

开始
早前通过swoole了解到了协程的概念,正值当时看到了JS的GeneratorFunction,于是激动的心颤抖的手,敲着代码往前走,就用js写下了一个协程模块node-coroutine-js.当然这个模块比较简单,基本就是利用node本身的能力实现的,其中为了避免主线的阻塞所以使用了setImmediate的方法来执行方法。后来在了解协程方面信息的时候,了解到了libco以后,又产生了通过libco的方式来做node协程模块,因为libco这个库真的太厉害了,我接下来为大家分析一下其中我用到的swap相关的核心逻辑。至于libco的loop,在node的libuv面前却显得不太出众。
libco核心逻辑
libco是通过一个stCoRoutine_t结构体来管理一个协程单元的,这个结构中主要包括了该协程单元的被交换时的寄存器值,以及stack的空间,以及协程执行的方法和传入的参数值,通过co_create方法来初始化,初始化的过程也不算复杂,有兴趣的可以自己了解一下。然后在初始化了stCoRoutine_t以后,通过co_resume方法将协程方法调用起来,其具体代码如下所示:
void co_resume( stCoRoutine_t *co )
{
stCoRoutineEnv_t *env = co->env;
stCoRoutine_t *lpCurrRoutine = env->pCallStack[ env->iCallStackSize - 1 ];
if( !co->cStart )
{
coctx_make( &co->ctx,(coctx_pfn_t)CoRoutineFunc,co,0 );
co->cStart = 1;
}
env->pCallStack[ env->iCallStackSize++ ] = co;
co_swap( lpCurrRoutine, co );
}
其中stCoRoutineEnv_t结构体是每个线程中管理整个协程操作调度的结构体,其中通过pCallStack数组来维持一个调用栈,其中总是包含一个保存主线信息的stCoRoutine_t,该数组默认有128的深度来用于一些嵌套的调用,不过通常情况下不会出现太深的嵌套,基本就是主线和当前正在调用的协程方法两个值。从函数中我们可以看出,如果方法是第一次执行会首先通过coctx_make来做一次对coctx_t的初始化。结构体coctx_t是调用中的核心,上面我们说过stCoRoutine_t保存了寄存器值就是通过该结构体来保存的,我们来看下这个结构体的代码:
struct coctx_t
{
#if defined(__i386__)
void *regs[ 8 ];
#else
void *regs[ 14 ];
#endif
size_t ss_size;
char *ss_sp;
};
从结构体的属性我么可以看出,32位存储7个寄存器的值和返回地址的值,而64位存储13个寄存器的值和返回地址的值,ss_sp则是存储的是初始化stCoRoutine_t时所分配的stack在内存中的起始位置。了解了coctx_t以后我们来看看它是如何初始化的:
#if defined(__i386__)
int coctx_make( coctx_t *ctx,coctx_pfn_t pfn,const void *s,const void *s1 )
{
//make room for coctx_param
char *sp = ctx->ss_sp + ctx->ss_size - sizeof(coctx_param_t);
sp = (char*)((unsigned long)sp & -16L);
coctx_param_t* param = (coctx_param_t*)sp ;
param->s1 = s;
param->s2 = s1;
memset(ctx->regs, 0, sizeof(ctx->regs));
ctx->regs[ kESP ] = (char*)(sp) - sizeof(void*);
