

阅读之前
希望你能有以下基础,方便阅读:
- ECMAScript 6 (ES6)
为什么需要Mock
现今的业务系统已经很少是孤立存在的了,尤其对于一个大公司而言,各个部门之间的配合非常密切,我们或多或少都需要使用兄弟团队或是其他公司提供的接口服务。这样的话,就对我们的联调和测试造成了很大的麻烦。假如各个兄弟部门的步伐完全一致,那么问题就会少很多,但理想很丰满,现实却很骨感,要做到步伐一致基本是不可能的。
为此,我们就需要使用一些工具来帮助我们将业务单元之间尽量解耦,它就是Mock
什么是Mock
如果将mock单独翻译过来,其意义为 “虚假、虚设”,因此在软件开发领域,我们也可以将其理解成 “虚假数据”,或者 “真实数据的替身”。
Mock的好处
- 团队可以更好地并行工作
当使用mock之后,各团队之间可以不需要再互相等待对方的进度,只需要约定好相互之间的数据规范(文档),即可使用mock构建一个可用的接口,然后尽快的进行开发和调试以及自测,提升开发进度的的同时,也将发现缺陷的时间点大大提前。
- 开启TDD(Test-Driven Development)模式,即测试驱动开发
单元测试是TDD实现的基石,而TDD经常会碰到协同模块尚未开发完成的情况,但是有了mock,这些一切都不是问题。当接口定义好后,测试人员就可以创建一个Mock,把接口添加到自动化测试环境,提前创建测试。
- 测试覆盖率
比如一个接口在各种不同的状态下要返回不同的值,之前我们的做法是复现这种状态然后再去请求接口,这是非常不科学的做法,而且这种复现方法很大可能性因为操作的时机或者操作方式不当导致失败,甚至污染之前数据库中的数据。如果我们使用mock,就完全不用担心这些问题。
- 方便演示
通过使用Mock模拟数据接口,我们即可在只开发了UI的情况下,无须服务端的开发就可以进行产品的演示。
- 隔离系统
在使用某些接口的时候,为了避免系统中数据库被污染,我们可以将这些接口调整为Mock的模式,以此保证数据库的干净。
在吹了这么多的Mock之后,相信大家一定跃跃欲试了,那么接下来我们谈一谈实现Mock的几种方法。
实现Mock
“倔强青铜”
好了,我们先从最倔强的“青铜”开始吧,在没有mock的时候,我们是如何在没有真实接口的情况下进行开发的呢?
在本人的记忆里,当遇到这种情况,我最开始的做法就是将数据先写死在业务中,比如:
// api
import api from '../api/index';
function getApiMessage() {
return new Promise((resolve) => {
resolve({
message: '请求成功'
});
})
// return api.getApiMessage();
}
我会将真实的请求注释掉,return一个resolve假数据的promise代替真实的请求,然后我在调用这个方法的时候就会返回一个resolve我自己定义的虚假数据的promise而不是从尚未完成的接口获得的promise。看起来还不错,起码我能够在没有接口的情况下继续进行开发了。虽然当遇到复杂的列表数据的时候,自己写起来有点手疼。
但是虚假数据和业务如此耦合真的好吗?假如当真正的接口完成之后,因为业务可以“正确运行”而忘记了移除这些虚假数据,导致实际你使用的数据一直是你自己编造而非真实的,那可是相当严重的问题。所以我们接下来需要思考的便是如何尽量的减少在业务代码中写入这些虚假数据。为了达成这个目标,让我们正式晋级mock的“荣耀黄金”段位。
“荣耀黄金”
在mock的“荣耀黄金”段位,我们拥有了一个非常好用的工具:mockJs,通过使用mockJs我们能根据模板和规则生成复杂的接口数据,而无需我们自己动手去书写,例如:
// api
import api from '../api/index';
import Mock from 'mockjs';
function getApiMessage() {
return new Promise((resolve) => {
resolve(Mock.mock({
list|1-20: ['mock数据']
});
})
// return api.getApiMessage();
}
/**
* 通过 Mock.mock 方法和 list|1-20: ['mock数据'] 模板
* 我们将生成一个长度为 1-20, 每个值都为 'mock数据' 数组
*/
但是这样做始终只不过是方便了我们“造假”而已,并不能将“假货”真的从我们的业务代码中移除出去。为了实现这个目的,我们不妨先来分析我们的需求:
- 模拟数据与业务代码完全分离
- 通过一些配置,达到只mock部分数据,大部分的数据还是从请求中获取
首先,如果我们要想要模拟数据和业务代码完全分离,我们必须要想办法在请求的时候做一些文章,让其在请求的时候去获取mock数据而非去请求真正的接口,也就是所谓的“请求拦截”,而实现请求拦截也同样有两种方式:
- 修改请求链接到mock-server,在mock-server配置mock数据和路由
// api/index.js
// 通过新增getDataUseMock方法来说明使用了mock方法
import request from '../request';
function getDataUseMock(data) {
request({
mock: true
});
}
// request/index.js
const mockServer = 'http://127.0.0.1:8081';
function request(opt) {
if (opt.mock) {
const apiName = opt.api;
opt.url = `${mockServer}/${apiName}`;
}
...
