

在 《【Get】用深度学习识别手写数字》 中,我们通过一个手写数字识别的例子,体验了如何使用 深度学习 + tensorflow 解决一个具体的问题。
实际上,这是一个分类问题,即将输入的图片数据分成 0-9 共 10 个类别,而且我们的数据都是直接使用 MNIST 上下载的处理好的数据。
在现实生产中,我们的数据源通常来自于数据库,是没有经过预处理的,那么我们该做些什么来让这些数据库里的数据能够用于进行机器学习呢?
机器学习的前置步骤,数据预处理就是解决这个问题的。
本篇 CoorChice 将会通过一个回归预测问题,来展示如何进行这个过程。
原始数据
我们用于机器学习的数据的量不能太少,否则训练效果会极差。但是我们个人如何才能获取到大量的数据来进行训练呢?
CoorChice 推荐 kaggle:https://www.kaggle.com/datasets,这是全球最大的数据科学社区和数据竞赛平台。在这个美妙的地方,我们可以轻松的找到各种各样的,海量的,精彩绝伦的数据。
打开链接就可以看到海量的数据,我们很随意的选择其中一个数据源来进行训练。
就选第一条吧!
第一条数据是关于一个面包店的交易的数据。点击进入后,找到下载就可以下载这套数据了。
也许你可能不能立刻下载,因为他会要求你先登录。那就成为 Kaggle 的会员吧。
我们使用表格打开刚刚下载的数据观察观察。
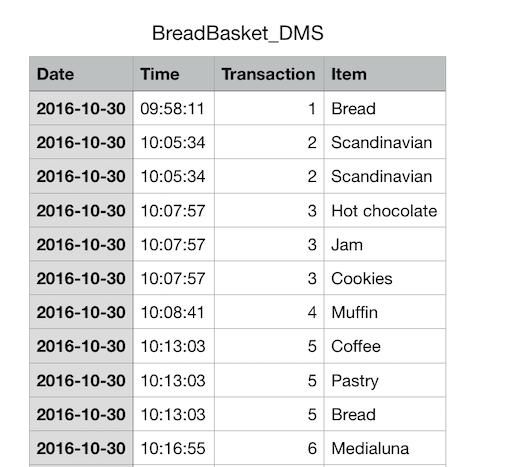
My God! 这是一堆简陋不堪的数据,共有 21293 条数据,每条只有 4 个特征! 4 个特征! 4 个特征!
没关系,我们只是学习如何处理数据的过程,所以就凑合着用一下吧。
开始数据处理
实际上,通常我们的数据呆在数据库中,就是这种表格的形式。
在开始之前,需要先安装一下 Pandas 这个 Python 库,它被用来读取我们的表格数据,和进行增、删、改、查等操作。
下好了,我们就开始吧...
观察数据
进行数据处理最重要的一步,就是对数据进行观察和分析。通过观察和分析,我们要除去一些无关紧要的数据列,比如在预测天气预报的时候,我们就应该把 ‘李雷早上吃了什么’ 这个数据列去掉,因为对模型训练毫无帮助。
同时,我们要从数据中挖掘出一些隐藏的信息,以扩充特征。日入在预测产品的交易信息时,我们从日期这个数据列,就能知道当天是否是一个节日,是什么节日。
在我们下载的这堆面包店的交易数据中,仅有惨不忍睹的 4 个类目!
通常,当我们使用机器学习来解决问题时,都会有一个目的。比如,在这堆数据中,CoorChice 希望通过机器学习训练一个模型,能够用于预测未来一定条件下的某种类型的面包所能达到的交易量是多少。
因此,我们将交易量 Transaction 这一列数据作为数据集的标签数据。
接下来剩下的只有 日期、时间、面包类目 这三个特征了。
从数据中挖掘更多的信息
仅有这三个特征来进行训练,结果可想而知会有多差。比你想的差还要差,所以我们需要从现有的数据中挖掘出更多的信息来。比如,在图片数据中,通常会进行一些旋转、平移之类的操作,来补充数据量。
日期 Date
首先看看日期能挖掘到什么有用的信息?
