

前言
- unix提供的IO模型有几种,分别有哪些?
- 各种IO模型的特点是什么?他们有什么区别?
- 阻塞,非阻塞,同步,异步的区别?
- epoll为什么高效?
概述
普通输入操作包含的步骤
- 等待数据准备好
- 从内核向进程复制数据
网络数据输入包含的步骤
- 等待数据从网络送达,到达后被复制到内核缓冲区
- 把数据从内核缓冲区复制到应用程序缓冲区
IO模型介绍
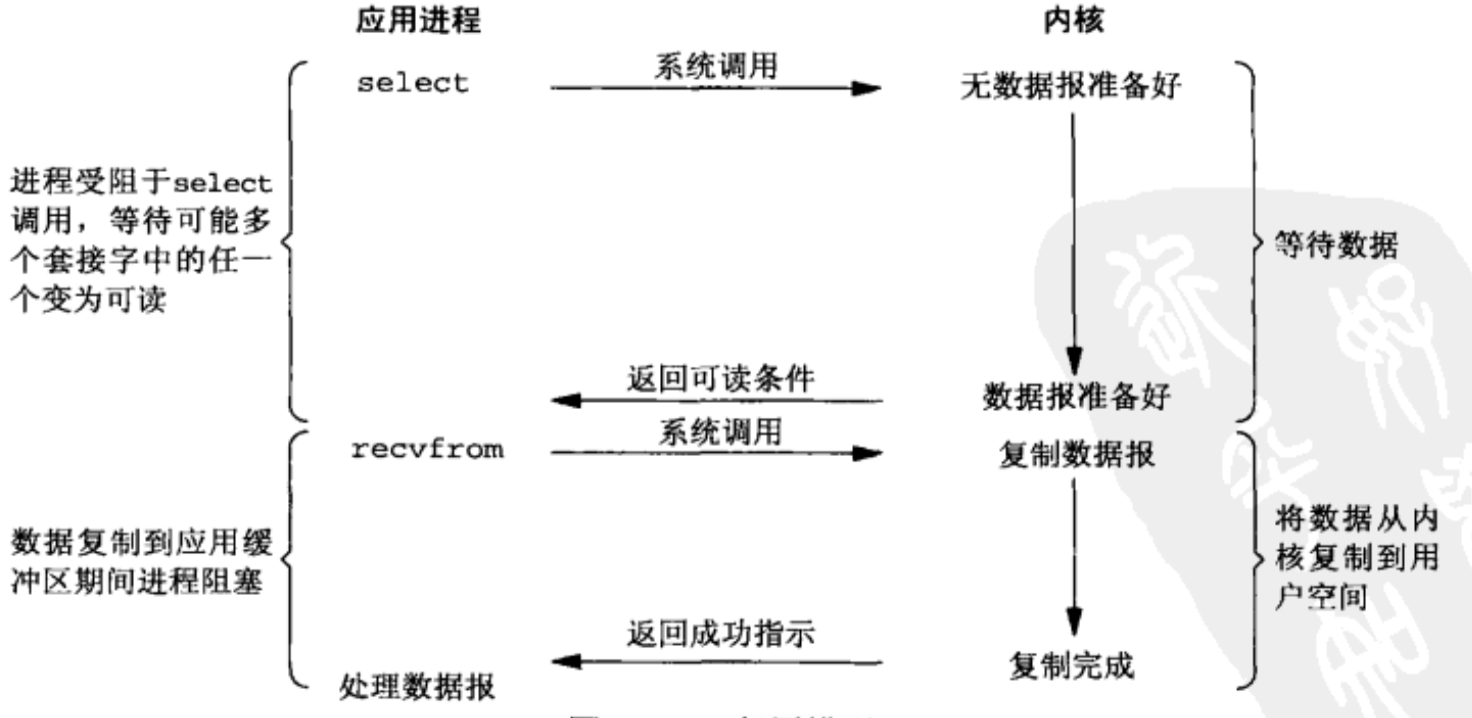
阻塞式IO
- 使用系统调用,并一直阻塞直到内核将数据准备好,之后再由内核缓冲区复制到用户态,在等待内核准备的这段时间什么也干不了
- 下图函数调用期间,一直被阻塞,直到数据准备好且从内核复制到用户程序才返回,这种IO模型为阻塞式IO