}
- 直接在检测使用mock时,从mock数据文件中取出对应key值的数据
// api/index.js
// 通过新增getDataUseMock方法来说明使用了mock方法
import request from '../request';
function getDataUseMock(data) {
request({
mock: true
});
}
// request/index.js
import mockData from 'mock/db.js';
function request(opt) {
if (opt.mock) {
const apiName = opt.api;
return new Promise((resolve) => {
resolve(mockData.apiName)
})
}
...
}
//mock/db.js
export default {
'/api/test': {
msg: '请求成功'
}
}
乍一看好像第二种方式似乎更简单,事实也确实如此,但是考虑到如果我是直接从文件中直接读取数据,那么业务上的行为也会改变,该发请求的地方并没有发请求,所以我还是选择了自己搭建一个本地的服务,通过控制路由返回不同的mock数据来处理,并且通过为请求增加一个额外mock参数通知业务哪些接口应当被自建的mock-server拦截,从而尽量减少对原有业务的影响。
在mock-server开发之前,我们需要明白我们的mock-server应当能做哪些事情:
- 所改即所得,具有热更新的能力,每次增加 /修改 mock 接口时不需要重启 mock 服务,更不用重启前端构建服务
- mock 数据可以由工具生成不需要自己手动写
- 能模拟 POST、GET 请求
因为mock的模拟数据都在本地维护,我们所需要的只要是个无界面的能够响应请求的server即可,所以我选择了json-server
在构建server之前,我们先要明确我们需要模拟的数据是什么,以及用什么(mockjs)去维护
// db.js
var Mock = require('mockjs');
// 通过使用mock.js,来避免手写数据
module.exports = {
getComment: Mock.mock({
"error": 0,
"message": "success",
"result|40": [{
"author": "@name",
"comment": "@cparagraph",
"date": "@datetime"
}]
})
};
其次我们要知道我们跳转的访问路由是哪些:
// routes.js
// 根据db.js中的key值,自动生成的路由便是/[key],在route.js中的声明只是为了重定向
module.exports = {
"/comment/get": "/getComment"
}
然后我们就可以书写我们启动server的主要代码了:
// server.js
const jsonServer = require('json-server')
const db = require('./db.js')
const routes = require('./routes.js')
const port = 3000;
const server = jsonServer.create()
// 使用mock的数据生成对应的路由
const router = jsonServer.router(db)
const middlewares = jsonServer.defaults()
// 根据路由列表重写路由
const rewriter = jsonServer.rewriter(routes)
server.use(middlewares)
// 将 POST 请求转为 GET,满足可以接受 POST 和 GET 请求的需求
server.use((request, res, next) => {
request.method = 'GET';
next();
})
server.use(rewriter) // 注意:rewriter 的设置一定要在 router 设置之前
server.use(router)
server.listen(port, () => {
console.log('open mock server at localhost:' + port)
})
由此,只要使用node server.js便能够启动一个mock-server了,但是这样启动的server,并不能因为我修改route.js或者db.js而实时更新,也就是说,我需要每次都重启一次才能更新我的server,这里还需要我们进行一个小操作,比如使用nodemon来监控我们的mock-server.
