

一、引言
物流订单能力作为基础能力,需要设计一套稳定的订单模型,以及一套能够在高并发环境下持续可用的接口。这些接口作为原子接口,供上层业务复用。上层业务无论多么复杂,通过这些原子接口,最终都会收敛到稳定的订单模型中来,这也是区分基础能力和产品服务的一个重要的边界。
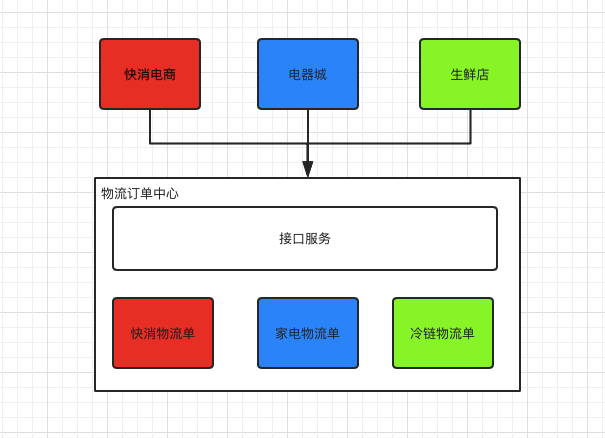
本文通过以下5点来介绍如何构建一套物流订单能力:
1、模型设计
2、状态机设计
3、高并发创建接口
4、高并发更新接口
5、高并发查询接口
二、物流订单数据模型设计
首先来看ER模型

一共四张表,主模型是logistics_order、logistics_order_package和logistics_order_item表,logistics_order_unique是去重表。
1、logistics_order
描述:物流订单主单表,整张表大概分为以下几部分信息
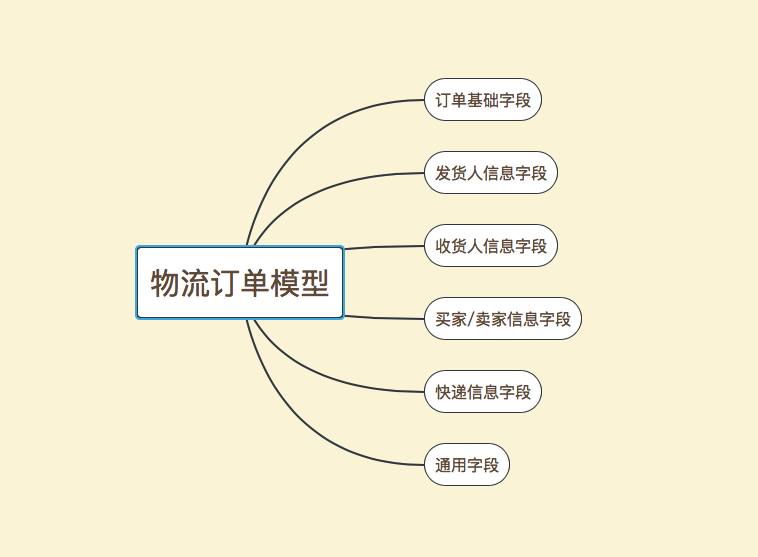
表结构设计
字段名称 | 字段类型 | 是否必填 | 描述 |
id | bigint | 必填 | 主键 |
lg_order_code | varchar(128) | 必填 | 物流单号 |
trade_order_code | varchar(128) | 非必填 | 交易单号 |
receiver_id | bigint | 非必填 | 收货人ID |
receiver_name | varchar(64) | 非必填 | 收货人姓名 |
receiver_telephone | varchar(32) | 非必填 | 收货人电话 |
receiver_province | varchar(32) | 非必填 | 收货人省份 |
receiver_city | varchar(64) | 非必填 | 收货人城市 |
receiver_area | varchar(64) | 非必填 | 收货人地区 |
receiver_street | varchar(64) | 非必填 | 收货人街道 |
receiver_address | varchar(1024) | 非必填 | 收货人详细地址 |
receiver_address_code | varchar(32) | 非必填 | 四级地址编码 |
sender_id | bigint | 非必填 | 发货人ID |
sender_name | varchar(64) | 非必填 | 发货人姓名 |
sender_telephone | varchar(32) | 非必填 | 发货人电话 |
sender_province | varchar(32) | 非必填 | 发货人省份 |
