

本篇文章将会介绍 Hadoop 重要的计算框架 MapReduce。
完整的 MapReduce 框架包含两部分:
- 算法逻辑层面,即
map、shuffle以及reduce三个重要算法组成部分,本篇文章将会介绍这个层面; - 实际运行层面,即算法逻辑作业在分布式主机中是以什么形式和什么流程运行的,因为自
MapReduce version2以后,作业都是提交给YARN进行管理,所以本文将不会介绍此部分。
系列其他文章有:
一、What is MapReduce?
MapReduce是一个基于 java 的并行分布式计算框架,使用它来编写的数据处理应用可以运行在大型的商用硬件集群上来处理大型数据集中的可并行化问题,数据处理可以发生在存储在文件系统(非结构化)或数据库(结构化)中的数据上。MapReduce 可以利用数据的位置,在存储的位置附近处理数据,以最大限度地减少通信开销。
MapReduce 框架通过编组分布式服务器,并行运行各种任务,管理系统各部分之间的所有通信和数据传输;其还能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,减少开发人员的负担。
MapReduce 还是一个并行程序设计模型与方法(Programming Model & Methodology)。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,将复杂的、运行于大规模集群上的并行计算过程高度地抽象到了两个函数:Map和Reduce,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
二、The Algorithm
MapReduce框架通常由三个操作(或步骤)组成:
Map:每个工作节点将map函数应用于本地数据,并将输出写入临时存储。主节点确保仅处理冗余输入数据的一个副本。Shuffle:工作节点根据输出键(由map函数生成)重新分配数据,对数据映射排序、分组、拷贝,目的是属于一个键的所有数据都位于同一个工作节点上。Reduce:工作节点现在并行处理每个键的每组输出数据。
MapReduce 流程图:
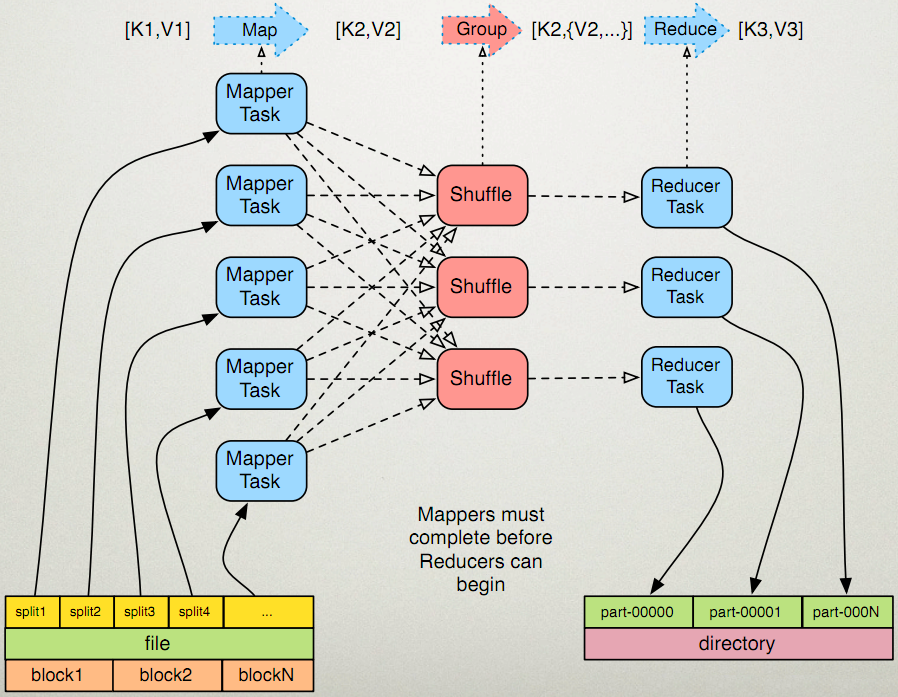
MapReduce 允许分布式运行 Map 操作,只要每个 Map 操作独立于其他 Map 操作就可以并行执行。
另一种更详细的,将 MapReduce 分为5个步骤的理解是:
- Prepare the Map() input:
MapReduce框架先指定Map处理器,然后给其分配将要处理的输入数据 -- 键值对K1,并为该处理器提供与该键值相关的所有输入数据; - Run the user-provided Map() code:
Map()在K1键值对上运行一次,生成由K2指定的键值对的输出; - Shuffle the Map output to the Reduce processors:将先前生成的
K2键值对,根据『键』是否相同移至相同的工作节点; - Run the user-provided Reduce() code:对于每个工作节点上的
K2键值对进行Reduce()操作; - Produce the final output:
MapReduce框架收集所有Reduce输出,并按K2对其进行排序以产生最终结果进行输出。