- 阻塞式IO式最流行的IO模型
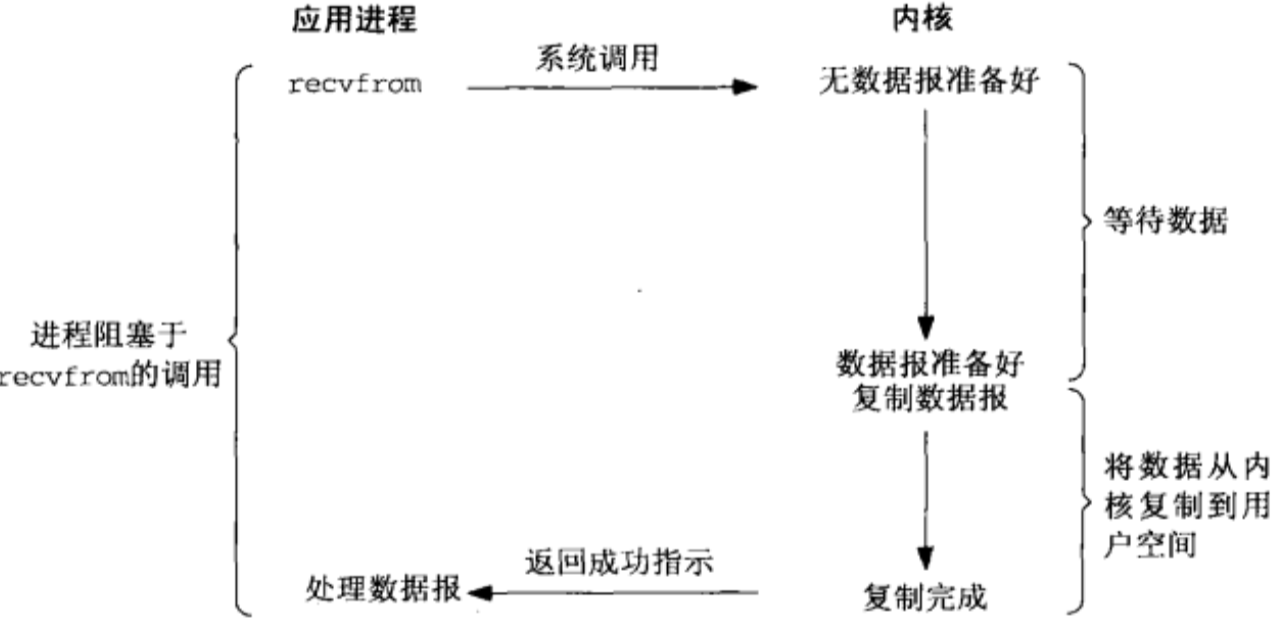
非阻塞式IO
- 内核在没有准备好数据的时候会返回错误码,而调用程序不会休眠,而是不断轮询询问内核数据是否准备好
- 下图函数调用时,如果数据没有准备好,不像阻塞式IO那样一直被阻塞,而是返回一个错误码。数据准备好时,函数成功返回。
- 应用程序对这样一个非阻塞描述符循环调用成为轮询。
- 非阻塞式IO的轮询会耗费大量cpu,通常在专门提供某一功能的系统中才会使用。通过为套接字的描述符属性设置非阻塞式,可使用该功能
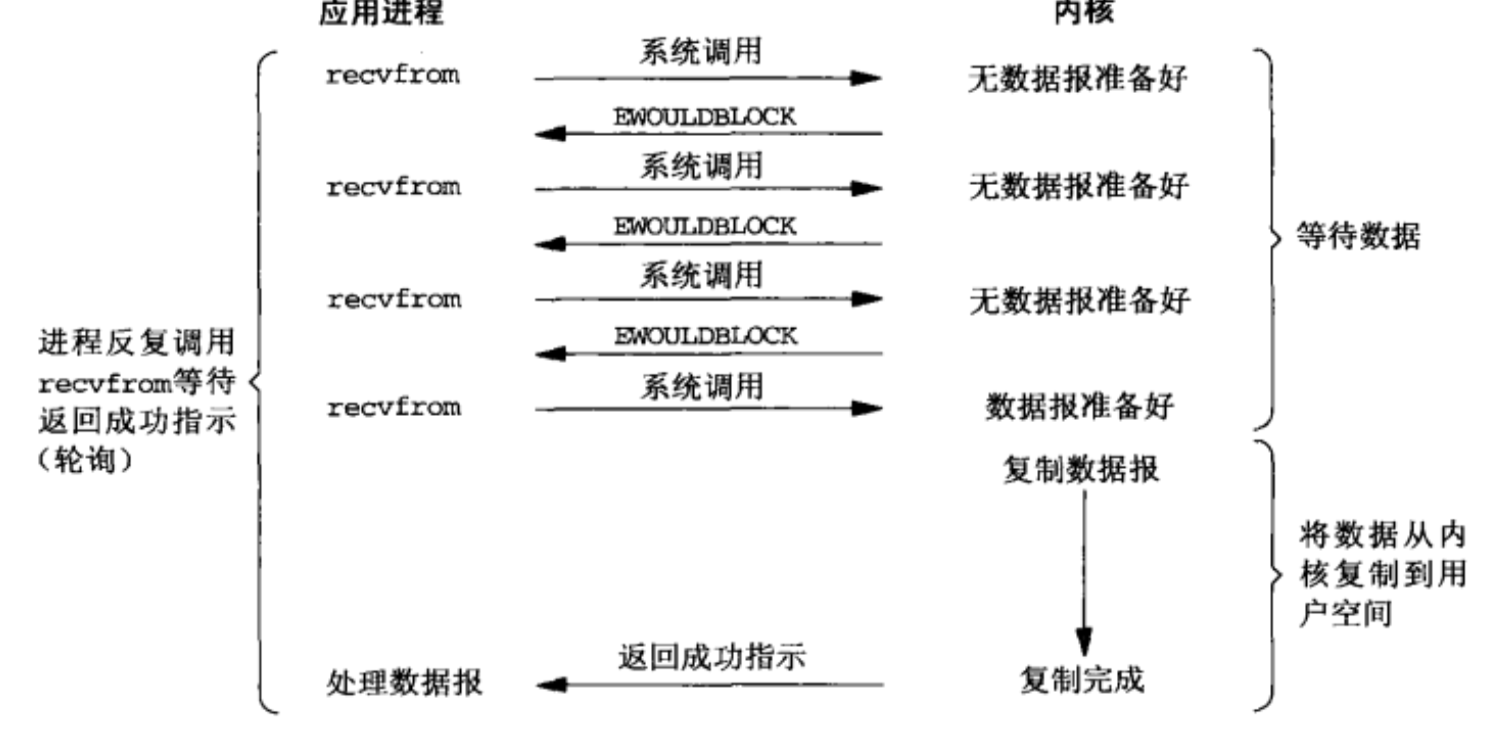
IO多路复用
- 类似与非阻塞,只不过轮询不是由用户线程去执行,而是由内核去轮询,内核监听程序监听到数据准备好后,调用内核函数复制数据到用户态