sender_city | varchar(64) | 非必填 | 发货人城市 |
sender_area | varchar(64) | 非必填 | 发货人地区 |
sender_street | varchar(64) | 非必填 | 发货人街道 |
sender_address | varchar(1024) | 非必填 | 发货人详细地址 |
sender_address_code | varchar(32) | 非必填 | 四级地址编码 |
buyer_id | bigint | 必填 | 买家ID |
buyer_name | varchar(64) | 非必填 | 买家昵称 |
seller_id | bigint | 非必填 | 卖家ID |
seller_name | varchar(64) | 非必填 | 卖家昵称 |
parent_lg_order_code | varchar(128) | 非必填 | 父物流单号 |
biz_type | varchar(32) | 必填 | 业务类型 |
order_origin | int | 非必填 | 订单来源 |
order_type | int | 必填 | 订单类型 |
status | int | 必填 | 状态 |
mailno | varchar(256) | 非必填 | 运单号 |
express_code | varchar(32) | 非必填 | 快递公司编码 |
express_name | varchar(32) | 非必填 | 快递公司名称 |
is_delete | int | 必填 | 是否删除 |
feature | varchar(1024) | 非必填 | 扩展字段,JSON格式 |
version | int | 非必填 | 版本号,用于乐观锁 |
gmt_created | datetime | 必填 | 创建时间 |
gmt_modified | datetime | 必填 | 编辑时间 |
索引设计:
a)、主键id
b)、普通索引字段:lg_order_code、buyer_id
2、logistics_order_item
描述:物流子单表,主要存储要发货的商品信息,整张表大概分为以下几部分信息
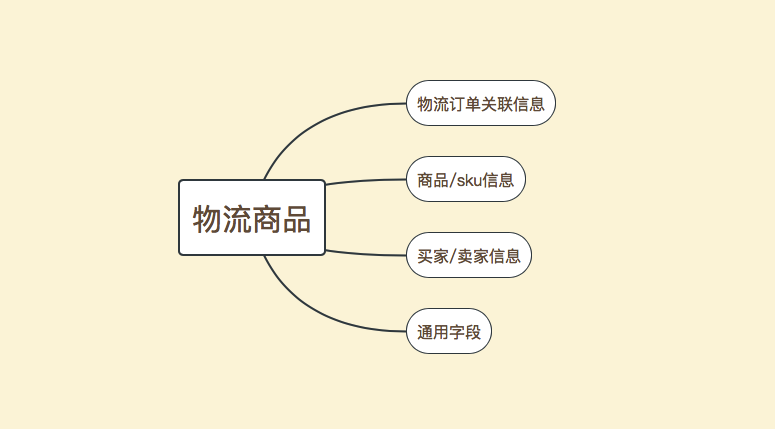
表设计
字段名称 | 字段类型 | 是否必填 | 描述 |
id | bigint | 必填 | 主键 |
lg_order_code | varchar(128) | 必填 | 物流单号 |
trade_order_code | varchar(128) | 非必填 | 交易单号 |