// 将所有和mock相关的文件:db.js route.js server.js 放入mock文件夹
// 然后执行:
$ nodemon --watch mock mock/server.js
// 就能够启动一个能自动热更新的mock-server了。
这之后,我们只需要在自己的业务代码中,使用我们之前定义的类似于getDataUseMock的方法,就可以对指定API进行mock啦。
虽然我们这样做已经完成了mock数据和业务代码的完全分离,但是还是不可避免的在业务代码中使用了特殊的方法来声明我需要mock某个接口,还是同样要面对当不需要mock时,要删除这些方法并替换成正式请求的方法的问题。而且mock数据的部分仍然放在和业务代码一个git目录下,只有开发者才有权限去修改和增加,并没有很好地达到mock应当有的作用。
为此,我征求了部门Leader和“广大”开发者的意见,确定了我们需要的mock应当是怎样的:
- 尽量少的修改业务中的代码就能使用
mock - 修改的业务代码不会影响正常的业务流程
mock-server应当是面向所有人,而不只是前端开发者- 能够可视化的修改和增加
mock接口和mock数据 - 能够同时支持多个项目使用
在这几个基本原则的帮助下,我们的mock终于晋级到了“永恒钻石”段位。
“永恒钻石”
在钻石段位的加持下,我找到了 mock-server 的“上分利器”: 来自阿里前端团队开源的THX工具库中的RAP2,其包含的优势完全符合我对mock的需求。在依照网上的教程,将RAP2部署到了我们本地的服务器上之后,我们只需要通过在本地配置 hosts 文件即可访问我们自己的RAP2,这之后,我们需要做的仅仅只剩下业务代码中的处理了:
- 尽量少的修改业务中的代码就能使用
mock - 修改的业务代码不会影响正常的业务流程
为了能够尽量少的去修改代码并且让修改的代码不影响正常的业务流程,我们需要增加一个特殊的开发模式,仅在这个开发模式下,我们修改的代码才会生效,或者说才会存在。
我们给我们新增的开发模式可以命名为mock开发模式,为了区分这个开发模式,我们使用nodejs中的环境变量来进行区分。
"scripts": {
"dev:mock": "cross-env MOCK=true npm run dev"
}
在使用cross-env声明了环境变量之后,我们可以通过process.env.MOCK获取到我们声明的环境变量的值,当我们增加的MOCK变量存在,且为true时,我们才进行mock的请求拦截。
但是我们仅仅声明这一点还是不够,我们还需要通知业务代码,哪些接口需要被mock。所以,我们还需要一个mock模式下才会存在的列表,来告诉我们哪些接口应当被mock。
// config.js
if (process.env.MOCK) {
config.mockList = [
'/api/test',
'/api/needMock'
]
} else {
config.mockList = [];
}
当然你也可以使用条件编译来判断是否将config.mockList打入你的代码里,这是更加好的选择。
接下来,你只需要在你封装的请求方法里,对config的mockList和你当前请求的api进行对比,判断其是否要进行mock即可。
import config from '../config/config';
const mockServer = 'http://rap2.xxx.com'
function request(opt) {
const apiName = opt.api;
if (config.mockList && config.mockList.includes(apiName)) {
opt.url = `${mockServer}/${apiName}`;
}
...
