

$mount
mount是手动加载的过程,接下来让我们看看具体是怎么实现的:
src/platforms/web/entry-runtime-with-compiler.js
/*把原本不带编译的$mount方法保存下来,在最后会调用。*/
const mount = Vue.prototype.$mount
/*挂载组件,带模板编译*/
Vue.prototype.$mount = function (
el?: string | Element,
hydrating?: boolean
): Component {
el = el && query(el)
/* istanbul ignore if */
if (el === document.body || el === document.documentElement) {
process.env.NODE_ENV !== 'production' && warn(
`Do not mount Vue to <html> or <body> - mount to normal elements instead.`
)
return this
}
const options = this.$options
// resolve template/el and convert to render function
/*处理模板templete,编译成render函数,render不存在的时候才会编译template,否则优先使用render*/
if (!options.render) {
let template = options.template
/*template存在的时候取template,不存在的时候取el的outerHTML*/
if (template) {
/*当template的类型是字符串时*/
if (typeof template === 'string') {
/*检索到template的首字母是#时判断为id*/
if (template.charAt(0) === '#') {
template = idToTemplate(template)
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && !template) {
warn(
`Template element not found or is empty: ${options.template}`,
this
)
}
}
} else if (template.nodeType) {
/*当template为DOM节点的时候*/
template = template.innerHTML
} else {
/*报错*/
if (process.env.NODE_ENV !== 'production') {
warn('invalid template option:' + template, this)
}
return this
}
} else if (el) {
/*获取element的outerHTML*/
template = getOuterHTML(el)
}
if (template) {
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
mark('compile')
}
/*将template编译成render函数,这里会有render以及staticRenderFns两个返回,这是vue的编译时优化,static静态不需要在VNode更新时进行patch,优化性能*/
const { render, staticRenderFns } = compileToFunctions(template, {
shouldDecodeNewlines,
shouldDecodeNewlinesForHref,
delimiters: options.delimiters,
comments: options.comments
}, this)
options.render = render
options.staticRenderFns = staticRenderFns
/* istanbul ignore if */
if (process.env.NODE_ENV !== 'production' && config.performance && mark) {
mark('compile end')
measure(`vue ${this._name} compile`, 'compile', 'compile end')
}
}
}
/*调用const mount = Vue.prototype.$mount保存下来的不带编译的mount*/
return mount.call(this, el, hydrating)
}
通过mount编译代码我们清晰的了解到,在mount的过程中,如果render函数不存在(render函数存在会优先使用render)会将template进行compileToFunctions得到render以及staticRenderFns。譬如说手写组件时加入了template的情况都会在运行时进行编译。而render function在运行后会返回VNode节点,供页面的渲染以及在update的时候patch。接下来我们来看一下template是如何编译的。
compile 函数(src/compiler/index.js)就是将 template 编译成 render function 的字符串形式。接下来就详细讲解这个函数:
import { parse } from './parser/index'
import { optimize } from './optimizer'
import { generate } from './codegen/index'
import { createCompilerCreator } from './create-compiler'
// `createCompilerCreator` allows creating compilers that use alternative
// parser/optimizer/codegen, e.g the SSR optimizing compiler.
// Here we just export a default compiler using the default parts.
export const createCompiler = createCompilerCreator(function baseCompile (
template: string,
options: CompilerOptions
): CompiledResult {
const ast = parse(template.trim(), options)
if (options.optimize !== false) {
optimize(ast, options)
}
const code = generate(ast, options)
return {
ast,
render: code.render,
staticRenderFns: code.staticRenderFns
}
})
createCompiler 函数主要通过3个步骤:parse、optimize、generate来生成一个包含ast、render、staticRenderFns的对象。
parse
在说parse函数之前,我们先来了解一个概念:AST(Abstract Syntax Tree)抽象语法树: 在计算机科学中,抽象语法树(abstract syntax tree或者缩写为AST),或者语法树(syntax tree),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。具体可以查看抽象语法树。
AST会经过generate得到render函数,render的返回值是VNode,VNode是Vue的虚拟DOM节点,具体定义如下:
export default class VNode {
tag: string | void;
data: VNodeData | void;
children: ?Array<VNode>;
text: string | void;
elm: Node | void;
ns: string | void;
context: Component | void; // rendered in this component's scope
key: string | number | void;
componentOptions: VNodeComponentOptions | void;
componentInstance: Component | void; // component instance
parent: VNode | void; // component placeholder node
// strictly internal
raw: boolean; // contains raw HTML? (server only)
isStatic: boolean; // hoisted static node
isRootInsert: boolean; // necessary for enter transition check
isComment: boolean; // empty comment placeholder?