trade_sub_order_code | varchar(128) | 非必填 | 交易子单号 |
package_id | bigint | 非必填 | 包裹ID |
sku_id | bigint | 非必填 | skuid |
sku_name | varchar(256) | 非必填 | sku名称 |
buyer_id | bigint | 必填 | 买家ID |
seller_id | bigint | 非必填 | 卖家ID |
shop_id | bigint | 非必填 | 店铺ID |
item_id | bigint | 必填 | 商品ID |
item_type | int | 非必填 | 商品类型 |
item_name | varchar(256) | 非必填 | 商品名称 |
item_num | int | 必填 | 商品数量 |
item_weight | decimal | 非必填 | 商品重量 |
item_volumn | decimal | 非必填 | 商品体积 |
marking | varchar(128) | 非必填 | 商品标签信息 |
status | int | 必填 | 状态 |
feature | varchar(1024) | 非必填 | 扩展字段 |
is_delete | int | 必填 | 是否删除 |
version | int | 必填 | 版本号 |
gmt_created | datetime | 必填 | 创建时间 |
gmt_modified | datetime | 必填 | 修改时间 |
索引设计:
a)、主键id
b)、普通索引字段:lg_order_code、buyer_id
3、logistics_order_pacakge
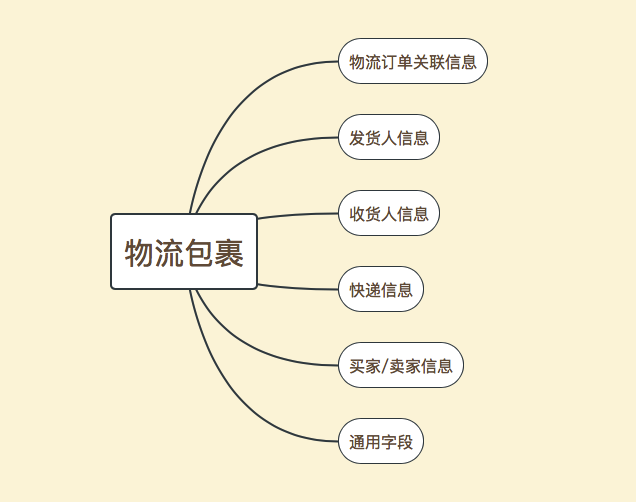
描述:物流包裹,是对物流商品的包装。这张表主要是为了拆单场景使用。拆单场景有很多种,比如同一个订单下的不同商品发往不同地址,大家电商品拆分发货,商品分仓发货等等。总之,每一个包裹都对应一个运单号,都有对应的发货地和收货地以及物流详情。
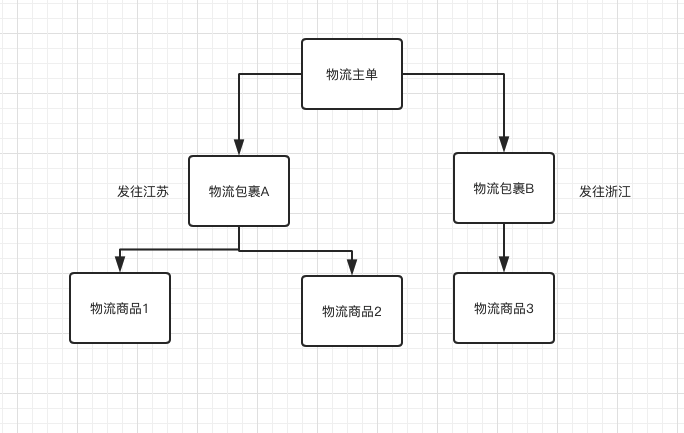
表设计
字段名称 | 字段类型 | 是否必填 | 描述 |
id | bigint | 必填 | 主键 |
lg_order_code | varchar(128) | 必填 | 物流单号 |
trade_order_code | varchar(128) | 非必填 | 交易单号 |
receiver_id | bigint | 非必填 | 收货人ID |
receiver_name | varchar(64) | 非必填 | 收货人姓名 |
