviceInputs实例中。这个对象在设备输出数据和捕捉会话间扮演接线板的作用。
- 捕捉设备的输出
AVCaptureOutput 是一个抽象类。用于为捕捉会话得到的数据寻找输出的目的地。框架定义了一些抽象类的高级扩展类。例如 AVCaptureStillImageOutput 和 AVCaptureMovieFileOutput类。使用它们来捕捉静态照片、视频。例如 AVCaptureAudioDataOutput 和 AVCaptureVideoDataOutput ,使用它们来直接访问硬件捕捉到的数字样本。
- 捕捉连接
AVCaptureConnection类.捕捉会话先确定由给定捕捉设备输入渲染的媒体类型,并自动建立其到能够接收该媒体类型的捕捉输出端的连接。
- 捕捉预览
如果不能在影像捕捉中看到正在捕捉的场景,那么应用程序用户体验就会很差。幸运的是框架定义了AVCaptureVideoPreviewLayer 类来满足该需求。这样就可以对捕捉的数据进行实时预览。
通过一个特定的AVCaptureOutput类型的AVCaptureMetadataOutput可以实现人脸检测功能.支持硬件加速以及同时对10个人脸进行实时检测.
当使用人脸检测时,会输出一个具体的子类类型AVMetadataFaceObject,该类型定义了多个用于描述被检测到的人脸的属性,包括人脸的边界(设备坐标系),以及斜倾角(roll angle,表示人头部向肩膀方向的侧倾角度)和偏转角(yaw angle,表示人脸绕Y轴旋转的角度).
实现代码如下:
- (void)viewDidLoad {
[super viewDidLoad];
_facesViewArr = [NSMutableArray arrayWithCapacity:0];
//1.获取输入设备(摄像头)
NSArray *devices = [AVCaptureDeviceDiscoverySession discoverySessionWithDeviceTypes:@[AVCaptureDeviceTypeBuiltInWideAngleCamera] mediaType:AVMediaTypeVideo position:AVCaptureDevicePositionBack].devices;
AVCaptureDevice *deviceF = devices[0];
// NSArray *devices = [AVCaptureDevice devicesWithMediaType:AVMediaTypeVideo];
// AVCaptureDevice *deviceF;
// for (AVCaptureDevice *device in devices )
// {
// if ( device.position == AVCaptureDevicePositionFront )
// {
// deviceF = device;
// break;
// }
// }
//2.根据输入设备创建输入对象
AVCaptureDeviceInput*input = [[AVCaptureDeviceInput alloc] initWithDevice:deviceF error:nil];
//3.创建原数据的输出对象
AVCaptureMetadataOutput *metaout = [[AVCaptureMetadataOutput alloc] init];
//4.设置代理监听输出对象输出的数据,在主线程中刷新
[metaout setMetadataObjectsDelegate:self queue:dispatch_get_main_queue()];
self.session = [[AVCaptureSession alloc] init];
//5.设置输出质量(高像素输出)
if ([self.session canSetSessionPreset:AVCaptureSessionPreset640x480]) {
[self.session setSessionPreset:AVCaptureSessionPreset640x480];
}
//6.添加输入和输出到会话
[self.session beginConfiguration];
if ([self.session canAddInput:input]) {
[self.session addInput:input];
}
if ([self.session canAddOutput:metaout]) {
[self.session addOutput:metaout];
}
[self.session commitConfiguration];
//7.告诉输出对象要输出什么样的数据,识别人脸, 最多可识别10张人脸
[metaout setMetadataObjectTypes:@[AVMetadataObjectTypeFace]];
AVCaptureSession *session = (AVCaptureSession *)self.session;
//8.创建预览图层
_previewLayer = [[AVCaptureVideoPreviewLayer alloc] initWithSession:session];
_previewLayer.videoGravity = AVLayerVideoGravityResizeAspectFill;
_previewLayer.frame = self.view.bounds;
[self.view.layer insertSublayer:_previewLayer atIndex:0];
//9.设置有效扫描区域(默认整个屏幕区域)(每个取值0~1, 以屏幕右上角为坐标原点)
metaout.rectOfInterest = self.view.bounds;
//前置摄像头一定要设置一下 要不然画面是镜像
for (AVCaptureVideoDataOutput* output in session.outputs) {
for (AVCaptureConnection * av in output.connections) {
//判断是否是前置摄像头状态
if (av.supportsVideoMirroring) {
//镜像设置
av.videoOrientation = AVCaptureVideoOrientationPortrait;
// av.videoMirrored = YES;
}
}
}
//10. 开始扫描
[self.session startRunning];
}
- (void)captureOutput:(AVCaptureOutput *)output didOutputMetadataObjects:(NSArray<__kindof AVMetadataObject *> *)metadataObjects fromConnection:(AVCaptureConnection *)connection
{
//当检测到了人脸会走这个回调
//干掉旧画框
for (UIView *faceView in self.facesViewArr) {
[faceView removeFromSuperview];
}
[self.facesViewArr removeAllObjects];
//转换
for (AVMetadataFaceObject *faceobject in metadataObjects) {
AVMetadataObject *face = [self.previewLayer transformedMetadataObjectForMetadataObject:faceobject];
CGRect r = face.bounds;
//画框
UIView *faceBox = [[UIView alloc] initWithFrame:r];
faceBox.layer.borderWidth = 3;
faceBox.layer.borderColor = [UIColor redColor].CGColor;
faceBox.backgroundColor = [UIColor clearColor];
[self.view addSubview:faceBox];
[self.facesViewArr addObject:faceBox];
}
}
运行APP,效果如下:
本文四种方式实现的代码已放到Github,有需要的可以下载查看。
关注我
欢迎关注公众号:jackyshan,技术干货首发微信,第一时间推送。