当然是星期啦。今天是星期一、星期二、...、对交易肯定是有影响的。我们通过 Date 可以计算出当前日期是周几。
还有什么可挖掘的吗?嗯,左思右想...咦,节日肯定也是影响面包交易量的一个重要因素,有了 Date 我们也能知道当前日期是什么节日。
然后,通过观察可以发现,随着日期的增加,交易量也是在累加的,所以日期的大小也可直接作为一个特征。
由于 CoorChice 要尝试预测的是未来某个时间、某种面包所能达到的交易量,所以日期的大小对结果必然是有影响的。但我们不能直接将日期转换为一个形如
20161030这样的数字,因为一年只有 12 个月,每一个月天数不一样的,所以这个数值跳跃度比较大,这样就大大增加了训练的难度和准确率。我们需要的是一个统一标准的数值。如果确定某一天为基准,然后把日期转换为和这一天的距离,那量化标准自然就是很明了的了。因为数据是从2016-10-30开始,那么把这天作为基准日就再合适不过了。
时间 Time
接下来观察 Time 有什么可用的没。
Time 本身是一些比较密集的数据,间隔不大。我们可以把它划归到小时里,因此就会有 24 个小时。比如,“10:13:03” 就让它属于 10 点这个小时吧。
通过时间,我们还可以知道现在是处于
早晨、上午、中午、下午、傍晚、晚上、深夜中的那个时间段。不同的时间段或多或少也会影响交易量。
确定好了思路,接下来就开始找着这个思路处理数据了。
处理原始数据
处理数据的第一步当然是先读取数据啦,我们前面下载的 Pandas 就使用来干这个的。
读取数据
# 读取数据
datas = pd.read_csv('data/BreadBasket_DMS.csv')
读取数据后,输出一下看看长什么样子。
print(datas.head())
->>
Date Time Transaction Item
0 2016-10-30 09:58:11 1 Bread
1 2016-10-30 10:05:34 2 Scandinavian
2 2016-10-30 10:05:34 2 Scandinavian
3 2016-10-30 10:07:57 3 Hot chocolate
4 2016-10-30 10:07:57 3 Jam
[5 rows x 4 columns]
增强数据
然后,我们对原始数据按照上面分析的思路进行处理。
# 挖掘,周几对交易量的影响
datas['Weekday'] = datas['Date']
datas['Weekday'] = datas['Weekday'].map(lambda x: get_weekday(x))
# 挖掘,各个节日对交易量的影响
datas['Festival'] = datas['Date']
datas['Festival'] = datas['Festival'].map(lambda x: get_festival(x))
# 挖掘,当前所处的时间段对交易量的影响
datas['Time_Quantum'] = datas['Time']
datas['Time_Quantum'] = datas['Time_Quantum'].map(lambda x: get_time_quantum(x))
# 将 Date 一列变为与 2016-10-30 这天的距离
datas['Date'] = datas['Date'].map(lambda x: get_delta_days(x))
# 将时间转变为时段
datas['Time'] = datas['Time'].map(lambda x: get_time_range(x))
# 缩小数据大小
datas['Transaction'] = datas['Transaction'].map(lambda x: (float(x) / 1000.))
现在,再输出一下数据看看。
print(datas.head())
->>
Date Time Transaction ... Weekday Festival Time_Quantum
0 0.0 9 0.001 ... 6 null 上午
1 0.0 10 0.002 ... 6 null 上午
2 0.0 10 0.002 ... 6 null 上午
3 0.0 10 0.003 ... 6 null 上午
4 0.0 10 0.003 ... 6 null 上午
[5 rows x 7 columns]
从表格数据中可以看到,Date 和 Transaction 都变成浮点数了,因为把它们进行缩小,有利于后面的梯度下降,否则 loss 会非常非常的大。
现在,我们已经扩充了一些特征。
进行 One-Hot 编码
接下来,对于离散的数据,比如 Weekday、Time 这样的,它的大小并不会对交易产生影响,但这种离散的特征的类别取值是会对结果产生影响的。比如,春节这天会对食物的交易量产生影响。
我们需要对这样的特征数据进行 独热编码 。关于 独热编码 ,你可以在 CoorChice 的 《机器学习,看完就明白了》 这篇文章,了解相关信息。
ont_hot_data = pd.get_dummies(datas, prefix=['Time', 'Item', 'Weekday', 'Festival', 'Time_Quantum'])
看看现在数据表变成了什么样子了。
print(ont_hot_data.head())
->>
Date Transaction ... Time_Quantum_晚上 Time_Quantum_深夜
0 0.0 0.001 ... 0 0
1 0.0 0.002 ... 0 0
2 0.0 0.002 ... 0 0
3 0.0 0.003 ... 0 0
4 0.0 0.003 ... 0 0
[5 rows x 136 columns]
经过独热编码后,columns 已经扩充到了惊人的 136 列!
之所以需对数据进行独热编码,还有一个原因是在训练时,独热编码在分类是 0 和 1 的关系,而如果用 1,2,3,.. 的分类标签方式,是不利于梯度下降的,计算出的梯度往往比较大。
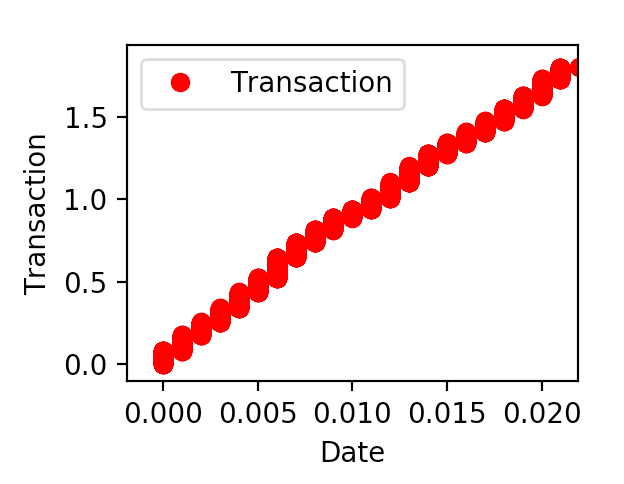
对 Date、Transaction,可以看到表格中,CoorChice 还对他们进行缩小,目的是为了把数值范围变小,这样有利于梯度下降的求解。
我们看看现在数据的分布情况:
打乱数据
接下来,我们需要将元素的有序的数据进行打乱,这样有助于提高训练出来的模型的泛化能力。
ont_hot_data = ont_hot_data.sample(frac=1, replace=False)
ont_hot_data = ont_hot_data.sample(frac=1, replace=False)
ont_hot_data = ont_hot_data.sample(frac=1, replace=False)
一遍不够,要打乱 3 遍!