实际生产环境中,数据很有可能是分散在各个服务器上,对于原先的大数据处理方法,则是将数据发送至代码所在的地方进行处理,这样非常低效且占用了大量的带宽,为应对这种情况,MapReduce 框架的处理方法是,将 Map() 操作或者 Reduce() 发送至数据所在的服务器上,以『移动计算替代移动数据』,来加速整个框架的运行速度,大多数计算都发生在具有本地磁盘上数据的节点上,从而减少了网络流量。
Mapper
一个 Map 函数就是对一些独立元素组成的概念上的列表的每一个元素进行指定的操作,所以每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map 操作是可以高度并行的
MapReduce 框架的 Map 和 Reduce 函数都是根据 (key, value) 形式的数据结构定义的。 Map 在一个数据域(Data Domain)中获取一个键值对,然后返回一个键值对的列表:
Map(k1,v1) → list(k2,v2)
Map 函数会被并行调用,应用于输入数据集中的每个键值对(keyed by K1)。然后每个调用返回一个键值对(keyed by K2)列表。之后,MapReduce 框架从所有列表中收集具有相同 key(这里是 k2)的所有键值对,并将它们组合在一起,为每个 key 创建一个组。
Reducer
而 Reduce 是对一个列表的元素进行适当的合并。虽然不如 Map 函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。Reduce 函数并行应用于每个组,从而在同一个数据域中生成一组值:
Reduce(k2, list (v2)) → list(v3)
Reduce 端接收到不同任务传来的有序数据组。此时 Reduce() 会根据程序猿编写的代码逻辑进行相应的 reduce 操作,例如根据同一个键值对进行计数加和等。如果Reduce 端接受的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。
Partitioner
前面提到过,Map 阶段有一个分割成组的操作,这个划分数据的过程就是 Partition,而负责分区的 java 类就是 Partitioner。
Partitioner 组件可以让 Map 对 Key 进行分区,从而将不同分区的 Key 交由不同的 Reduce 处理,由此,Partitioner 数量等同于 Reducer 的数量,一个 Partitioner 对应一个 Reduce 作业,可认为其就是 Reduce 的输入分片,可根据实际业务情况编程控制,提高 Reduce 效率或进行负载均衡。MapReduce 的内置分区是HashPartition。
具有多个分割总是有好处的,因为与处理整个输入所花费的时间相比,处理分割所花费的时间很短。当分割较小时,可以更好的处理负载平衡,但是分割也不宜太小,如果过小,则会使得管理拆分和任务加载的时间在总运行时间中占过高的比重。
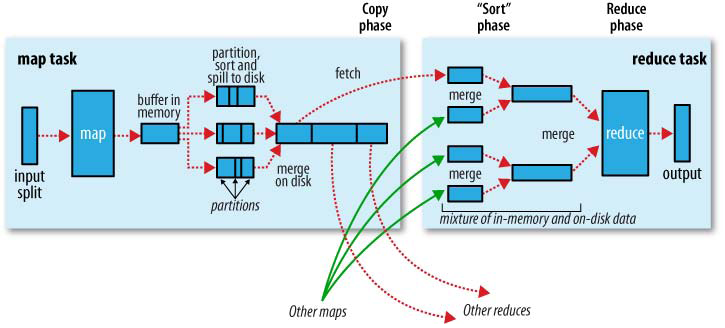
下图是 map 任务和 reduce 任务的示意图:
三、WordCount Example
这里给出一个统计词频案例的 Java 代码:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
// 继承 Mapper 类,实现自己的 map 功能
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