isCloned: boolean; // is a cloned node?
isOnce: boolean; // is a v-once node?
asyncFactory: Function | void; // async component factory function
asyncMeta: Object | void;
isAsyncPlaceholder: boolean;
ssrContext: Object | void;
fnContext: Component | void; // real context vm for functional nodes
fnOptions: ?ComponentOptions; // for SSR caching
fnScopeId: ?string; // functional scope id support
constructor (
tag?: string,
data?: VNodeData,
children?: ?Array<VNode>,
text?: string,
elm?: Node,
context?: Component,
componentOptions?: VNodeComponentOptions,
asyncFactory?: Function
) {
/*当前节点的标签名*/
this.tag = tag
/*当前节点对应的对象,包含了具体的一些数据信息,是一个VNodeData类型,可以参考VNodeData类型中的数据信息*/
this.data = data
/*当前节点的子节点,是一个数组*/
this.children = children
/*当前节点的文本*/
this.text = text
/*当前虚拟节点对应的真实dom节点*/
this.elm = elm
/*当前节点的名字空间*/
this.ns = undefined
/*编译作用域*/
this.context = context
/*函数化组件作用域*/
this.functionalContext = undefined
/*节点的key属性,被当作节点的标志,用以优化*/
this.key = data && data.key
/*组件的option选项*/
this.componentOptions = componentOptions
/*当前节点对应的组件的实例*/
this.componentInstance = undefined
/*当前节点的父节点*/
this.parent = undefined
/*简而言之就是是否为原生HTML或只是普通文本,innerHTML的时候为true,textContent的时候为false*/
this.raw = false
/*静态节点标志*/
this.isStatic = false
/*是否作为跟节点插入*/
this.isRootInsert = true
/*是否为注释节点*/
this.isComment = false
/*是否为克隆节点*/
this.isCloned = false
/*是否有v-once指令*/
this.isOnce = false
/*异步组件的工厂方法*/
this.asyncFactory = asyncFactory
/*异步源*/
this.asyncMeta = undefined
/*是否异步的预赋值*/
this.isAsyncPlaceholder = false
}
// DEPRECATED: alias for componentInstance for backwards compat.
/* istanbul ignore next */
get child (): Component | void {
return this.componentInstance
}
}
接下来我们来看看parse的源码:
src/compiler/parser/index.js
function parse(template) {
...
const stack = [];
let currentParent; //当前父节点
let root; //最终返回出去的AST树根节点
...
parseHTML(template, {
start: function start(tag, attrs, unary) {
......
},
end: function end() {
......
},
chars: function chars(text) {
......
