

摘要: 在进行爬虫时,除了常见的不用登录就能爬取的网站,还有一类需要先登录的网站。比如豆瓣、知乎,以及上一篇文章中的桔子网。这一类网站又可以分为:只需输入帐号密码、除了帐号密码还需输入或点击验证码等类型。本文以只需输入账号密码就能登录的桔子网为例,介绍模拟登录常用的 3 种方法。
- POST 请求方法:需要在后台获取登录的 URL并填写请求体参数,然后 POST 请求登录,相对麻烦;
- 添加 Cookies 方法:先登录将获取到的 Cookies 加入 Headers 中,最后用 GET 方法请求登录,这种最为方便;
- Selenium 模拟登录:代替手工操作,自动完成账号和密码的输入,简单但速度比较慢。
下面,我们用代码分别实现上述 3 种方法。
1. 目标网页
这是我们要获取内容的网页:
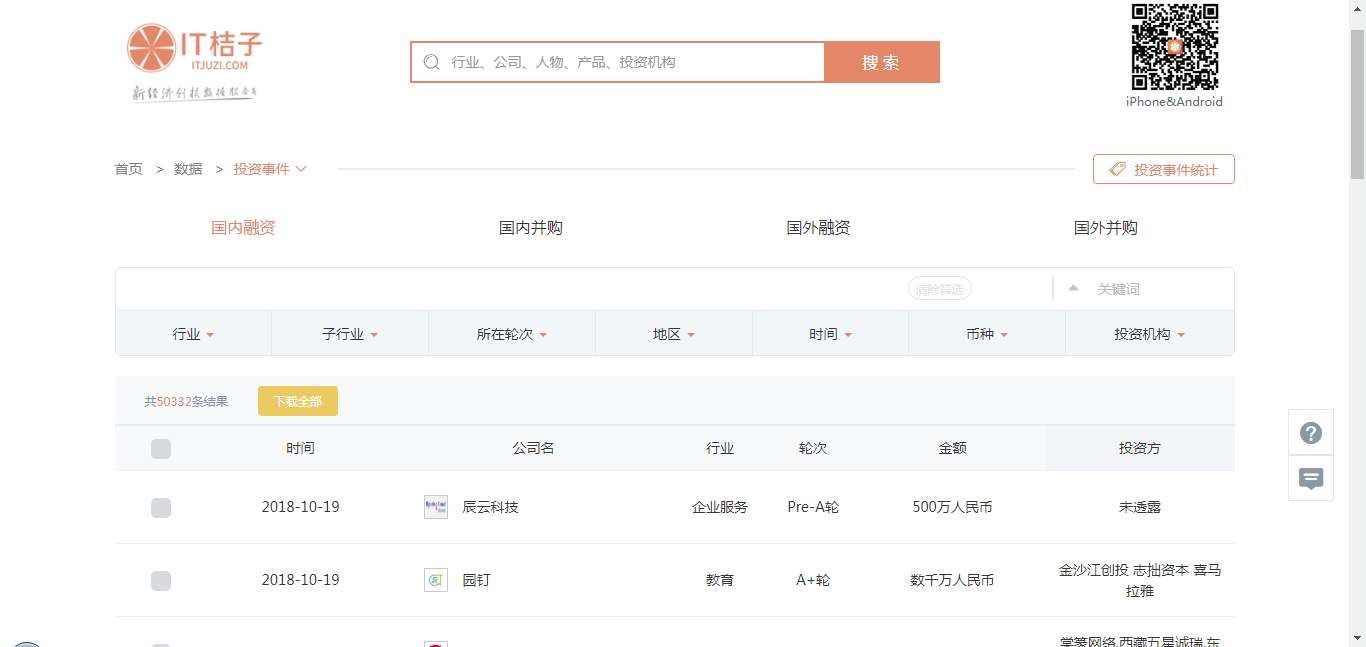
这个网页需要先登录才能看到数据信息,登录界面如下:
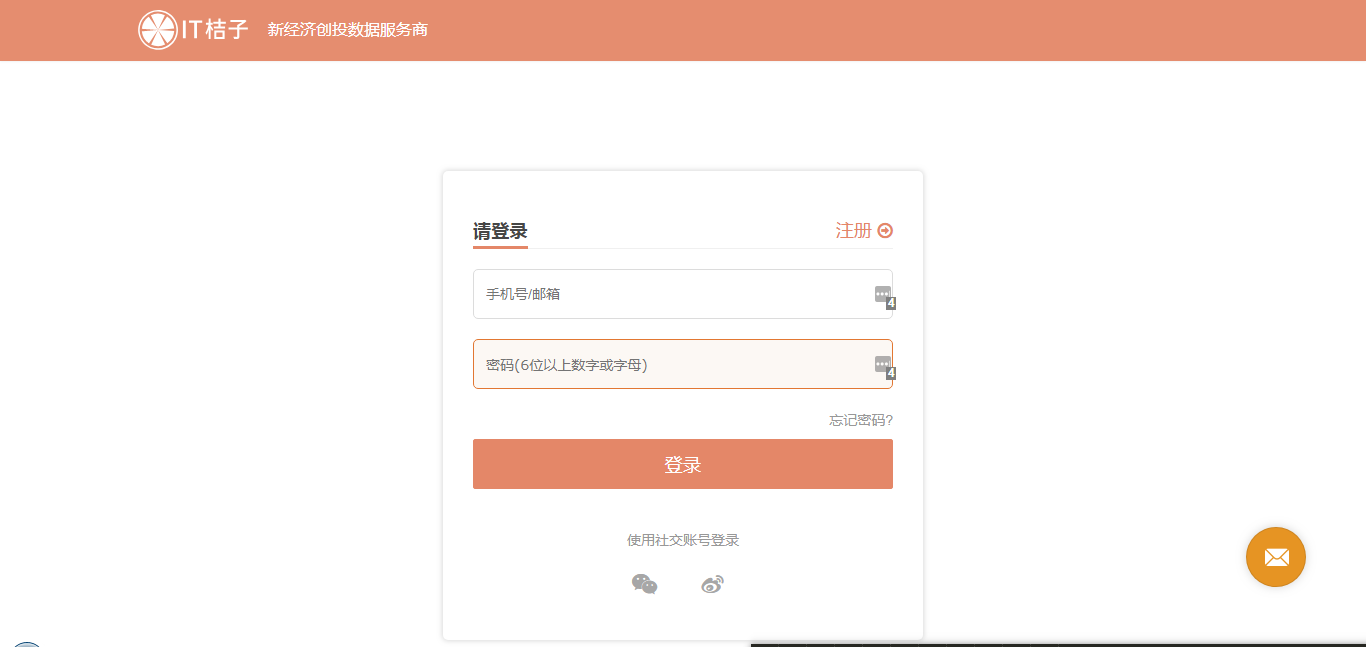
可以看到,只需要输入账号和密码就可以登录,不用输验证码,比较简单。下面我们利用一个测试账号和密码,来实现模拟登录。
