

声明:本文由罗周杨原创,转载请注明作者和出处
本文是阅读斯坦福经典教材 Speech and Language Processing-Logistic Regression 所做的笔记,推荐看原文。
Logistic Regression可以用于二分类问题和多分类问题(Multinomial logistic regression)。逻辑回归是一种分类算法,并不是回归算法。逻辑回归属于判别式分类器(discriminative classifier),而朴素贝叶斯属于生成式分类器(generative classifier)。
判别式分类器和生成式分类器
为了区别这两种分类器,我们可以举一个简单的例子:区分照片里面的动物是猫还是狗。
Generative model的目标是,理解什么是猫什么事狗,然后做出判断。而Discriminative model则是紧紧学习怎样去区分这两种动物,而不是去学习它们是什么。
在数学上更直观的比较,首先看我们的niave Bayes分类公式:
对于generative model(例如naive Bayes)使用一个**似然(likelihood)**项来计算,这个项表示的是如何生成一个文档的特征,如果我们知道它是类别c的话。而对于discriminative model,它会尝试直接去计算
。
基于概率的机器学习分类器的组成
基于概率的机器学习分类器有以下几个组成部分:
- 特征表示,即对每一个输入的表示
- 一个分类函数,用来估算当前输入的类别,例如sigmoid和softmax
- 一个目标函数,通常涉及在训练集上最小化误差,例如交叉熵损失函数
- 一个优化目标函数的算法,例如SGD
Sigmoid
二分类逻辑回归的目标是训练一个分类器,可以做出二分类决策,sigmoid就是可行的方式之一。
逻辑回归通过从训练集学习两个参数和
来做出决策。
逻辑回归的类别估算公式如下:
要学习的两个参数在上式也有直接体现。
在线性代数里面,通常把上面的加权和用**点积(dot product)**来表示,所以上式等价于:
那么得到的结果是一个浮点数,对于二分类为题,结果只有0和1两种,那我们怎么判断这个z是属于0类别还是1类别呢?
我们先看看sigmoid函数长什么样吧。
图像如下:
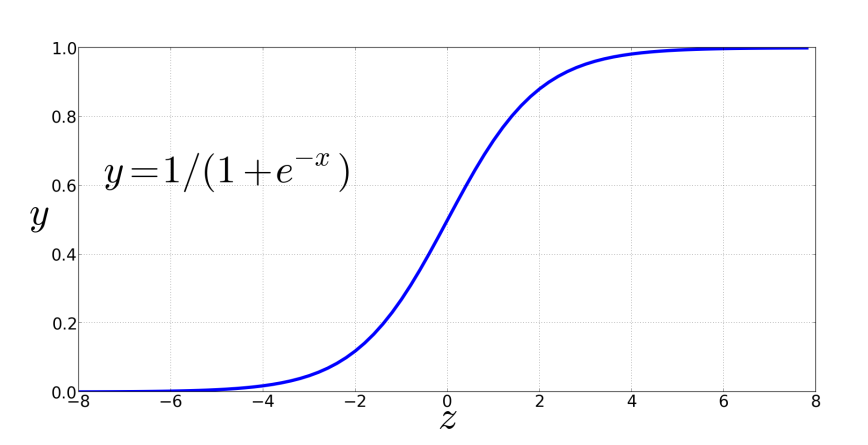
可以看到,sigmoid函数的值域是(0,1),并且是关于(0,0.5)对称的,所以很容易得到一个决策边界:
z<=0.5时属于0类别z>0.5时属于1类别
sigmoid函数有很多很好的性质:
- 它的输入范围是
,输出值范围是
,这就是天然的概率表示啊!