ctx->regs[ kEIP ] = (char*)pfn;
return 0;
}
#elif defined(__x86_64__)
int coctx_make( coctx_t *ctx,coctx_pfn_t pfn,const void *s,const void *s1 )
{
char *sp = ctx->ss_sp + ctx->ss_size;
sp = (char*) ((unsigned long)sp & -16LL );
memset(ctx->regs, 0, sizeof(ctx->regs));
ctx->regs[ kRSP ] = sp - 8;
ctx->regs[ kRETAddr] = (char*)pfn;
ctx->regs[ kRDI ] = (char*)s;
ctx->regs[ kRSI ] = (char*)s1;
return 0;
}
#endif
接下来我们来了解一下上面的代码,虽然上面的代码有32位架构的也有64位架构的,但是其实做的都是同样三件事:
1.指定sp的起始地址,因为coctx_t的ss_sp指针指向的位置在低位,而我们知道,esp所存放的栈上地址是由高到低的,所以需要通过ctx->ss_sp + ctx->ss_size;的方式找到内存的高位,再通过align方式将内存对齐,然后通过减去一个sizeof(void*)的内存用来放置fp的指针,而在32位的架构中还要多留两个指针的位置存放传入参数,就得到了协程方法的sp起始地址。
2.指定传入的参数,我们可以看到在32位架构中,参数是通过push入栈的形式传入的,后面的参数先进栈,前面的参数后进栈(所以s1在低位,s2在高位),而在64位的架构中则是通过rdi寄存器传入第一个参数,rsi传入第二个参数,这个对我们后面讨论汇编语句的时候很重要,当然对于熟悉汇编的朋友来说,这些提不提都行。
3.将需要执行的方法的地址置为返回地址中,即是CoRoutineFunc。
在完成了coctx_t的初始化以后,则是文件中最核心的调用了co_swap函数。在主线中调用co_resume函数时,lpCurrRoutine必然保存的是主线的信息,我们就不讨论深入嵌套的情况了,就只看主线是如何调用协程函数的。co_swap中有很多记录信息的东西,我们可以抛开不看,其中最主要的就是嵌入的汇编函数void coctx_swap( coctx_t *,coctx_t* ) asm("coctx_swap");,我们来看一下他的代码,很简短,但是真的让人惊叹:
#if defined(__i386__)
leal 4(%esp), %eax //sp
movl 4(%esp), %esp
leal 32(%esp), %esp //parm a : ®s[7] + sizeof(void*)
pushl %eax //esp ->parm a
pushl %ebp
pushl %esi
pushl %edi
pushl %edx
pushl %ecx
pushl %ebx
pushl -4(%eax)
movl 4(%eax), %esp //parm b -> ®s[0]
popl %eax //ret func addr
popl %ebx
popl %ecx
popl %edx
popl %edi
popl %esi
popl %ebp
popl %esp
pushl %eax //set ret func addr
xorl %eax, %eax
ret
#elif defined(__x86_64__)
leaq 8(%rsp),%rax
leaq 112(%rdi),%rsp
pushq %rax
pushq %rbx
pushq %rcx
pushq %rdx
pushq -8(%rax) //ret func addr
pushq %rsi
pushq %rdi
pushq %rbp
pushq %r8
pushq %r9
pushq %r12
pushq %r13
pushq %r14