2. POST 提交请求登录
首先,我们要找到 POST 请求的 URL。
有两种方法,第一种是在网页 devtools 查看请求,第二种是在 Fiddler 软件中查看。
先说第一种方法。
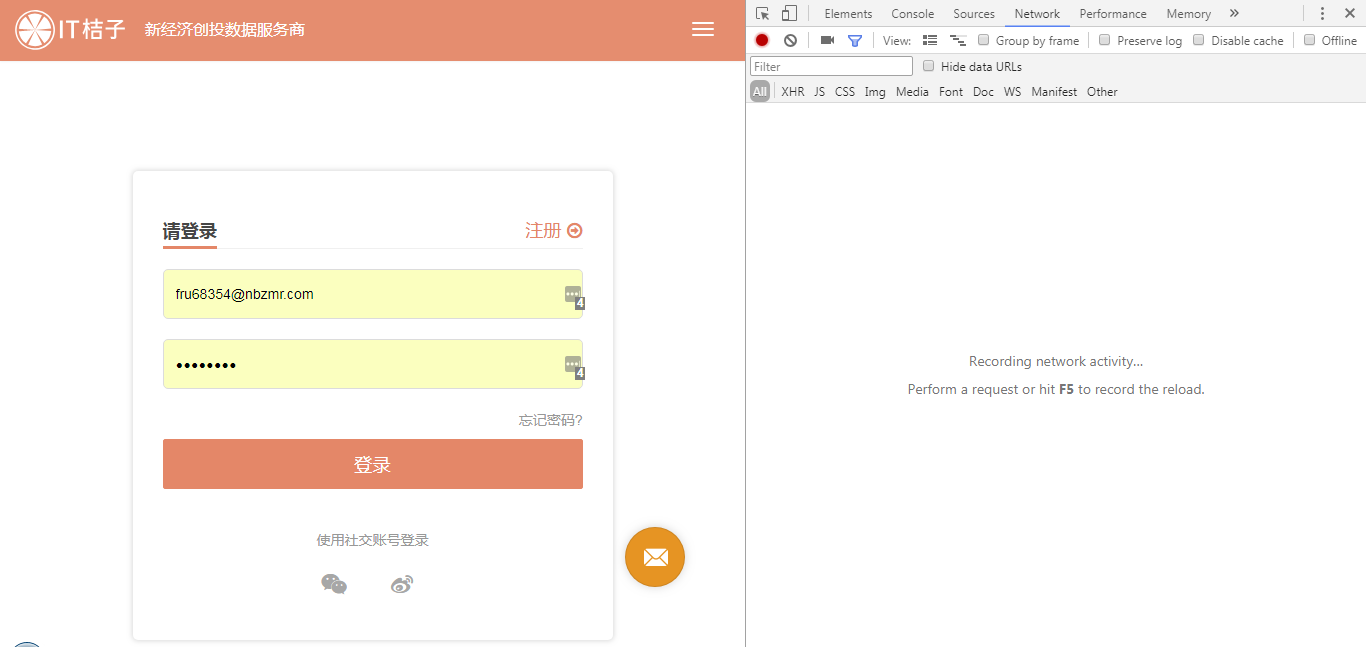
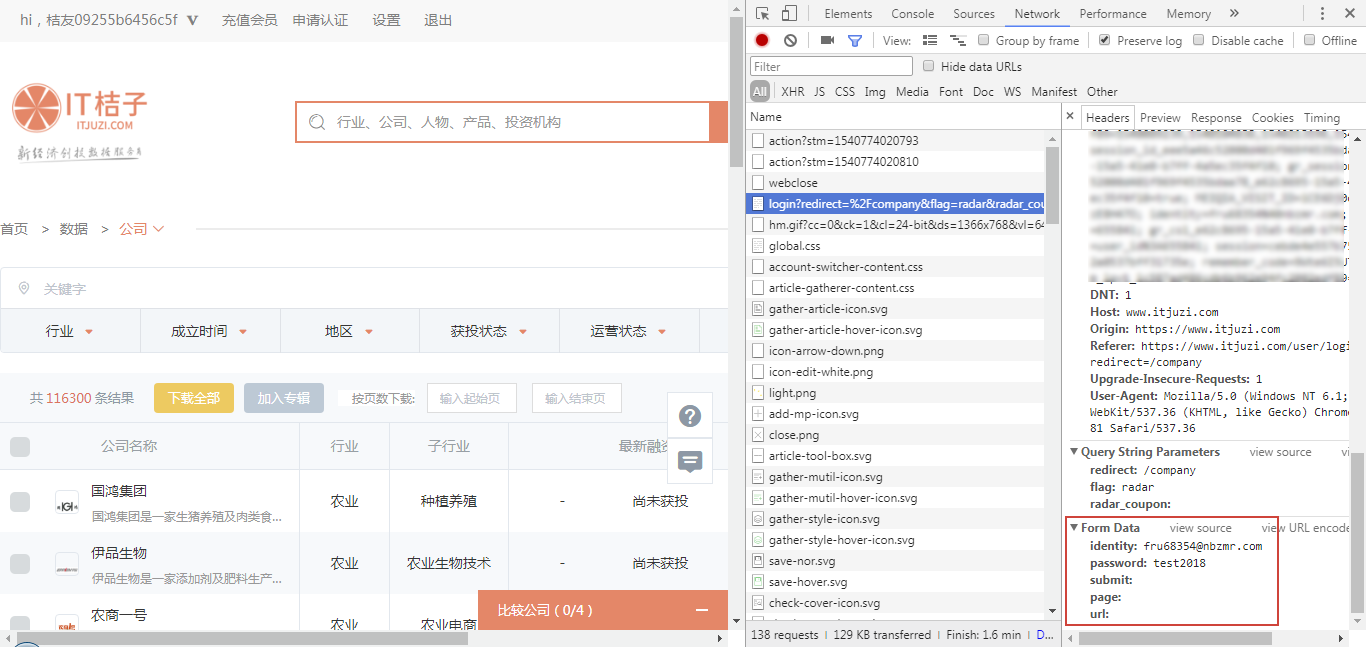
在登录界面输入账号密码,并打开开发者工具,清空所有请求,接着点击登录按钮,这时便会看到有大量请求产生。哪一个才是 POST 请求的 URL呢?这个需要一点经验,因为是登录,所以可以尝试点击带有 「login」字眼的请求。这里我们点击第四个请求,在右侧 Headers 中可以看到请求的 URL,请求方式是 POST类型,说明 URL 找对了。
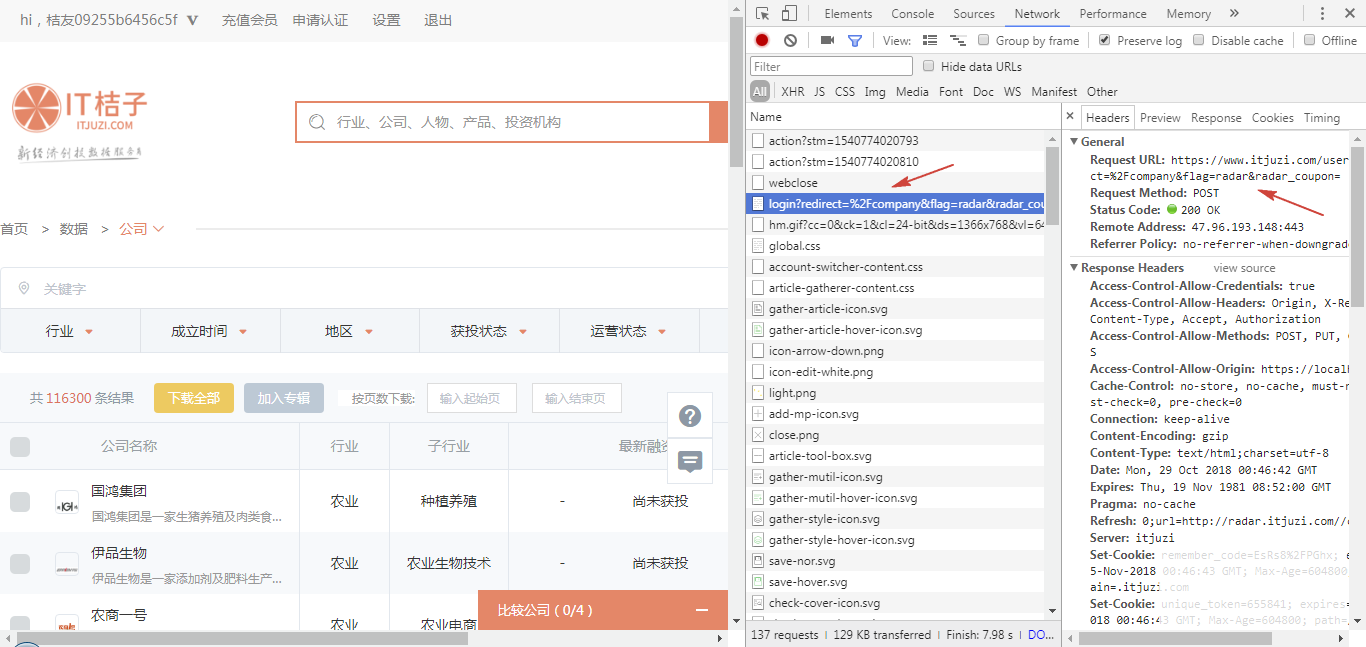
接着,我们下拉到 Form Data,这里有几个参数,包括 identify 和 password,这两个参数正是我们登录时需要输入的账号和密码,也就是 POST 请求需要携带的参数。