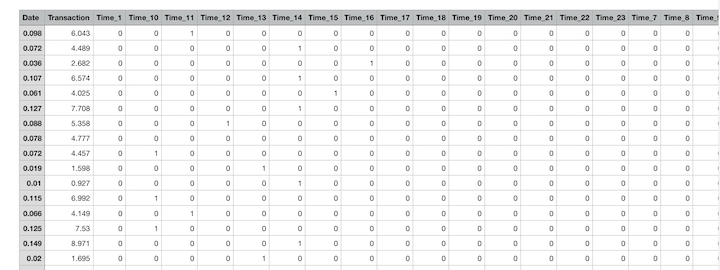
看 Date 一列,说明数据已经被打的足够乱了。
保存数据
最后,我们要把处理好的数据分为训练集和测试集,CoorChice 按大概 30% 取测试集数据,然后分别保存。
# 测试数据集大小
test_count = 6000
train_count = ont_hot_data.shape[0] - test_count
# 切割出训练数据集
train_data = ont_hot_data[:train_count]
# 切割出测试数据集
test_data = ont_hot_data[train_count:]
# 分别保存两个数据集
train_data.to_csv('data/train_data.csv', index=False, header=True)
test_data.to_csv('data/test_data.csv', index=False, header=True)
保存处理好的数据很简单,使用 Pandas 提供的 to_csv() 就可以把数据存 csv 格式。
index 和 header 分别表示是否保存行号和列名称。
现在,我们已经把原始数据处理好,并且分割成了训练集和测试集。我们有 15,293 条训练数据,和 6000 条测试数据。
开始训练吧!
在开始之前,建议先看一看这一篇 《【Get】用深度学习识别手写数字》 ,因为套路基本上是一样的,只是有的地方需要根据具体情况调整。
在手写数字识别中,我们构建的是一个简单 4 层网络,它由两个卷积层,一个全链接层和一个输出层组成。
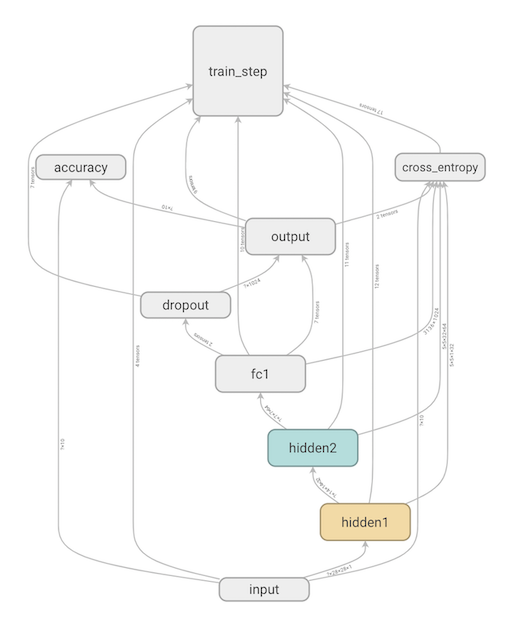
回顾一下这个网络结构。
发生了欠拟合!
一开始,CoorChice 直接使用了这个网络进行训练,经过 10w 次的漫长训练之后发现,准确率最高不过 0.1%。
起初 CoorChice 减小 lr(学习率),想着可能是学习率过大,导致震荡了。然而,毫无作用。
出现这种现象,基本可以判断大概率上是发生欠拟合了。
发生欠拟合,可以通过以下步骤一步步的排除问题和改进网络。
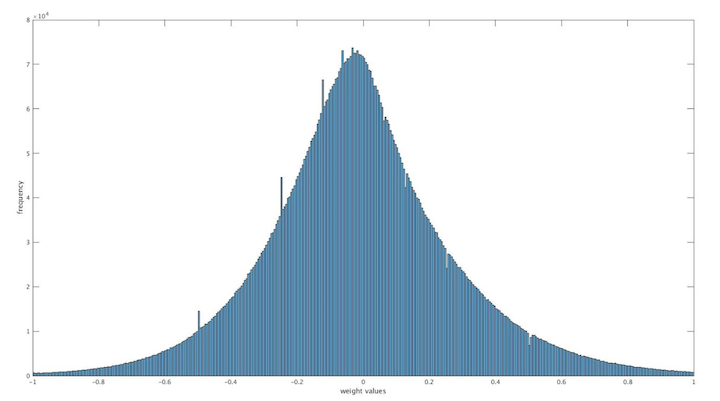
使用适合的权重初始化方案
本次训练中,权重的初始化沿用了上次的正太分布初始化方案,应该是比较优秀的方案了,所以就不做改动了。
选择适当的激活函数
在上一次的网络构建中,卷积层、全链接层都用的是 ReLu 激活函数,输出层使用的是 Softmax 激活函数。而这次 CoorChice 把激活函数全换成了优秀的 ReLu 激活函数,这应该也是没毛病的。
选择适合的优化器和学习率
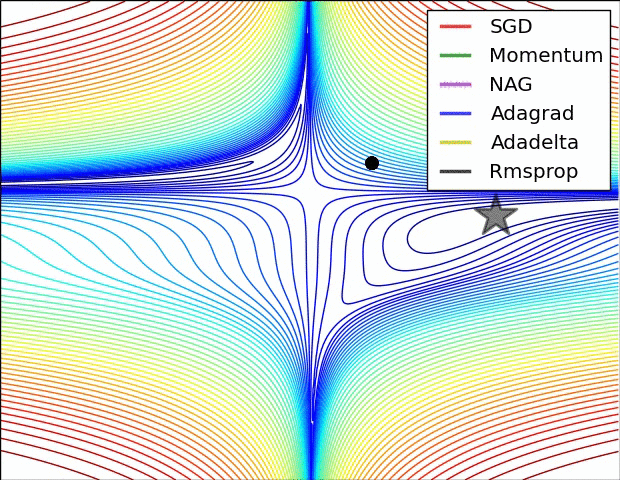
这是一张各种优化器的比较图,从图中可以看到,有一个名叫 Adadelta 的优化器表现十分亮眼啊!