pushq %r15
movq %rsi, %rsp
popq %r15
popq %r14
popq %r13
popq %r12
popq %r9
popq %r8
popq %rbp
popq %rdi
popq %rsi
popq %rax //ret func addr
popq %rdx
popq %rcx
popq %rbx
popq %rsp
pushq %rax
xorl %eax, %eax
ret
#endif
我们着重来分析一下32位的操作,刚刚我们说过,在32位系统中后面的参数先入栈,而前面的参数后入栈,所以leal 4(%esp), %eax首先将传入的第一个参数的栈地址赋值给eax寄存器,第一个参数当然就是我们主线的上下文,接着通过movl 4(%esp), %esp将取第一个参数栈地址赋值给esp寄存器,也就是第一个参数本身,指向主线上下文的指针,为什么要这么做呢,我们接下来看这句leal 32(%esp), %esp,也就是会将指向上下文的指针加32以后的值赋值给esp,就等于这样current_ctx_ptr + 32 = esp。刚刚说到我们的ctx指针指向的起始值也是低位,而esp的值是从高到低变化的,所以先将esp的值指向ctx.reg数组结束处,这样做在每次执行push指令的时候就能将值存入到当前的ctx.reg数组的位置上,所以我们可以看到这样的存值方式,eax的指针在ctx.reg[7],而ebx在ctx.reg[1],最后一句pushl -4(%eax) 要着重说一下,eax我们知道是当前上线文的指针值,是通过esp+4得到的,那么eax-4得到的就是最初的esp值,这个值自然是指向返回地址的,所以在ctx.reg[0]中存放的是返回地址,我们知道主线返回地址自然是调用coctx_swap方法的co_swap方法。movl 4(%eax), %esp,通过上面的分析我们就可以知道这是将第二个参数即协程上下文的的地址传入esp寄存器,这个时候这个指针指向的既是ctx->regs[0]的地址,将之pop到eax,后面的则是将regs数组中的值pop到对应的寄存器上。从刚刚我们看到的协程上下文的初始化中,我们可以看到我们将CoRoutineFunc的地址放入ctx->regs[0]中,所以pushl %eax即是将CoRoutineFunc的地址压到栈顶,然后通过ret指令则会跳转到esp指向的地址。而xorl %eax, %eax是一个清空eax寄存器的操作。
分析完了这个汇编文件我们就可知道,在主线中调用了coctx_swap函数后,即会根据改变了的返回地址跳转到CoRoutineFunc中执行:
static int CoRoutineFunc( stCoRoutine_t *co,void * )
{
if( co->pfn )
{
co->pfn( co->arg );
}
co->cEnd = 1;
stCoRoutineEnv_t *env = co->env;
co_yield_env( env );
return 0;
}
在这个函数中,会调用我们在开始通过co_create注册的函数,在执行完成后会调用co_yield_env:
stCoRoutine_t *last = env->pCallStack[ env->iCallStackSize - 2 ];
stCoRoutine_t *curr = env->pCallStack[ env->iCallStackSize - 1 ];
env->iCallStackSize--;
co_swap( curr, last);
这个函数将会通过co_swap返回到主线上,通过刚刚的描述我们可以知道即是返回到主线co_swap调用完成coctx_swap处。
到此基本整个libco的交换核心部分就讨论完毕了,在了解了这个过程以后确实让人拍案叫绝,以前看深入Linux内核架构的时候看到内核在创建线程时候代码:
Linux内核版本2.6.24
arch/x86/kernel/process_32.c