参数构造非常简单,接下来只需要利用 Requests.post 方法请求登录网站,然后就可以爬取内容了。
下面,我们尝试用 Fiddler 获取 POST 请求。
如果你对 Fiddler 还不太熟悉或者没有电脑上没有安装,可以先了解和安装一下。
Fiddler 是位于客户端和服务器端的 HTTP 代理,也是目前最常用的 HTTP 抓包工具之一 。 它能够记录客户端和服务器之间的所有 HTTP 请求,可以针对特定的 HTTP 请求,分析请求数据、设置断点、调试 web 应用、修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 web 调试的利器。
Fiddler 下载地址:
使用教程:
下面,我们就通过 Fiddler 截取登录请求。
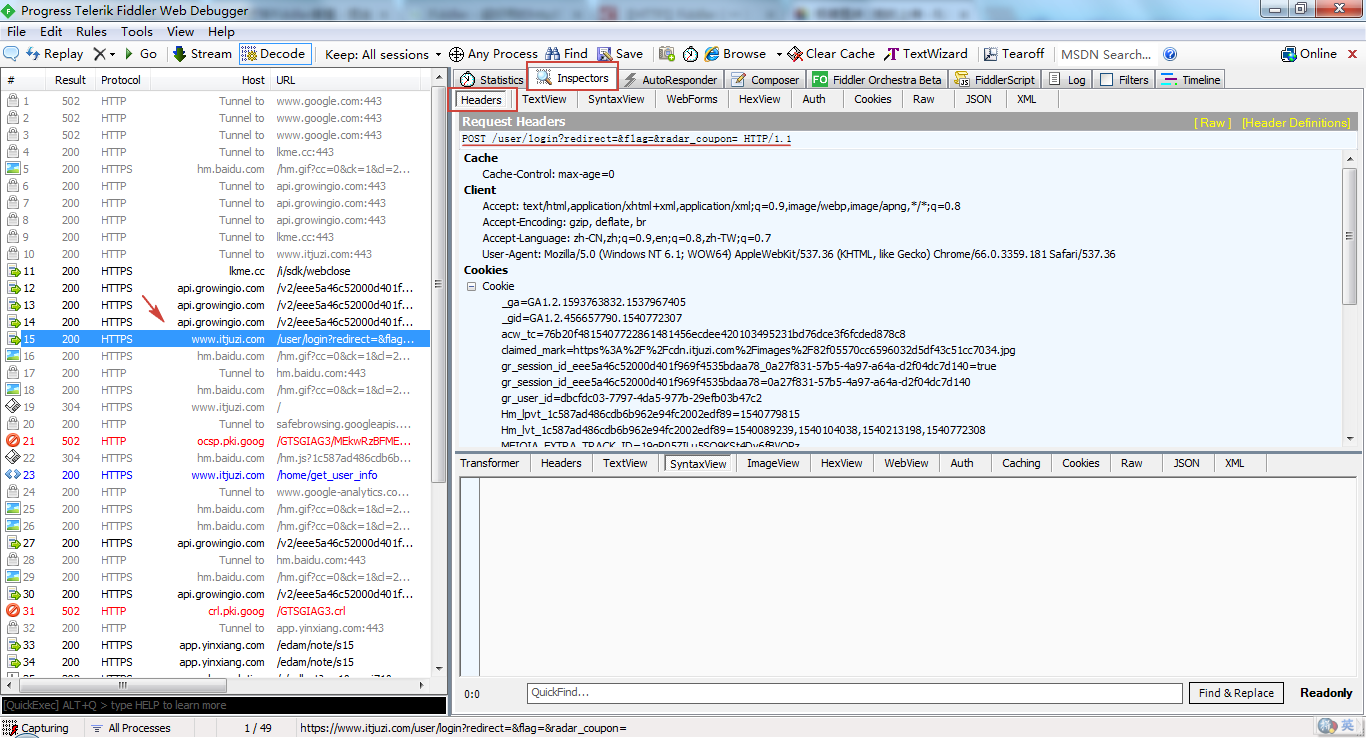
当点击登录时,官场 Fiddler 页面,左侧可以看到抓取了大量请求。通过观察,第15个请求的 URL中含有「login」字段,很有可能是登录的 POST 请求。我们点击该请求,回到右侧,分别点击「inspectors」、「Headers」,可以看到就是 POST 请求,该 URL 和上面的方法获取的 URL 是一致的。