- 在
x=0附近几乎是线性的,在非常负或者非常正的时候,变化不大
至此,我们可以计算类别0和类别1的概率:
cross-entropy损失函数
说到损失函数,你可能会想到均方差损失(MSE):
这个损失在线性回归里面用的很多,但是将它应用于概率分类的话,就变得难以优化了(主要是非凸性)。
条件似然估计(conditional maximum likelihood estimation):选择参数和
来最大化标签和训练数据之间(
)的对数概率。
因为类别的分布是一个伯努利分布(Bernoulli distribution),所以我们可以很容易写出:
因为,当y=1时,,当
y=0时,。
由此,可以得到对数概率:
我们的训练过程就是要最大化这个对数概率。如果对上式两边取负数,最大化问题就变成了最小化问题,即训练的目标就是最小化:
又因为,所以我们的负对数似然损失公式为:
这也就是我们的交叉熵损失(cross-entorpy loss),至于为什么是这个名称,因为上述公式就是:的概率分布和估计分布
之间的交叉熵。
所以,在整个批量的数据上,我们可以得到平均损失为:
梯度下降
梯度下降的目标就是最小化损失,用公式表示就是:
对于我们的Logistic Regression,就是
和
。
那么我们如何最小化这个损失呢?梯度下降就是一种寻找最小值的方式,它是通过倒数来得到函数的最快衰减方向来完成的。
对于逻辑回归的这个损失函数来说,它是凸函数(convex function),所以它只有一个最小值,没有局部最小值,所以优化过程中肯定可以找到全局最小点。
举个二维的例子,感受一下这个过程,如下图所示:
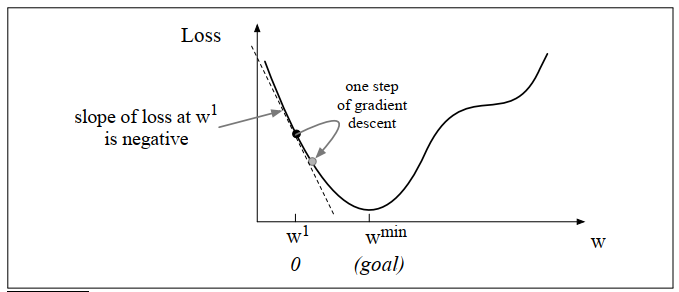
可见,上述损失函数的优化过程就是每次向着梯度的正方向移动一小步!可以用公式表示如下:
上面 决定了这个一小步是多少,也称作学习率(learning rate)。
上面的梯度 结果是一个常数。
如果是N维空间呢?那么梯度就是一个矢量了,如下所示:
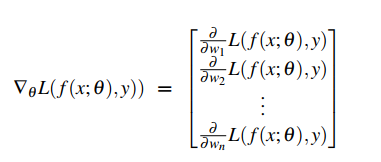
那么,我们的参数更新就是:
Logistic Regression的梯度
逻辑回归的损失如下:
我们有:
对于一个批量的数据,我们的梯度如下:
正则化
上面训练的模型可能会出现过拟合(overfitting),为了解决这个问题,我们需要一项技术,叫做正则化(regularization)。
正则化是对权重的一种约束,更细致一点地说,是在以最大化对数概率的前提下,对权重
的约束。
所以我们的目标可以用下面的公式描述:
其中,就是正则项(regularization term)。
上式可以看出,正则项是为了惩罚大的权重。我们总是倾向于,在效果差不多的模型中,选择更少的那一个。所谓
更少就是
的特征更少,即指
的向量中0的个数更多的。
常用的正则化方式有L2正则和L1正则。
L2正则计算的是欧氏距离,公式如下:
L1正则计算的是马哈顿距离,公式如下:
那么L2正则和L1正则有什么优缺点呢?
- L2正则比较容易优化,因为它的导数就是
,而L1的导数在0出不连续
- L2正则更偏向于需要小的权重值,L1正则更偏向于某些权重值更大,但是同时也更多的权重值为0,也就是说L1正则化的结果倾向于稀疏的权重矩阵。
L1和L2正则都有贝叶斯解释。L1正则可以解释为权重的Laplace先验概率,L2正则对应这样一个假设:权重的分布是一个均值为0()的正态分布。
权重的高斯分布如下:
根据Bayes法则,我们的权重可以用以下公式估算:
使用上面的高斯分布计算先验概率,可以得到:
我们让,
,取对数,则有:
Multinomial logistic regression
上面我们讨论的都是二分类问题,如果我们想要多分类呢?这个时候就需要Multinomial logistic regression了,这种多分类也叫作softmax regression或者maxent classifier。
多分类的类别集合就是不两种了,所以我们更换一个给输出结果计算概率的函数,用来替代sigmoid,那就是sigmoid的泛华版本softmax。
其中,。
所以,对于输入
我们有:
显然,softmax函数的分母是一个累加,因此softmax对于每一个输入,都输出一个概率值,并且所有输入的概率值和为1!
和sigmoid类似,把带入:
注意的是,我们的和
都是对应此时的分类的,所以写成
和
。
同样的,我们的损失函数也变成了泛化版本:
其中,1{y=k}表示时值为1,否则为0。
因此,可以得到下面的导数(没有推导过程):
思考题
- logistic regression和神经网络是不是很相似呢?你能说出它们的异同吗?
联系我
- WeChat: luozhouyang0528
- Email: stupidme.me.lzy@gmail.com
- 公众号: stupidmedotme