Adadelta 是一种自适应的优化器,它能够自动的计算自变量更新量的平方的指数加权移动的平均项来作为学习率。因此,我们设置的学习率实际上影响已经不是太大了。
从图中可以看到,这种优化器在训练之初和中期又能够快速下降,只不过到接近最优解的时候会出现小幅震荡。而 SGD 因全程都保持一个学习率,所以在设置合适的情况下,在最优解附近收敛的更干脆。
# 使用 Adadelta 进行损失函数的梯度下降求解
train_step = tf.train.AdadeltaOptimizer(0.0001).minimize(cross_entropy)
但由于 Adadelta 实际训练过程中与我们起初告诉它的学习率关系不大,就是不受控,训练起来到后面还是很难受的,所以 CoorChice 尝试之后还是选择换成 SGD 。
lr = tf.Variable(1e-5)
# 使用 SGD 进行损失函数的梯度下降求解
train_step = tf.train.GradientDescentOptimizer(lr).minimize(cross_entropy)
而且,CoorChice 使用了一个变量 lr 来设置优化器的学习率,这样在训练过程中,我们还可以动态的额控制当前的学习率。
增加网络深度、宽度
当发生欠拟合时,也有可能是网络过于简单,权重太少,导致无法学习到足够的信息。在本次训练中,CoorChice 仍然使用了上次的 4 层单核网络,似乎确实是太简单了。
那就加强它吧。
# coding=utf-8
from cnn_utils import *
class CnnBreadBasketNetwork:
def __init__(self):
with tf.name_scope("input"):
self.x_data = tf.placeholder(tf.float32, shape=[None, 135], name='x_data')
# 补位
input_data = tf.pad(self.x_data, [[0, 0], [0, 1]], 'CONSTANT')
with tf.name_scope("input_reshape"):
# 变形为可以和卷积核卷积的张量
input_data = tf.reshape(input_data, [-1, 17, 8, 1])
tf.summary.image("input", input_data, 1)
self.y_data = tf.placeholder(tf.float32, shape=[None], name='y_data')
# ------------------------构建第一层网络---------------------
with tf.name_scope("hidden1"):
# 第一个卷积
with tf.name_scope("weights1"):
W_conv11 = weight_variable([3, 3, 1, 64])
variable_summaries(W_conv11, "W_conv11")
with tf.name_scope("biases1"):
b_conv11 = bias_variable([64])
variable_summaries(b_conv11, "b_conv11")
h_conv11 = tf.nn.relu(conv2(input_data, W_conv11) + b_conv11)
tf.summary.histogram('activations_h_conv11', h_conv11)
# 第二个卷积
with tf.name_scope("weights2"):
W_conv12 = weight_variable([3, 3, 64, 64])
variable_summaries(W_conv12, "W_conv12")
with tf.name_scope("biases2"):
b_conv12 = bias_variable([64])
variable_summaries(b_conv12, "b_conv12")
h_conv12 = tf.nn.relu(conv2(h_conv11, W_conv12) + b_conv12)
tf.summary.histogram('activations_h_conv11', h_conv12)
# 池化
h_pool1 = max_pool_2x2(h_conv12)
tf.summary.histogram('pools_h_pool1', h_pool1)
# ------------------------构建第二层网络---------------------
with tf.name_scope("hidden2"):
# 第一个卷积核
with tf.name_scope("weights1"):
W_conv21 = weight_variable([3, 3, 64, 128])
variable_summaries(W_conv21, 'W_conv21')
with tf.name_scope("biases1"):
b_conv21 = bias_variable([128])
variable_summaries(b_conv21, 'b_conv21')
h_conv21 = tf.nn.relu(conv2(h_pool1, W_conv21) + b_conv21)
tf.summary.histogram('activations_h_conv21', h_conv21)
# 第二个卷积核
with tf.name_scope("weights2"):
W_conv22 = weight_variable([3, 3, 128, 128])
variable_summaries(W_conv22, 'W_conv22')
with tf.name_scope("biases2"):
b_conv22 = bias_variable([128])
variable_summaries(b_conv22, 'b_conv22')
h_conv22 = tf.nn.relu(conv2(h_conv21, W_conv22) + b_conv22)
tf.summary.histogram('activations_h_conv22', h_conv22)
# 池化
self.h_pool2 = max_pool_2x2(h_conv22)
tf.summary.histogram('pools_h_pool2', self.h_pool2)