receiver_telephone | varchar(32) | 非必填 | 收货人电话 |
receiver_province | varchar(32) | 非必填 | 收货人省份 |
receiver_city | varchar(64) | 非必填 | 收货人城市 |
receiver_area | varchar(64) | 非必填 | 收货人地区 |
receiver_street | varchar(64) | 非必填 | 收货人街道 |
receiver_address | varchar(1024) | 非必填 | 收货人详细地址 |
receiver_address_code | varchar(32) | 非必填 | 四级地址编码 |
sender_id | bigint | 非必填 | 发货人ID |
sender_name | varchar(64) | 非必填 | 发货人姓名 |
sender_telephone | varchar(32) | 非必填 | 发货人电话 |
sender_province | varchar(32) | 非必填 | 发货人省份 |
sender_city | varchar(64) | 非必填 | 发货人城市 |
sender_area | varchar(64) | 非必填 | 发货人地区 |
sender_street | varchar(64) | 非必填 | 发货人街道 |
sender_address | varchar(1024) | 非必填 | 发货人详细地址 |
sender_address_code | varchar(32) | 非必填 | 四级地址编码 |
buyer_id | bigint | 必填 | 买家ID |
seller_id | bigint | 非必填 | 卖家ID |
shop_id | bigint | 非必填 | 店铺ID |
mailno | varchar(256) | 非必填 | 运单号 |
express_code | varchar(32) | 非必填 | 快递公司编码 |
express_name | varchar(32) | 非必填 | 快递公司名称 |
pacakge_type | int | 必填 | 包裹类型 |
status | int | 必填 | 状态 |
feature | varchar(1024) | 非必填 | 扩展字段 |
is_delete | int | 必填 | 是否删除 |
version | int | 必填 | 版本号 |
gmt_created | datetime | 必填 | 创建时间 |
gmt_modified | datetime | 必填 | 修改时间 |