asmlinkage int sys_clone(struct pt_regs regs) {
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs.ebx;
newsp = regs.ecx;
parent_tidptr = (int __user *)regs.edx; child_tidptr = (int __user *)regs.edi; if (!newsp)
newsp = regs.esp;
return do_fork(clone_flags, newsp, ®s, 0, parent_tidptr, child_tidptr);
}
从上面的代码我们可以粗略看出,创建线程的newsp通过ecx传入的,跟libco在堆上分配一块内存然后将协程的esp指向该处颇有相似之处。当然协程的调度中因为没有内核参与任务的调度,加上是单线操作,避开了一些锁竞争之类的问题,使性能得到了极大的提升,即是其优势所在。
node-coroutine
说完了libco的逻辑,说回我自己开发的模块,当然开发这个东西毫无必要,毕竟通过generatorFunction本身就可以实现了,不过我还是想尝试一下这方面的开发,于是就开始了自坑之路,项目地址: node-coroutine
首先,libco中包括了很多关于多线程和异步的东西,多线程在node中没用,而异步比起libuv来说确实只是个子集,所以我先砍掉了这两块,将env作为全局的变量在注册模块的时候就会初始化。另外libco的方法也只保留了跟交换上下文有关的核心方法,如下:
//2.context
int coctx_init( coctx_t *ctx ,pfn_co_routine_t pfn,const void *s);
//3.coroutine
int co_create( stCoRoutine_t **co,const stCoRoutineAttr_t *attr,pfn_co_routine_t pfn,void *arg );
void co_swap(stCoRoutine_t* curr, stCoRoutine_t* pending_co,int main);
void co_yield();
void co_free( stCoRoutine_t * co );
//4.func
void save_stack_buffer(stCoRoutine_t* occupy_co);
stStackMem_t* co_get_stackmem(stShareStack_t* share_stack);
stStackMem_t* co_alloc_stackmem(unsigned int stack_size);
stShareStack_t* co_alloc_sharestack(int count, int stack_size);
至于我自己写的流程相对来说比较简单,只是在swap的时候没有当时调用而是通过uv_work_t的回调来实现,因为最后的协程方法都是在循环中调用,如果都是无限循环的方法,很可能造成主线的其他业务无法执行,一直在协程中执行的情况,所以通过uv_work的方式可以让libuv的loop始终在执行,在从协程回到主线时,可以处理其他业务(跟js版使用setImmediate来执行切换的思路类似)。不过在开发过程中遇到的两个问题倒是值得跟大家分享:
SetStackLimit的坑
因为协程的栈地址是在堆上执行,所以在第一次跑测试的就报出了这个错误:
RangeError: Maximum call stack size exceeded
这种情况一般在我们的平时的编程中多半是无限的递归调用导致,但是我很确定我的代码中没有递归,那么我就判断出肯定是v8对内存中执行的地址是有限制的,这个时候我就想起了node的v8-options中有一个 stack_size的选项,既然有这个选项我就猜测应该会有一个设置这个值的地方,于是就直接在v8.h文件中搜索stack_size,但是并没有,于是我就只搜索stack,出来的选项有点多,不过没往下跳几次,我就找到了一个setStackLimit的方法,然后心中那个高兴啊,觉得自己解决这个问题易如反掌,因为需要设置的stack是在协程方法中于是我就在我的协程方法中加入了这样的语句:
uintptr_t limit = reinterpret_cast<uintptr_t>(&limit) - (co_arg->coroutine->ctx).ss_size;
globalIsolate->SetStackLimit(limit);
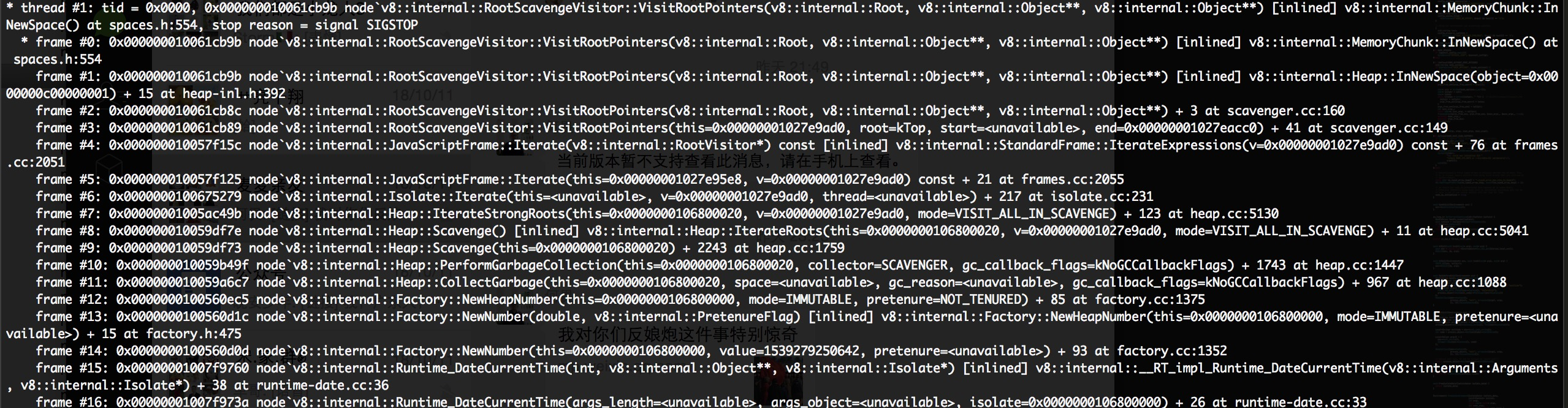
结果这样以后并没有起到作用,这让我很诧异,我去V8看了源码,这个方法主要就是设置thread_top的c_limit值和js_limit值,然后我在源码中打印了设置后的这两个值,发现设置成功了,但是依然没解决问题,这让我很是不解。于是我就在v8中搜索这个错误,然后发现该错误是从方法Isolate::StackOverflow中爆出来的,于是我在该方法中做了断言,产生了core文件,然后用llnode做了分析,得到下图:

从该图可以看出是在internal的frame中判断出错的,这个是v8内部的runtime方法执行而爆出来的错。于是我就找到了v8/src/runtime/runtime_internal.cc中,这个文件中有两个地方都出现了isolate->StackOverflow()的调用,这个就简单了,我在这两个方法下都下个断言,然后就发现错误是这个地方暴出的:
RUNTIME_FUNCTION(Runtime_ThrowStackOverflow) {
SealHandleScope shs(isolate);
DCHECK_LE(0, args.length());
return isolate->StackOverflow();
}
你如果搜索Runtime_ThrowStackOverflow在全局都是找不到方法的,因为在v8内部通过宏将Runtime方法都放到了一个数组中,而其索引成为了FunctionId来索引这些方法调用,所以通过搜索kThrowStackOverflow即可找到调用调用处,发现在builtins-xxx.cc中都是调用这个方法,当然我的机器是x64的所以我直接找到了builtins-x64.cc的文件中,在每个调用kThrowStackOverflow的地方打印出标记,然后编译执行,结果。。。编译的时候我打印的语句倒是都执行了,但是执行的时候一个都没执行。然后我就猜测这个地方的可能在编译过程中都变成了字节码,而我的打印语句明显不是需要转变成字节码的一部分,所以编译的时候直接执行过了,但是真正执行的时候并没有什么用。那怎么办呢?当然就是按照他的格式写啦,于是我在runtime-internal.cc中加入了一个方法
RUNTIME_FUNCTION(Runtime_ThrowStackOverflowDebug) {
SealHandleScope shs(isolate);
DCHECK_LE(0, args.length());
printf("have done!\n");
return isolate->StackOverflow();
}
当然只在这里加还是不够的还要在src/runtime/runtime.h中的#define FOR_EACH_INTRINSIC_INTERNAL(F)下面加一条F(ThrowStackOverflowDebug, 0, 1)这个时候再编译就行了,就这样通过测试我发现这个错误主要是builtins-x64.cc中两个地方报出来的:
static void Generate_CheckStackOverflow(MacroAssembler* masm,IsTagged rax_is_tagged)
中通过判断:
__ cmpp(rcx, r11);
__ j(greater, &okay); // Signed comparison.
// Out of stack space.