shape_0 = self.h_pool2.get_shape()[1].value
shape_1 = self.h_pool2.get_shape()[2].value
h_pool2_flat = tf.reshape(self.h_pool2, [-1, shape_0 * shape_1 * 128])
# ------------------------ 构建第一层全链接层 ---------------------
with tf.name_scope("fc1"):
with tf.name_scope("weights"):
W_fc1 = weight_variable([shape_0 * shape_1 * 128, 4096])
variable_summaries(W_fc1, 'W_fc1')
with tf.name_scope("biases"):
b_fc1 = bias_variable([4096])
variable_summaries(b_fc1, 'b_fc1')
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
tf.summary.histogram('activations_h_fc1', h_fc1)
# ------------------------构建输出层---------------------
with tf.name_scope("output"):
with tf.name_scope("weights"):
W_out = weight_variable([4096, 1])
variable_summaries(W_out, 'W_out')
with tf.name_scope("biases"):
b_out = bias_variable([1])
variable_summaries(b_out, 'b_out')
# 注意⚠️,此处的激活函数已经替换成 ReLu 了
self.y_conv = tf.nn.relu(tf.matmul(h_fc1, W_out) + b_out)
tf.summary.histogram('activations_y_conv', self.y_conv)
这就是经过改进后的网络的全部代码了。
可以看到,还是熟悉的套路。以下是版本更新内容:
每个卷积核的 size 由 5x5 变成了 3x3
第一个卷积层的卷积核通道数由原来的 32 增加到了 64。将卷积核数量提高一倍。
卷积核层数仍然是两层,但每层都多增加了一个卷积核组。
全链接层的神经元个数由原来的 1024 个增加至 4096 个。
再说一下网络中的一些变化。
self.x_data = tf.placeholder(tf.float32, shape=[None, 135], name='x_data')
# 补位
input_data = tf.pad(self.x_data, [[0, 0], [0, 1]], 'CONSTANT')
# 变形为可以和卷积核卷积的张量
input_data = tf.reshape(input_data, [-1, 17, 8, 1])
self.y_data = tf.placeholder(tf.float32, shape=[None], name='y_data')
定义占位的时候,由于表格数据中只有 135 列,所以先定义一个 shape 为 [None,135] 的占位。但是比较尴尬的是,135 是一个奇数,无法转换成能和卷积核卷积的张量,所以 CoorChice 给它补了一列,通过 tensorflow 提供的 pad() 函数。
input_data = tf.pad(self.x_data, [[0, 0], [0, 1]], 'CONSTANT')
第二个参数中的数字分别表示需要在原张量的 上、下、左、右 补充多少行或列。这里 CoorChice 再原张量的右边补充了一列 0。
现在,就可以变形成可和卷积核卷积的张量了。
input_data = tf.reshape(input_data, [-1, 17, 8, 1])
- 小技巧:通常,经过多层的卷积和池化之后,进入第一层全链接层或者直接进入输出层的时候,我们需要知道上一层的形状是怎样的,然后才能设计全链接层或者输出层的权重形状。可以通过如下方式方便的获得输入的形状:
# 获得最后一个池化层的宽
shape_0 = self.h_pool2.get_shape()[1].value
# 获得最后一个池化层的高
shape_1 = self.h_pool2.get_shape()[2].value
# 变形为全链接层可乘的形状
h_pool2_flat = tf.reshape(self.h_pool2, [-1, shape_0 * shape_1 * 128])
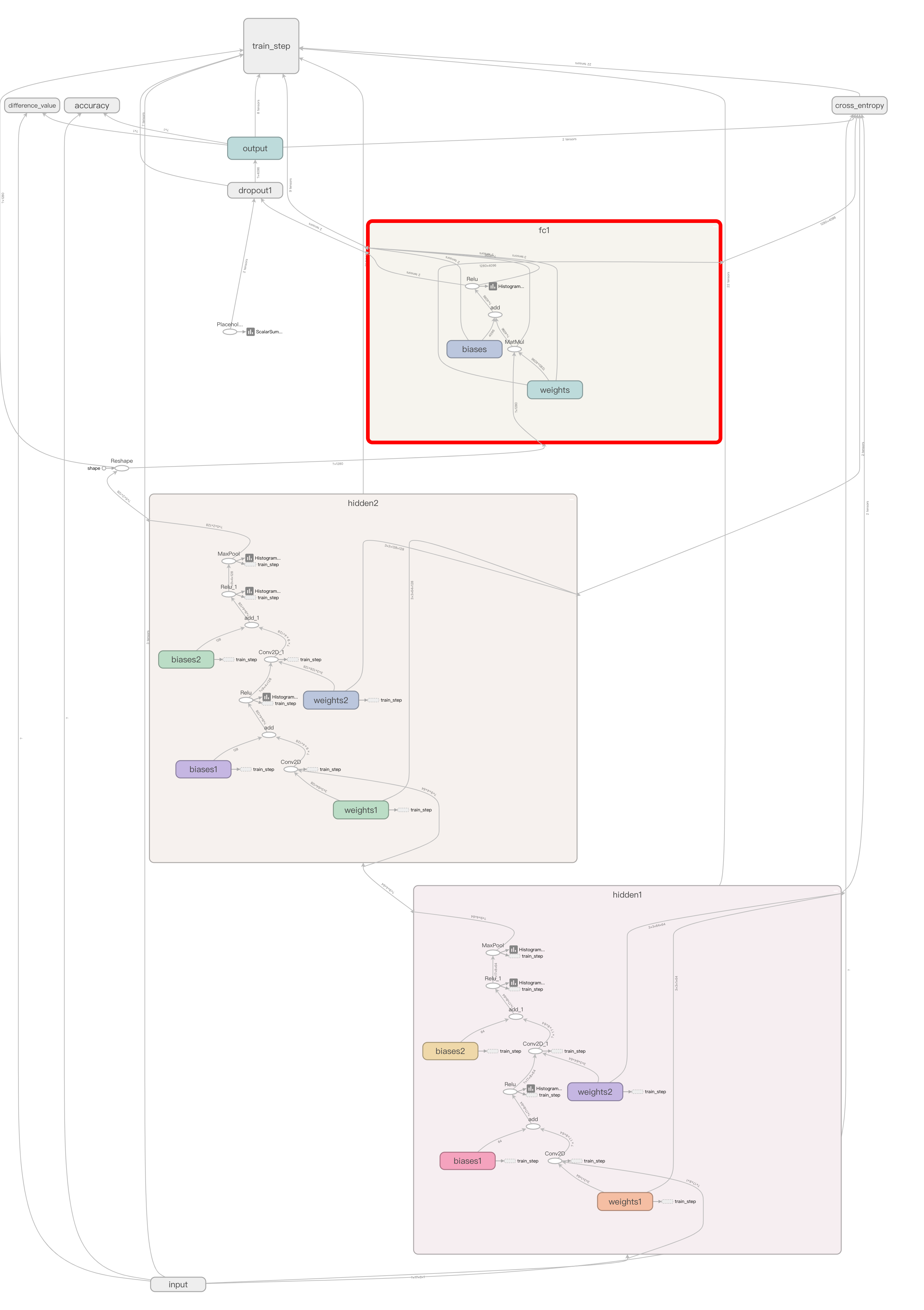
实际上,这个网络可能不是太好,深度不够,可能导致准确率不够。但受设备限制,设计的太深,会导致每次训练都会花费大量的时间,所以 CoorChice 就尽量精简一点,主要看这个过程是怎样进行的。
这是新的网络结构:
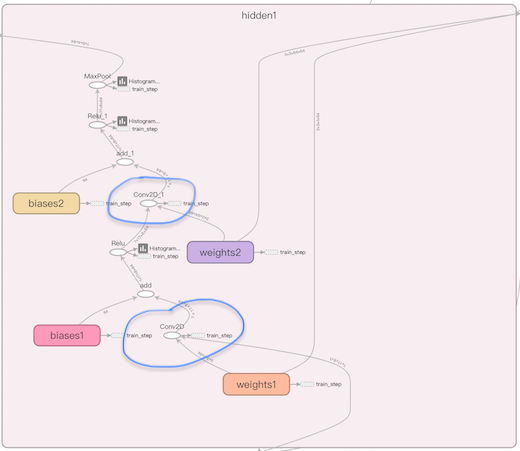
看看局部的两组卷积 hidden 层:
开启训练!
# coding=utf-8
import time
from cnn_model import *
from BBDATA import *
train_times = 20000
base_path = ".../BreadBasket/"
save_path = base_path + str(train_times) + "/"
# 读取数据
BBDATA = read_datas('data/')
# 创建网络
network = CnnBreadBasketNetwork()
x_data = network.x_data
y_data = network.y_data
y_conv = network.y_conv
keep_prob = network.keep_prob
# ------------------------构建损失函数---------------------
with tf.name_scope("cross_entropy"):
# 创建正则化对象,此处使用的是 L2 范数
regularization = tf.contrib.layers.l2_regularizer(scale=(5.0 / 500))