}
})
return root
}
这个方法太长啦,就省略了parse的相关内容,只看一下大体的功能,其主要的功能函数应该是parseHTML方法。接受了2个参数,一个使我们的模板template,另一个是包含start、end、chars的方法。 在看parseHTML之前,我们需要先了解一下下面这几个正则:
// 该正则式可匹配到 <div id="index"> 的 id="index" 属性部分
const attribute = /^\s*([^\s"'<>\/=]+)(?:\s*(=)\s*(?:"([^"]*)"+|'([^']*)'+|([^\s"'=<>`]+)))?/
const ncname = '[a-zA-Z_][\\w\\-\\.]*'
const qnameCapture = `((?:${ncname}\\:)?${ncname})`
// 匹配起始标签
const startTagOpen = new RegExp(`^<${qnameCapture}`)
const startTagClose = /^\s*(\/?)>/
// 匹配结束标签
const endTag = new RegExp(`^<\\/${qnameCapture}[^>]*>`)
// 匹配DOCTYPE、注释等特殊标签
const doctype = /^<!DOCTYPE [^>]+>/i
const comment = /^<!\--/
const conditionalComment = /^<!\[/
Vue 通过上面几个正则表达式去匹配开始结束标签、标签名、属性等等。有了上面这些基础,我们再来看看parseHtml的内部实行:
export function parseHTML (html, options) {
const stack = []
const expectHTML = options.expectHTML
const isUnaryTag = options.isUnaryTag || no
const canBeLeftOpenTag = options.canBeLeftOpenTag || no
let index = 0
let last, lastTag
while (html) {
// 保留 html 副本
last = html
// 如果没有lastTag,并确保我们不是在一个纯文本内容元素中:script、style、textarea
if (!lastTag || !isPlainTextElement(lastTag)) {
let textEnd = html.indexOf('<')
if (textEnd === 0) {
// Comment:
if (comment.test(html)) {
...
}
if (conditionalComment.test(html)) {
...
}
// Doctype:
const doctypeMatch = html.match(doctype)
if (doctypeMatch) {
...
}
// End tag:
const endTagMatch = html.match(endTag)
if (endTagMatch) {
...
}
// Start tag:
const startTagMatch = parseStartTag()
if (startTagMatch) {
...
}
}
let text, rest, next
if (textEnd >= 0) {
...
}
if (textEnd < 0) {
text = html
html = ''
}
// 绘制文本内容,使用 options.char 方法。
if (options.chars && text) {
options.chars(text)
}
} else {
...
}
...
}
上面只看一下代码的大概意思:
1.首先通过while (html)去循环判断html内容是否存在。
2.再判断文本内容是否在script/style标签中。
3.上述条件都满足的话,开始解析html字符串。
这里面有parseStartTag 和 handleStartTag两个方法值得关注一下:
function parseStartTag () {
//判断html中是否存在开始标签
const start = html.match(startTagOpen)
if (start) {
// 定义 match 结构
const match = {
tagName: start[1], // 标签名
attrs: [], // 属性名
start: index // 起点位置
}
/**
* 通过传入变量n来截取字符串,这也是Vue解析的重要方法,通过不断地蚕食掉html字符串,一步步完成对他的解析过程
*/
advance(start[0].length)
let end, attr
// 如果还没有到结束标签的位置
// 存入属性
while (!(end = html.match(startTagClose)) && (attr = html.match(attribute))) {
advance(attr[0].length)
match.attrs.push(attr)
}
// 返回处理后的标签match结构
if (end) {
match.unarySlash = end[1]
advance(end[0].length)
match.end = index
return match
}
}
}
假设我们设置一个html字符串
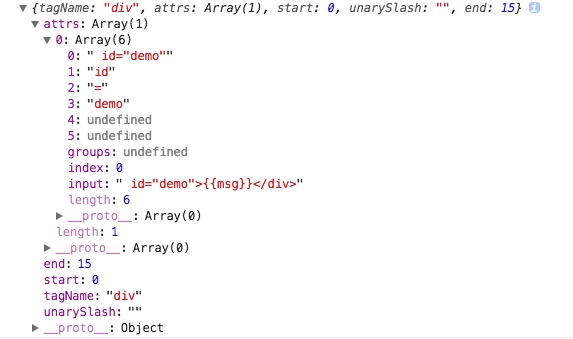
function handleStartTag (match) {
// match 是上面调用方法的时候传递过来的数据结构
const tagName = match.tagName
const unarySlash = match.unarySlash
...
const unary = isUnaryTag(tagName) || !!unarySlash
// 备份属性数组的长度
const l = match.attrs.length
// 构建长度为1的空数组
const attrs = new Array(l)
for (let i = 0; i < l; i++) {
const args = match.attrs[i]
...