索引设计:
a)、主键id
b)、普通索引字段:lg_order_code、buyer_id
4、logistics_order_unique
描述:物流去重表,用于创建的时候去重,具体作用会在第四节介绍。
字段名称 | 字段类型 | 是否必填 | 描述 |
id | bigint | 必填 | 主键 |
unique_code | varchar(196) | 必填 | 去重单号 |
trade_code | varchar(128) | 必填 | 业务单号 |
biz_type | varchar(32) | 必填 | 业务类型 |
lg_order_id | bigint | 必填 | 物流单主键ID |
buyer_id | bigint | 必填 | 买家ID |
gmt_created | datetime | 必填 | 创建时间 |
gmt_modified | datetime | 必填 | 修改时间 |
索引设计
主键:id
唯一索引:unique_code
三、状态机的设计
1、正向物流状态机设计
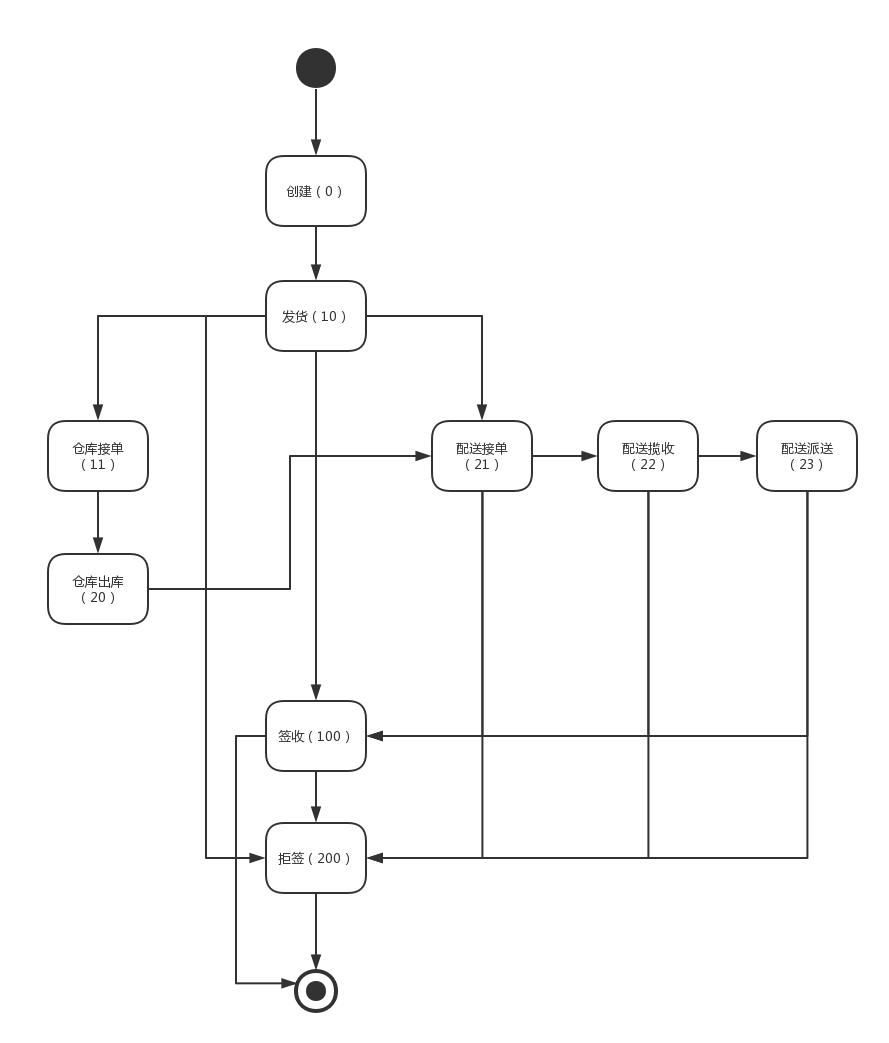
正向物流包含了三条主要流程:
a、创建->发货->签收/拒签
这种是最简单的流程,也是用户最关心的流程,如果公司使用的是第三方物流系统,那么只要这条状态流就足够了。
b、创建->发货->配送接单->配送揽收->配送派送->签收/拒签
这条状态流对接了配送的物流流转状态,一般对接第三方物流详情后,会得到物流配送的信息。
c、创建->发货->仓库接单->仓库出库->配送揽收->配送派送->签收/拒签
这条状态流是最复杂的,包含了仓库和配送,一般只有大公司才会考虑这么细致的状态流转。
2、逆向物流状态机设计
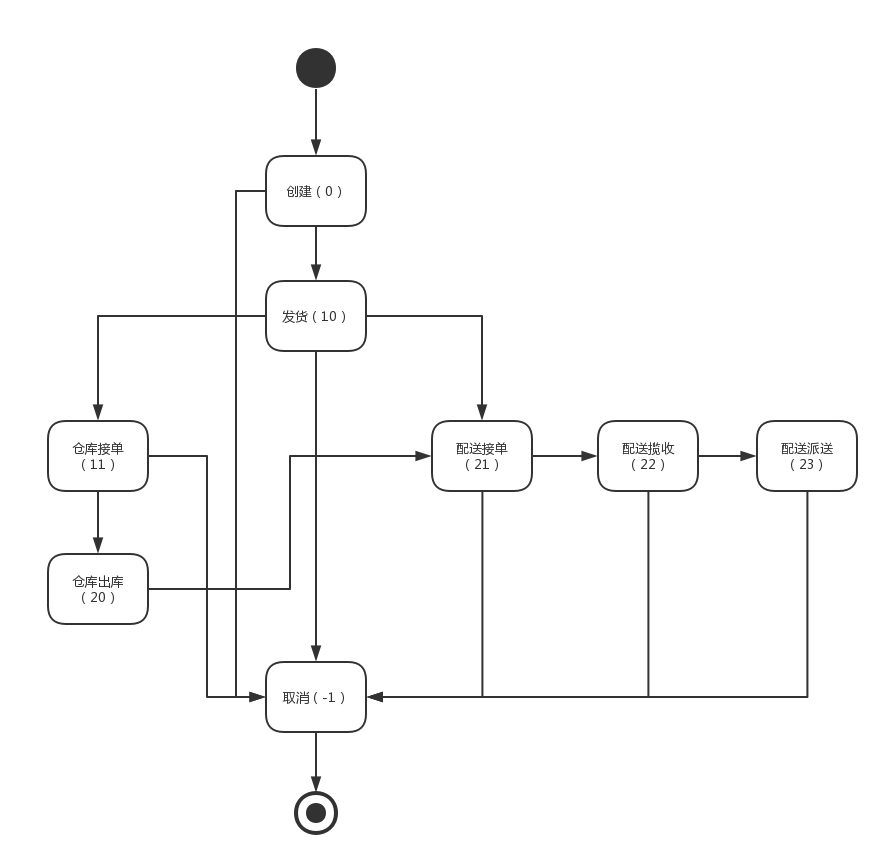
由上面的状态机可以看出来,取消物流的时机有4种:
1、创建后取消
2、发货后取消
3、仓库接单后出库前取消
4、配送接单后签收前取消
上面第三种和第四种状况也叫仓截单和配截单,需要配合WMS系统和TMS系统进行特别开发。
四、高并发下的订单创建接口设计
在整个交易物流业务流程中,物流订单的创建是衔接交易和物流的关键环节。从系统架构上来说,首先交易和物流必须通过消息解耦,这样可以对交易中心的高流量进行削峰,减少物流订单中心的压力,其次,物流订单中心必须提供高并发下稳定的创建接口,而且需要支持幂等。
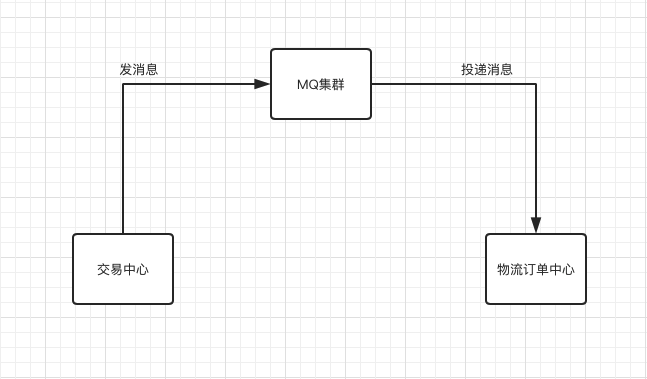
为此,我们设计了如下的高并发创建流程:
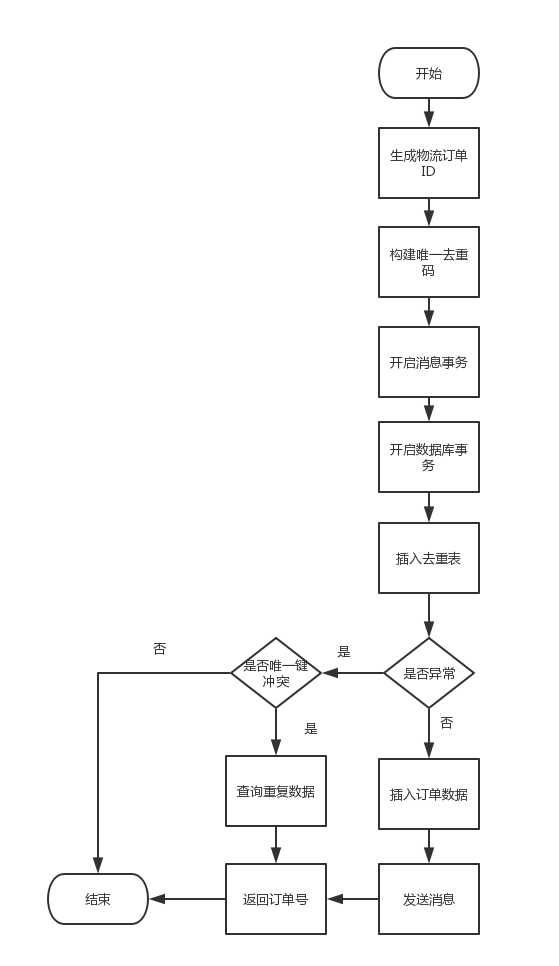