__ CallRuntime(Runtime::kThrowStackOverflow);
爆出,以及:
static void Generate_StackOverflowCheck(MacroAssembler* masm, Register num_args, Register scratch,Label* stack_overflow,Label::Distance stack_overflow_distance = Label::kFar)
中的判断:
__ cmpp(scratch, num_args);
// Signed comparison.
__ j(less_equal, stack_overflow, stack_overflow_distance);
不得不说v8这个伪汇编写得真是太舒服了,让我爆破之魂熊熊燃烧,于是 通过将上面方法中的方法__ j(greater, &okay);改成__ j(always, &okay);,而下面的__ j(less_equal, stack_overflow, stack_overflow_distance);改成__ j(never, stack_overflow, stack_overflow_distance);重新编译,然后问题就解决了。不过我总不能让别人用我这个编译版本吧,于是还是静下来心来看,发现这些判断上面都跟一个变量有密切的关系:Heap::kRealStackLimitRootIndex于是我搜索了这个变量。好吧又回到了stacklimit上,这次我找到了Heap::SetStackLimits发现是这个方法下会设置上面的参数:
roots_[kRealStackLimitRootIndex] = reinterpret_cast<Object*>((isolate_->stack_guard()->real_jslimit() & ~kSmiTagMask) | kSmiTag);
我又在下面下了断言,然后执行测试文件,果然没执行,这个时候我很困惑,难道还真的不能设置这个值不成?然后就用试一试的心态又放到主线上执行,结果这次真的执行了。原来isolate::SetStackLimit要在正常的stack下去设置才行,通过isolate::SetStackLimit打断点以后发现这个原因其实很简单,因为设置了这个limit以后要过会儿才通过runtime方法的调用来生效,而在协程方法中不会执行这些方法,所以设置了也不会生效。所以我在main.cpp的方法中直接设置了globalIsolate->SetStackLimit(1)因为不能判断到底最低的stack在哪儿。
在这次修改以后终于能执行成功了,但是我还没来得及高兴,又发生了崩溃了。。。
莫名其妙的HeapObject
既然发生了崩溃,第一件事就是用llnode打开core文件,原来是新生代回收在做扫描的时候发生了崩溃,既然找到了地址当然是打开代码一看,这是一个很简单的Inline函数总共只有一句话:
flags_ & kIsInNewSpaceMask) != 0;
所以只能判断是这个对象本身发生了问题,于是我打印了扫描的所有object的指针,果然发现在崩溃时会出现一个很莫名其妙的地址,如下图所示:
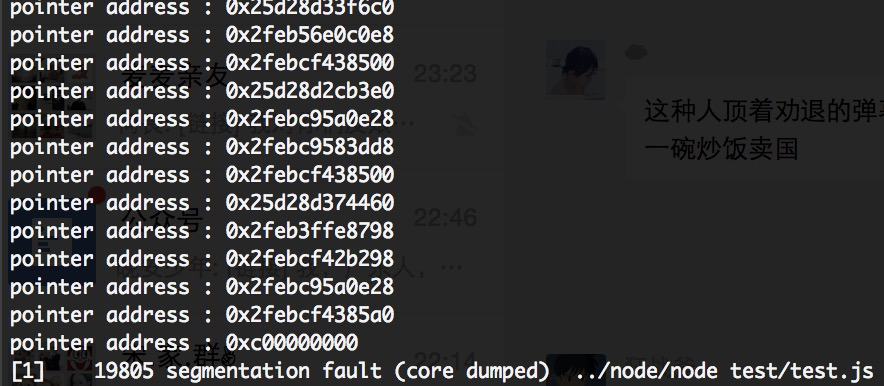
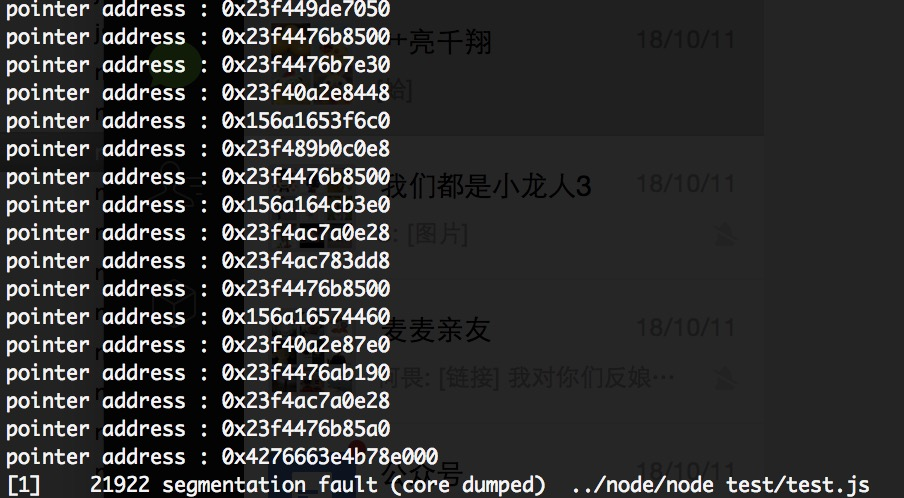
这个HeapObject的出现就让我百思不得其解了。难道是在栈上产生的对象?但新生代和老生代的都是heap上的内存,按理说不应该都在一个范围内,不应该出现如此诡异的内存地址啊,所以猜测应该是有其他地址的内存溢出导致改写了这里的正常值,或者是已经回收了这段内存但是在jsframe的栈上还找得到其指针。但是在是什么造成上述的这些问题或者是其他什么原因,到现在我还是毫无头绪,希望有朋友能帮忙给出一些答案。
总结
一次不成功的开发之旅,虽然探索了很多东西,但是最后没能解决乱地址的问题,确实让人很沮丧,还希望能有高手帮忙指出。