# 应用正则化到参数集上
reg_term = tf.contrib.layers.apply_regularization(regularization)
# 在损失函数中加入正则化项
cross_entropy = tf.reduce_mean(tf.square((y_conv - y_data))) + reg_term
tf.scalar_summary('loss', cross_entropy)
with tf.name_scope("train_step"):
lr = tf.Variable(1e-5)
# 使用 SGD 进行损失函数的梯度下降求解
train_step = tf.train.GradientDescentOptimizer(lr).minimize(cross_entropy)
# 记录平均差值
with tf.name_scope("difference_value"):
dv = tf.reduce_mean(tf.abs(y_conv - y_data))
tf.scalar_summary('difference_value', cross_entropy)
# ------------------------构建模型评估函数---------------------
with tf.name_scope("accuracy"):
with tf.name_scope("correct_prediction"):
correct_prediction = tf.less_equal(tf.abs(y_conv - y_data), 0.5)
with tf.name_scope("accuracy"):
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.scalar_summary('accuracy', accuracy)
# 创建会话
sess = tf.InteractiveSession()
summary_merged = tf.merge_all_summaries()
train_writer = tf.train.SummaryWriter(save_path + "graph/train", sess.graph)
test_writer = tf.train.SummaryWriter(save_path + "graph/test")
start_time = int(round(time.time() * 1000))
# 初始化参数
sess.run(tf.initialize_all_variables())
global loss
loss = 0
global train_accuracy
for i in range(train_times):
# 从训练集中取出 200 个样本进行一波训练
batch = BBDATA.train_data.batch(200)
if i % 100 == 0:
summary, train_accuracy, test_loss, dv_value = sess.run([summary_merged, accuracy, cross_entropy, dv],
feed_dict={x_data: BBDATA.test_data.data, y_data: BBDATA.test_data.label, keep_prob: 1})
test_writer.add_summary(summary, i)
consume_time = int(round(time.time() * 1000)) - start_time
print("当前共训练 " + str(i) + "次, 累计耗时:" + str(consume_time) + "ms,实时准确率为:%g" % (train_accuracy * 100.) + "%, "
+ "当前误差均值:" + str(dv_value) + ", train_loss = " + str(loss) + ", test_loss = " + str(test_loss))
if i % 1000 == 0:
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _, loss = sess.run([summary_merged, train_step, cross_entropy],
feed_dict={x_data: batch.data, y_data: batch.label, keep_prob: 0.6}, options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, str(i))
train_writer.add_summary(summary, i)
else:
summary, _, loss = sess.run([summary_merged, train_step, cross_entropy],
feed_dict={x_data: batch.data, y_data: batch.label, keep_prob: 0.6})
train_writer.add_summary(summary, i)
# 每训练 2000 次保存一次模型
if i != 0 and i % 1000 == 0:
test_accuracy, test_dv = sess.run([accuracy, dv], feed_dict={x_data: BBDATA.test_data.data, y_data: BBDATA.test_data.label, keep_prob: 1})
save_model(base_path + str(i) + "_" + str(test_dv) + "/", sess, i)
# 在测试集计算准确率
summary, final_test_accuracy, test_dv = sess.run([summary_merged, accuracy, dv],
feed_dict={x_data: BBDATA.test_data.data, y_data: BBDATA.test_data.label, keep_prob: 1})
train_writer.add_summary(summary)
print("测试集准确率:%g" % (final_test_accuracy * 100.) + "%, 误差均值:" + str(test_dv))
print("训练完成!")