1、生成物流订单ID
这个ID必须提前生成,不能使用数据库自增ID,原因一个是后面订单中心数据库不可避免的会进行分库分表,提前通过全局生成可以规避后面迁移数据的风险,第二是提前生成ID可以将ID存入去重表,这样高并发下,多余的创建请求可以直接从去重表拿到订单ID,而不需要走后面的流程。
2、构建唯一去重码
唯一去重码必须唯一识别一次请求,我们通过业务单号+业务类型作为去重码,并构建唯一索引,保证高并发下不会重复创建。
3、开启消息事务
由于创建订单流量非常大,所以除了必要的插入数据操作,其他业务操作必须通过消息异步化。为了保证消息一定能够发出去,我们会使用MQ的消息事务保证。消息事务的原理可以参考这篇文章:www.codeceo.com/article/dis…
4、开启数据库事务
数据库事务就不用说了,可以使用spring的事务模板。
5、插入去重表
这里通过唯一去重码的唯一索引保证创建的唯一性,如果插入失败并且是数据库唯一索引异常,则通过唯一去重码去查去重表的数据,把里面的物流订单ID拿出来直接返回,如果是其他异常,则直接抛异常回滚事务,否则插入去重表。
6、插入订单数据
基本的数据库操作,这一步如果出错,会回滚整个事务。
7、发送消息
通过mq发送订单创建消息,这一步出错,按照上面的文章中的介绍,MQ会主动回调系统,验证是否是数据库插入成功消息没发,如果是则会把该条消息设置为已提交,从而保证消息发送成功。
通过上面的流程,我们可以保证物流订单的高并发幂等创建。
五、高并发下的订单更新接口设计
物流订单中心承载了整个物流域的状态流转,对于物流订单中心的更新也会比较多。平均来说,一笔物流订单在整个生命周期中,会有10到20次更新,当物流订单非常多的时候,更新的量是非常可观的,因此,我们需要设计出一套高并发的更新接口。
1、使用版本锁保证数据不被覆盖
我们在设计数据库表的时候,往往会加上version字段,这个字段就是用来做版本锁的,版本锁的流程如下:
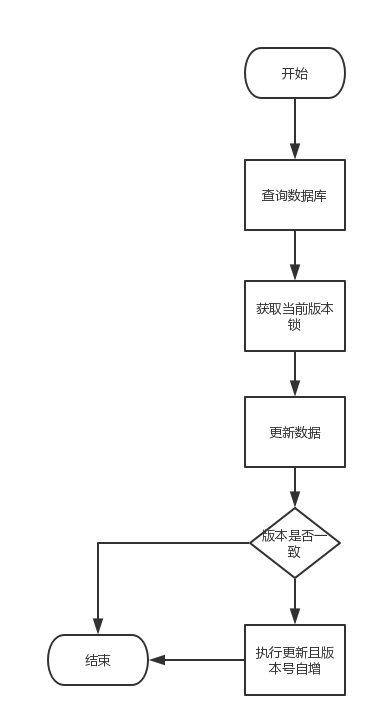
2、锁分离
对于更新来说,有些字段会频繁更新,比如状态,有些字段则较少更新。对于频繁更新的字段,如果使用版本锁,就会导致大量版本冲突,从而会影响其他字段的更新。因此,我们可以对状态更新单独设计一个status_version字段,更新状态只会使用这个字段,即使状态更新冲突,也不影响其他字段的更新,从而提高更新效率。
为了使锁分离,我们需要在接口层面设计两套接口,一套是通用的更新接口,用于全量更新字段,一套是类似状态这样的特殊字段的更新接口。
3、数据比对
在实践中,我们发现更新接口被误用的情况,比如数据完全一致,也进行更新接口的调用,这些调用到数据库层面仅仅是改了下gmt_modified字段,没有任何其他作用。对于这些误调用,我们通过更新字段的比对,将它们挡掉,这样就减少了一部分数据库的压力。