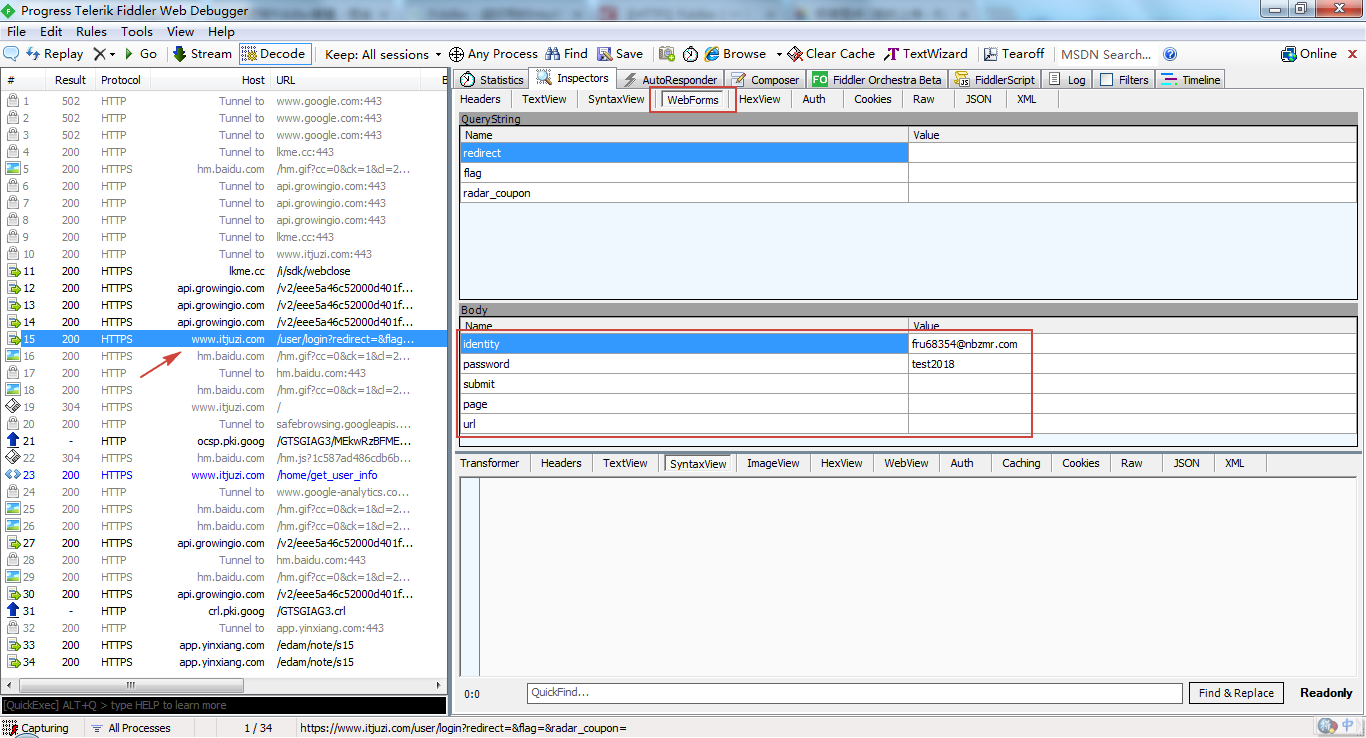
接着,切换到右侧的 Webforms 选项,可以看到 Body 请求体。也和上面方法中得到的一致。
获取到 URL 和请求体参数之后,下面就可以开始用 Requests.post 方法模拟登录了。
代码如下:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
data = {
'identity':'irw27812@awsoo.com',
'password':'test2018',
}
url ='https://www.itjuzi.com/user/login?redirect=&flag=&radar_coupon='
session = requests.Session()
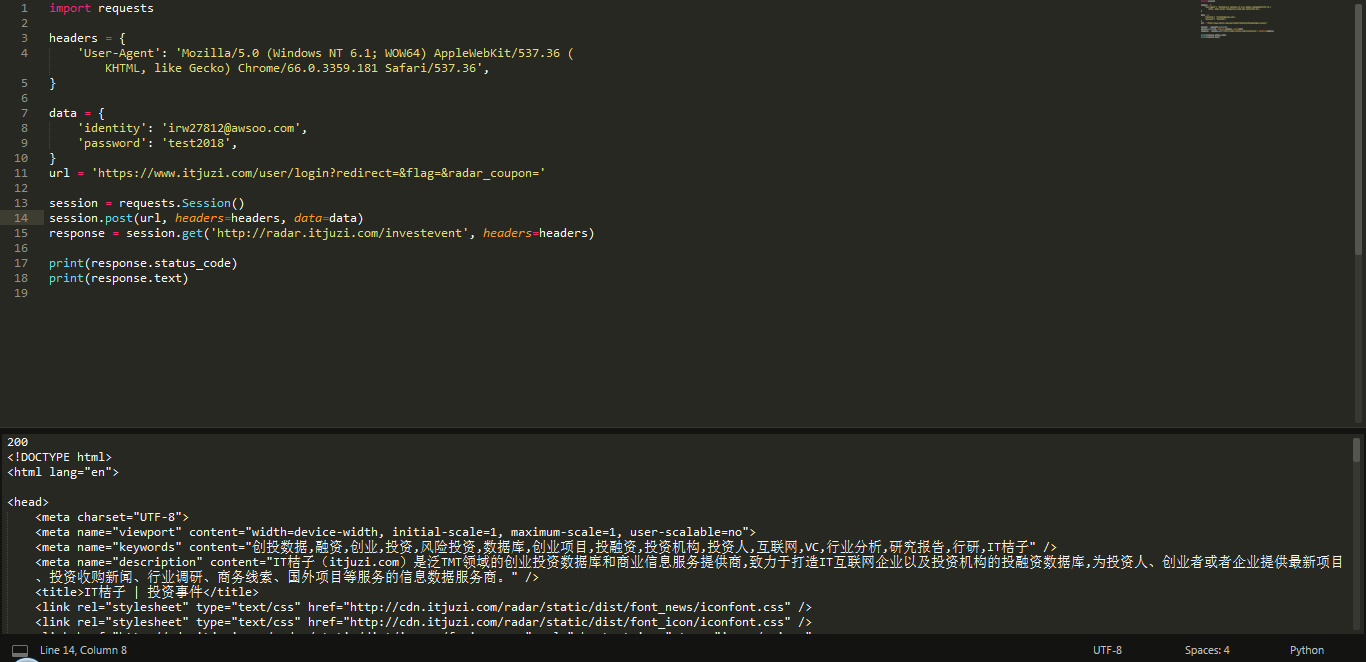
session.post(url,headers = headers,data = data)
