

Apache Kylin 入门系列目录
- Apache Kylin 入门 1 - 基本概念
- Apache Kylin 入门 2 - 原理与架构
- Apache Kylin 入门 3 - 安装配置参数详解
- Apache Kylin 入门 4 - 构建 Model
- Apache Kylin 入门 5 - 构建 Cube
- Apache Kylin 入门 6 - 优化 Cube
- 基于 ELKB 构建 Kylin 查询时间监控页面
工作原理
简单来说,Kylin 的核心思想是预计算(利用空间换时间),即对多维分析可能用到的度量进行预计算,将计算好的结果保存成 Cube 并存在 HBase 中,供查询时直接访问。
把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了 Kylin 能够拥有很好的快速查询和高并发能力,具体工作过程如下:
- 指定数据模型(Model),定义维度(Dimensions)和度量(Measure);
- 预计算 Cube,计算所有 Cuboid 并保存为物化视图;
- 执行查询时(Restful API/JDBC/ODBC),读取 Cuboid,运算,产生查询结果。
体系架构
Apache Kylin 系统可以分为在线查询和离线构建两部分,技术架构如图所示,在线查询的模块主要处于上半区,而离线构建则处于下半区。
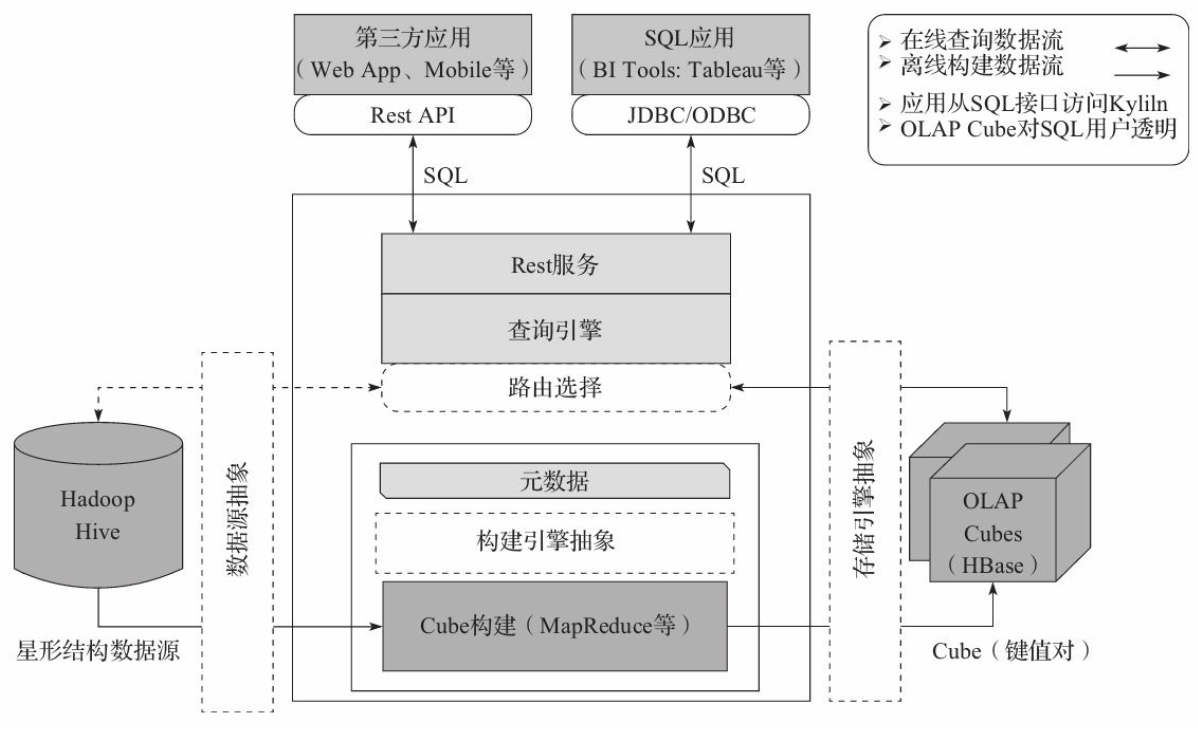
Kylin 的核心模块
- REST Server:提供 Restful 接口,例如创建、构建、刷新、合并等 Cube 相关操作,Kylin 的 Projects、Tables 等元数据管理,用户访问权限控制,SQL 的查询等;
- Query Engine:使用开源的 Apache Calcite 框架来实现 SQL 解析,可以理解为 SQL 引擎层;
- Routing:负责将解析 SQL 生成的执行计划转换成 Cube 缓存的查询,这部分查询是可以在秒级甚至毫秒级完成;