train_writer.close()
test_writer.close()
# 保存模型
save_model(save_path, sess, train_times)
sess.close()
这是完整的训练代码,基本上和 《【Get】用深度学习识别手写数字》 中是一样的。只不过 CoorChice 多加了一个 MAE 作为模型评估的指标。
dv = tf.reduce_mean(tf.abs(y_conv - y_data))
因为是进行回归预测,所以使用 MAE 均方方差来作为一个评估模型好坏的指标。平均绝对差越小,表明模型预测结果越接近于真实情况。
此外,由于是做回归预测,所以之前分类使用的交叉熵损失函数就不是特别合适了,我们换成均方误差损失函数。
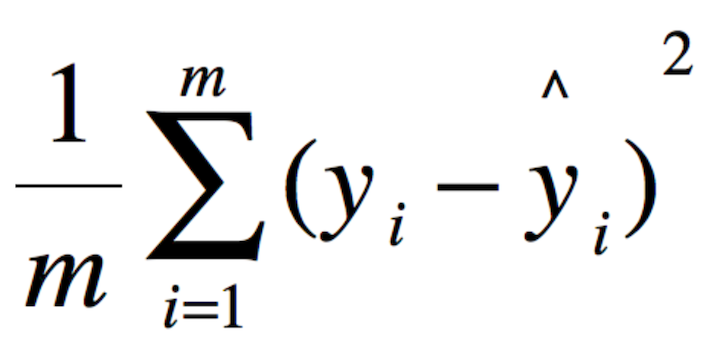
cross_entropy = tf.reduce_mean(tf.square((y_conv - y_data))) + reg_term
需要注意的是:
correct_prediction = tf.less_equal(tf.abs(y_conv - y_data), 0.5)
评估模型现在不应该再是比较预测值和标签值是否相等了,在回归预测中,要做到模型能够预测出的值和真实值完全相等几乎是不可能的。我们把评估模型改造成绝对差 <500 即接受该预测结果,毕竟是在个人设备上跑,要达到比较高的精度还是很难的。
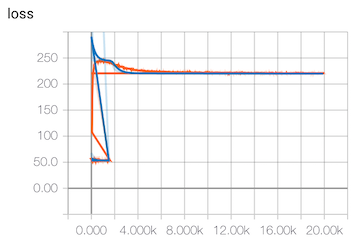
loss 不下降了
上面这段代码中,SGD 优化器的学习率变量实际上是 CoorChice 后来加上的。在此前,使用的固定的,但当 run 起来开始训练的时候,发现 loss 总在一个值很大,但范围很小的区间内波动,而且准确率也在小范围的波动,提升不上去。
- 损失变化曲线
- 准确率变化曲线
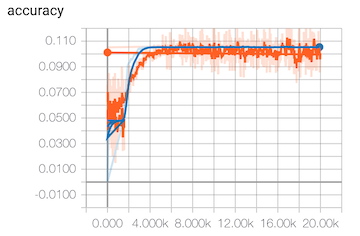
此时的准确大概在 10.5% 附近徘徊开来,loss 趋势变化也不大。
这说明训练基本处于停滞不前的状态了,但显然,我们的模型精度是不够的。出现这种情况可能是以下几种情况。
陷入局部最优解
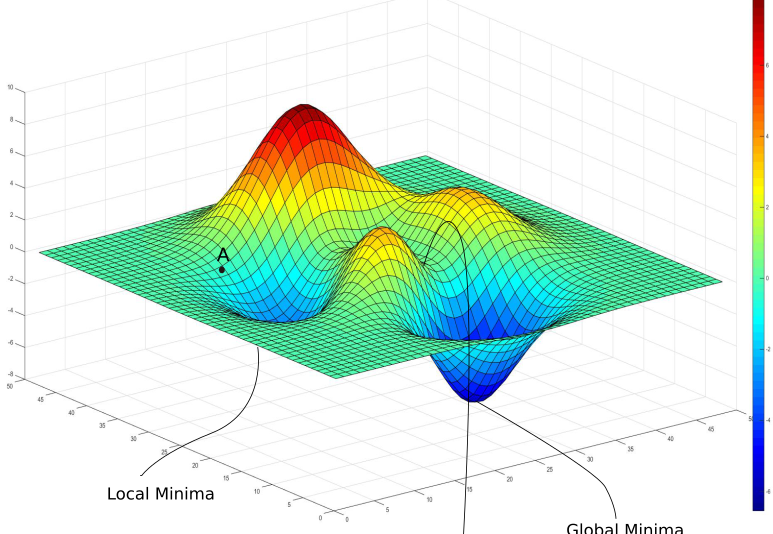
如图,在多特征的高维 loss 曲面中,可能存在很多 A 点旁边的小坑。当进入小坑的底部时,loss 的一阶导数也是为 0 的,就网上常常说的陷入了局部最优解中,而没有到真正的 Global Minima。
实际上,上面代码中我们采取的 mini-patch 抽样进行训练,一定程度上也是能减小陷入局部最优解的情况的。因为可能这批样本陷入了局部最优中,下一批样本的波动又把你从坑里拽出来了。当然有的时候我们可能会看到 loss 反而增大了,也是因为这种方式导致的。
