

在深度学习环境安装一文中,我们已经搭建了撸代码的基本环境。现在就可以来正式写代码了。我们今天的目标是模拟线性回归,通过调整参数(斜率k和b)找到和数据最匹配的线性函数。
tips: 所有代码都在jupyter notebook中完成
自动微分变量
首先是引入pytorch,以及包含的自动微分变量包autograd
这个自动微分变量是用来干什么的呢?
简单来说,他是将张量的运算“流程化”,在使用自动微分变量进行运算时,其实上是在构建一个计算图。
比如, 我们定义了两个变量, 一个是tensor, 一个是自动微分变量

requires_grad = True的含义,代表这个微分变量可反向传播
tensor的方法variable几乎都能用,而variable有很多它自己独特的方法,比如反向传播(backward),对输入量求梯度值(grad())等等。稍后我们会在实例中对相关方法做进一步解释。
现在我们要知道的是,所有需要神经网络调整的参数,都需要具备“梯度可反传”的性质,所以,他们在定义时,都需要定义为自动微分变量。
让我们再定义一个variable变量, torch.linspace(0, 10)是创建在阈值为[0, 10]上均等划分出一个100维的向量,如夏所示
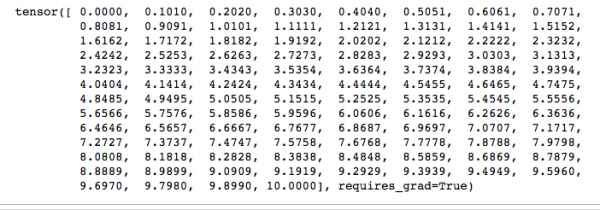
然后我们对这个变量进行2步运算
-
x + 2得到新变量y
-
y平方再取均值,得到一个变量z

上述过程用数学描述,即可表示为如下复合函数。
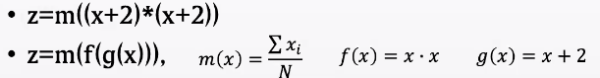
如果在z上,有任何的数值波动,我们都可以用数学的方法,求出x偏导的一个解析解,即x对应的数值波动。
而这个过程在神经网络中,就是梯度反传。目标值的数值波动,在自变量上都会有一个梯度的变化。
在pytorch中就更简单了,只需要一句backword()命令,不管中间经历了多复杂的函数运算,都能直接在自变量中获取梯度
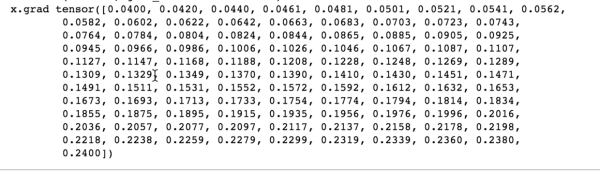
神经网络本质上就是复杂的函数运算,我们把中间复杂的运算部分交给机器,才能把更多的精力放在研究“函数组合”,也就是算法上
拟合线性回归
了解神经网络最关键的反向传播机制后,我们接下来尝试做一个简单的拟合。
1. 生成数据
首先我们模拟一些离散的点。使用randn方法生成[0-1]区间内正态分布的随机点,它接收一个生成数量的参数
设置完了之后我们把这些点画出来,这里就用到了一个第三方的库matplotlib.pyplot,官方文档在这里,上篇文章也带大家安装过。这里直接引入,并画图
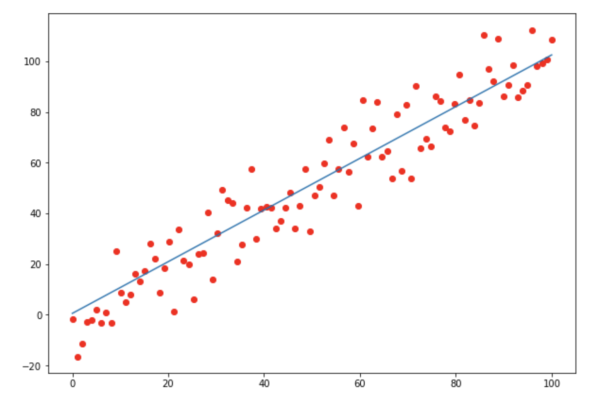
绘图结果如下
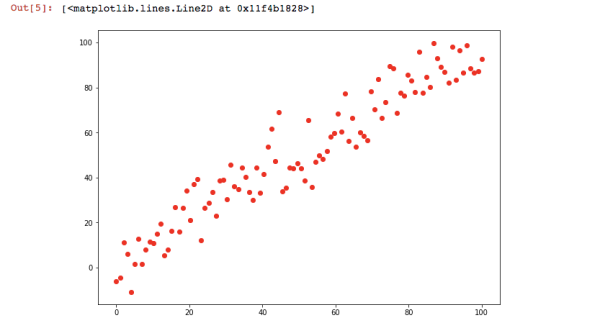
2. 写模型主体
这个图形是线性的,我们就可以将它设为一个一次函数y = k * x + b的形式。
那我们的目标就是,求出一组k和b,使得最后得出的一次函数和数据最接近。
初始的k和b可以随机生成,注意一定要将他们设置为微分变量,这样才能获取他们的梯度,
然后再设置一个学习率。学习率是一个超参数,一般可以设置为0.0001。如果太大会导致无法得到精确的结果,而太小又需要数量更多的运算过程。具体数值可以看训练情况调整。
现在就开始进入训练代码部分,我们先上代码
代码中每一步都有清晰的注释,我在这里着重解释一下几个重点:
-
expand_as()命令是一个维度变化操作,矩阵相乘操作对维度变化有要求,而它就是可以让两个相乘的矩阵维度匹配
-
损失函数:损失函数是一门大学问,他是预测值和真实值的“差异”,在这里选取的是最简单的损失函数,即直接将真实值和预测值相减,而为了避免正负号的影响,再做了一次平方操作。最终的损失值一定是一个0维的实数,而我们计算过程使用的都是张量,所以最后取了每一位相加后的均值,即torch.mean((predictions - y) ** 2)
-
自动微分变量的值,需要使用x.data()获取
-
每次获取到新的k和b后,记得清空k和b的梯度
每一轮训练我们都会得到一组新的k和b,当观察到loss的下降趋势逐渐变小时,说明模型训练的差不多了,这时候的k和b就是我们要的值了。那么我们可以尝试画出这条一次函数看看效果。
这时候我们需要引入计算包numby和绘图包matplotlib。
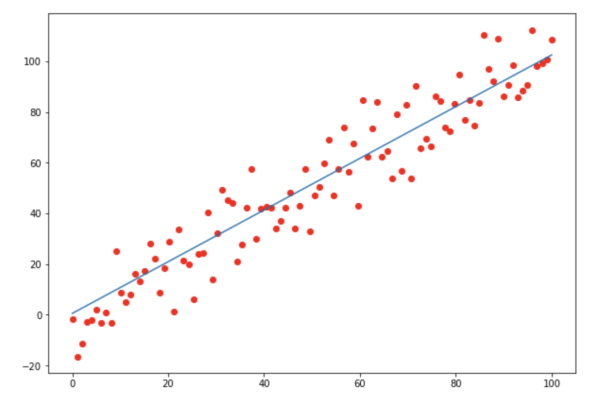
可以看到,最终的一次函数和数据基本吻合
下回我会写一篇真正的神经网络训练过程,更复杂也更有趣~
敬请期待
参考资料