- Metadata:Kylin 中有大量的元数据信息,包括 Cube 的定义、星型模型的定义、Job 和执行 Job 的输出信息、模型的维度信息等等,Kylin 的元数据和 Cube 都存储在 HBase 中,存储的格式是 json 字符串;
- Cube Build Engine:所有模块的基础,它主要负责 Kylin 预计算中创建 Cube,创建的过程是首先通过 Hive 读取原始数据,然后通过一些 MapReduce 或 Spark 计算生成 Htable,最后将数据 load 到 HBase 表中。
离线构建
离线构建的主要步骤:
- 数据源在左侧,目前主要是 Hadoop Hive,保存着待分析的用户数据;
- 根据元数据的定义,下方构建引擎从数据源抽取数据,并构建 Cube;
- 数据以关系表的形式输入,
且必须符合星形模型(2.0 开始已经支持星型模型); MapReduce 是当前主要的构建技术(2.5 开始 Spark 是主要的构建技术);- 构建后的 Cube 保存在右侧的存储引擎中,一般选用 HBase 作为存储。
在线查询
- 用户可以从上方查询系统(Rest API、JDBC/ODBC)发送 SQL 进行查询分析;
- 无论从哪个接口进入,SQL 最终都会来到 Rest 服务层,再转交给查询引擎进行处理;
- 查询引擎解析 SQL,生成基于关系表的逻辑执行计划;
- 然后将其转译为基于 Cube 的物理执行计划;
- 最后查询预计算生成的 Cube 并产生结果。
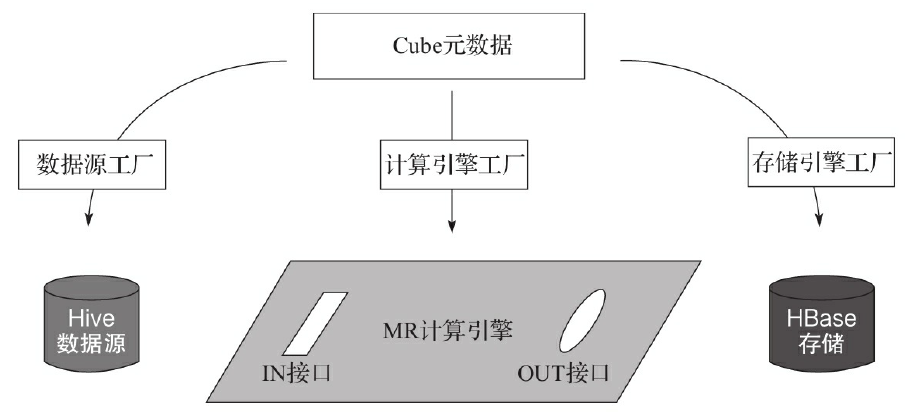
可扩展架构
可扩展指 Kylin 可以对其主要依赖的三个模块做任意的扩展和替换,Kylin 的三大依赖模块分别是数据源(Hive)、构建引擎(MR)和存储引擎(HBase)。
可扩展架构带来了额外的灵活性,比如,它可以允许多个引擎同时并存。例如 Kylin 可以同时对接 Hive、Kafka 和其他第三方数据源;抑或用户可以为不同的 Cube 指定不同的构建引擎或存储引擎,以期达到最极致的性能和功能定制。