六、高并发下的订单查询接口设计
物流订单中心作为物流领域的核心,其他业务系统几乎全部会依赖到物流订单,物流订单的查询接口调用量往往会非常大,物流订单可以说是整个业务的单点,一旦物流订单中心挂了,影响会非常大。因此,我们必须设计高并发下的订单查询接口。
1、数据库层面优化
首先是数据库层面的优化,具体可以参考这篇文章:www.jianshu.com/p/cd033668f…
2、分库分表
物流订单库不可避免的会涉及到分库分表,在进行分库分表的时候需要注意三点:
a、物流订单ID全局生成
物流订单ID全局生成可以参考雪花算法或者阿里TDDL的方法
b、选择合适的分表字段
分表字段是用来做路由的,因此必须选择一定会有的字段,比如买家ID。
c、sql语句尽量不要跨表
一旦分库分表,对于一些复杂的sql查询必须进行拆分,否则会影响性能。如果无法拆分,则需要迁移到搜索引擎中。
3、数据分离
物流订单数据一般会分成热点数据和冷数据,热点数据是最近生成的订单,这些订单还处于业务流转中,冷数据是那些历史数据,一般查询量非常小。我们可以按照一定规则,把历史数据迁移到Hbase保存,数据库只留下热点数据,从而减少数据库的数据量。对于历史数据,我们需要提供历史数据的查询接口。
4、查询接口优化
我们在设计查询接口的时候,设计一个LogisticsOrderQuery对象,其中包含查询条件,以及一些开关:

isIncludePackage:这个开关告诉接口是否把包裹信息查出来
isIncludeItems:这个开关告诉接口是否把物流商品查出来
通过这些开关,可以减少数据的查询量,减轻数据库压力。
5、集群读写分离
当上面的策略都无法增加并发量的时候,我们还剩最后一招,那就是加机器。但是,加机器也不是随便加的,为了更科学的利用自有,我们把集群分为读集群和写集群,通过dubbo的接口路由规则,把读流量分配到读集群,写流量分配到写集群,我们根据读写请求的峰值进行集群的容量规划,动态扩容。
七、总结
通过上面的介绍,我们基本介绍完了一个物流订单系统涉及到的技术要点,我们可以看出来,对于基础能力相关的系统,往往对技术要求比较高,它们聚焦的是高并发下稳定、可靠的系统表现,而不是业务需求,这也是为什么中台思想中要把系统分为基础能力系统和业务产品系统。接下来的一系列文章,我会逐一介绍其他基础能力系统,以及产品服务系统的设计要点,最后会把这两种系统串起来,再次讲一下基于中台思想的系统设计。
更多文章欢迎访问 http://www.apexyun.com/
联系邮箱:public@space-explore.com
(未经同意,请勿转载)