- 下图中select这个系统调用,充当代理类的角色,不断轮询注册到它这里的所有需要IO的文件描述符,有结果时,把结果告诉被代理的recvfrom函数,它本尊再亲自出马去拿数据
- IO多路复用至少有两次系统调用,如果只有一个代理对象,性能上是不如前面的IO模型的,但是由于它可以同时监听很多套接字,所以性能比前两者高
- 多路复用包括:
- select:线性扫描所有监听的文件描述符,不管他们是不是活跃的。有最大数量限制(32位系统1024,64位系统2048)
- poll:同select,不过数据结构不同,需要分配一个pollfd结构数组,维护在内核中。它没有大小限制,不过需要很多复制操作
- epoll:用于代替poll和select,没有大小限制。使用一个文件描述符管理多个文件描述符,使用红黑树存储。同时用事件驱动代替了轮询。epoll_ctl中注册的文件描述符在事件触发的时候会通过回调机制激活该文件描述符。epoll_wait便会收到通知。最后,epoll还采用了mmap虚拟内存映射技术减少用户态和内核态数据传输的开销
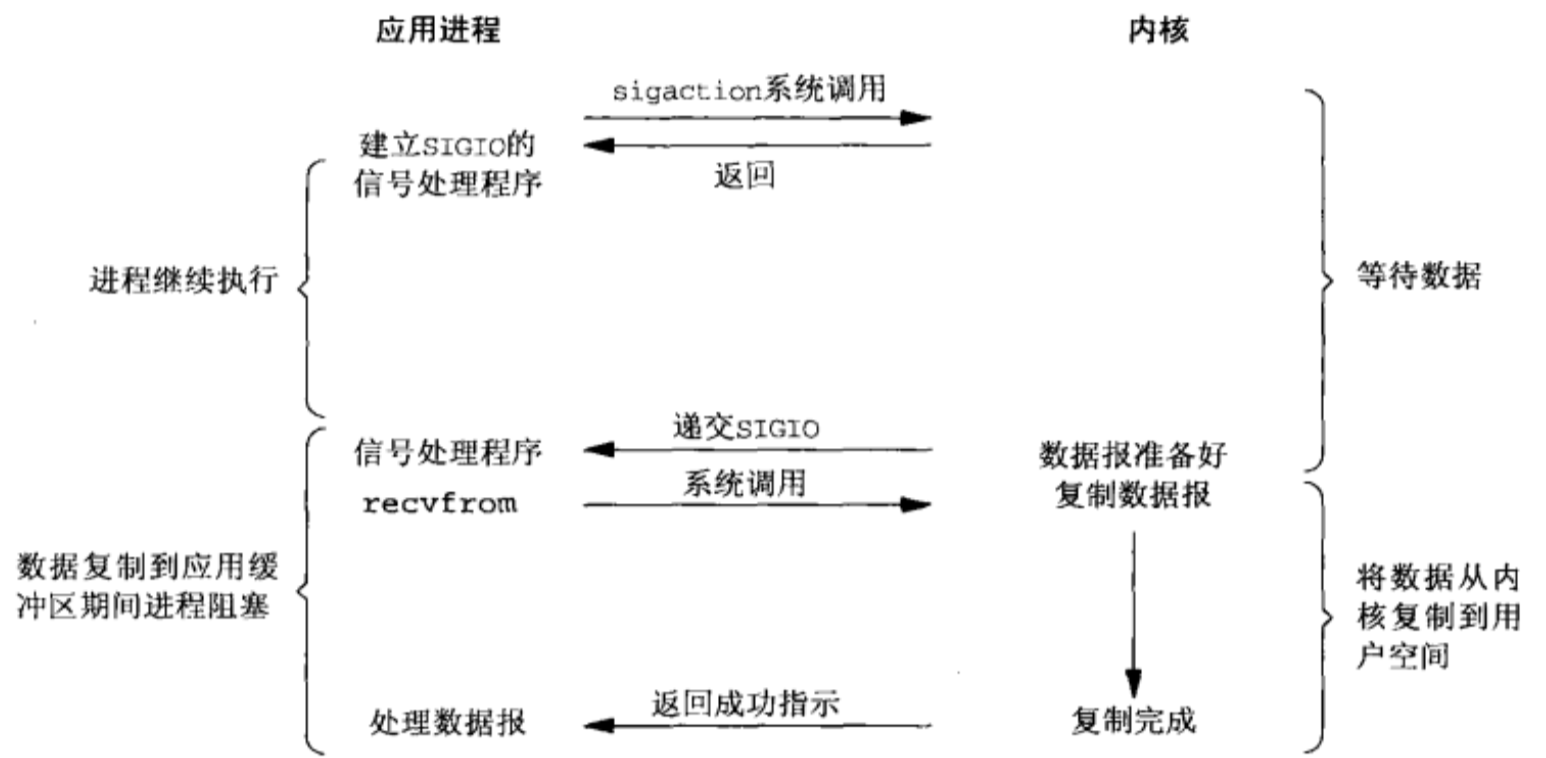
信号驱动式IO
- 使用信号,内核在数据准备就绪时通过信号来进行通知
- 首先开启信号驱动io套接字,并使用sigaction系统调用来安装信号处理程序,内核直接返回,不会阻塞用户态
- 数据准备好时,内核会发送SIGIO信号,收到信号后开始进行io操作
异步IO
- 异步IO依赖信号处理程序来进行通知