# 登录后,我们需要获取另一个网页中的内容
response = session.get('http://radar.itjuzi.com/investevent',headers = headers)
print(response.status_code)
print(response.text)
使用 session.post 方法提交登录请求,然后用 session.get 方法请求目标网页,并输出 HTML代码。可以看到,成功获取到了网页内容。
下面,介绍第 2 种方法。
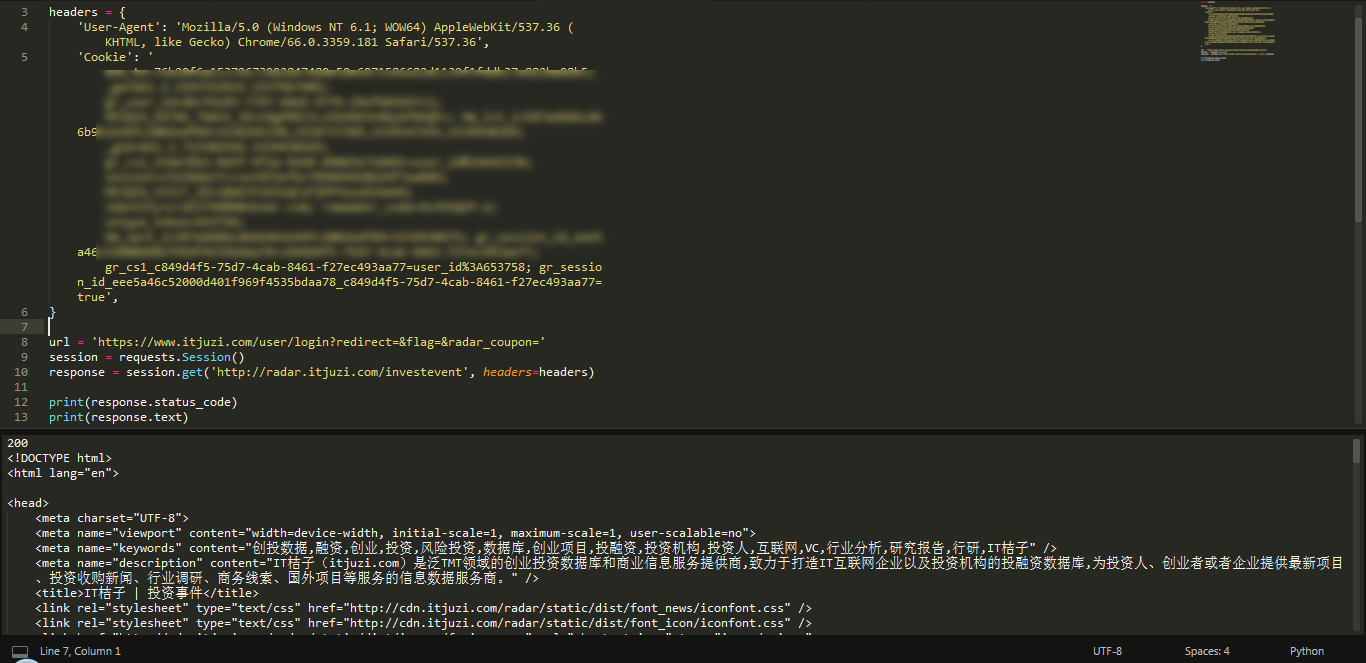
3. 获取 Cookies,直接请求登录
上面一种方法,我们需要去后台获取 POST 请求链接和参数,比较麻烦。下面,我们可以尝试先登录,获取 Cookie,然后将该 Cookie 添加到 Headers 中去,然后用 GET 方法请求即可,过程简单很多。
代码如下:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'Cookie': '你的cookie',
}
url = 'https://www.itjuzi.com/user/login?redirect=&flag=&radar_coupon='