// map 功能必须实现的函数
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
// 继承 Reducer 类,实现自己的 reduce 功能
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
// 初始化Configuration,读取mapreduce系统配置信息
Configuration conf = new Configuration();
// 构建 Job 并且加载计算程序 WordCount.class
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
//指定 Mapper、Combiner、Reducer,也就是我们自己继承实现的类
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
// 设置输入输出数据
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
上述代码会发现在指定 Mapper 以及 Reducer 时,还指定了 Combiner 类,Combiner 是一个本地化的 reduce 操作(因此我们看见 WordCount 类里是用 reduce 进行加载的),它是 map 运算的后续操作,与 map 在同一个主机上进行,主要是在 map 计算出中间文件前做一个简单的合并重复key值的操作,减少中间文件的大小,这样在后续进行到 Shuffle 时,可以降低网络传输成本,提高网络传输效率。
提交 MR 作业的命令:
hadoop jar {程序的 jar 包} {任务名称} {数据输入路径} {数据输出路径}
例如:
hadoop jar hadoop-mapreduce-wordcount.jar WordCount /sample/input /sample/output
上述代码示意图:
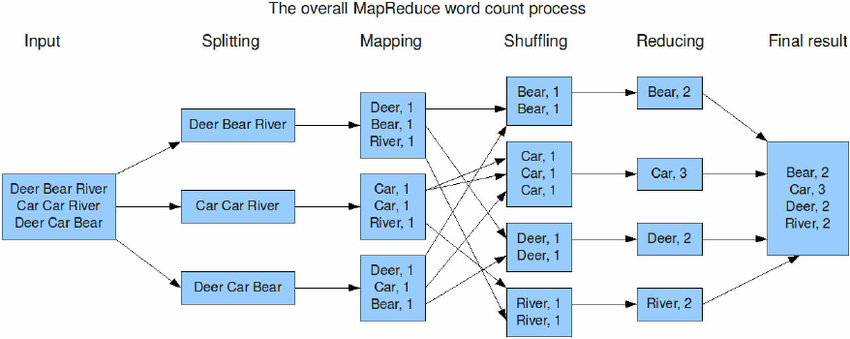
Map -> Shuffle -> Reduce 的中间结果,包括最后的输出都是存储在本地磁盘上。
四、Advantage & Shortcoming of MapReduce
MapReduce 的两大优势是:
1 ) 并行处理:
在 MapReduce 中,我们将作业划分为多个节点,每个节点同时处理作业的一部分。因此,MapReduce 基于Divide and Conquer范例,它帮助我们使用不同的机器处理数据。由于数据由多台机器而不是单台机器并行处理,因此处理数据所需的时间会减少很多。
2 ) 数据位置:
我们将计算移动到 MapReduce 框架中的数据,而不是将数据移动到计算部分。数据分布在多个节点中,其中每个节点处理驻留在其上的数据部分。
这使得具有以下优势:
- 将处理单元移动到数据所在位置可以降低网络成本;
- 由于所有节点并行处理其部分数据,因此处理时间缩短;
- 每个节点都会获取要处理的数据的一部分,因此节点不会出现负担过重的可能性。
但是,MapReduce 也有其限制:
- 不能进行流式计算和实时计算,只能计算离线数据;
- 中间结果存储在磁盘上,加大了磁盘的 I/O 负载,且读取速度比较慢;
- 开发麻烦,例如
wordcount功能就需要很多的设置和代码量,而Spark将会非常简单。