- 不过异步IO与前面IO模型不同的是:前面的都是数据准备阶段的阻塞与非阻塞,异步IO模型通知的是IO操作已经完成,而不是数据准备完成
- 异步IO才是真正的非阻塞,主进程只负责做自己的事情,等IO操作完成(数据成功从内核缓存区复制到应用程序缓冲区)时通过回调函数对数据进行处理
- unix中异步io函数以aio_或lio_打头
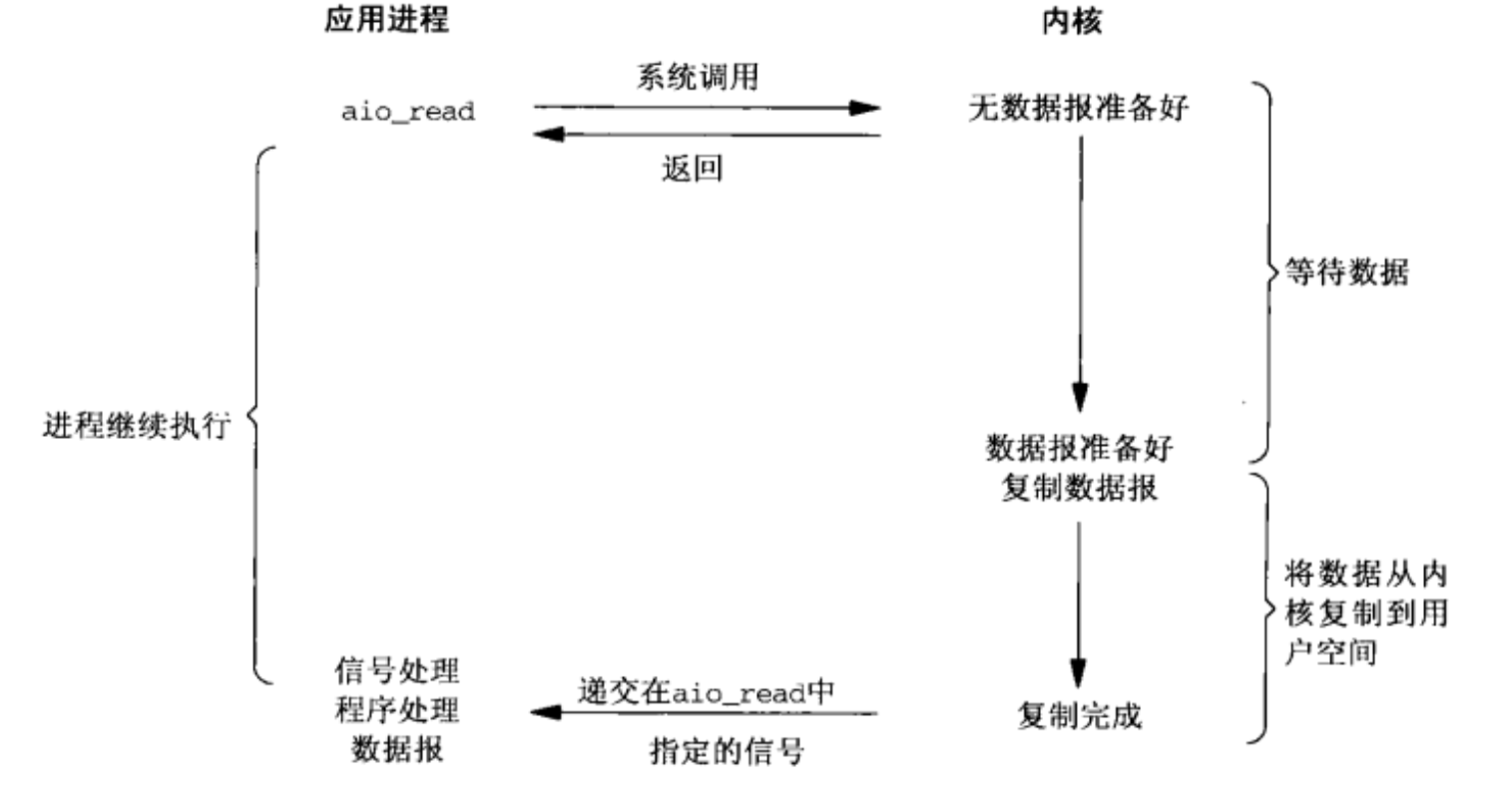
各种IO模型对比
- 前面四种IO模型的主要区别在第一阶段,他们第二阶段是一样的:数据从内核缓冲区复制到调用者缓冲区期间都被阻塞住!
- 前面四种IO都是同步IO:IO操作导致请求进程阻塞,直到IO操作完成
- 异步IO:IO操作不导致请求进程阻塞

参考
《unix网络编程》第一卷