session = requests.Session()
response = session.get('http://radar.itjuzi.com/investevent', headers=headers)
print(response.status_code)
print(response.text)
可以看到,添加了 Cookie 后就不用再 POST 请求了,直接 GET 请求目标网页即可。可以看到,也能成功获取到网页内容。
下面介绍第 3 种方法。
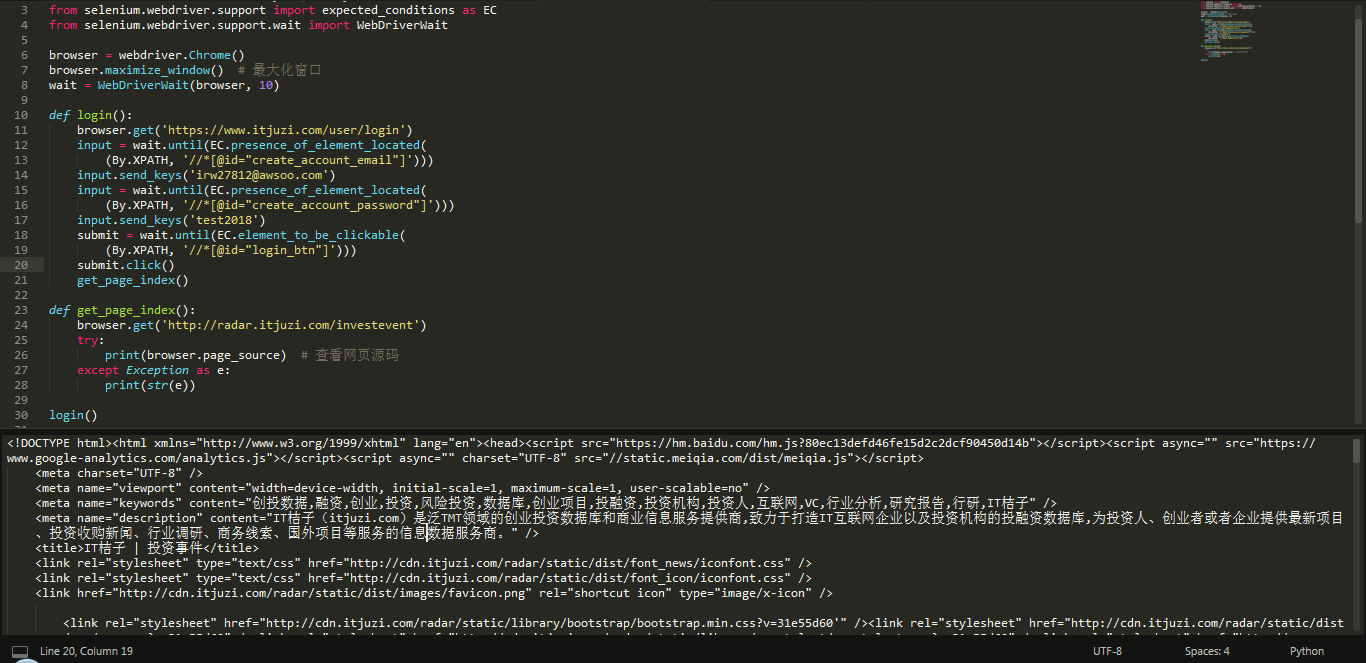
4. Selenium 模拟登录
这个方法很直接,利用 Selenium 代替手动方法去自动输入账号密码然后登录就行了。
关于 Selenium 的使用,在之前的一篇文章中有详细介绍,如果你不熟悉可以回顾一下:
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.maximize_window() # 最大化窗口
wait = WebDriverWait(browser, 10) # 等待加载10s