}
如此,我们的mock终于到达了最终形态,从此只要接口文档(甚至RAP2的mock接口就可以直接作为接口文档),我们就能随意的进行开发测试啦~
RAP2的使用
从团队开始
团队是仓库的上级单位,一个团队可以拥有多个mock仓库,但是不是只有团队才能拥有仓库,个人也可以。使用团队的目的只是为了让团队下的仓库不被团队外人员获悉,保持一个团队的私密性(当然你也可以选择公开团队)。
仓库
仓库是接口的上级单位,可以归属于个人或者团队,每个仓库都可以指派开发人员,被指定的人员可以修改或者添加仓库的接口,未被指派的人员仅能查看接口,每个仓库都拥有一个特定的仓库域名前缀。其下的接口域名规则都遵循:${仓库前缀域名}${接口配置域名},且每个仓库都提供一个接口获取当前仓库数据。
接口
我们先来看看接口配置页面的组成:
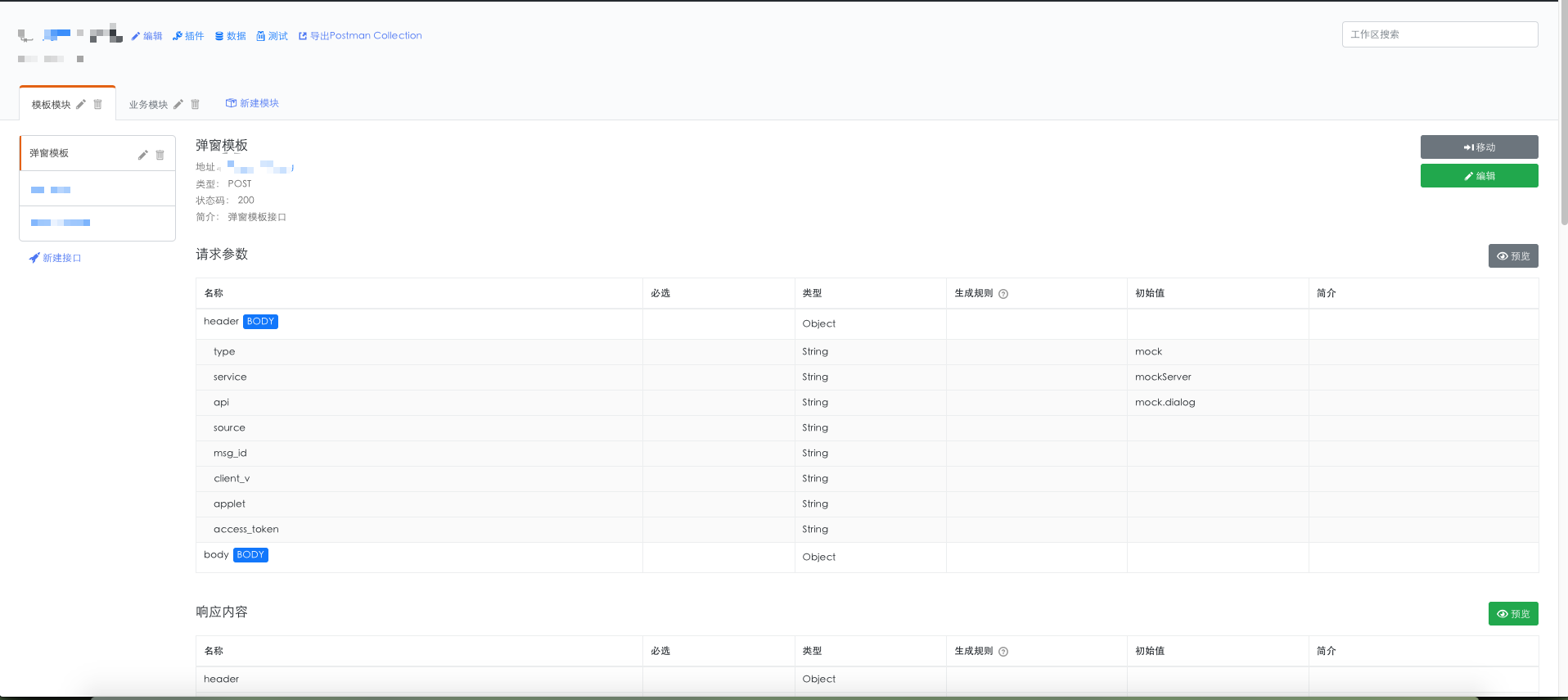
- 新建接口(接口列表)
- 接口模块
- 接口详情(请求参数和响应参数)
在接口详情中,请求的mock接口的路由是在新建接口的时候去创建的,创建之后自动生成一个接口,请求地址就是${仓库域名}${接口路由}。
请求参数的部分配置我们最主要要关注的是生成规则和默认值,其规则和模板可以参考mockJs的文档中的语法规范,生成规则遵循数据模板定义规范(Data Template Definition,DTD),默认值遵循数据占位符定义规范(Data Placeholder Definition,DPD)。