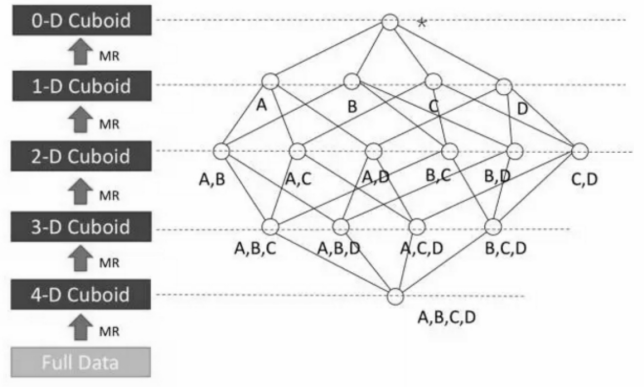
构建算法
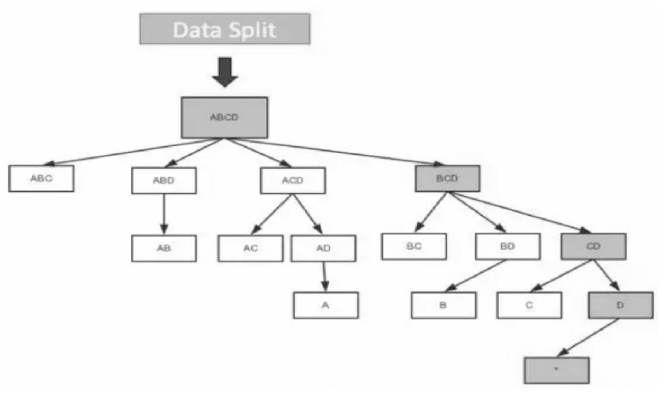
Layered Cubing
这个四维 Cube 需要五轮的 MapReduce 来完成:第一轮 MR 的输入是源数据,这一步会对维度列的值进行编码,并计算 ABCD 组合的结果。接下来的 MR 以上一轮的输出结果为输入,向上聚合计算三个维度的组合:ABC、BCD、ABD和ACD;依此类推,直到算出所有的维度组合。
Layered Cubing 的特点:
- 算法比较简单;
- 算法的稳定性非常高;
- 计算量或者数据量大的时候并不能充分利用系统的资源;
- 没有充分利用内存(缓存中间计算结果)。
Fast Cubing
最大化利用 Mapper 端的 CPU 和内存,对分配的数据块,将需要的组合全都做计算后再输出给 Reducer;由 Reducer 再做一次合并(Merge),从而计算出完整数据的所有组合。如此,经过一轮 MapReduce 就完成了以前需要 N 轮的 Cube 计算。
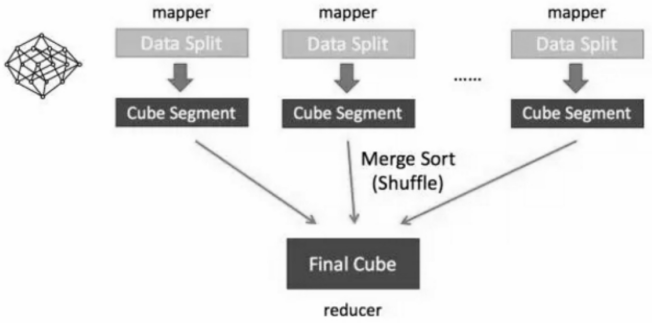
Fast Cubing 的特点:最大限度地把计算发生在 Mapper 这一端,一方面减少 shuffle 的数据量,另一方面减少 Reducer 端的计算量。
第一步会计算 Base Cuboid(所有维度都有的组合),再基于它计算减少一个维度的组合。基于 parent 节点计算 child 节点,可以重用之前的计算结果;当计算 child 节点时,需要 parent 节点的值尽可能留在内存中;如果 child 节点还有 child,那么递归向下,所以它是一个深度优先遍历。当有一个节点没有 child,或者它的所有 child 都已经计算完,这时候它就可以被输出,占用的内存就可以释放。
Any Code,Code Any!
扫码关注『AnyCode』,编程路上,一起前行。