def login():
browser.get('https://www.itjuzi.com/user/login')
input = wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="create_account_email"]')))
input.send_keys('irw27812@awsoo.com')
input = wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="create_account_password"]')))
input.send_keys('test2018')
submit = wait.until(EC.element_to_be_clickable(
(By.XPATH, '//*[@id="login_btn"]')))
submit.click() # 点击登录按钮
get_page_index()
def get_page_index():
browser.get('http://radar.itjuzi.com/investevent')
try:
print(browser.page_source) # 输出网页源码
except Exception as e:
print(str(e))
login()
这里,我们在网页中首先定位了账号节点位置:'//*[@id="create_account_email"]',然后用 input.send_keys 方法输入账号,同理,定位了密码框位置并输入了密码。接着定位 登录 按钮的位置://*[@id="login_btn"],然后用 submit.click() 方法实现点击登录按钮操作,从而完成登录。可以看到,也能成功获取到网页内容。
以上就是模拟需登录网站的几种方法。当登录进去后,就可以开始爬取所需内容了。
5. 总结:
- 本文分别实现了模拟登录的 3 种操作方法,建议优先选择第 2 种,即先获取 Cookies 再 Get 请求直接登录的方法。
- 本文模拟登录的网站,仅需输入账号密码,不需要获取相关加密参数,比如 Authenticity_token ,同时也无需输入验证码,所以方法比较简单。但是还有很多网站模拟登录时,需要处理加密参数、验证码输入等问题。后续将会介绍。
推荐阅读:
本文完。