// 取定义属性的值
const value = args[3] || args[4] || args[5] || ''
// 改变attr的格式为 [{name: 'id', value: 'demo'}]
attrs[i] = {
name: args[1],
value: decodeAttr(
value,
options.shouldDecodeNewlines
)
}
}
// stack中记录当前解析的标签
// 如果不是自闭和标签
// 这里的stack这个变量在parseHTML中定义,作用是为了存放标签名 为了和结束标签进行匹配的作用。
if (!unary) {
stack.push({ tag: tagName, lowerCasedTag: tagName.toLowerCase(), attrs: attrs })
lastTag = tagName
}
// parse 函数传入的 start 方法
options.start(tagName, attrs, unary, match.start, match.end)
}
到这里似乎一切明朗了许多,parseHTML主要用来解析html字符串,解析出字符串中的tagName,attrs,match等元素,传入start方法:
start (tag, attrs, unary) {
...
// 创建基础的 ASTElement
let element: ASTElement = createASTElement(tag, attrs, currentParent)
if (ns) {
element.ns = ns
}
...
if (!inVPre) {
// 判断有没有 v-pre 指令的元素。如果有的话 element.pre = true
// 官网有介绍:<span v-pre>{{ this will not be compiled }}</span>
// 跳过这个元素和它的子元素的编译过程。可以用来显示原始 Mustache 标签。跳过大量没有指令的节点会加快编译。
processPre(element)
if (element.pre) {
inVPre = true
}
}
if (platformIsPreTag(element.tag)) {
inPre = true
}
if (inVPre) {
// 处理原始属性
processRawAttrs(element)
} else if (!element.processed) {
// structural directives
// v-for v-if v-once
processFor(element)
processIf(element)
processOnce(element)
// element-scope stuff
processElement(element, options)
}
// 检查根节点约束
function checkRootConstraints (el) {
if (process.env.NODE_ENV !== 'production') {
if (el.tag === 'slot' || el.tag === 'template') {
warnOnce(
`Cannot use <${el.tag}> as component root element because it may ` +
'contain multiple nodes.'
)
}
if (el.attrsMap.hasOwnProperty('v-for')) {
warnOnce(
'Cannot use v-for on stateful component root element because ' +
'it renders multiple elements.'
)
}
}
}
// tree management
if (!root) {
// 如果不存在根节点
root = element
checkRootConstraints(root)
} else if (!stack.length) {
// 允许有 v-if, v-else-if 和 v-else 的根元素
...
if (currentParent && !element.forbidden) {
if (element.elseif || element.else) {
processIfConditions(element, currentParent)
} else if (element.slotScope) { // scoped slot
currentParent.plain = false
const name = element.slotTarget || '"default"'
;(currentParent.scopedSlots || (currentParent.scopedSlots = {}))[name] = element
} else {
// 将元素插入 children 数组中
currentParent.children.push(element)
element.parent = currentParent
}
}
if (!unary) {
currentParent = element
stack.push(element)
} else {
endPre(element)
}
// apply post-transforms
for (let i = 0; i < postTransforms.length; i++) {
postTransforms[i](element, options)
}
}
其实start方法就是处理 element 元素的过程。确定命名空间;创建AST元素 element;执行预处理;定义root;处理各类 v- 标签的逻辑;最后更新 root、currentParent、stack 的结果。 最终通过 createASTElement 方法定义了一个新的 AST 对象。
总结
下面我们来屡一下parse整体的过程:
1.通过parseHtml来一步步解析传入html字符串的标签、元素、文本、注释..。
2.parseHtml解析过程中,调用传入的start,end,chars方法来生成AST语法树
我们看一下最终生成的AST语法树对象:

要是喜欢的话给我个star, github
感谢muwoo提供的解析思路。