骑在鞍点上
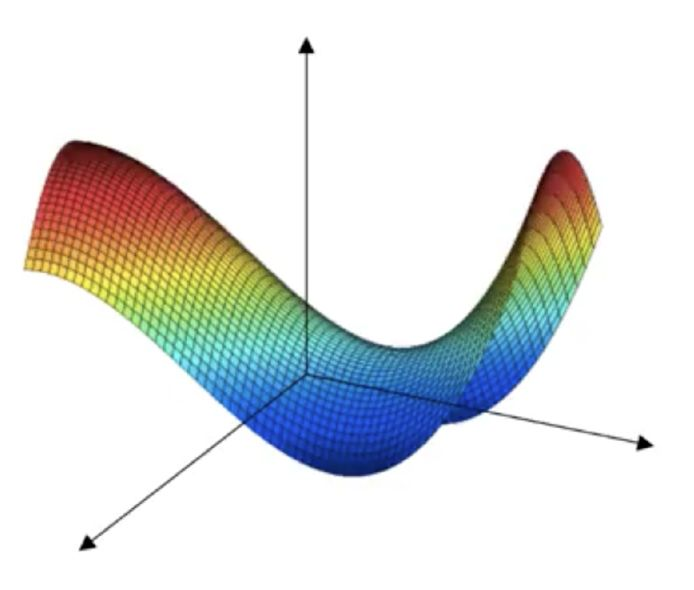
如图,在 loss 的曲面中,会有比局部最优坑还多的马鞍型曲面。

憨态可掬的🐎...
当我们骑到马鞍上的鞍点是,此处的导数也是为0的,那么是真正的收敛了吗?不是的。看图中,我们在x轴方向上是极小值,但在y轴方向上是极大值。

如果落在这样正在进入鞍点的尴尬位置,那么你的训练就会看起来几乎毫无波动,走出这个区域需要花费很长的时间。
幸运的是,通过适当增大学习率或者适当减小 batch,都有助于尽快逃离这个区域。
无尽的平缓面
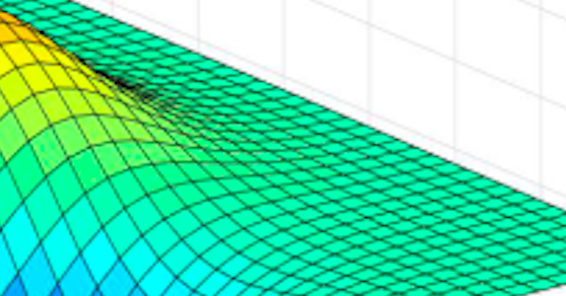
然后在 loss 曲面中,同时存在着如上图一样的大面积的平缓曲面,处于这些区域中的点,虽然导数不为 0 ,但值却及其的小,即使一遍又一遍的反复训练,仍然看起来几乎没有变化。
可怕的是,我们无法分辨出是处于局部最优,还是处于马鞍区域,或者干脆就是在类平面上。
如何处理?
出现以上几种情况,都会导致看起来不学习的情况,特别是在性能有限的个人设备上。但我们还是有一些套路可以尽量减小这种情况的发生的。
检查数据。确保数据标签对应正常。
修改调整网络结构。尽量使用一些开源的大牛们产出的网络模型,如 VGG 系列。在它们的基础上修改大概率上比自己捣腾靠谱。
调整 batch 大小。batch过大导致训练时间过长,也容易进入局部最优或者马鞍区域。过小又回导致震荡比较剧烈,不容易找到最优解。
多尝试不同的参数初始化。如果足够幸运的话,没准初始化就落到了 Global Minima 的坑里去了。
动态学习率。一成不变的小的学习率当陷入局部最优时就算是掉坑里了,或者在平滑面上移动的特别慢。如果大了又容易错过最优解。所以像 Adam 这样动态的学习率优化器能一定程度上减少这些问题的发生。当然,我们也可以在 SGD 的基础上,根据 loss 的情况自己动态的增大学习率,在 loss 很大却不变的时候,在 loss 较小的时候减小学习率,避免错过最优解。
通过 loss 大致的判断问题
train loss 不断下降,test loss不断下降,说明网络仍在学习;
train loss 不断下降,test loss趋于不变,说明网络过拟合;
train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
通过 loss 可以大致的判断一些问题,上述规律可以最为参考,但不保证一定准确。
总结
最后,一张图做个总结:

- 抽出空余时间写文章分享需要动力,各位看官动动小手点个赞哈,信仰还是需要持续充值的😄
- CoorChice 一直在不定期的分享新的干货,想要上车只需进到 CoorChice的【个人主页】 点个关注就好了哦。
